NLP(十):RNN和LSTM的反向传播BPTT,GPU,Text-RNN的原理及其keras实现
目录
1. RNN
1.1 RNN的结构(前向传播)
1.2 RNN的前向传播
1.3 RNN的反向传播BPTT
1.4 RNN的优缺点
2. 双向RNN
3. 针对梯度爆炸,梯度消失的解决
4. LSTM及GRU
4.1 LSTM
4.1.1 LSTM之遗忘门
4.1.2 LSTM之输入门
4.1.3 LSTM之细胞状态更新
4.14 LSTM之输出门
4.2 GRU
5. Text-RNN的原理
6. 利用Text-RNN进行文本分类的keras实现
1. RNN
本小节参考:https://www.cnblogs.com/pinard/p/6509630.html
1.1 RNN的结构(前向传播)
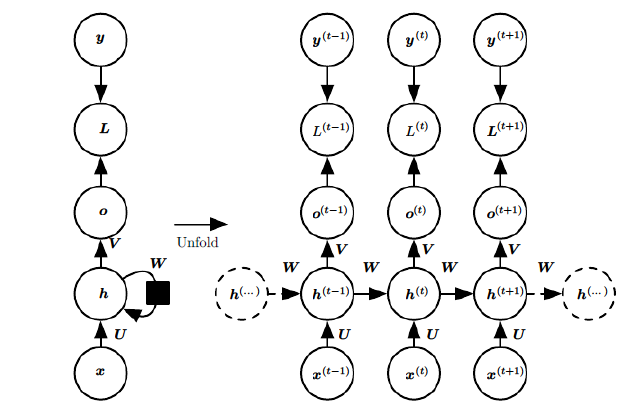
DNN和CNN中,训练样本的输入和输出是比较的确定的。但是有一类问题DNN和CNN不好解决,就是训练样本输入是连续的序列,且序列的长短不一,比如基于时间的序列:一段段连续的语音,一段段连续的手写文字。这些序列比较长,且长度不一,比较难直接的拆分成一个个独立的样本来通过DNN/CNN进行训练。
而对于这类问题,RNN则比较的擅长。RNN假设我们的样本是基于序列的。比如是从序列索引1到序列索引ττ的。对于这其中的任意序列索引号tt,它对应的输入是对应的样本序列中的x(t)。而模型在序列索引号tt位置的隐藏状态h(t),则由x(t)和在(t−1)位置的隐藏状态h(t−1)共同决定。在任意序列索引号t,我们也有对应的模型预测输出o(t)。通过预测输出o(t)和训练序列真实输出y(t),以及损失函数L(t),我们就可以用DNN类似的方法来训练模型,接着用来预测测试序列中的一些位置的输出。
这幅图描述了在序列索引号tt附近RNN的模型。其中:
1)x(t)代表在序列索引号t时训练样本的输入。同样的,x(t−1)和x(t+1)代表在序列索引号t−1和t+1时训练样本的输入。
2)h(t)h(t)代表在序列索引号tt时模型的隐藏状态。h(t)h(t)由x(t)x(t)和h(t−1)h(t−1)共同决定。
3)o(t)代表在序列索引号tt时模型的输出。o(t)只由模型当前的隐藏状态h(t)决定。
4)L(t)代表在序列索引号tt时模型的损失函数。
5)y(t)代表在序列索引号tt时训练样本序列的真实输出。
6)U,W,V这三个矩阵是我们的模型的线性关系参数,它在整个RNN网络中是共享的,这点和DNN很不相同。 也正因为是共享了,它体现了RNN的模型的“循环反馈”的思想。
1.2 RNN的前向传播
对于任意一个序列索引号t,我们隐藏状态h(t)由x(t)和h(t−1)得到:
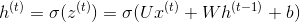
其中 为RNN的激活函数,一般为tanh, b为线性关系的偏倚。
为RNN的激活函数,一般为tanh, b为线性关系的偏倚。
序列索引号t时模型的输出o(t)的表达式比较简单:
![]()
在最终在序列索引号t时我们的预测输出为:
![]()
通常由于RNN是识别类的分类模型,所以上面这个激活函数一般是softmax。
通过损失函数L(t),比如对数似然损失函数,我们可以量化模型在当前位置的损失,即![]() )和y(t)的差距。
)和y(t)的差距。
1.3 RNN的反向传播BPTT
有了RNN前向传播算法的基础,就容易推导出RNN反向传播算法的流程了。RNN反向传播算法的思路和DNN是一样的,即通过梯度下降法一轮轮的迭代,得到合适的RNN模型参数U,W,V,b,c。由于我们是基于时间反向传播,所以RNN的反向传播有时也叫做BPTT(back-propagation through time)。当然这里的BPTT和DNN也有很大的不同点,即这里所有的U,W,V,b,c在序列的各个位置是共享的,反向传播时我们更新的是相同的参数。
为简化描述,这里的损失函数我们为交叉熵损失函数,输出的激活函数为softmax函数,隐藏层的激活函数为tanh函数。
对于RNN,由于我们在序列的每个位置都有损失函数,因此最终的损失L为:
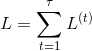
其中V,c,V,c,的梯度计算是比较简单的:
但是W,U,b的梯度计算就比较的复杂了。从RNN的模型可以看出,在反向传播时,在在某一序列位置t的梯度损失由当前位置的输出对应的梯度损失和序列索引位置t+1时的梯度损失两部分共同决定。对于W在某一序列位置t的梯度损失需要反向传播一步步的计算。我们定义序列索引t位置的隐藏状态的梯度为:
![]()
这样我们可以像DNN一样从δ(t+1)递推δ(t) :
