hadoop的部署
1.hadoop本地部署
1.建立hadoop用户,并且设置密码
[root@server5 ~]# useradd -u 1000 hadoop
[root@server5 ~]# passwd hadoop
2.以hadoop用户使用hadoop与java的压缩包
[root@server5 ~]# ls
hadoop-3.0.3.tar.gz jdk-8u181-linux-x64.tar.gz
[root@server5 ~]# mv * /home/hadoop
[root@server5 ~]# su - hadoop
[hadoop@server5 ~]$ ls
hadoop-3.0.3.tar.gz jdk-8u181-linux-x64.tar.gz
[hadoop@server5 ~]$ tar zxf jdk-8u181-linux-x64.tar.gz
[hadoop@server5 ~]$ ln -s jdk1.8.0_181/ java
[hadoop@server5 ~]$ tar zxf hadoop-3.0.3.tar.gz
[hadoop@server5 ~]$ ln -s hadoop-3.0.3 hadoop
3.在hadoop的配置文件中添加java的路径
[hadoop@server5 ~]$ cd /home/hadoop/hadoop/etc/hadoop
[hadoop@server5 hadoop]$ vim hadoop-env.sh
54 export JAVA_HOME=/home/hadoop/java
4.配置java的环境变量
[hadoop@server5 hadoop]$ cd
[hadoop@server5 ~]$ vim .bash_profile
10 PATH=$PATH:$HOME/.local/bin:$HOME/bin:$HOME/java/bin
[hadoop@server5 ~]$ source .bash_profile
[hadoop@server5 ~]$ jps
1576 Jps
5.测试
[hadoop@server5 ~]$ cd /home/hadoop/hadoop
[hadoop@server5 hadoop]$ mkdir input
[hadoop@server5 hadoop]$ cp etc/hadoop/*.xml input/
[hadoop@server5 hadoop]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.0.3.jar grep input/ output 'dfs[a-z.]+'
[hadoop@server5 hadoop]$ cd output/
[hadoop@server5 output]$ ls
part-r-00000 _SUCCESS

2.伪分布式
1编辑配置文件
[hadoop@server5 output]$ cd /home/hadoop/hadoop/etc/hadoop
[hadoop@server5 hadoop]$ vim core-site.xml
19
20
21 fs.defaultFS
22 hdfs://localhost:9000
23
24
[hadoop@server5 hadoop]$ vim hdfs-site.xml
19
20
21 dfs.replication
22 1
23
24
2.对本机及其相关本机相关域名生成钥匙做免密连接
[hadoop@server5 hadoop]$ ssh-keygen
[hadoop@server5 hadoop]$ ssh-copy-id localhost
[hadoop@server5 hadoop]$ ssh-copy-id server5
3.格式化namenode节点并且开启hdfs服务
[hadoop@server5 hadoop]$ cd /home/hadoop/hadoop
[hadoop@server5 hadoop]$ bin/hdfs namenode -format
[hadoop@server5 hadoop]$ cd sbin/
[hadoop@server5 sbin]$ ./start-dfs.sh ##开启服务之后会生成相应的节点
Starting namenodes on [localhost]
Starting datanodes
Starting secondary namenodes [server5]
[hadoop@server5 sbin]$ jps
3090 Jps
2949 SecondaryNameNode
2649 NameNode
2763 DataNode
浏览器查看http://172.25.32.5:9870

