【目标检测】MMDetection专栏之基准测试 和 Model Zoo|三
环境
硬件
8 个 NVIDIA Tesla V100 GPUs
Intel Xeon 4114 CPU @ 2.20GHz
软件环境
Python 3.6 / 3.7
PyTorch 1.1
CUDA 9.0.176
CUDNN 7.0.4
NCCL 2.1.15
镜像站点
我们使用AWS作为托管model zoo的主要站点,并在阿里云上维护镜像。你可以在模型网址中把https://s3.ap-northeast-2.amazonaws.com/open-mmlab替换为https://open-mmlab.oss-cn-beijing.aliyuncs.com。
常用设置
所有FPN基准和RPN-C4基准均使用8个GPU进行训练,批处理大小为16(每个GPU 2张图像)。其他C4基线使用8个批处理大小为8的GPU进行了训练(每个GPU 1张图像)。
所有模型都在
coco_2017_train上训练以及在coco_2017_val测试。我们使用分布式训练,并且BN层统计信息是固定的。
我们采用与Detectron相同的训练时间表。1x表示12个epoch,而2x表示24个epoch,这比Detectron的迭代次数略少,并且可以忽略不计。
ImageNet上所有pytorch样式的预训练主干都来自PyTorchmodel zoo。
为了与其他代码库进行公平比较,我们将GPU内存报告
torch.cuda.max_memory_allocated()为所有8个GPU 的最大值。请注意,此值通常小于nvidia-smi显示的值。我们将推理时间报告为总体时间,包括数据加载,网络转发和后处理。
基线
具有不同主干的更多模型将添加到model zoo。
基线
具有不同主干的更多模型将添加到model zoo。
RPN