对于δ(τ),由于它的后面没有其他的序列索引了,因此有:
![]()
有了δ(t),计算W,U,b就容易了,这里给出W,U,b的梯度计算表达式:
![]()
1.4 RNN的优缺点
RNN虽然理论上可以很漂亮的解决序列数据的训练,但是它也像DNN一样有梯度消失,梯队爆炸的问题,当序列很长的时候问题尤其严重。因此,上面的RNN模型一般不能直接用于应用领域。在语音识别,手写书别以及机器翻译等NLP领域实际应用比较广泛的是基于RNN模型的一个特例LSTM。
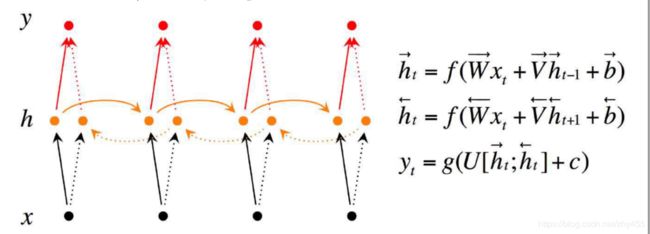
2. 双向RNN
双向RNN使用的场景:有些情况下,当前的输出不只依赖于之前的序列元素,还可能依赖之后的序列元素; 比如做完形填空,机器翻译等应用。
3. 针对梯度爆炸,梯度消失的解决
RNN虽然理论上可以很漂亮的解决序列数据的训练,但是它也像DNN一样有梯度消失,梯队爆炸的问题,当序列很长的时候问题尤其严重。因此,上面的RNN模型一般不能直接用于应用领域。在语音识别,手写书别以及机器翻译等NLP领域实际应用比较广泛的是基于RNN模型的一个特例LSTM。
4. LSTM及GRU
4.1 LSTM
如果我们略去RNN每层都有的o(t),L(t),y(t),则RNN的模型可以简化成如下图的形式:
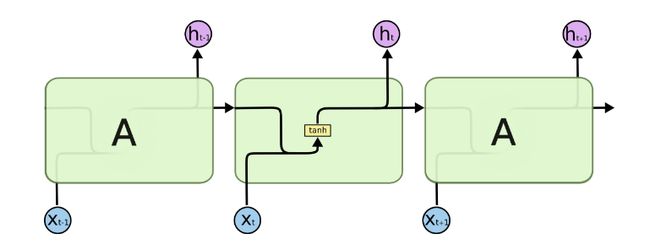
图中可以很清晰看出在隐藏状态h(t)由x(t)和h(t−1)得到。得到h(t)后一方面用于当前层的模型损失计算,另一方面用于计算下一层的h(t+1)。.由于RNN存在梯度消失的问题,大牛们对于序列索引位置t的隐藏结构做了改进,可以说通过一些技巧让隐藏结构复杂了起来,来避免梯度消失的问题,这样的特殊RNN就是我们的LSTM。LSTM的结构如下图: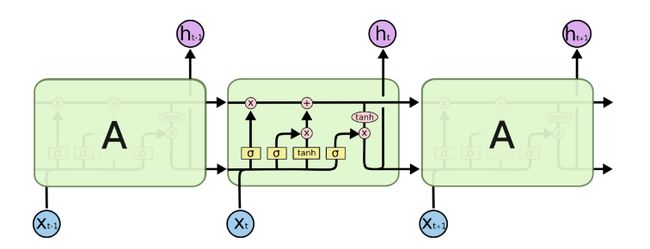
4.1.1 LSTM之遗忘门
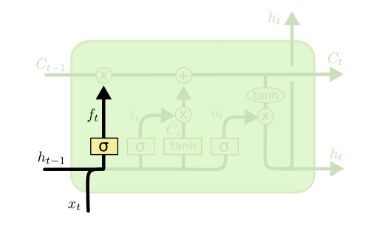
![]()
![]() 为线性关系的系数和偏倚,和RNN中的类似。σ为sigmoid激活函数。
为线性关系的系数和偏倚,和RNN中的类似。σ为sigmoid激活函数。
4.1.2 LSTM之输入门

第一部分使用了sigmoid激活函数,第二部分使用了tanh激活函数, 两者的结果后面会相乘再去更新细胞状态。用数学表达式即为:
![]()
![]()
![]() 为线性关系的系数和偏倚,和RNN中的类似。σ为sigmoid激活函数。
为线性关系的系数和偏倚,和RNN中的类似。σ为sigmoid激活函数。
4.1.3 LSTM之细胞状态更新
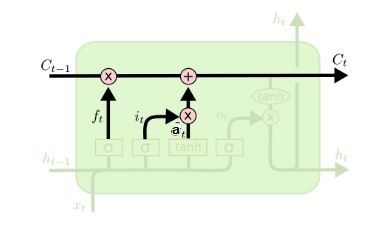
细胞状态C(t)由两部分组成,第一部分是C(t−1)和遗忘门输出f(t)的乘积,第二部分是输入门的i(t)和a(t)的乘积
![]()
其中,⊙⊙为Hadamard积。
4.14 LSTM之输出门
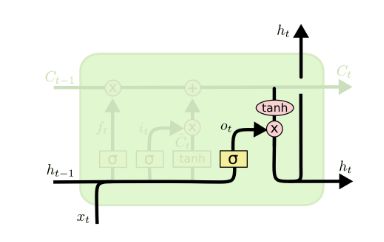
隐藏状态h(t)的更新由两部分组成,第一部分是o(t), 它由上一序列的隐藏状态h(t−1)和本序列数据x(t),以及激活函数sigmoid得到,第二部分由隐藏状态C(t)和tanh激活函数组成, 即:
![]()
![]()
4.2 GRU
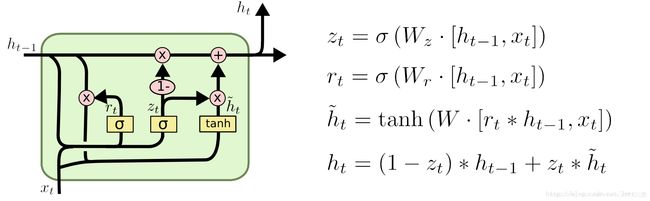
其中, rt表示重置门,zt表示更新门。
1重置门rt决定是否将之前的状态忘记。(作用相当于合并了 LSTM 中的遗忘门和传入门)
2将先前隐藏状态ht-1和遗忘门输出的向量进行点乘。当rt趋于0的时候,前一个时刻的状态信息ht−1会被忘掉,隐藏状态会被重置为当前输入的信息。
3得到了新的隐藏状态ĥ , 但是还不能直接输出,而是通过更新门来控制最后的输出:ht=(1−zt)∗ht−1+zt∗ĥ t
5. Text-RNN的原理

6. 利用Text-RNN进行文本分类的keras实现
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import *
import numpy as np
# from tensorflow.keras.layers import Input, Dense
imdb = keras.datasets.imdb
(train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words=10000)
############################
