MySQL-DQL基础学习
文章目录
- DQL
- 一.基础查询
- 二.条件查询
- 三.排序查询
- 四.常见函数
- 4.1 字符函数
- 4.2 数学函数
- 4.3日期函数
- 4.4 其他函数
- 4.5 流程控制函数
- 4.6分组函数
- 五.分组查询
- 六.连接查询 多表查询 ⚠️
- 七. 子查询
- 八.分页查询
- 九. 联合查询
DQL
DQL
数据查询语言:Data Query Language
一.基础查询
SELECT 列表 FROM 表名;
特点:
查询列表可以是:表中的字段、常量、表达式、函数。
单个字段:
select 列表 from 表名;
多个字段:
select 列表1,列表2 … from 表名;
所有字段:
select * from 表名;
常量:
select 100;
select jack;
表达式:
select 100*9;
函数:
select version();
concat (first_name, last_name) as 姓名;
ifnull(可能为空的值,为空显示值); - - 调用方法
起别名:
1.select 原列表 as 新列表 from 表名; - -便于理解;查询字段有重复时,方便区别
2.select 原列表 新列表 from 表名;
去重:
select distinct 列表 from 表名;
+号作用:
select first_name + last_name as 姓名 from 表名; - -同个类型数据;
1.select 100+90; 两个操作数都为数值型,则做加法运算
2.select '123'+90; 其中一方为字符型,试图将字符型数值转换成数值型
如果转换成功,则继续做加法运算
select 'john'+90; 上如果转换失败,则将字符型数值转换成0
3.select null+10; 只要其中一方为null, 则结果肯定为null
二.条件查询
SELECT 列表 FROM 表名 WHERE 筛选条件;
分类:
1.按条件表达式筛选
简单条件运算符:
> < = !<>(不等于) >= <=
2.按逻辑表达式筛选
逻辑运算符:
&& | | !
and or not
3.模糊查询
通配符:
% 任意多个字符,包含0个%
_ 任意单个字符
like
between and
in
is null / is not null – > 不能只null
例子:
select last_name from employees where last_name like ‘_\_%’ ;
select last_name from employees where last_name like ‘_$_%’ ESCAPE ‘$’; - - $为转义字符
select * from employees where id <= 100 and id >= 50;
select * from employees where id between 50 and 100; - -between 包含临界值;小到大
select job_id from employees where job_id =‘IT’ or ‘ABC’ or …;
select job_id from employees where job_id in(‘IT’,’ABC’,…); - - in函数相当 =
安全等于<=>
select last_name from employees where last_name is null;
select last_name from employees where last_name <=> null;
is null pk <=>
Is NULL:仅仅可以判断NULL值,可读性较高,建议使用
<=> :既可以判断NULL值,又可以判断普通的数值,可读性较低
三.排序查询
SELECT 列表 FROM 表名 [ WHERE 筛选条件 ] order by 排序列表 [ asc | desc ] #默认升序
order by 支持别名:
#中文长度 排序用到length ( ) ;
select length( last_name ) 字节长度, last_name, salary
from employees
order by 字节长度 DESC;
支持多个字段排序:
select *
from employees
order by salary ASC, employee_id DESC;
四.常见函数
SELECT 函数名(实参列表) [ from 表名 ]
分类:
- 单行 如concat、length、ifnull等
- 分组函数 做统计使用,又叫统计函数、聚集函数、组函数
4.1 字符函数
-
length(‘John’) ; ->输出: 4 -> 中文3个字节 英文1个
-
concat 拼接字符
-
upper() lower() 大小写
-
substr / substring 截取函数
索引从1开始
select substr (’1234’ , 2); -> 234 -> 第2个开始
select substr(‘123456’ , 1 , 3); -> 123 -> 第1个开始,第3个结束 -
instr( )
select instr (’1234’ , 2); -> 2 放回字串第一次出现的位置; 无返回0 -
trim ( )去前后空格/指定字符
select trim(’a’ from ‘aaaaaaaBaaBaaaaaaa’); -> BaaB -
lpad( ) 用指定字符实现左填充制定长度
select lapd( ’123’ , 5 , ‘*’ ); -> 123 -
rpad( ) 右填充
-
replace (‘ A ’ , ’ B ’ ) B替换 A
4.2 数学函数
-
round() 四舍五入