访问文末【原文链接】即可下载表格中的model列模型权重
Faster R-CNN
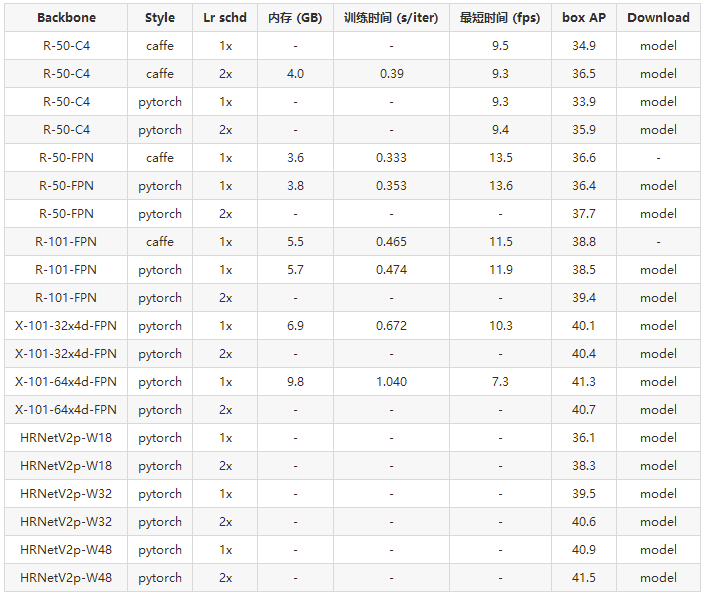
访问文末【原文链接】即可下载表格中的model列模型权重
Mask R-CNN
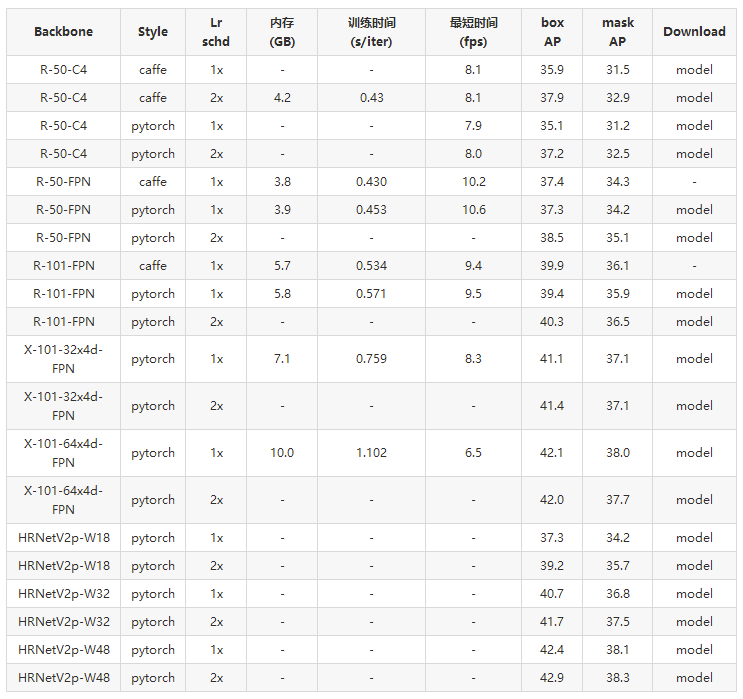
访问文末【原文链接】即可下载表格中的model列模型权重
Fast R-CNN (有预先计算的proposals)
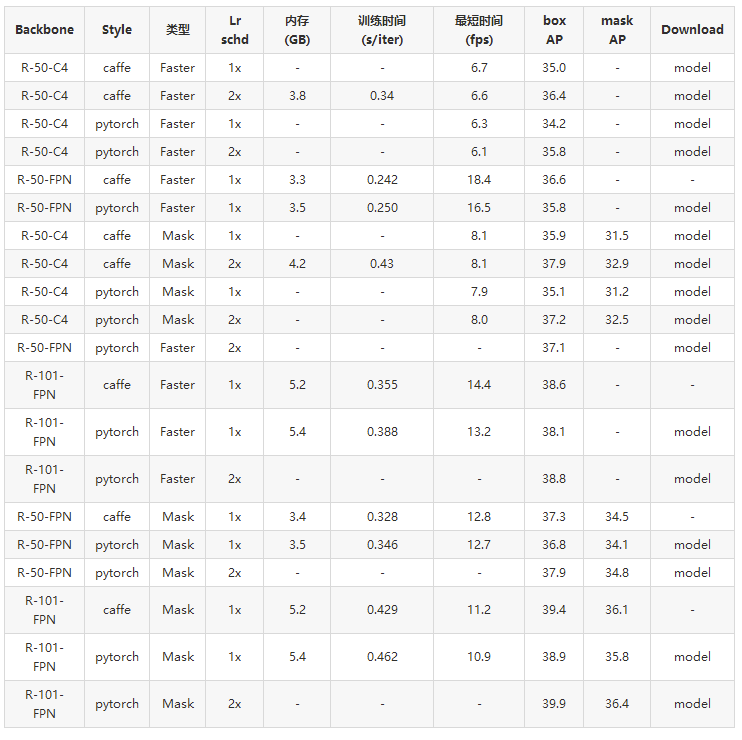
访问文末【原文链接】即可下载表格中的model列模型权重
RetinaNet
访问文末【原文链接】即可下载表格中的model列模型权重
Cascade R-CNN

