2019微生物组—宏基因组分析技术研讨会第五期
在广大粉丝的期待下,《生信宝典》联合《宏基因组》在2019年8月2-4日,北京鼓楼推出《宏基因组分析》专题培训第四期,为大家提供一条走进生信大门的捷径、为同行提供一个宏基因组分析学习和交流的机会、助力学员真正理解分析原理和完成实战分析,独创四段式教学(3天集中授课+自行练习2周+再集中讲解答疑+上课视频回看反复练习),“教—练—答—用”四个环节统一协调,真正实现独立分析大数据。
关于学习生物信息学分析的重要性,请阅读《生物信息9天速成班—成为团队中不可或缺的人》。生信分析离不开程序写作,这部分没想象的难,只要跟着我们操作下来,就可以理解,具体见《生物信息中的程序学习心得》。
课程简介
请详细阅读课程简介,如果以下内容您全精通,不必参加此培训。
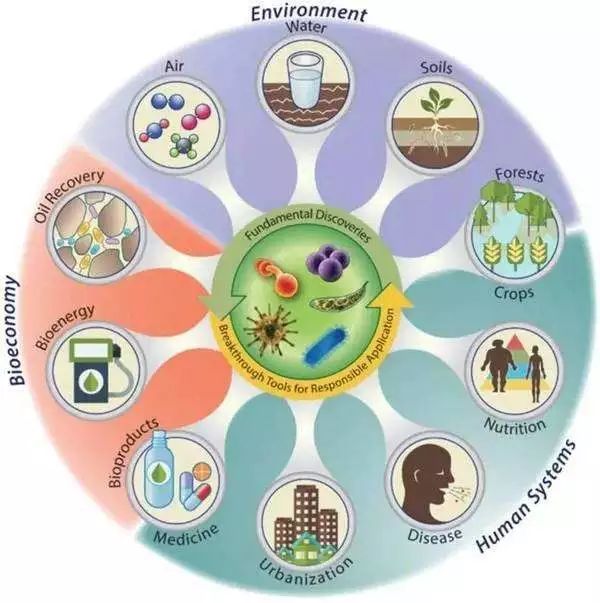
宏基因组/微生物组是当今世界科研最热门的研究领域之一,为加强本领域的技术交流与传播,推动中国微生物组计划发展,中科院青年科研人员创立“宏基因组”公众号,目标为打造本领域纯干货技术及思想交流平台。成立两年,分享专业技术原创文章900+篇,关注人数47,000+,累计阅读量7,000,000+。
为满足广大读者进一步学习的需求,现联合《生信宝典》组织宏基因组学专题培训课程,进一步学习和交流宏基因组学分析技术,手把手带您快速入门、节约宝贵的时间,助力科研成果早日产出。
本课程一共3天,每天6节课,共18节课,全部课程均理论与实战结合(只要课上讲的都是可以学会并自己实现的分析)。从Linux和R基础、宏基因组Linux服务器分析平台搭建、Windows常用统计分析软件、数据分析图表解读和实战、宏基因组有参(Reference-based适合人类、动物肠道等)和无参(De novo适合植物、环境样本等)标准分析流程、Binning(挖掘单菌基因组)、统计分析以及各类高级分析(多基因连接进化树、网络图绘制和美化、网络属性比较、机器学习等),和CNS级图片修改排版。3天时间,老司机带您完成自学需要3个月甚至是3年的崎岖之路,助力您真正实现宏基因组分析、并根据自己课题的背景优化分析方案。
课程大纲
每节课1小时一个主题,理论结合实战,学懂原理,实战实操,全是老司机多年经验和代码的无私分享。下面是课程安排,如11代表第一天第一节课,26代表第二天第六节课,41为两周后的线上集中视频答疑。
| 编号 | 主题 | 简介 |
