开源监控利器Prometheus初探

转载本文需注明出处:微信公众号EAWorld,违者必究。
前言:
Kubernetes作为当下最炙手可热的容器管理平台,在给应用部署运维带来便捷的同时,也给应用及性能监控带来了新的挑战。本文给大家分享一款十分火热的开源监控工具Prometheus,让我们一起来看它是如何兼顾传统的应用监控、主机性能监控和Kubernetes监控的。
目录:
一、Prometheus简介
二、Prometheus架构图
三、Prometheus架构详解
四、Prometheus监控Kubernetes
一、Prometheus简介
什么是Prometheus?
Prometheus是一个开源的系统监控及告警工具,最初建设在SoundCloud。从2012 Prometheus推出以来,许多公司都采用它搭建监控及告警系统。同时,项目拥有非常活跃的开发者和用户社区。
它现在是一个独立于任何公司的开源项目,为了强调这一点并明确项目的管理结构,在2016年Prometheus加入CNCF基金会成为继Kubernetes之后的第二个托管项目。
Prometheus有什么特点?
多维的数据模型(基于时间序列的k/v键值对)。
灵活的查询及聚合语句(PromQL)。
不依赖分布式存储,节点自治。
基于HTTP的pull模式采集时间序列数据。
可以使用pushgateway(prometheus的可选中间件)实现push模式。
可以使用动态服务发现或静态配置采集的目标机器。
支持多种图形及仪表盘。
Prometheus适用场景。
在选择Prometheus作为监控工具前,要明确它的适用范围,以及不适用的场景。
Prometheus在记录纯数值时间序列方面表现非常好。它既适用于以服务器为中心的监控,也适用于高动态的面向服务架构的监控。
在微服务的监控上,Prometheus对多维度数据采集及查询的支持也是特殊的优势。
Prometheus更强调可靠性,即使在故障的情况下也能查看系统的统计信息。权衡利弊,以可能丢失少量数据为代价确保整个系统的可用性。因此,它不适用于对数据准确率要求100%的系统,比如实时计费系统(涉及到钱)。
二、Prometheus构架图

上图是Prometheus的架构图,从图中可以看出Prometheus的架构设计理念,中心化的数据采集,分析。
1. Prometheus Server:Prometheus的核心,根据配置完成数据采集, 服务发现以及数据存储。
2. Pushgateway:为应对部分push场景提供的插件,监控数据先推送到pushgateway上,然后再由server端采集pull。(若server采集间隔期间,pushgateway上的数据没有变化,server将采集2次相同数据,仅时间戳不同)
3. Prometheus targets:探针(exporter)提供采集接口,或应用本身提供的支持Prometheus数据模型的采集接口。
4. Service discovery:支持根据配置file_sd监控本地配置文件的方式实现服务发现(需配合其他工具修改本地配置文件),同时支持配置监听Kubernetes的API来动态发现服务。
5. Alertmanager:Prometheus告警插件,支持发送告警到邮件,Pagerduty,HipChat等。
三、Prometheus架构详解
接下来,让我们一起了解rometheus架构中各个组件是如何协同工作来完成监控任务。
Prometheus server and targets
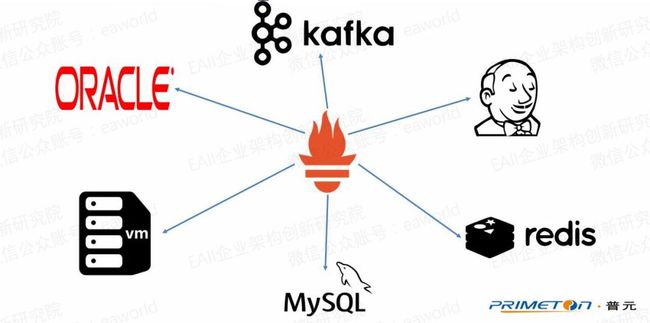
利用Prometheus官方或第三方提供的探针,基本可以完成对所有常用中间件或第三方工具的监控。

之前讲到Prometheus是中心化的数据采集分析,那这里的探针(exporter)是做什么工作呢?
上图中硬件及系统监控探针node exporter通过getMemInfo()方法获取机器的内存信息,然后将机器总内存数据对应上指标node_memory_MemTotal。
Jenkins探针Jenkins Exporter通过访问Jenkins的api获取到Jenkins的job数量并对应指标Jenkins_job_count_value。
探针的作用就是通过调用应用或系统接口的方式采集监控数据并对应成指标返回给prometheus server。(探针不一定要和监控的应用部署在一台机器)
总的来说Prometheus数据采集流程就是,在Prometheus server中配置探针暴露的端口地址以及采集的间隔时间,Prometheus按配置的时间间隔通过http的方式去访问探针,这时探针通过调用接口的方式获取监控数据并对应指标返回给Prometheus server进行存储。(若探针在Prometheus配置的采集间隔时间内没有完成采集数据,这部分数据就会丢失)
Prometheus alerting
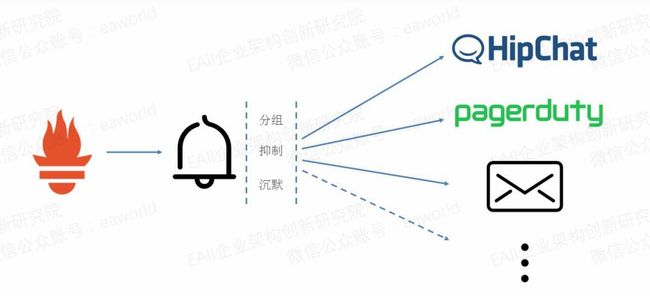
Prometheus serve又是如何根据采集到的监控数据配和alertmanager完成告警呢?