# explore data
print("Training entries: {}, labels: {}".format(len(train_data), len(train_labels)))
# >> Training entries: 25000, labels: 25000
print(train_data[0])
# >>
print(len(train_data[0]), len(train_data[1]))
############################
# 将整数转换回字词:了解如何将整数转换回文本可能很有用。在以下代码中,我们将创建一个辅助函数来查询包含整数到字符串映射的字典对象:
# A dictionary mapping words to an integer index
word_index = imdb.get_word_index()
# The first indices are reserved
word_index = {k: (v + 3) for k, v in word_index.items()}
word_index[""] = 0
word_index[""] = 1
word_index[""] = 2 # unknown
word_index[""] = 3
reverse_word_index = dict([(value, key) for (key, value) in word_index.items()])
def decode_review(text):
return ' '.join([reverse_word_index.get(i, '?') for i in text])
# 现在,我们可以使用 decode_review 函数显示第一条影评的文本:
print(decode_review(train_data[0]))
####################################
# prepare data
# 我们可以填充数组,使它们都具有相同的长度,然后创建一个形状为 max_length * num_reviews 的整数张量。我们可以使用一个能够处理这种形状的嵌入层作为网络中的第一层。
# 使用 pad_sequences 函数将长度标准化
train_data = keras.preprocessing.sequence.pad_sequences(train_data,
value=word_index[""],
padding='post',
maxlen=256)
test_data = keras.preprocessing.sequence.pad_sequences(test_data,
value=word_index[""],
padding='post',
maxlen=256)
# now, the len of data is 256
print(train_data[0])
##########################################
#### stucture the model
convs = []
inputs = keras.layers.Input(shape=(256,))
embed1 = keras.layers.Embedding(10000, 32)(inputs)
bilstm = keras.layers.Bidirectional(keras.layers.LSTM(20, return_sequences=False))(embed1)
out = keras.layers.Dropout(0.5)(bilstm)
# output = keras.layers.Dense(32, activation='relu')(out)
pred = keras.layers.Dense(units=1, activation='sigmoid')(out)
model = keras.models.Model(inputs=inputs, outputs=pred)
# adam = optimizers.Adam(lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=1e-08, decay=0.0)
model.summary()
model.compile(loss="binary_crossentropy", optimizer="adam", metrics=['accuracy'])
# validation data
x_val = train_data[:10000]
partial_x_train = train_data[10000:]
y_val = train_labels[:10000]