|---|---|---|
| 11 | Linux基础 | 简介、远程登陆、文件传输、常用命令 |
| 12 | Linux软件安装 | Conda安装与配置,宏基因组相关软件安装和数据库下载 |
| 13 | Win软件安装 | git、R、Rstudio、R包、STAMP、AI等 |
| 14 | 图表解读 | 常用分析图表在文章中意义和使用场景 |
| 15 | R基础 | 发展史、生物学中应用、ggplot2绘图 |
| 16 | 可视化 | 16种图表的数据整理和在线绘制 |
| 21 | 宏基因组简介 | 发展史、常用技术适用范围、分析思路 |
| 22 | 宏基因组有参质控 | FastQC、Trimmomatic、 MultiQC]()、KneadData质控、parallel并行计算 |
| 23 | 物种和功能组成 | MetaPhlAn2物种组成、HUMAnN2功能组成、功能关联驱动物种 |
| 24 | 物种和功能差异比较和可视化 | GraPhlAn、LEfSe、STAMP、R语言统计 |
| 25 | 发表前准备 | 图片排版、数据释放、代码整理(可选) |
| 26 | 网络绘制 | 基础、igraph、Gephi |
| 31 | 物种注释和可视化 | Kraken、Kraken2、GraPhlAn、Krona、microbiomeViz、metacoder |
| 32 | 拼接、基因注释和定量 | MEGAHIT、metaSPAdes、QUAST、Prokka、cd-hit、Salmon |
| 33 | 基因功能注释 | KEEG、COG/EggNOG、CAZy/dbcan2、ARDB/Resfams/CARD、Uniref、VFDB、TCDB |
| 34 | 分箱Binning | 理论、MetaWRAP、VizBin |
| 35 | 细菌基因组进化 | Bins提取保守基因、多基因进化树、 一文读懂进化树 Evolview基础 进阶 iTOL美化 进阶 |
| 36 | 总结串讲 | 宏基因组分析套路回顾和总结 |
| 37 | 考试50题 | 自评学习效果、知识点回顾 |
| 41 | 答疑-线上 | 答疑、考试内容串讲 |
教程内容简介如下:
一、分析平台搭建
