哈夫曼算法——C/C++
哈夫曼
1、简介
- 哈夫曼树又称最优二叉树,是一种带权路径长度最短的二叉树。所谓树的带权路径长度,就是树中所有的叶结点的权值乘上其到根结点的路径长度(若根结点为0层,叶结点到根结点的路径长度为叶结点的层数)。
- 树的带权路径长度记为WPL=(W1L1+W2L2+W3L3+…+WnLn),N个权值Wi(i=1,2,…n)构成一棵有N个叶结点的二叉树,相应的叶结点的路径长度为Li(i=1,2,…n)。可以证明哈夫曼树的WPL是最小的。
2、哈夫曼树
例子:A 7 B 19 C 2 D 6 E 32 F 3 G 21 H 10
代表数据和权值,哈夫曼树就是要使WPL最小。
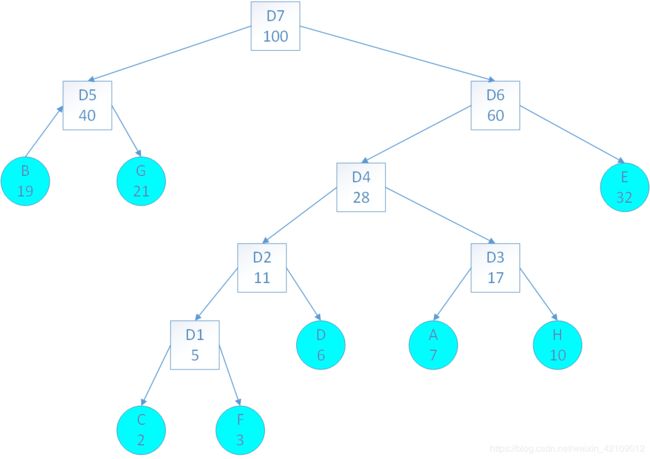
下图是编辑好的哈夫曼树。
圆圈是初始数据和初始权值,正方形是计算权值。
根节点为0,每层依次加一。
WPL=2x4+3x4+6x3+7x3+10x3+19x2+21x2+32x2
这就是最简单的,不管你再怎么建树都比这个大。
哈夫曼算法原理:
2.1、为每个符号建立一个叶子节点,并加上其相应的发生频率
2.2、当有一个以上的节点存在时,进行下列循环:
- 把这些节点作为带权值的二叉树的根节点,左右子树为空
- 选择两棵根结点权值最小的树作为左右子树构造一棵新的二叉树,且至新的二叉树的根结点的权值为其左右子树上根结点的权值之和。
- 把权值最小的两个根节点移除
- 将新的二叉树加入队列中.
2.3、最后剩下的节点暨为根节点,此时二叉树已经完成。
3、哈夫曼编码
在数据通信中,经常需要将传送的的文字转换为二进制字符0、1,组成的二进制字符串,该过程称为编码。
哈夫曼编码可用于构造最短代码长度方案。
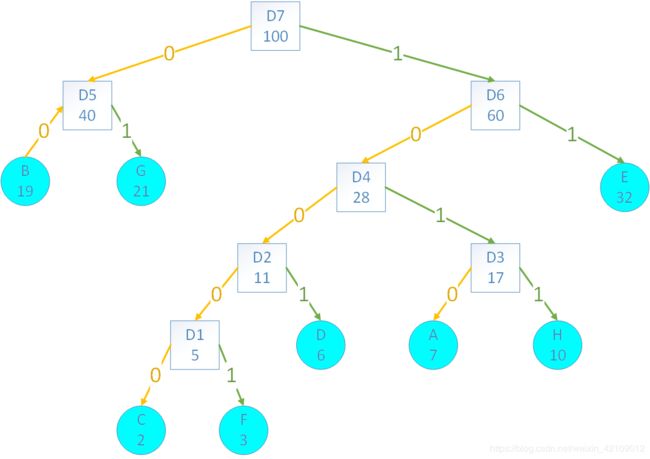
哈夫曼编码就是使用哈夫曼二叉树,左节点为0,右节点为1,最后得到该位置的01路径。
哈夫曼编码的实质就是使用次数越多的字符采用的编码越短。
例如:上图
A——1010
B——00
C——10000
D——1001
E——11
F——10001
G——01
H——1011
4、代码实现
三个函数
//创建哈夫曼树
void createHT(HTNode HT[],int n)
//哈夫曼编码
void createHCode(HTNode HT[],HCode HC[],int n)
//主函数
int main()
结构体
(1)哈夫曼树结构体
权重可以改类型,一般统计频率用float、double,统计次数用int。
typedef struct node{ //定义哈夫曼结点类型
char data; //结点值
int weight; //权重
int parent; //父结点
int lchild; //左孩子结点
int rchild; //右孩子结点
}HTNode;
(2)哈夫曼编码结构体
typedef struct code{
char cd[256]; //存放的哈夫曼码
int start; //记录cd[]编译哈夫曼码的起始位置
}HCode;
#define _CRT_SECURE_NO_WARNINGS
#include5、运行结果
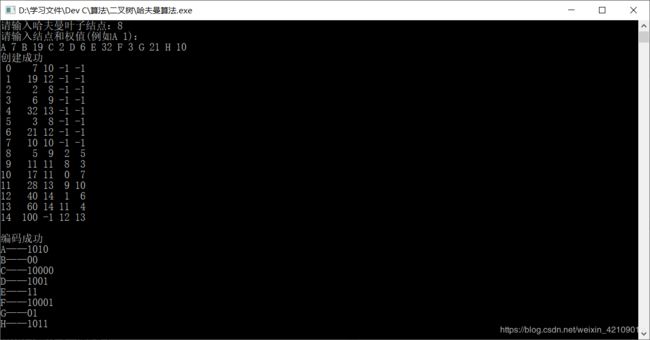
例子:8
A 7 B 19 C 2 D 6 E 32 F 3 G 21 H 10
(可以一对一对的输入,也可以一次全部输入)
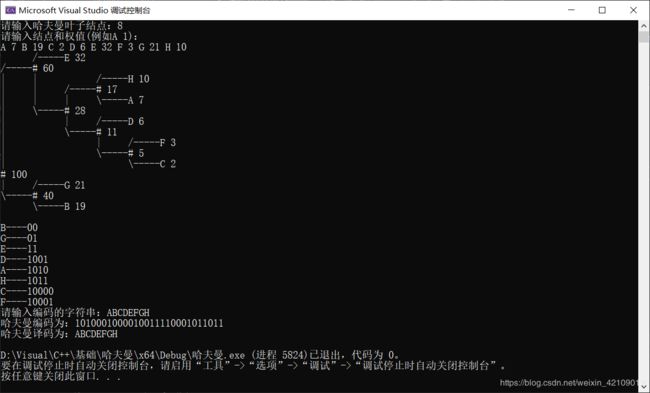
更新(2020/5/22)
上述仅仅实现哈夫曼编码构造,然而大部分都需要加密解密,所以重新编写了哈夫曼算法
因为使用的 scanf() 输入,所以没考虑空格
#define _CRT_SECURE_NO_WARNINGS
#include