【Oracle-OCP】第三次课
Category
- OLAP与OLTP的介绍
- OLAP
- OLTP
- Oracle Memory Structure
- SGA(System Global Area)是什么?
- data buffer cache
- redo log buffer
- shared pool
- PGA(Process Global Area)是什么?
- PGA与SGA的异同?
- Pool,Buffer,Cache的区别
- 落盘・集群・事务
- 落盘是什么?
- 集群是什么?
- 事务是什么?
- DB日志
- Redo
- Alert
- audit
- COMMAND
- 自动内存管理
- 块儿的大小
- 一次IO读多少个块儿
- keep cache size
- recyle cache size
- 查看log_buffer大小
- 如何设定log_buffer?
- TIP
- Redo触发的条件
- Oracle的log_buffer该设为多大?
- Oracle的log_buffer如何设置?
- 想看记录操作系统里面所有报错/谁登陆上来的信息怎么办?
- 如何优化一张不常用的表
- 我有一个表5个g,把它放到内存里,就把其他内容挤走了怎么办
- 系统稳定的情况下,命中率低的原因可能是?
- 什么是内存数据库?
- 数据库块默认大小是?
- 如果一个块儿8块,但你要读的数据是16块怎么办?
- DBA主要做这些事
- RPM
- Rpm不同的软件安装方法
OLAP与OLTP的介绍
数据处理大致可以分成两大类:联机事务处理OLTP(on-line transaction processing)、联机分析处理OLAP(On-Line Analytical Processing)。OLTP是传统的关系型数据库的主要应用,主要是基本的、日常的事务处理,例如银行交易。OLAP是数据仓库系统的主要应用,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。
OLTP 系统强调数据库内存效率,强调内存各种指标的命令率,强调绑定变量,强调并发操作;
OLAP 系统则强调数据分析,强调SQL执行市场,强调磁盘I/O,强调分区等。
OLAP
数据仓库,按周,或按月往库里导数据,只读的,没有更改操作的
OLAP(Online AnalyticalProcessing)是一种数据处理技术,专门设计用于支持复杂的分析操作,侧重对决策人员和高层管理人员的决策支持,可以根据分析人员的要求快速、灵活地进行大数据量的复杂查询处理,并且以一种直观而易懂的形式将查询结果提供给决策人员,以便他们准确掌握企业(公司)的经营状况。
配置oracle时,空间分配默认为40%,需要我们调到80%
OLAP系统:PGA占比20%,SGA占比60%
OLTP系统: PGA占比60%,SGA占比20%
OLTP
OLTP,也叫联机事务处理(Online Transaction Processing),表示事务性非常高的系统,一般都是高可用的在线系统,以小的事务以及小的查询为主,评估其系统的时候,一般看其每秒执行的Transaction以及Execute SQL的数量。在这样的系统中,单个数据库每秒处理的Transaction往往超过几百个,或者是几千个,Select 语句的执行量每秒几千甚至几万个。典型的OLTP系统有电子商务系统、银行、证券等,如美国eBay的业务数据库,就是很典型的OLTP数据库。
OLTP系统最容易出现瓶颈的地方就是CPU与磁盘子系统。
接下来主要讲的是OLTP的内容
Oracle Memory Structure
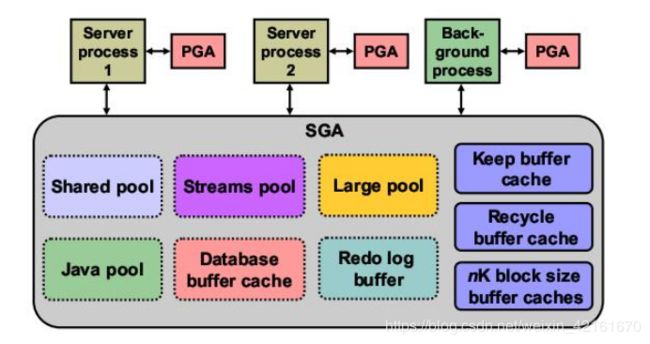
SGA(System Global Area)是什么?