“工欲善其事必先利其器”,没有自己的分析平台,想分析大数据,那怎么能行。宏基因组数据量极大,前期原始下机的大数据想在自己本本上处理还是有难度的。好在现阶段一般的高校、科研院所、课题组都有自己的服务器,即使没有服务器,也可以租用国内的阿里云、腾讯云等服务。现在分析条件拥有了,如何把服务器变成宏基因组分析的利器呢,这是一个非常复杂的专业问题,在这里你马上可以学到!
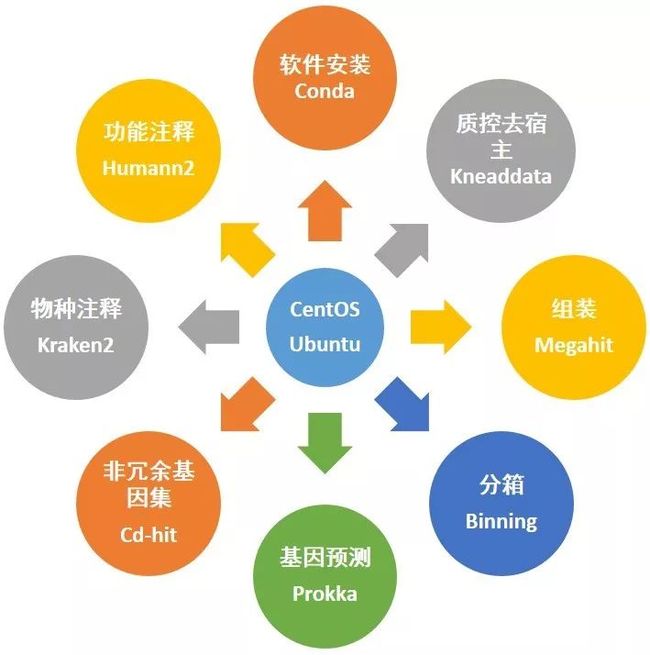
图1. 宏基因组分析流程的搭建——系统、安装方法和主要软件
服务器推荐使用Ubuntu系统。最低配置32G内存、8核;推荐256G内存,24线程起;配置越高,分析更快更流畅。
没有软件的计算机只是一堆废铁,没有宏基因组分析系统的服务器也和你的数据分析没有半毛钱关系。想要搭建整套的宏基因组分析流程,网上的资源即零散、又稀少。易生信团队将分享多年经验摸索优秀软件和布置技巧,并分享全部源代码,让你在主流Linux服务器系统(Ubuntu 16/18.04,CentOS7等主流发行版)上快速布置宏基因组分析流程依赖的几十款常用软件、几百个依赖的R和Python包,轻松拥有专业分析平台。
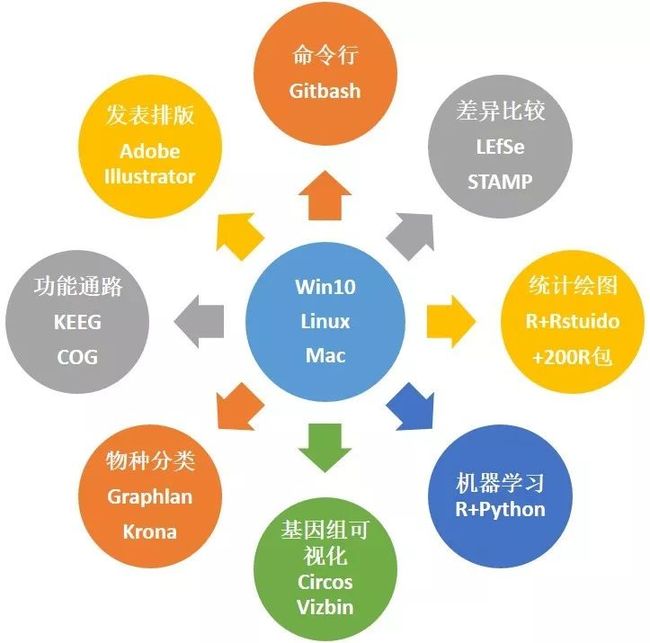
图2. 易生信首创基于Win10优化的数据统计分析和可视化流程,笔记本秒变大数据分析平台
推荐使用Windows10系统,8G内存分析更快更流畅。
高通量测序所谓的大数据,都是在原始数据和分析过程中体积大,但结果不大。通常宏基因组分析会获得样品物种组成、功能组成表,这些表格是下游分析、高级分析以及个性分析的起点,绝大部分工作在我们的笔记本上是可以搞定的,只是很多人并不知道如何入手。
其实你的个人电脑就是数据表(丰度矩阵)统计分析的利器。易生信团队独创实现了跨平台的分析流程,在大家的Windows笔记本上可以轻松实现扩增子、宏基因组领域统计、可视化的绝大多数分析,第三节课带你轻松在自己的本本上搭建数据表统计分析与可视化平台,基于目前最主流的Win10进行优化和测试,让笔记本秒变数据分析可视化平台。
我们也会带大家在Linux上配置整个分析可视化平台 (Mac跟Linux类似,无做区别对待,但部分软件可能安装方式不同,未做深入测试,不建议参加培训时使用)。
二、生信基础
有了生信分析平台,如何灵活运用还是要学点独门绝学的。21世纪最重要的是人才,人才最好掌握三门语言,将让你人生立于不败之地,在任何团队中都是不可或缺的人才。这三门语言就是中文、英文和计算机语言。中文每天都在用在学,英文对于博士也至少接触了10年以上并能应用于阅读和写作文献,而编程语言大家大学阶段都学过Visual Basic、Visual Foxpro、或C语言,但能在工作中应用的绝对凤毛麟角。更何况这些语言在生命科学领域是非常低效的,不提倡学习。
