String
文章目录
- String
- 概述
- 字符串常量池
- String, StringBuffer and StringBuilder
String
概述
String在Java中是不可变类,被final修饰,因此他不可被继承。(Integer 等包装类也不能被继承,也是不可变类)
JDK8中String的底层实现是char数组
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
private final char value[];
JDK9中String的底层实现改为了byte数组,并且用coder标识使用哪种编码
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
private final byte[] value;
private final byte coder;
}
共同点都是value数组都还是不可变的数组,即数组元素可以变化,但是数组的初始化后就不能引用其他数组,从而保证String不可变
String 不可变性天生具备线程安全,可以在多个线程中安全地使用。
String的subString方法虽然改变了字符串内容,但是其实内部是新创建一个String对象进行返回,实际原字符串对象没有改变
public String substring(int beginIndex, int endIndex) {
if (beginIndex < 0) {
throw new StringIndexOutOfBoundsException(beginIndex);
}
if (endIndex > value.length) {
throw new StringIndexOutOfBoundsException(endIndex);
}
int subLen = endIndex - beginIndex;
if (subLen < 0) {
throw new StringIndexOutOfBoundsException(subLen);
}
return ((beginIndex == 0) && (endIndex == value.length)) ? this
: new String(value, beginIndex, subLen);
}
字符串常量池
字符串常量池存在于方法区中,是一片K-V存储区,K是字符串内容,V是字符串对象实例,创建字符串时,如果字符串常量池中已经存在同内容的字符串,则直接返回String对象引用,不创建字符串
常量池的出现减少了字符串对象的创建,节省了内存,提高了效率,道理跟redis缓存是相似的
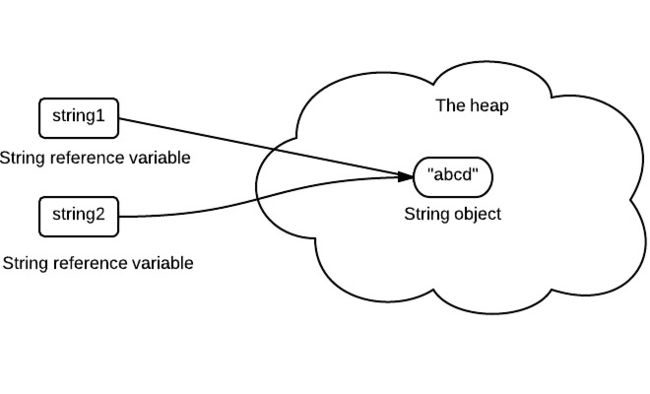
如果string对象如果是可变的,那么一个引用更改了字符串就会导致其他引用引用的字符串内容发生改变,这是String不可变的一个好处之一
String 的 intern() 方法在运行过程将字符串添加到 String Pool 中。
当一个字符串调用 intern() 方法时,如果 String Pool 中已经存在一个字符串和该字符串值相等(使用 equals() 方法进行确定),那么就会返回 String Pool 中字符串的引用;否则,就会在 String Pool 中添加一个新的字符串,并返回这个新字符串的引用。
String s1 = new String("aaa");
String s2 = new String("aaa");
System.out.println(s1 == s2); // false
String s3 = s1.intern();
String s4 = s1.intern();
System.out.println(s3 == s4); // true
// s3和s4引用的都是s1时产生的实例
intern()原理
public native String intern();
intern()是一个本地方法
Java_java_lang_String_intern(JNIEnv *env, jobject this)
{
return JVM_InternString(env, this);
}
JVM_ENTRY(jstring, JVM_InternString(JNIEnv *env, jstring str))
JVMWrapper("JVM_InternString");
JvmtiVMObjectAllocEventCollector oam;
if (str == NULL) return NULL;
oop string = JNIHandles::resolve_non_null(str);
//重点在这
oop result = StringTable::intern(string, CHECK_NULL);
return (jstring) JNIHandles::make_local(env, result);
JVM_END
常量池的寻找和返回引用的过程:
oop StringTable::intern(Handle string_or_null, jchar* name,
int len, TRAPS) {
// 先通过字符串的name和长度len算出哈希值
unsigned int hashValue = java_lang_String::hash_string(name, len);
// 根据哈希值找到在字符串常量池中的位置索引
int index = the_table()->hash_to_index(hashValue);
oop string = the_table()->lookup(index, name, len, hashValue);
// Found
// 不为空即原来存在则直接返回引用
if (string != NULL) return string;
// Otherwise, add to symbol to table
// 否则则创建新对象放入池中
return the_table()->basic_add(index, string_or_null, name, len,
hashValue, CHECK_NULL);
}
查找的过程,循环遍历,一个一个比较
oop StringTable::lookup(int index, jchar* name,
int len, unsigned int hash) {
for (HashtableEntry<oop>* l = bucket(index); l != NULL; l = l->next()) {
if (l->hash() == hash) {
if (java_lang_String::equals(l->literal(), name, len)) {
return l->literal();
}
}
}
return NULL;
}
所以可以看出,字符串常量池内部解决哈希冲突使用的是拉链法,所以当字符串非常多时,效率会有所下降,因为哈希冲突也会随着严重,可能需要遍历很长的链表
如果是采用 “bbb” 这种字面量的形式创建字符串,会自动地将字符串放入 String Pool 中。
String s5 = "bbb";
String s6 = "bbb";
System.out.println(s5 == s6); // true
JDK7之前字符串常量池是放于永久代,永久代空间有限,大量使用字符串容易OOM,JDK7之后字符串常量池放于堆中
new String(“abc”)
// 编译期只在字符串常量池创建abc对象,仅仅在字符串常量池没有相关对象时才创建
String abc = "abc";
// 会创建两个对象,堆中和字符串常量池中都会(前提是 String Pool 中还没有 "abc" 字符串对象)。每次都创建,并且指向堆中对象,不指向字符串常量池中的对象
String abc = new String("abc");
所以:
public class Test {
public static void main(String[] args) {
String abc = "abc";
String abc1 = new String("abc");
System.out.println(abc == abc1); // false
}
}
可以看到,new String()每次都会新创建对象
public class Test {
public static void main(String[] args) {
String abc1 = new String("abc");
String abc = "abc";
System.out.println(abc == abc1); //还是false
}
}
可以看出abc1指向的是堆中对象而不是字符串常量池的对象
String, StringBuffer and StringBuilder
区别:
- 可变性:
- string不可变
- stringbuffer和stringbuilder可变
- 线程安全:
- string,stringbuffer线程安全
- stringbuilder线程不安全
- 效率:
- stringbuilder优于stringbuffer
两个字符串的拼接操作
"abc" + "def"
内部是调用的stringbuilder实现