举一个常见的告警示例,在主机可用内存低于总内存的20%时发送告警。我们可以根据Prometheus server采集的主机性能指标配置这样一条规则node_memory_Active/node_memory_MemTotal < 0.2,Prometheus server分析采集到的数据,当满足该条件时,发送告警信息到alertmanager,alertmanager根据本地配置处理告警信息并发送到第三方工具由相关的负责人接收。
Prometheus server在这里主要负责根据告警规则分析数据并发送告警信息到alertmanager,alertmanager则是根据配置处理告警信息并发送。
Alertmanager又有哪些处理告警信息的方式呢?
分组:将监控目标相同的告警进行分组。如发生停电,收到的应该是单一信息,信息中包含所有受影响宕机的机器,而不是针对每台宕机的机器都发送一条告警信息。
抑制:抑制是指当告警发出后,停止发送由此告警引发的其他告警的机制。如机器网络不可达,就不再发送因网络问题造成的其他告警。
沉默:根据定义的规则过滤告警信息,匹配的告警信息不会发送。
Service discovery
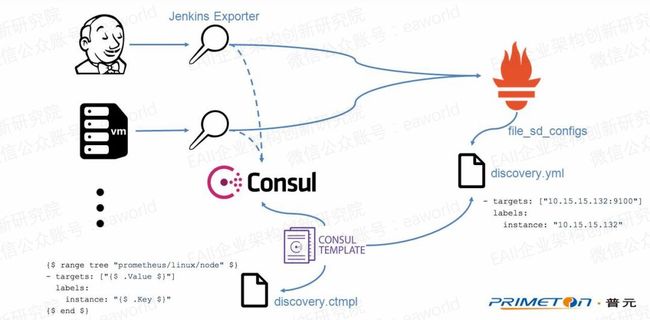
Prometheus支持多种服务发现的方式,这里主要介绍架构图中提到的file_sd的方式。之前提到Prometheus server的数据采集配置都是通过配置文件,那服务发现该怎么做?总不能每次要添加采集目标还要修改配置文件并重启服务吧。
这里使用file_sd_configs指定定义了采集目标的文件。Prometheus server会动态检测该配置文件的变化来更新采集目标信息。现在只要能更新这个配置文件就能动态的修改采集目标的配置了。
这里采用consul+consul template的方式。在新增或减少探针(增减采集目标)时在consul更新k/v,如新增一个探针,添加如下记录Prometheus/linux/node/10.15.15.132=10.15.15.132:9100,然后配置consul template监控consul的Prometheus/linux/node/目录下k/v的变化,根据k/v的值以及提前定义的discovery.ctmpl模板动态生成Prometheus server的配置文件discovery.yml。
Web UI
至此,已经完成了数据采集和告警配置,是时候通过页面展示一波成果了。
Grafana已经对Prometheus做了很好的支撑,在Grafana中添加Prometheus数据源,然后就可以使用PromQL查询语句结合grafana强大的图形化能力来配置我们的性能监控页面了。
联邦模式

中心化的数据采集存储,分析,而且还不支持集群模式。带来的性能问题显而易见。Prometheus给出了一种联邦的部署方式,就是Prometheus server可以从其他的Prometheus server采集数据。
可能有人会问,这样最后的数据不是还是要全部汇集到Prometheus的global节点吗?