生信中最常用的三类语言是Shell + R + Python/Perl,前两门是基础,保证你完成项目分析。我们在课上将同时讲解生物学家必要掌握的Shell和R语言基础知识,保证你高效、稳定的使用宏基因分析平台、保证大数据分析和后期可视化至发表阶段所需的技能。我们在文后提供了学习视频供提前预习。

图3. Shell和R学习大纲,首创Rstuio中鼠标点击可完成Shell脚本和R语言分析,既打开生信的大门,又不会增加生物学家时间成本
当你利用几个小时,走进大数据分析和可视化的大门后,你将发现一个全新的世界。很多人会感觉相见恨晚,爱上分析,从此走向人生的快车道。即使你对编程不感兴趣,这里面用到的理念也定能让你受益终身,在今后相关分析中事半功倍,比别人更胜一筹。再说现在连小学生都学Python了,再不会,孩子都带不好了。
三、图表解读和绘制专题
针对很多老师缺少系统的生信背景,看不懂分析文章图表,更对绘制各式图表手足无措的情况, 我们推出过如下两个系列,共16篇原创文章,对8种图型和R语言绘图进行讲解。
扩增子图表解读-理解文章思路
扩增子统计绘图-冲击高分文章
但这些只是入门,在培训时,我们将结合发表的高水平文章,进一步讲解16种常用分析图的原理和使用范围,让你不仅读懂图,更知道如何应用于自己的研究,并亲自轻松完成绘图。
针对使用R语言绘图学习时间成本较高的问题,易生信团队针对常用16种图开发了免费绘图网站,一键出图,更可鼠标点选参数修改图形的个性样式。
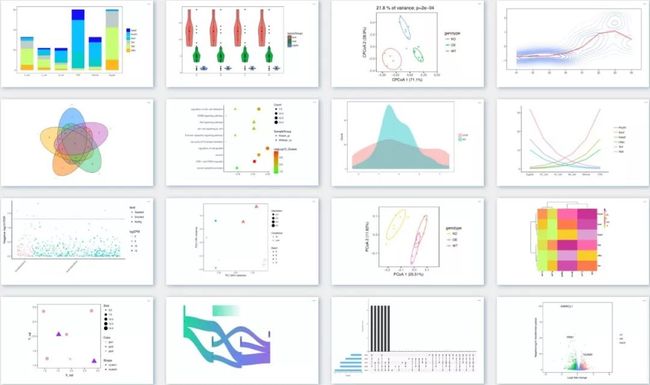
图4. 16种常用图形的表达的意义、使用场景和绘制。可使用我们的在线绘图工具实现。
为了让各种统计图片实现出版级的组图,特开设了一节Adobe Illustrator修图排版课,讲述基本使用技巧,轻松掌握精髓,让你文章图版档次向CNS看齐,轻松成为实验室的修图和拼图达人。
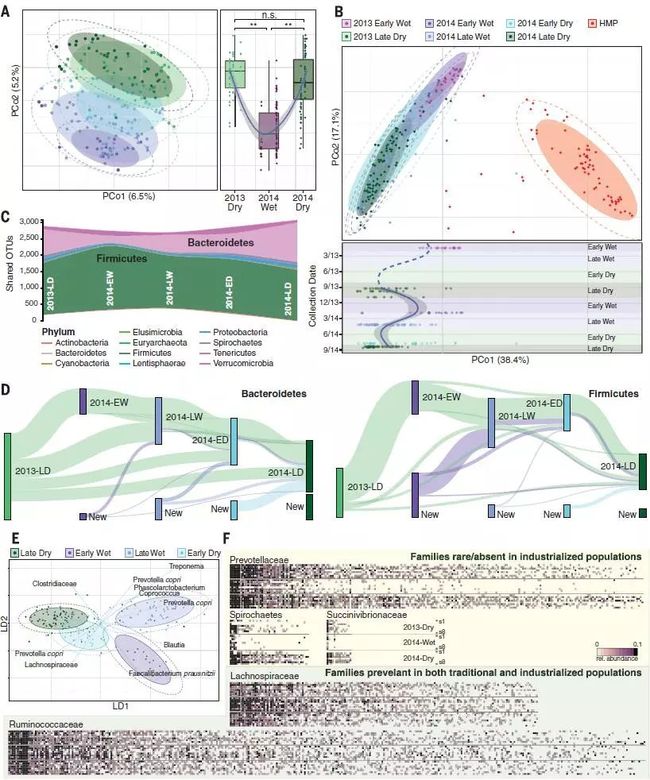
图5. AI排版本子图为CNS出版级组图示例(Science, 2016封面文章)
四、宏基因组学概述
在第一天全面打造科研基础后之,我们将开始宏基因组大数据分析之旅。
作为专业基础知识,我们将学习以下内容。