SGA:System Global Area(全局系统区)是Oracle Instance的基本组成部分,在实例启动时分配;系统全局域SGA主要由三部分构成:共享池(share pool)、数据缓冲区(data buffer cache)、日志缓冲区(log buffer)。
每个Oracle实例都会有一个庞大的内存结构,称为SGA
每个Oracle进程会访问SGA的一部分
data buffer cache
(1) data buffer cache的作用与目的
-
缓冲磁盘的数据:
- buffer: memory -> disk
-
设置data buffer cache的目的:
- 从buffer的角度:Lazy Write 延迟写
- 从cache的角度:Flash Cache
(2) data buffer cache的状态
- unused
- clean
- clean是指 commit以后,log写到磁盘里,data在磁盘里,这样的数据就是干净数据
- dirty
- dirty指 commit以后,log写到磁盘里,data不写,这样的数据就是脏数据/脏块儿
(3) data buffer cache的种类
- keep pool
- recycle pool
- default pool
- nk pool
(4)data buffer cache又名
- data buffer
- buffer cache
redo log buffer
(1) redo log buffer的作用和目的
- redo log buffer中记录了DML & DDL的操作
这些操作是以时间顺序连续的记录在redo log buffer中 - 由于data buffer cache的存在,导致了数据的不安全
-log buffer的存在避免这这种不安全的隐患 ——— 提交后的数据不会丢失 - 日志先行
(2) 触发LGWR的条件
- 每3scommit
- log switch
- 1/3的log buffer空间满了或者超过1mb的data写入log buffer中
(3) redo log buffer大小的设置
- redo log buffer最小要设置1.625MB
- 一般来说,由于"1/3和1MB的原则",log buffer超过10MB没有什么太大的意义
- 对于一个高并发事务的大型系统来说,需要加大log buffer的大小
- LGWR在忙于将redo log从memory写入到disk中,会有新的redo log继续填入到log buffer中
shared pool
(1) shared pool的组成
- library cache: 内存中用来存储sql解析后的信息,执行计划
- 与library cache相关的概念
- hard parse, soft parse, soft soft parse
- VKaTeX parse error: Expected 'EOF', got '&' at position 5: SQL &̲ VSQLAREA
- 与library cache相关的概念
- data dictionary cache: 内存中用来存储数据字典的信息
- reserve pool: 内存中用来存储大的对象(超过5KB)
(2) result cache(非常类似memcached)
- result cache是oracle11g推出的新特性,通过把结果集缓存在内存中提高查询的性能
- result cache适合于数据变化不频繁的系统,例如OLAP
- 如果使用了result cache,在执行sql前,oracle先去result cache中查看相关的结果
- 当先关的对象发生了变化,比如表中的数据被删除了一条,则缓存的结果失效
detail http://blog.itpub.net/17203031/viewspace-765994/
(3) bind variable
PGA(Process Global Area)是什么?
PGA(Program Global Area程序全局区)是一块包含一个服务进程的数据和控制信息的内存区域。你每启动一个数据库进程就会在内存中创建一个pga,它是独有的,非共享。
PGA是一个特定于进程的内存
他是一个操作系统进程或者线程专用的内存(Linux-进程,Windows-线程)
不允许系统的其他进程或者线程访问
PGA中的P有三种含义
- Process
- Program
- Private
PGA由三块组成
- SQL Work Area[*important]: (1) hash join, (2) [**important]sort, (3) bitmap merge
- Private SQL Area: bind variable info
- Session Memory: session info
从Oracle9i起,有两种办法管理PGA的内存
- 手动PGA内存管理
- 自动PGA内存管理
从Oracle11g起,自动管理PGA内存可以通过两种技术来实现
- 设置PGA_AGGREGATE_TARGET参数
- 设置MEMORY_TARGET参数
PGA与SGA的异同?
PGA与 SGA 类似,都是 Oracle 数据库系统为会话在服务器内存中分配的区域。
两者的作用和共享程度也不相同。 SGA 对系统内的所有进程都是共享的。当多个用户同时连接到一个例程时,所有的用户进程、服务进程都可以共享使用这个 SGA 区。SGA 的主要用途就是为不同用户之间的进程与服务进程提供交流的平台。
Pool,Buffer,Cache的区别
Pool:没有文件作交互的
Buffer,cache内存与文件作交互的,但交互的方向是不一样的
Buffer(缓冲): 从内存写到磁盘,缓冲压力,延迟写
Cache(缓存):从磁盘缓存到内存
落盘・集群・事务
落盘是什么?