访问文末【原文链接】即可下载表格中的model列模型权重
Cascade Mask R-CNN

访问文末【原文链接】即可下载表格中的model列模型权重
注意:
20e级联(掩码)R-CNN中的时间表指示在第16和19个epoch减少lr,总共减少20个epoch。
混合任务级联(HTC)
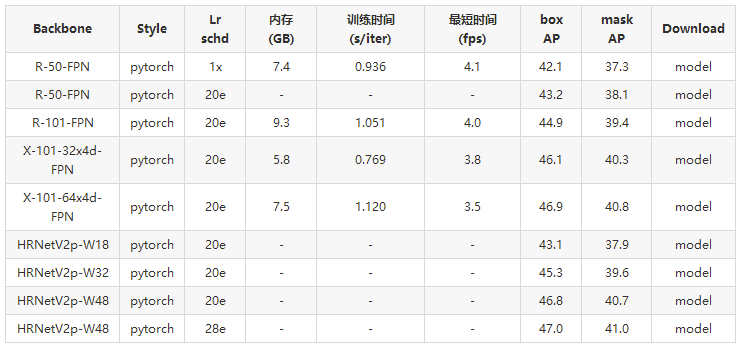
访问文末【原文链接】即可下载表格中的model列模型权重
注意:
有关详细信息和更强大的模型(50.7 / 43.9),请参阅混合任务级联(https://github.com/open-mmlab/mmdetection/blob/master/configs/htc).
SSD

访问文末【原文链接】即可下载表格中的model列模型权重
注意:
cudnn.benchmark设置为True用于SSD训练和测试。对于batch size= 1和batch size= 8,报告推理时间。
由于模型参数和nms,COCO和VOC的速度有所不同。
组规范化(GN)
有关详细信息,请参考组规范化(https://github.com/open-mmlab/mmdetection/blob/master/configs/gn)。
权重标准化
有关详细信息,请参考权重标准化(https://github.com/open-mmlab/mmdetection/blob/master/configs/gn+ws)。
可变形卷积v2
有关详细信息,请参阅可变形卷积网络(https://github.com/open-mmlab/mmdetection/blob/master/configs/dcn)。
CARAFE:功能的内容感知重组
有关详细信息,请参考CARAFE(https://github.com/open-mmlab/mmdetection/blob/master/configs/carafe)。
Instaboost
有关详细信息,请参考Instaboost(https://github.com/open-mmlab/mmdetection/blob/master/configs/instaboost)。
Libra R-CNN
有关详细信息,请参考Libra R-CNN(https://github.com/open-mmlab/mmdetection/blob/master/configs/libra_rcnn)。
Guided Anchoring
有关详细信息,请参阅Guided Anchoring(https://github.com/open-mmlab/mmdetection/blob/master/configs/guided_anchoring)。
FCOS
有关详细信息,请参阅FCOS(https://github.com/open-mmlab/mmdetection/blob/master/configs/fcos)。
FoveaBox
有关详细信息,请参考FoveaBox(https://github.com/open-mmlab/mmdetection/blob/master/configs/foveabox)。
RepPoints
有关详细信息,请参考RepPoints(https://github.com/open-mmlab/mmdetection/blob/master/configs/reppoints)。
FreeAnchor
有关详细信息,请参考FreeAnchor(https://github.com/open-mmlab/mmdetection/blob/master/configs/free_anchor)。
Grid R-CNN (plus)
有关详细信息,请参考Grid R-CNN(https://github.com/open-mmlab/mmdetection/blob/master/configs/grid_rcnn)。
GHM
有关详细信息,请参阅GHM(https://github.com/open-mmlab/mmdetection/blob/master/configs/ghm)。
GCNet
有关详细信息,请参考GCNet(https://github.com/open-mmlab/mmdetection/blob/master/configs/gcnet)。
HRNet
有关详细信息,请参考HRNet(https://github.com/open-mmlab/mmdetection/blob/master/configs/hrnet)。
Mask Scoring R-CNN