背景:国际微生物组、中国微生物组计划
研究对象:人、动物、植物、环境
研究方法:培养组学、扩增子、宏基因组、宏转录组、宏蛋白组、宏代谢组、宏基因组关联分析、宏表观组……
宏基因组学的研究热点:培养组、肠菌与疾病、宏基因组关联分析(MWAS)、多组学联合分析……
测序发展史与原理
样品制备、实验重复和测序数据量的选择
宏基因组分析SCI文章的常用套路
宏基因组与扩增子优缺点比较
原始数据评估、组装结果好坏的判断
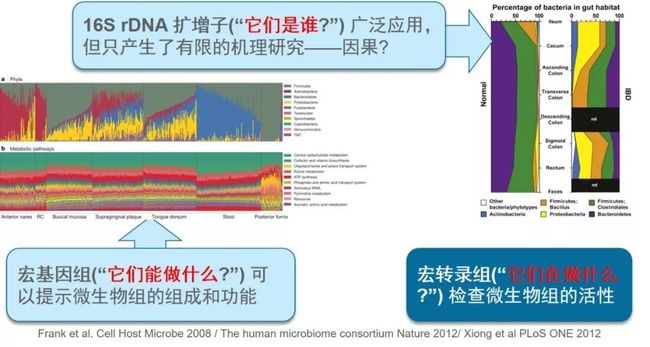
图6. 宏基因组学常用手段:扩增子、宏基因组、宏转录组所能回答的科学问题
五、宏基因组学有参分析流程
刚上手每个样品几G到几十G的数据,如果无从下手,还是建议立马来一套有参分析,快速获得样品的物种组成和功能组成。有参(Reference-based)方法,顾名思义,是直接使用现在的物种、功能基因注释数据库,数据只通过质控、比对而快速获得相应物种、功能基因的相对丰度矩阵。在本领域第一分析大牛Rob Knight的最新综述中对此方法也很推崇,《Nature综述 | Rob Knight等手把手教你分析菌群数据(全文翻译1.8万字)》。
此法优势明显,步骤少,速度快,省时省力,适合人类肠道、模式生物、海洋等有较好参考数据库的领域。缺点是无法识别未被报导物种的功能基因,对于植物、土壤、极端环境样本分析时,会损失很多信息。
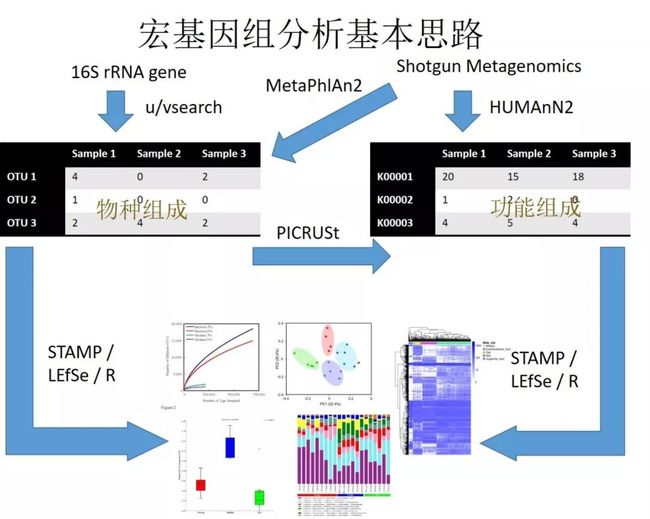
图7. 宏基因组分析基本思路——有参分析流程。主要通过MetaPhlAn2基于己报导的所有微生物基因组获得物种组成,基于UniRef、EggNOG、KEGG等蛋白数据库确定功能组成。16S扩增子数据本身只包含物种组成,可通过PICRUSt获得KEGG/COG的功能组成。
主要知识点:
1. 实验设计的编写原则
2. KneadData流程快速质控和去宿主流程
3. 物种组成定量MetaPhlAn2
4.功能组成定量HUMAnN2
六、宏基因组无参分析流程
宏基因组无参分析,主要有两个目的:一是获得未被注释的物种和基因表达;二是通过Binning挖掘新物种的基因组。看样子很美好,但实际操作起来对计算量要求非常大。分析过程中比有参多了组装、基因预测、非冗余基因集构建和基因注释等步骤。
图8. 宏基因组无参分析流程。
关键步骤及使用软件:
数据质控fastqc, Trimmomatic, MultiQC, khmer