如图,将data或log从内存写到磁盘的这一过程称之为落盘
落盘有两种方式
- Data从内存写到库,写的方式是随机写
- 是Log从内存写到库,写的方式是顺序写
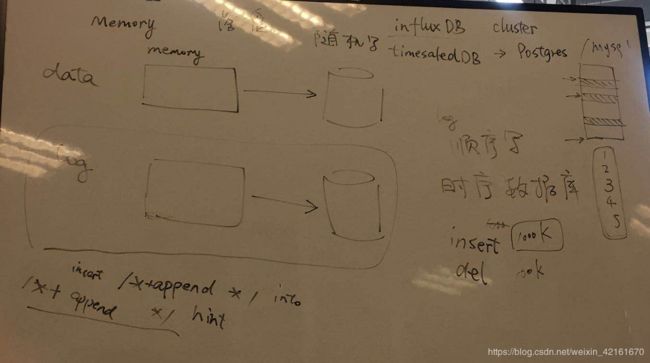
那么问题来了,当执行一行命令后进行commit操作时,是触发data写入,还是log写入?
写监控(log)是顺序写(把日志记录到日志里,插入数据时插时间戳),代价小
写data是随机写,折腾,成本大
因此进行commit操作时,是触发log写
时序数据库特点
时序数据库就是记log
时序数据库不支持删除某一条,但可以按照时间来删一片
所有数据库都支持Data写入和log写入吗
举例来说,influxDB只有Data写,没有Log写的机制
Postgre,Oracle支持Data,Log这两条机制
集群是什么?
简单来说是多库复制,一个库down了,就起另一个库
事务是什么?
两个commit中间夹的就是一个事务
要提交就全提交,要取消就全取消,这样的叫做事务
DB日志
Redo,alert,audit
Redo
记录的是oracle里边所有的操作(DML操作),针对于数据的操作
假设你向数据库Insert 1
Redo 记录的是什么时间哪个用户执行了一个什么样的操作
Rodo的作用?
是用于恢复脏数据的
Alert
告警日志,记录的是数据库的情况(记录数据库的生老病死)
Alert里记录的是谁什么时间登陆了数据库,数据库什么时候down机了,什么时候启动了
某一个数据文件要满了,warning,告诉你我要切换了
日志满了,我要切换了,告警一下,然后日志切换
有三组日志
a满了,往b里写,
b满了,往c里写,
c满了,往a里覆盖
audit
审计,DDL(create,drop,alter),DML(增,删,改)
COMMAND
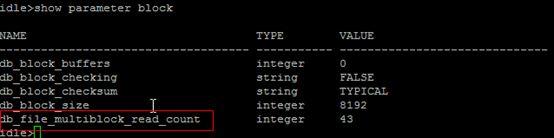
- show we buffer
- show parameter 8k
- show parameter block
- show parameter keep
- show parameter log_buffer
自动内存管理
sqls
idle>show we buffer

- db_block_buffers 是buffer cache的大小: 0是自动调整
- buffer_pool_keep
buffer_pool_recycle
keep pool 和recycle的大小也是自动的,要多少拿多少
块儿的大小
数据以块儿为单位存储,一般默认最小存储单位为8k
sqls
idle>show parameter 8k
idle>show parameter 16k
idle>show parameter 32k
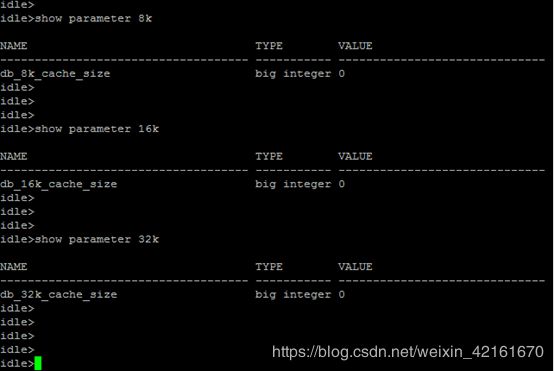
一次IO读多少个块儿
截图显示,一次IO读43个块儿
sqls
idle>show parameter block
keep cache size
sqls
idle>show parameter keep
recyle cache size
sqls
idle>show parameter recycle
查看log_buffer大小
idle>show parameter log_buffer
如何设定log_buffer?