round( 1.5 ) -> 2
round (1.234 , 2) ->1.23 -
Ceil ( ) 向上取整,返回>= 该参数的最小整数
seil ( - 1.02 ) -> -1 -
floor ( ) 向下取整,返回<= 该参数的最小大整数
floor ( 9.99 ) -> 9
floor ( -9.99 ) -> -10 -
truncate ( ) 截断
truncate ( 1.6777777 , 1); -> 1 -
Mod ( ) 取余 = % = a-a/b*b
-
rand ( ) 随机获取数,返回0-1之间的小数
4.3日期函数
-
Now 返回当前系统日期+时间
-
curdate 返回日期,不包含时间
-
curtime 返回时间,不包含日期
-
指定年月日时分秒, year、month/ monthname 、 day …
datediff:返回俩天的差
monthname:返回英语形式的月份
-
格式化输入日期
select * from employees where hiredate = STR_TO_DATE (‘4-3 1992’ , ‘%c-%d %Y’ );


4.4 其他函数
- version()
- database()
- user()
4.5 流程控制函数
-
if 、 if else
select if(10 < 5, ‘ T ’ , ‘ F ‘); -> F -
case 用法一:
case department_id; - - 要判断的字段或表达式
when 条件1 then 要显示的值1或语句1
when 40 then salary * 1.2;
when 50 then salary * 1.3;
else salary
end as 新工资
from employees;
SELECT
CASE WHEN salary <= 500 THEN '1'
WHEN salary > 500 AND salary <= 600 THEN '2'
WHEN salary > 600 AND salary <= 800 THEN '3'
WHEN salary > 800 AND salary <= 1000 THEN '4'
ELSE NULL END salary_class, -- 别名命名
COUNT(*)
FROM Table_A
- case 用法二: 类似 多重 if
case
when 条件1 then 要显示的值1或语句1
when salary > 500 then ‘ A ’
when salary > 300 then ‘ B ’
…
else 要显示的值n或者语句n
end
4.6分组函数
用于统计,又叫聚合函数活统计函数或组函数
-
sum 、 avg 平均值 、 max 、min 、 count
sum 、 avg 一般用于处理数值型
max 、 min 、 count 可以处理任何类型 -
都忽略null值
-
可以和distinct 搭配实现去重运算
-
Count函数的单独介绍
一般用count(*)用作统计行数
count(*)统计结果集的行数
count(字段)统计该极端非空值的个数
count(1):也是统计结果集的行数
效率上:
MyISAM存储引擎,count(*)最高
InnoDB存储引擎,count(*)- count(1)> count(字段) -
和分组函数一起查询的字段,要求是group by 后的字段
select sum( salary ) from employees;
五.分组查询
语法:
select 查询列表
from 表名
where 筛选条件
group by 分组列表
having 分组后筛选
order by 排序列表;
- 执行顺序:
- from子句
- where 子句
- group by 子句
- having 子句
- select 子句
- oder by 子句
1.查询列表往往是,分组函数和被分组的字段
2.分组查询中的筛选分为俩类
| 筛选的基表 | 关键词 | 位置 |
|---|---|---|
| 分组前筛选 | 原始表 | where — group by前面 |
| 分组后筛选 | 分组后的结果集 | having — group by后面 |
Where - group by - having
组函数的条件只能放在having 后面!!!!!
每个部门的总工资
select sum( salary ), department_id
from employees
group by department_id;
六.连接查询 多表查询 ⚠️
笛卡尔乘积 , 一对多
按年代分类:
sq192标准:仅仅支持内连接
sq199标准【推荐】:支持内连接+外连接(左外和右外) +交叉连接按功能分类:
内连接: 等值连接
非等值连接
自连接
外连接: 左外连接
右外连接
全外连接(mysql不支持)
交叉连接
———————SQL92————————
1.等值连接
select 查询列表
from 表1 别名1 , 表2 别名2….
where 等值连接的连接条件 表1.key = 表2.key
【and 筛选条件】
【group by 分组字段】
【having 分组后筛选】
【order by 排序字段】
特点:
为了解决多表中字段同名问题,往往为表其别名
表的顺序无要求
n表连接至少需要n-1个连接条件
等值连接的结果是多表的交集部分
2.非等值连接
select 查询列表
from 表1 别名1 , 表2 别名2….
where 非等值连接的连接条件 表1.key != 表2.key
【and 筛选条件】
【group by 分组字段】
【having 分组后筛选】
【order by 排序字段】
3.自连接
select 查询列表
from 表1 别名1 , 表1 别名2….