组装拼接MEGAHIT和评估quast
基因注释Prokka
构建非冗余基因集:CD-HIT
基因丰度估计:Salmon等方法快速基因丰度定量,后续可进行PCA、PCoA、CCA等整体组间差异比较;也可进一步使用edgeR、MetaStat、LEfSe进行组间差异基因分析;
物种注释:获得非冗余基因集物种注释信息,也可在reads层面使用Kraken2进行直接物种注释,结合第6步丰度值可进行组间差异物种分析;
基因功能分类注释:代谢通路(KEGG),同源基因簇(eggNOG)注释,结合6中丰度进行组间差异功能比较;
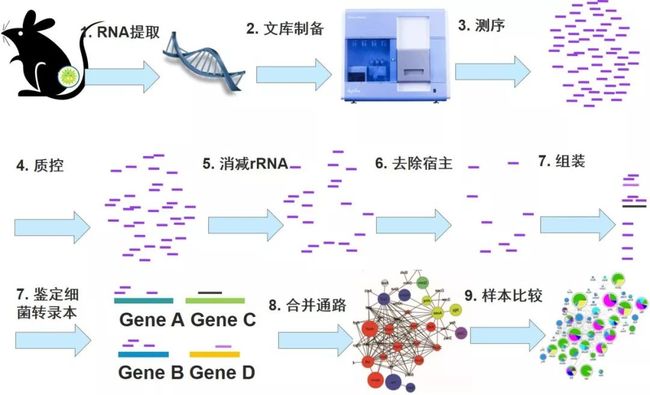
图9. 宏转录组分析流程。宏转录组较宏基因组多一步去除rRNA基因序列的步骤。此方法缺点是无法获得真实的物种组成,但它体现的是在特定时空条件下有活性的物种和功能基因表达水平组成。
七、高级分析与可视化实战
R语言统计绘图与可重复计算
宏基因组中鉴定单菌(分箱bin):MetaWRAP
Bin结果评估及可视化:CheckM, VizBin
宏基因组可视化:Circos
在线流程:MEGAN、MG-RAST、EBI-metagenome
网络分析: igraph、WGCNA、Cytoscape
多基因连接树构建:RaxML、fasttree、iTOL
其它常用:Graphlan、Krona
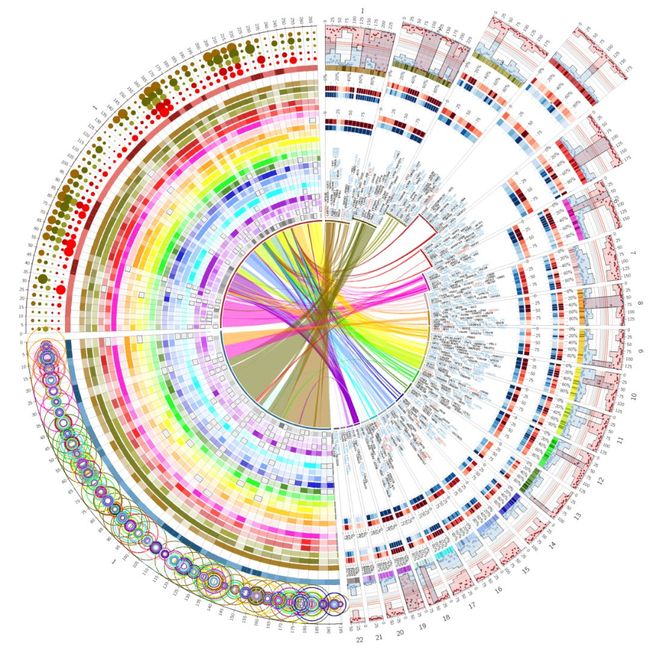
图10. 宏基因组基因组成、丰度、覆盖度等信息可视化
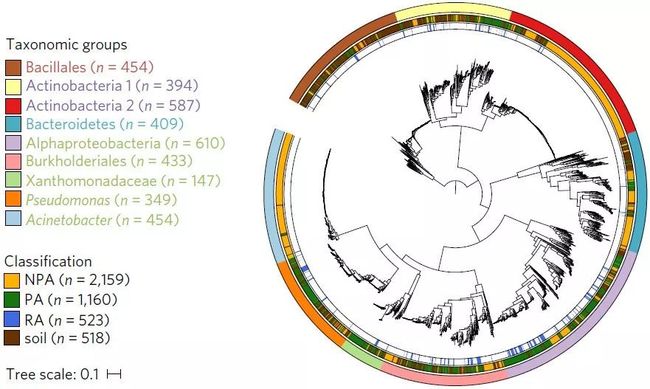
图11. 基于多基因连接的进化树构建和美化(Levy-2018-NatureGenetics)
学习完本课程,你能得到什么?
深彻理解生物测序数据的基本思想

宏基因组分析三种模式全面的解决方案,以及结果的统计分析
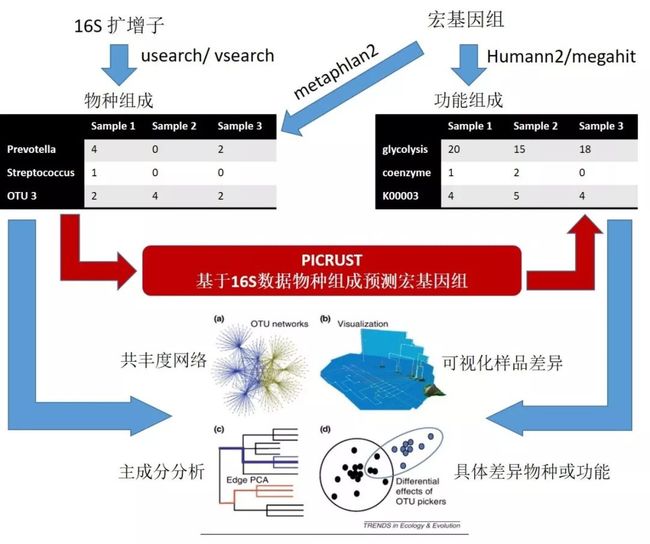
16S扩增子数据PICRUST预测宏基因组
宏基因组数据Humann2定量物种和功能
Denovo宏基因组拼接和binning
几十种软件数据库的使用经验
几十款本领域软件的安装、使用教程
常用功能注释数据库的理解和使用
高要求的结果可视化
结果的差异比较
多种可视化方案
主讲教师