log_buffer是不能在线调整的。最简单的方法就是在init.ora文件中添加一句 “log_buffer=5000000”。 然后用这个init.ora重启Oracle(SQL>startup pfile=init.ora)
https://blog.csdn.net/jiaping0424/article/details/80353968
TIP
Redo触发的条件
- 每三秒触发一次
- Commit后会触发redo log
- 日志切换(开启一个新文件,将log刷到磁盘)
- 当log buffer满了 1/3,或写入数据量超过1M时,就会写入到磁盘里
*Log buffer的大小? 3M
生产环境设置50M够用
Oracle的log_buffer该设为多大?
各地现场的log_buffer都不一样,有的现场设置为200M,有的现场设置500K。到底应该设多大呢?
log_buffer是Redo log的buffer。
因此在这里必须要了解Redo Log的触发事件(LGWR)
1、当redo log buffer的容量达到1/3
2、设定的写redo log时间间隔到达,一般为3秒钟。
3、redo log buffer中重做日志容量到达1M
4、在DBWn将缓冲区中的数据写入到数据文件之前
5、每一次commit–提交事务。
上面的结论可以换句话说
1、log_buffer中的内容满1/3,缓存刷新一次。
2、最长间隔3秒钟,缓存刷新一次
3、log_buffer中的数据到达1M,缓存刷新一次。
4、每次提交一个“事务”,缓存刷新一次
对于日志缓冲区来说,设置过小,容易引起log buffer space等待事件。但也不是说设置得越大就越好的,设置过大,由于LGWR进程会不断启动刷新日志缓冲区从而释放内存,所以可能会根本用不上多余的内存,从而浪费内存。
设置合适的日志缓冲区大小,目的是为了能够让LGWR进程合理地触发。理想情况下是,一方面,在LGWR进程向联机日志文件中写重做记录时,日志缓冲区中还是有剩余的可用空间以供其他进程所使用;另一方面,当LGWR进程完成时,日志缓冲区中的剩余可用空间不要很多,因为这时由LGWR所写入日志文件的日志块就可以释放出来了,成为新的剩余可用空间。然后,LGWR可以再次启动刷新脏的日志块。如此良性循环,就能在满足性能的前提下,充分利用日志缓冲区。没必要盲目地把日志缓冲区设置得很大,完全可以把节省下来的内存交给比如数据块缓冲区(buffer cache)等这样更需要内存的组件。
我们已经知道,当重做记录达到日志缓冲区的1/3或1MB时,就会触发LGWR进程。也就是说,Oracle默认认为LGWR进程在写日志缓冲区大小的1/3或1MB的重做记录的过程中,剩下的日志缓冲区可以供新的重做记录的需要。当LGWR写完以后,那么这1/3或1MB的日志缓冲区就又可以成为可用的日志块以容纳新的重做记录了。由此,我们可以很容易推导出,当我们设置日志缓冲区达到3MB(3×1MB)以上时,这时多余出来的日志缓冲区实际上并不能用得上,换句话说,多余出来的内存就被我们浪费了。
在设置日志缓冲区时,可以参考下面这个建议的公式来计算:1.5×(平均每个事务所产生的重做记录大小×每秒提交的事务数量)。
首先先找到总事务量是多少:
select a.value as trancount from v s y s s t a t a , v sysstat a,v sysstata,vstatname b
where a.statistic# = b.statistic# and b.name = ‘user commits’;
然后,找到系统总共的运行时间:
select trunc(sysdate - startup_time)2460*60 as
seconds from v$instance;
第三,找到产生的所有重做记录大小:
select value as redoblocks from v$sysstat where name =
‘redo blocks written’;
最后,我们可以分别计算公式中的值:平均每个事务所产生的重做记录大小= redoblocks/trancount;每秒提交的事务数量=trancount/seconds。这样,最后所建议的日志缓冲区的大小可以写为:1.5×(redoblocks/trancount)×(trancount/seconds)。
由此可以得出log_buffer一般在3-5M就足够了。超过3-5M,仅仅是浪费内存;当然太小了,也可能影响性能。在内存不太昂贵的今天,且如果你有大量“大事务”,log_buffer就设定为5M吧。
Oracle的log_buffer如何设置?