并不是这样的,我们可以在shard节点就完成分析处理,然后global节点直接采集分析处理过的数据进行展示。
比如在shard节点定义指标可用内存占比job:memory_available:proportion的结果为(node_memory_MemFree + node_memory_Buffers + node_memory_Cached)/node_memory_MemTotal,这样在shard节点就可以完成聚合操作,然后global节点直接采集处理过的数据就可以了,而不用采集零散的如node_memory_MemFree这类指标。
四、Prometheus监控Kubernetes
Kubernetes官方之前推荐了一种性能监控的解决方案,heapster+influxdb,heapster根据定义的间隔时间从Advisor中获取的关于pod及container的性能数据并存储到时间序列数据库influxdb。
也可以使用grafana配置influxdb的数据源并配置dashboard来做展现。而且Kubernetes中pod的自动伸缩的功能(Horizontal Pod Autoscaling)也是基于heapster,默认支持根据cpu的指标做动态伸缩,也可以自定义扩展使用其他指标。
但是Heapster无法做Kubernetes下应用的监控。现在,Heapster作为Kubernetes下的开源监控解决方案已经被其弃用(https://github.com/kubernetes/heapster),Prometheus成为Kubernetes官方推荐的监控解决方案。
Prometheus同样通过Kubernetes的cAdvisor接口(/api/v1/nodes/${1}/proxy/metrics/cadvisor)获取pod和container的性能监控数据,同时可以使用Kubernetes的Kube-state-metrics插件来获取集群上Pod, DaemonSet, Deployment, Job, CronJob等各种资源对象的状态,这反应了使用这些资源的应用的状态。
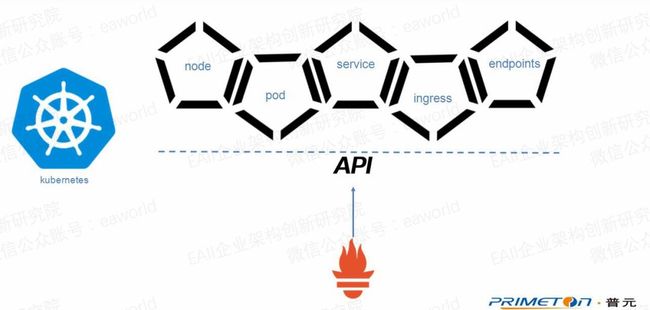
同时通过Kubernetes api获取node,service,pod,endpoints,ingress等服务的信息,然后通过匹配注解中的值来获取采集目标。
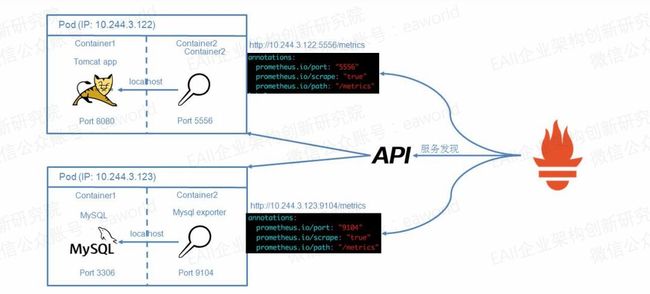
上面提到了Prometheus可以通过Kubernetes的api接口实现服务发现,并将匹配定义了annotation参数的pod,service等配置成采集目标。那现在要解决的问题就是探针到应用部署配置问题了。
这里我们使用了Kubernetes的pod部署的sidecar模式,单个应用pod部署2个容器,利用单个pod中仅共享网络的namespace的隔离特性,探针与应用一同运行,并可以使用localhost直接访问应用的端口,而在pod的注解中仅暴露探针的端口(prometheus.io/port: “9104”)即可。
Prometheus server根据配置匹配定义注解prometheus.io/scrape: “true”的pod,并将pod ip和注解中定义的端口(prometheus.io/port: “9104”)和路径(prometheus.io/path: “/metrics”)拼接成采集目标http://10.244.3.123:9104/metrics。通过这种方式就可以完成动态添加需要采集的应用。
精选提问:
问1:Prometheus webui 和 Grafana的界面是独立分开的,还是集成在一起的?
答:是独立页面。
问2:独立页面的话,那用户需要登录两个界面系统?
答:Prometheus自带的界面比较简单,一般是用Grafana做页面展示。Prometheus的界面可以查看采集目标,指标,和做简单的页面展现。
问3:微课堂中提到的缺点,消耗资源偏大。(在Prometheus2.0版本有所改善)。这个偏大有量化的指标吗?
答:之前1.7版本的时候使用时,一台4C8G的机器,十多个采集目标,然后用Grafana做查询展现发现CPU会占用比较高。大概70%。
问4:Prometheus和传统zabbix有哪些优势?
答:zabbix在传统的监控中使用比较普遍,倒也说不上Prometheus有什么优势。Prometheus在Kubernetes的监控应该是有很大优势的。
 关于作者:张子康,普元研发工程师,曾参与神华灾备云平台、万达DevOps平台等项目。对云计算相关技术有浓厚的兴趣,熟悉IaaS,k8s,docker等技术,在DevOps项目中主要负责集成环境的搭建以及部署功能的底层实现。
关于作者:张子康,普元研发工程师,曾参与神华灾备云平台、万达DevOps平台等项目。对云计算相关技术有浓厚的兴趣,熟悉IaaS,k8s,docker等技术,在DevOps项目中主要负责集成环境的搭建以及部署功能的底层实现。
 关于EAWorld:微服务,DevOps,数据治理,移动架构原创 技术分享
关于EAWorld:微服务,DevOps,数据治理,移动架构原创 技术分享
课程预告! 7月24日(下周二)下午14:30 普元测试开发工程师卢亚婷为大家分享《BDD下的自动化测试框架》,回复此公众号“YG+微信号”马上入群!