主讲老师和助教包括中科院微生物所、遗传发育所、基因组所、生物物理所等多名本领域一线技术专家,在Nature子刊、Science和Cell子刊均发表过重镑级成果。
刘永鑫,博士。2008年毕业于东北农大微生物学专业。2014年中科院遗传发育所获生物信息学博士学位,2016年博士后出站留所工作,任宏基因组学实验室工程师,目前主要研究方向为宏基因组数据分析和植物微生物组。QIIME 2项目参与人,目前在Science、Nature Biotechnology、Genomics Proteomics Bioinformatics、Science China Life Sciences等杂志发表论文十余篇。2017年7月创办“宏基因组”公众号,目前分享宏基因组、扩增子原创文章900余篇,代表博文有《扩增子图表解读、分析流程和统计绘图三部曲(21篇)》、《Nature综述:手把手教你分析菌群数据(1.8万字)》、《QIIME2中文教程(18篇)》等,关注人数4.7万+,累计阅读700万+。
陈同,博士,2015毕业于中科院遗传与发育生物学研究所,生物信息专业博士,在Cell Stem Cell(IF=23.2,第一作者兼封面文章),Nucleic Acids Research X 2,Stem Cells and Development等高水平杂志以第一作者或主要作者发表文章,运营有数万人关注的《生信宝典》微信公众号,给你不一样的学习生信体验。
陈亮,博士。2010年毕业于鲁东大学生物技术专业,2017年于中国科学院微生物研究所获微生物学博士学位。目前就职于中国科学院微生物研究所病原微生物与免疫学重点实验室,生物信息和计算生物学研究组,任助理研究员,目前主要研究内容为微生物生态学、宏基因组学等方面的数据挖掘和分析。在宏基因组公众号发表《一文学会网络分析》、《Science:肠道菌群揭示你的真实年龄》、《R中赋值符号箭头<-和等号=的区别》等文章。
周欣,中科院微生物硕博连续在读博士生(5年级),曾在加拿大农业与农业食品部-渥太华研究发展中心微生物生物信息研究组联合培养一年。熟悉高通量扩增子和宏基因组数据的处理及下游差异统计分析工作。目前主要研究方向为植物病害(土传病害)相关的微生物组学研究。在宏基因组公众号发表《再这么配培养基,你的细菌都被毒死了!》、《VSEARCH操作实战-免费使用价值万元的USEARCH》、《iTOL快速绘制颜值最高的进化树!》等。
往期课程瞬间





助教团队
十余名中国科学院、清华、北大博士(含在读),轮值讲师和助教,辅助学员学习和矫正培训过程中不足的点。