where 等值连接的连接条件 表1.key = 表1.key
【and 筛选条件】
【group by 分组字段】
【having 分组后筛选】
【order by 排序字段】
———————SQL99————————
语法:
select 查询列表
from 表1 别名1
连接类型】 join 表2 别名2
on 连接条件
【where 筛选条件 表1.key = 表2.key】
【and 筛选条件】
【group by 分组字段】
【having 分组后筛选】
【order by 排序字段】
内连接: inner
外连接: 左外连接:left【outer】
右外连接:right【outer】
全外连接(mysql不支持): full【outer】
交叉连接: corss
I.内连接 inner
select 查询列表
from 表1 别名1
inner join 表2 别名2
on 连接条件
【where 筛选条件 表1.key = 表2.key】
【and 筛选条件】
【group by 分组字段】
【having 分组后筛选】
【order by 排序字段】
分类:等值连接 非等值连接 自连接
1.等值连接
特点:
- 添加排序、分组、筛选
- inner 可以省略
- 筛选条件放在where后面,连接条件放在on后面,提高分离性
- inner join连接和sql92语法中的等值连接效果是一样的,都是查询多表的交集
2.非等值连接 3.自连接
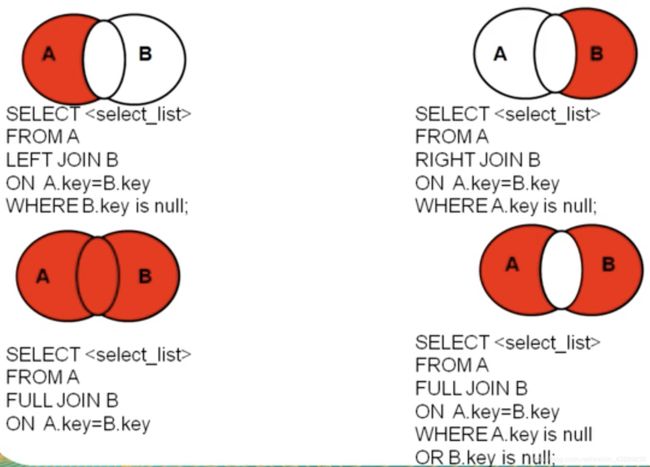
II.外连接 left
用于查询一个表中有,另一个中没有的记录
特点:
-
外连接的查询结果为主表中的所有记录
如果从表中有和它匹配的,则显示匹配值
如果从表中没有和它匹配的,则显示null
外连接查询结果 = 内连接+主表中有而从表中没有的记录 -
左外链接,左边是主表; 右外链接 同理
-
全外连接 = 内连接结果 + 表1中有的表2没的 + 表2有的表1没有的
mysql不支持
显示交集部分
III.交叉连接 cross = 笛卡尔乘积

七. 子查询
出现在其他语句中的select语句,叫做自查询或内查询
外部的查询语句,叫做主查询或外查询
分类:
按子查询出现的位置:
- select后面:
仅仅支持标量子查询 - from后面:
支持表子查询 - where.或having后面:★
标量子查询(单行) V
列子查询(多行)V
行子查询 - exists后面(相关子查询)
表子查询. - 按结果集的行列数不同:
标量子查询(结果集只有一行一列)
列子查询(结果集只有一列多行)
行子查询(结果集有一行多列)
表子查询(结果集一般为多行多列)
一、where或having后 面
- 标量子查询(单行子查询)
- 列子查询(多行子查询)
- 行子查询(一行多列)
特点:
①子查询放在小括号内
②子查询一般放在条件的右侧
③标量子查询,一般搭配着单行操作符使用
><>=:<==<>
1、列子查询,一般搭配着多行操作符使用
in/not in : 等于列表中的任意一个
any/some:和子查询返回的某一个值比较。可以替换成min
all : 和子查询返回的所有值比较。可以替换成max
④子查询的执行优先于主查询执行,主查询的条件用到了子查询的结果
案例1:谁的工资比Abel高?
①查询Abe1的工资
SELECT salary
FROM employees
WHERE last_ name = ' Abel '
②查询员工的信息,满足salary>①结果
SELECT *
FROM employees
WHERE salary> (
SELECT salary
FROM employees
WHERE last_ name = ' Abel '
) ;
二:select后面
仅仅支持标量子查询
三、from后面
将自查询结果充当一张表,要求必须起别名
四、exists后面(相关子查询)
select exists (select employ_id from employees);
查询是否存在 布尔类型1和0
八.分页查询
应用场景:要显示数据,一页显示不全,需要分页提交sql请求
特点:
limit语句放在查询语句的最后
公式:
要显示页数page,每页条目size
limit (page - 1)*size,size
语法:
select 查询列表
from 表1 别名1
[ join type] 表2 别名2
on 连接条件
[where 筛选条件 表1.key = 表2.key
[and 筛选条件
[group by 分组字段
[having 分组后筛选
[order by 排序字段
limit [ offset ], size;
offset要显示条目的起始索引(从0开始
size 要显示的条目个数
九. 联合查询
Union 联合 合并:将多条查询语句的结果合并成一个结果
语法:
查询语句1
union
查询语句2
union
…
应用场景:要查询的结果来自于多个表,且多个表没有直接连接关系,且查询信息一致时
特点:
- 要求多条查询语句的查询的类型和列数是一样的
- 要求多条查询语句的查询的每一列的类型和顺序最好一致
- 会自动去重复; union all 不去重复