有关详细信息,请参考Mask Scoring R-CNN(https://github.com/open-mmlab/mmdetection/blob/master/configs/ms_rcnn)。
Train from Scratch
有关详细信息,请参考 重新思考ImageNet预训练(https://github.com/open-mmlab/mmdetection/blob/master/configs/scratch)。
NAS-FPN
有关详细信息,请参阅NAS-FPN(https://github.com/open-mmlab/mmdetection/blob/master/configs/nas_fpn)。
ATSS
有关详细信息,请参考ATSS(https://github.com/open-mmlab/mmdetection/blob/master/configs/atss)。
其他数据集
我们还对PASCAL VOC(https://github.com/open-mmlab/mmdetection/blob/master/configs/pascal_voc),Cityscapes(https://github.com/open-mmlab/ mmdetection / blob / master / configs / cityscapes)和WIDER FACE(https://github.com/open-mmlab/mmdetection/blob/master/configs/wider_face)的一些方法进行了基准测试。
与 Detectron 和 maskrcnn-benchmark 的比较
我们将mmdetection与Detectron(https://github.com/facebookresearch/Detectron) 和maskrcnn-benchmark(https://github.com/facebookresearch/maskrcnn-benchmark)进行比较。使用的主干是R-50-FPN。
通常来说,mmdetection与Detectron相比具有3个优势。
更高的性能(尤其是在mask AP方面)
更快的训练速度
高效记忆
性能
Detectron和maskrcnn-benchmark使用Caffe风格的ResNet作为主干。我们使用caffe样式(权重从(https://github.com/facebookresearch/Detectron/blob/master/MODEL_ZOO.md#imagenet-pretrained-models) 和pytorch样式(权重来自官方model zoo)ResNet主干报告结果,表示为pytorch样式结果 / caffe样式结果。
我们发现,pytorch风格的ResNet通常比caffe风格的ResNet收敛慢,因此在1倍进度中导致结果略低,但2倍进度的最终结果则较高。
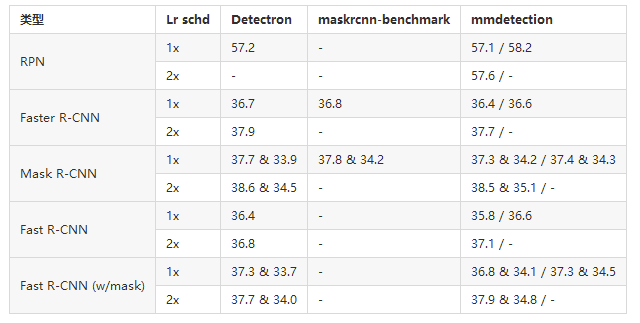
训练速度
训练速度以s/iter为单位。越低越好。
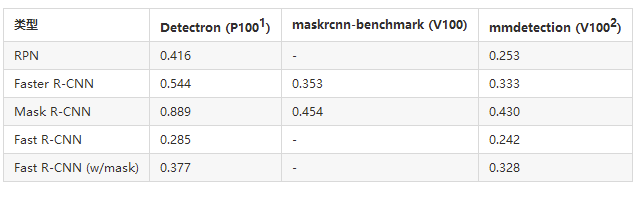
1.Facebook的Big Basin服务器(P100 / V100)比我们使用的服务器稍快。mmdetection在FB的服务器上也可以稍快一些地运行。
2.为了公平比较,我们在此处列出了caffe的结果。
推理速度
推理速度在单个GPU上以fps(img / s)进行测量。越高越好。

训练内存

毫无疑问,maskrcnn基准测试和mmdetection比Detectron的存储效率更高,而主要优点是PyTorch本身。我们还执行一些内存优化来推动它向前发展。
请注意,Caffe2和PyTorch具有不同的API,以通过不同的实现获取内存使用情况。对于所有代码库,nvidia-smi显示的内存使用量均大于上表中报告的数字。
原文链接:https://mmdetection.readthedocs.io/en/latest/MODEL_ZOO.html
(访问此原文链接可下载本文中表格的model列模型权重。)
☆☆☆为方便大家查阅,小编已将MMDetection专栏文章统一整理到公众号底部菜单栏,同步更新中,关注公众号,点击左下方“文章”,如图:

或点击下方“阅读原文”,进入MMDetection专栏,即可查看系列文章。
☆ END ☆
如果看到这里,说明你喜欢这篇文章,请转发、点赞。微信搜索「uncle_pn」,欢迎添加小编微信「 mthler」,每日朋友圈更新一篇高质量博文(无广告)。
↓扫描二维码添加小编↓