授课模式
本课程以讲解流程和实际操作为主,采用独创四段式教学:
第一阶段 3天集中授课;
第二阶段 自行练习2周;
第三阶段 在线直播答疑;
第四阶段 培训视频继续学习;
实现教-练-答-用四个环节的统一协调。
培训时间
2019-8-2 到 2019-8-4 (线下讲解实战)
每天早9点到晚6点,半封闭式教学 (最后1小时为圆桌讨论时间,增加互动交流。最后一天会稍微提前一些,多留出时间讨论,也方便老师乘车返回)
报到时间:上课当天
授课地点
北京市西城区鼓楼明德大厦附近 (北京会议较多,具体位置开课前1周通知)。
课程价格
截止 2019-7-26 4500 元/人
名额有限,每次课程报名满40人后自动关闭报名通道
提供易汉博基因科技实习机会或工作机会
课程福利
座位按报名并缴费(或预缴费)成功顺序从前到后龙摆尾式排序
赠送程序基础课一份 (http://bioinfo.ke.qq.com)
多人 (N,10>N>1) 组团报名并同时缴费,每人还可减免N-1百元 (最高500)
赠送金士顿U盘一个(32G含培训数据和脚本)
附推荐与分享对应的招生信息到朋友圈,截图发到[email protected] 可获得200元生信宝典腾讯课堂课程优惠券(可拆分供多个课程使用)
易生信同时推出多门相关课程,连报优惠——同时选2门课,95折;三门课9折,4门及以上85折。还可与团购同时优惠!扩增子(项目初探)+宏基因组(高精尖),祝你分析水平更上一层楼。
注意事项 *
需自备笔记本电脑,推荐使用win10系统,4G以上内存(推荐8G)。课程实践根据需要会提供云计算平台
培训班所有数据,文档为内部资料,仅供参阅,未经允许不得翻印外传登刊
上课期间禁止录音,录像
成功付款的学员,若临时有紧急事情不能到来的,可申请延期,更换后续培训班;也可申请退款
若开课2周 (含) 前申请退款可退还85%费用;开课3个工作日 (含) 前申请退款退还70%的费用 (若已开发票需承担相应手续费)
不可先延期再退款
更多课程的详细介绍,请扫描下方二维码。

易生信同时推出多门相关课程,连报优惠——同时选2门课,95折;三门课9折,4门及以上85折。还可与团购同时优惠!扩增子(项目初探)+宏基因组(高精尖),祝你分析水平更上一层楼。

成为实验中不可或缺的人,复制链接 http://www.ehbio.com/Training/ 或点击阅读原文,赶快报名吧!