- 测试
[hadoop@server5 hadoop]$ cd /home/hadoop/hadoop
[hadoop@server5 hadoop]$ bin/hdfs dfs -mkdir -p /user/hadoop
[hadoop@server5 hadoop]$ bin/hdfs dfs -ls
[hadoop@server5 hadoop]$ bin/hdfs dfs -put input
[hadoop@server5 hadoop]$ bin/hdfs dfs -ls
Found 1 items
drwxr-xr-x - hadoop supergroup 0 2019-08-18 17:02 input
网页查看
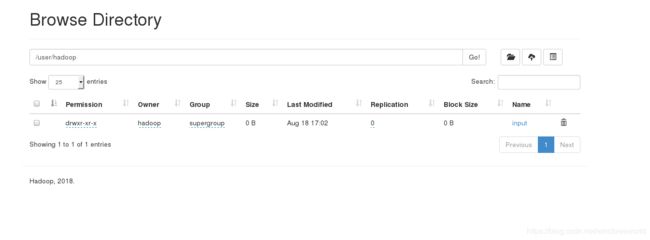
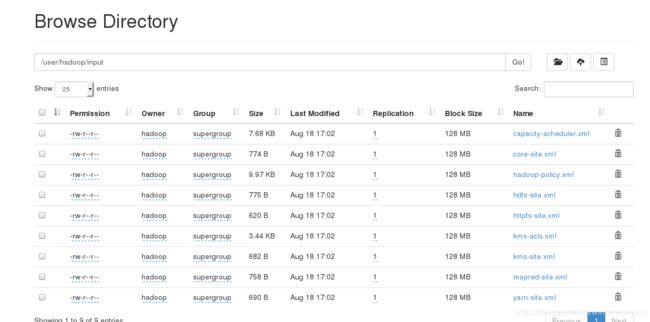
a.删除已经在本机上执行的input和output目录重新进行测试:
[hadoop@server5 hadoop]$ pwd
/home/hadoop/hadoop
[hadoop@server5 hadoop]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.0.3.jar wordcount input output
[hadoop@server5 hadoop]$ bin/hdfs dfs -cat output/*##查看hdfs文件系统上的output的内容
[hadoop@server5 hadoop]$ bin/hdfs dfs -get output##从hdfs文件系统上将output目录获取到本地
[hadoop@server5 hadoop]$ cd output/
[hadoop@server5 output]$ ls
part-r-00000 _SUCCESS
浏览器查看:
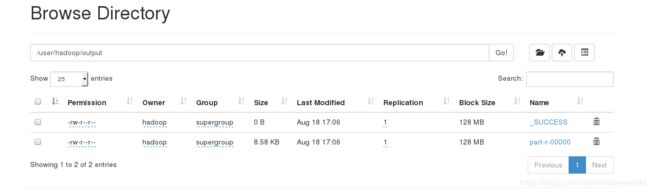
3.分布式hdfs文件系统
1.先停掉hdfs服务并且清除测试时进行相应算法产生的数据,注意算法产生的相应数据都是在/tmp目录下
[hadoop@server5 output]$ cd /home/hadoop/hadoop
[hadoop@server5 hadoop]$ sbin/stop-dfs.sh
Stopping namenodes on [localhost]
Stopping datanodes
Stopping secondary namenodes [server5]
[hadoop@server5 hadoop]$ cd /tmp/
[hadoop@server5 tmp]$ ls
hadoop hadoop-hadoop hsperfdata_hadoop
[hadoop@server5 tmp]$ rm -fr 8
[hadoop@server5 tmp]$ rm -fr *
2.在server5,server6和server7当作节点配置共享nfs文件系统
创建hadoop用户:在实现nfs共享文件的时候的权限共享,必须保持uid/gid一致,方可权限的传递
[root@server6 ~]# useradd hadoop
[root@server6 ~]# id hadoop
uid=1000(hadoop) gid=1000(hadoop) groups=1000(hadoop)
[root@server7 ~]# useradd hadoop
[root@server7 ~]# id hadoop
uid=1000(hadoop) gid=1000(hadoop) groups=1000(hadoop)
server5,server6及server7上安装nfs-utils
[root@server5 ~]# yum install -y nfs-utils
[root@server6 ~]# yum install -y nfs-utils
[root@server7 ~]# yum install -y nfs-utils
三台主机上开启服务
[root@server5 ~]# systemctl start rpcbind
[root@server6 ~]# systemctl start rpcbind
[root@server7 ~]# systemctl start rpcbind
server5(hdfs)上开启nfs服务并且做相应的配置
[root@server5 ~]# systemctl start nfs-server
[root@server5 ~]# vim /etc/exports
[root@server5 ~]# cat /etc/exports
/home/hadoop *(rw,anonuid=1000,anongid=1000)
[root@server5 ~]# exportfs -rv
exporting *:/home/hadoop
[root@server5 ~]# showmount -e
Export list for server5:
/home/hadoop *
3.在server6及其server7上进行nfs文件系统的挂载
[root@server6 ~]# systemctl start rpcbind
[root@server6 ~]# mount 172.25.32.5:/home/hadoop/ /home/hadoop/
server7
[root@server7 ~]# mount 172.25.32.5:/home/hadoop/ /home/hadoop/
挂载成功

4.在server5上对server6及其server7做相应的免密登陆
[hadoop@server5 ~]$ ssh-copy-id 172.25.32.6
[hadoop@server5 ~]$ ssh-copy-id 172.25.32.7
5.编辑server5的hdfs文件系统的配置文件添加服务点口及其修改节点
[hadoop@server5 ~]$ cd /home/hadoop/hadoop/etc/hadoop
[hadoop@server5 hadoop]$ vim core-site.xml
19
20
21 fs.defaultFS
22 hdfs://172.25.32.5:9000
23
24
[hadoop@server5 hadoop]$ vim hdfs-site.xml
19
20
21 dfs.replication
22 2
23
24
[hadoop@server5 hadoop]$ vim workers
[hadoop@server5 hadoop]$ cat workers
172.25.32.6
172.25.32.7
server6查看

server7查看

6.格式化hdfs文件系统并且开启服务
[hadoop@server5 hadoop]$ cd /home/hadoop/hadoop
[hadoop@server5 hadoop]$ bin/hdfs namenode -format
[hadoop@server5 hadoop]$ sbin/start-dfs.sh
[hadoop@server5 hadoop]$ jps
14422 SecondaryNameNode
14551 Jps
14204 NameNode
server6server7查看节点信息