今天在测试机上试着修改log_buffer参数,发现log_buffer参数值单位不能是K M G,而只能是整数,同时scope不能指定为both,验证过程如下:
1.查看当前的参数值
SQL> show parameters log_buffer;
NAME TYPE VALUE
log_buffer integer 7024640
2.scope不能指定为both
SQL> ALTER SYSTEM SET log_buffer = 65536 scope=both;
ALTER SYSTEM SET log_buffer = 65536 scope=both
*
ERROR at line 1:
ORA-02095: specified initialization parameter cannot be modified
3.单位不能是K,M,G
SQL> ALTER SYSTEM SET log_buffer = 32m scope=spfile;
ALTER SYSTEM SET log_buffer = 32m scope=spfile
*
ERROR at line 1:
ORA-02095: specified initialization parameter cannot be modified
SQL> ALTER SYSTEM SET log_buffer = 32k scope=spfile;
ALTER SYSTEM SET log_buffer = 32k scope=spfile
*
ERROR at line 1:
ORA-02095: specified initialization parameter cannot be modified
SQL> ALTER SYSTEM SET log_buffer = 32g scope=spfile;
ALTER SYSTEM SET log_buffer = 32g scope=spfile
*
ERROR at line 1:
ORA-02095: specified initialization parameter cannot be modified
4.不用指定单位,直接就是bytes
SQL> ALTER SYSTEM SET log_buffer = 65536 scope=spfile;
System altered.
5.恢复初始值.
SQL> ALTER SYSTEM SET log_buffer = 7024640 scope=spfile;
System altered.
想看记录操作系统里面所有报错/谁登陆上来的信息怎么办?
Tail –f /var/log/messages
黑你机器的黑客不想让你知道你被黑了一定会改这个log,因为这上面记录着谁登上来过~
如何优化一张不常用的表
敲如下命令:
我为了我要用的时候能马上用到它,就把它手动cache到keeppool里
Alter table a cache i
我有一个表5个g,把它放到内存里,就把其他内容挤走了怎么办
把非常大的对其他内容有影响的,给它专门设了个库,叫recycle pool
通常把这种大容量的内容放到这个库即可
系统稳定的情况下,命中率低的原因可能是?
cache里的内容被别的内容挤走了
如何解决这个问题?
扩大内存
什么是内存数据库?
内存大于文件的数据库 (redis)
数据库块默认大小是?
8k,能满足绝大部分人的需求
如果一个块儿8块,但你要读的数据是16块怎么办?
行迁移-rowchained
分成两个块儿,中间加个指针
OLTP的库默认8个块的块儿,ok,没错儿
OLAP的库可以设成16个块的块儿
DBA主要做这些事
简单概括为三点
- 优化(内存 参数优化)
- 高可用
- 数据恢复
RPM
Rpm不同的软件安装方法
- Yum安装
- Binery files 二进制文件安装(解压包后直接安装,绿色安装 比如mongo)
- Source code/ =》configure – prefix=/opt/mysql
以mysql为例,如果用命令安装,那么文件会分布在不同路径下
- 数据文件在var/profile下
- 配置文件在etc下
- Log-error在/var/log下
- Pid-file 在/var/run下
如果用source code安装(将/opt/mysql打成rpm包),能实现以下的目录
- Opt/mysql/data
- Opt/mysql/Log
- Opt/mysql/Etc
但是编译时间非常长,两个小时左右
如果有一百台电脑需要你去安装的话,这种方式很不可取
解决办法是打一个rpm的包,在每台电脑双击包进行安装能够大大节省时间,提高效率