机器学习案例六:基于聚类的投资组合分析
基于聚类的投资组合分析
- 案例背景
- 数据预处理
- Kmeans、层次聚类以及谱聚类等
- kmeans
- 层次聚类
- 谱聚类
- 找到离类中心最近的股票
- 要求
- 定义函数
- 执行函数返回结果
案例背景
数据集 sh50components 中给出了上证 50 指数成分股从 2011 年 1 月4 日至 2019 年 5 月 10 日,共 2029 个交易日的涨跌幅数据。由于部分股票上市时间较晚,实际共有 42 只股票。
数据预处理
- 导入库
import pandas as pd
import numpy as np
import os
from sklearn.cluster import KMeans
from sklearn.cluster import MiniBatchKMeans
from sklearn import cluster
from sklearn import metrics
- 读取数据
df=pd.read_csv('sh50components.csv',encoding='gbk')
- 矩阵转置
df_t=df.T
df_t.to_csv('sh50t.csv',index=False,encoding='gbk')
- 加入人工标注的行业再读取数据
data=pd.read_csv('sh50t_label.csv',encoding='gbk')
data.index=df_t.index
索引是每个公司的名称

Kmeans、层次聚类以及谱聚类等
kmeans
- 模型建立
data_train=data.iloc[:,0:-2]
data_label=data.label
mdl_kmeans=KMeans(n_clusters=8).fit(data_train)
- 模型评估
#内部指标
print(metrics.davies_bouldin_score(data_train,mdl_kmeans.labels_))
print(metrics.silhouette_score(data_train,mdl_kmeans.labels_))
# 外部指标
print(metrics.adjusted_rand_score(data_label,mdl_kmeans.labels_))
print(metrics.adjusted_mutual_info_score(data_label,mdl_kmeans.labels_))
内部指标: #1.62 #0.08
外部指标:#0.2834 #0.311
层次聚类
- 模型建立
mdl_hc=cluster.AgglomerativeClustering(n_clusters=8).fit(data_train)
- 模型评估
#内部指标
print(metrics.davies_bouldin_score(data_train,mdl_hc.labels_))
print(metrics.silhouette_score(data_train,mdl_hc.labels_))
# 外部指标
print(metrics.adjusted_rand_score(data_label,mdl_hc.labels_))
print(metrics.adjusted_mutual_info_score(data_label,mdl_hc.labels_))
内部指标: #1.44 #0.071
外部指标:#0.504 #0.512
谱聚类
- 模型建立
mdl_spec=cluster.SpectralClustering(n_clusters=8,
affinity='nearest_neighbors',
n_neighbors=10).fit(data_train)
- 模型评估
#内部指标
print(metrics.davies_bouldin_score(data_train,mdl_spec.labels_))
print(metrics.silhouette_score(data_train,mdl_spec.labels_))
# 外部指标
print(metrics.adjusted_rand_score(data_label,mdl_spec.labels_))
print(metrics.adjusted_mutual_info_score(data_label,mdl_spec.labels_))
内部指标: #2.0 #0.075
外部指标:#0.504 #0.507
找到离类中心最近的股票
要求
在上一题的基础上,将属于同一类的全部样例的属性均值作为类中心,找到与该类中心距离最近的股票(Kmeans 算法给出了类中心,因此可以直接使用)。
定义函数
- 计算类中心
def find_center(df): #index是公司名称,每一列都是numeric
x=df.index
y=df.shape[1]
sum_=np.zeros(int(y))
for i in x:
a=df.loc[i,:]
sum_ = sum_ + np.array(a)
return sum_/df.shape[0]
- 返回聚类类中心最近的股票
def find_minest(df,center):
x=df.index
distance=1000000
company='wu'
for i in x:
distance_sample=np.sum((np.array(df.loc[i,:])-center)**2)
if distance_sample < distance:
distance=distance_sample
company=i
return company,distance
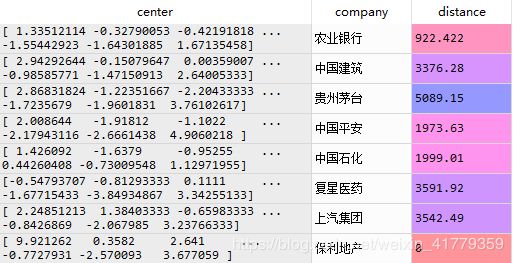
执行函数返回结果
class_=data['label'].value_counts().index
center_=[]
company_=[]
distance_=[]
for cla in class_:
class_df=data[data.label == cla]
class_df=class_df.drop('label',axis=1)
center=find_center(class_df)
company,distance=find_minest(class_df,center)
print('the {} center is :\n'.format(cla),center)
print('the nearest company is :\n',company)
center_.append(center)
company_.append(company)
distance_.append(distance)
stat_3=pd.DataFrame({'center':center_,'company':company_,'distance':distance_})