- 测试
[hadoop@server5 hadoop]$ bin/hdfs dfs -mkdir -p /user/hadoop
[hadoop@server5 hadoop]$ bin/hdfs dfs -mkdir input
[hadoop@server5 hadoop]$ bin/hdfs dfs -put etc/hadoop/*.xml input
[hadoop@server5 hadoop]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.0.3.jar grep input/ output 'dfs[a-z.]+'
浏览器查看信息,共两个数据节点
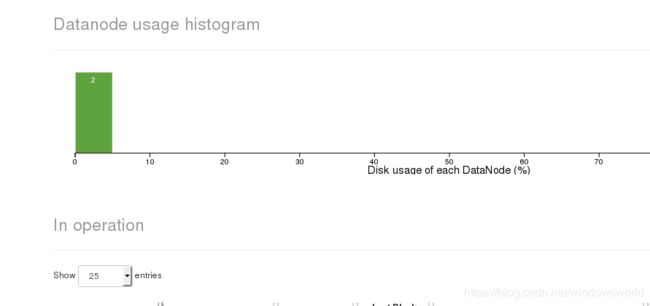
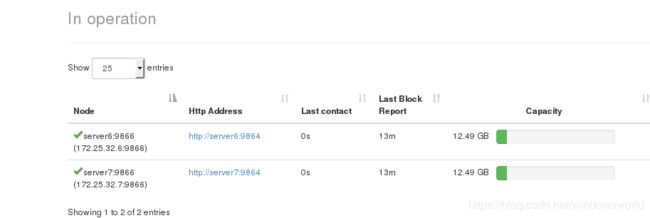
查看文件
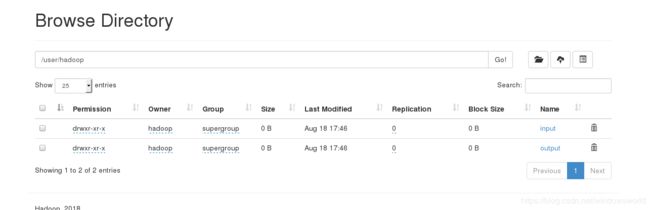
server8作为客户端进行测试:
[hadoop@server5 hadoop]$ ssh-copy-id server8##免秘登陆
[root@server8 ~]# useradd hadoop
[root@server8 ~]# passwd hadoop
[root@server8 ~]# id hadoop
uid=1000(hadoop) gid=1000(hadoop) groups=1000(hadoop)
[root@server8 ~]# yum install -y nfs-utils
[root@server8 ~]# systemctl start rpcbind
[hadoop@server8 ~]$ cd /home/hadoop/hadoop
[hadoop@server8 hadoop]$ bin/hdfs --daemon start datanode
[hadoop@server8 hadoop]$ jps
11165 DataNode
11215 Jps
浏览器查看:
节点添加成功

在客户端server8上上传文件并且在浏览器上查看发现数据上传成功:
[hadoop@server8 hadoop]$ dd if=/dev/zero of=file bs=1M count=500
记录了500+0 的读入
记录了500+0 的写出
524288000字节(524 MB)已复制,30.6657 秒,17.1 MB/秒
[hadoop@server8 hadoop]$ bin/hdfs dfs -put file
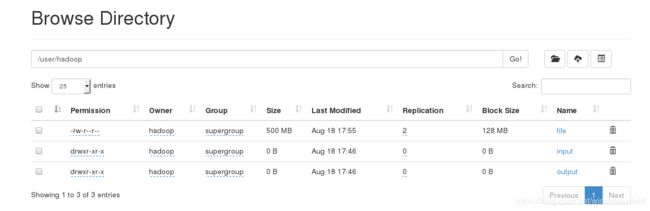
file文件,大小500M上传成功。
4.yarn
[hadoop@server5 hadoop]$ pwd
/home/hadoop/hadoop/etc/hadoop
[hadoop@server5 hadoop]$ vim mapred-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.env-whitelist
JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME
将server8添加到server5服务节点
[hadoop@server5 hadoop]$ vi workers
[hadoop@server5 hadoop]$ cat workers
172.25.32.6
172.25.32.7
172.25.32.8
[hadoop@server5 hadoop]$ cd ../..
[hadoop@server5 hadoop]$ pwd
/home/hadoop/hadoop
[hadoop@server5 hadoop]$ sbin/start-yarn.sh
Starting resourcemanager
Starting nodemanagers
开启yarn后主节点会出现ResourceManager,其余节点出现NodeManager节点