partial_y_train = train_labels[10000:]
# fit
history = model.fit(partial_x_train, partial_y_train, batch_size=512,
epochs=40,
validation_data=(x_val, y_val),
verbose=1)
# evalute model
results = model.evaluate(test_data, test_labels)
print(results)
# predict data
predictions = model.predict(test_data)
##################################################################
# 创建准确率和损失随时间变化的图
# model.fit() 返回一个 History 对象,该对象包含一个字典,其中包括训练期间发生的所有情况:
history_dict = history.history
print(history_dict.keys())
# >>dict_keys(['loss', 'val_loss', 'val_acc', 'acc'])
# 可以使用这些指标绘制训练损失与验证损失图表以进行对比,并绘制训练准确率与验证准确率图表:
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
##########-------------画图方式1-----------------
# # "bo" is for "blue dot"
# plt.plot(epochs, loss, 'bo', label='Training loss')
# # b is for "solid blue line"
# plt.plot(epochs, val_loss, 'b', label='Validation loss')
# plt.title('Training and validation loss')
# plt.xlabel('Epochs')
# plt.ylabel('Loss')
# plt.legend()
#
# plt.show()
# # -----------------------------------------
# plt.clf() # clear figure
# acc_values = history_dict['acc']
# val_acc_values = history_dict['val_acc']
#
# plt.plot(epochs, acc, 'bo', label='Training acc')
# plt.plot(epochs, val_acc, 'b', label='Validation acc')
# plt.title('Training and validation accuracy')
# plt.xlabel('Epochs')
# plt.ylabel('Accuracy')
# plt.legend()
# plt.show()
#######--------画图方式2-------------------
# fig = plt.figure()
# ax = plt.subplot(1,2,1)
# plt.plot(epochs, loss, 'bo', label='Training loss')
# plt.plot(epochs, val_loss, 'b', label='Validation loss')
# plt.title('Training and validation loss')
# plt.xlabel('Epochs')
# plt.ylabel('Loss')
# plt.legend()
#
# ax2 = plt.subplot(1,2,2)
# acc_values = history_dict['acc']
# val_acc_values = history_dict['val_acc']
#
# plt.plot(epochs, acc, 'bo', label='Training acc')
# plt.plot(epochs, val_acc, 'b', label='Validation acc')
# plt.title('Training and validation accuracy')
# plt.xlabel('Epochs')
# plt.ylabel('Accuracy')
# plt.legend()
#
# plt.show()