hive/spark-sql经典笔试面试题(一)累加计算
问题描述
在数据仓库中有这样一张表,记录了每个月的营业额,数据如下:
表名:test:
字段:1、month ;2、money

需要统计截止到每个月份的营业总额,如:
截止到2019年1月份营业总额为10元
截止到2019年2月份营业总额为10+10=20元
截止到2019年3月份营业总额为10+10+10=30元
以此类推…
先贴出最终结果的样子:

方案 一 简单粗暴计算
直接使用where条件过滤符合的数据,使用sum函数进行计算
select sum(money) from test where month='201901'
union all
select sum(money) from test where month<='201902'
union all
select sum(money) from test where month<='201903'
……
优点:这是最容易想到的解决方法,实现起来又方便
缺点:此方法虽能解决问题,可略显笨重,且同一张表扫描次数过多,执行速度缓慢,不可取。
方案二 巧用case when
无论是mysql还是hive 或者是spark-sql都支持case when,这是一个强大的功能,
配合上sum,count,等聚合函数,可以计算出结果。
select
sum(case when month=201901 then money else null end) as sum_money_01,
sum(case when month<=201902 then money else null end) as sum_money_02,
sum(case when month<=201903 then money else null end) as sum_money_03,
sum(case when month<=201904 then money else null end) as sum_money_04,
sum(case when month<=201905 then money else null end) as sum_money_05,
sum(case when month<=201906 then money else null end) as sum_money_06,
sum(case when month<=201907 then money else null end) as sum_money_07,
sum(case when month<=201908 then money else null end) as sum_money_08,
sum(case when month<=201909 then money else null end) as sum_money_09,
sum(case when month<=201910 then money else null end) as sum_money_10,
sum(case when month<=201911 then money else null end) as sum_money_11,
sum(case when month<=201912 then money else null end) as sum_money_12
from
test
优点:对test表只进行了一次扫描,判断month是属于哪个范围,符合写定范围则进行聚合运算,否则置为null利用sum函数不计算null值的特性,得到我们想要的答案。从某种程度上来说,case when 在此处发挥的是where的功能。
缺点:写法还是有些复杂,这是12个月我们就需要写12个语句,若是需求更加的细化,比如计算一年中截止到每一天的营业额,我们就需要写365个语句,显然是不可能的,可拓展性不高
方案三 使用自连接实现
第一步:将test表自己与自己进行连接,不过条件不是等于,而是大于等于,先列出这样的结果
(为了便于阅读加上了order by 实际上不需要排序)

我们看到离想要的结果已经很接近了,只要按照t0.month进行分组,对t1.money进行聚合,就可以得到想要的答案,
第二步,最终代码
select
t0.month,
sum(t1.money)
from
(select month,money from test)t0
join
(select month,money from test)t1
on t0.month>=t1.month
group by t0.month
优点:此种写法拓展性比较高,不用关心计算粒度多大,都能实现需求
缺点:实际上此处进行的是一种不完全的笛卡尔积,增加了数据量,若数据量比较大的情况下可能会导致执行速度下降。
简单计算一下扩大的倍数,例子中是6条,最终结果需要计算的是1+2+3+4+5+6=21条
若原来是n条数据,最终结果就是1+2+3+…+n=(1+n)*n/2,扩大倍数为(1+n)/2倍
方案四 使用窗口函数
select
month,
sum(money) over(order by month rows between unbounded preceding and current row) as sum_money
from
test
执行结果:
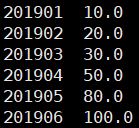
over从句中:
1、可使用partition by语句,使用一个或者多个原始数据类型的列
2、可使用partition by与order by语句,使用一个或者多个数据类型的分区或者排序列
关键是理解rows between含义,也叫做window子句:
preceding:往前
following:往后
current row:当前行
unbounded:无界限(起点或终点)
unbounded preceding:表示从前面的起点
unbounded following:表示到后面的终点
当order by后面缺少窗口从句条件,窗口规范默认是
row between unbounded preceding and current row. (从起点到当前行)
当order by和窗口从句都缺失, 窗口规范默认是
row between unbounded preceding and unbounded following.
(从起点到终点)
此处没有使用partition by语句进行分组,计算的是所有数据,
当计算到201903月份的时候,会从前面的起点(unbounded preceding)累加到当前行( current row)也就是10+10+10=30,这样也就得出了我们想要的结果
优点:写法简单,执行效率最高。而且需求变更,或者数据变化的接受能力都很强
缺点:比较难以理解,需要掌握窗口函数的使用。
关于窗口函数还有更多的用法、更强大的功能,更多详细介绍请移步大佬的博客:
李国冬——Hive常用函数大全(二)(窗口函数、分析函数、增强group)
拓展:
- 如果给的数据是比较细化的数据,比如给定的是每天的数据,需要按月汇总,那就先按照每个月的营业额进行汇总,得到开头那样的数据。
- 如果不是一家的营业额而是多家,比如a商店,b商店,c商店,那就在此基础上进行分组group by
关于累加计算的介绍本篇写了几种解法,可根据需求进行自主选择。
希望大家积极交流共同进步。