InnoDB存储引擎B+树索引介绍
InnoDB存储引擎支持B+树索引、哈希索引、全文索引和空间索引,后两种很少用到,本文主要介绍B+树索引。
B+树是从最早的平衡二叉树(AVL)演变而来,但是B+树不是一个二叉树。B+中的B不代表二叉(Binary),而是代表平衡(Balance)。其他常见的树结构还有BST,红黑树,B树,B*树。
MySQL中的B+树索引可以分为聚集索引(clustered index)和非聚集索引(non-clustered index)。
InnoDB聚集索引就是按照每张表的主键构造一颗B+树,并且叶子节点上存放着整行记录数据,而非聚集索引的叶子节点上仅保存键值以及指向数据页的偏移量。聚集索引的这个特性决定了索引组织表中数据也是索引的一部分。(ps:MyISAM索引的叶子节点上存放的是数据记录的地址。)
二、B+树索引结构
B+树是为磁盘及其他存储辅助设备而设计一种平衡查找树(不是二叉树)。B+树中,所有记录的节点按大小顺序存放在同一层的叶子节点中,各叶子节点用指针进行连接。MySQL将每个叶子节点的大小设置为一个页的整数倍,利用磁盘的预读机制,能有效减少磁盘I/O次数,提高查询效率。
页是计算机管理存储器的逻辑块,硬件及OS往往将主存和磁盘存储区分割为连续的大小相等的块,每个存储块称为一页,页的大小通常为4K。
下图,是一个经典的B+树组织结构图(简化的2层B+树,每个页面的扇出为4):
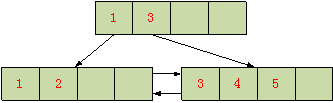
此B+树,有5条用户记录,分别是1,2,3,4,5;
B+树上层页面中的记录,存储的是下层页面中的最小值(Low Key);
B+树的所有数据,均存储在B+树的叶节点;
B+树叶子节点的所有页面,通过双向链表链接起来;
关于B+树的分裂与合并,这里不作详细介绍,有兴趣的可以自行了解。
实际上B+索引在数据库中有一个特点就是其高扇出性,因此在数据库中,B+树的高度一般不超过3层,也就是对于查找某一键值的行记录,最多只需要2到3次IO。现在一般的机械硬盘的IOPS在100~200之间,2~3次的IO意味着查询时间只需0.02~0.03秒,更有甚者,现在大多数企业都使用SSD固态硬盘,IOPS基本超过50000,查询效率进一步提升。
所有的叶子节点使用指针链接的好处是可以进行区间访问,这也是MySQL使用B+树作为索引存储结构的重要原因。
另一个重要的问题,为什么通常我们要给表设置一个自增的主键,因为所有记录的节点按大小顺序存放在同一层的叶子节点中,这样就就会形成一个紧凑的索引结构,近似顺序填满,每次插入新数据时减少B+树维护的成本。如果使用非自增主键,由于每次插入主键的值近乎于随机,分裂会造成了大量的碎片,后续不得不通过OPTIMIZE TABLE来重建并优化填充页面。另外区间读取时,MySQL预读一部分和你当前读数据所在内存相邻的数据块,也能有效减少磁盘I/O次数。
B+树索引并不能找到一个键值对应的具体行。b+树索引只能查到被查找数据行所在的页,然后数据库通过把页读入内存,再在内存中查找,最后得到结果。
三、什么是顺序读和随机读
顺序读是指顺序的读取磁盘上的块,随机读是指访问的块是不连续的,需要磁盘的磁头不断移动。随机读的性能是远远低于顺序读的。在数据库中,顺序读根据索引的叶节点就能顺序的读取所需的行数据,这个顺序读只是逻辑的顺序读,在磁盘上可能还是随机读。
随机读是指访问辅助索引叶节点不能完全得到结果,需要根据辅助索引页节点中的主键去寻找实际数据行。对于一些取表里很大部分数据的查询,正式因为读取是随机读,而随机读的性能会远低于顺序读。所以优化器才会选择全部扫描顺序读,而不使用索引。
InnoDB存储引擎有两个预读取方法,随机预读取和线性预读取。随机预读取是指当一个区(共64个连续页)中有13个页在缓冲区中并被频繁访问时,InnoDB存储引擎会将这个区中剩余的页预读到缓冲区。线性预读取基于缓冲池中页的访问方式,而不是数量。如果一个区中有24个页被顺序访问了,则InnoDB会读取下一个区的所有页到缓冲区。但是InnoDB预读取经过测试后性能比较差,经过TPCC测试发现禁用预读取比启用预读取提高了10%的性能。在新版本InnoDB中,MySQL禁用了随机预读取,仅保留了线性预读取,并且加入了innodb_read_ahead_threshold参数,当连续访问页超过该值时才启用预读取,默认值为56。
四、B+树索引的使用
MySQL索引的添加和删除操作,对于主键索引,MySQL先是创建一张加好索引的临时表,然后把数据导入临时表,再删除原表,把临时表重命名为原表。对于二级索引,新版本的MySQL不再创建临时表,而是首先对表加S锁,在创建的过程中不需要重建表,但是由于上了S锁,在创建索引的过程中只能进行查询操作,不能更新数据。
低选择性的字段没有必要添加B+树索引。例如性别,它们取值范围很小。相反,某个字段取值范围很广,如姓名,几乎没有重复,即高选择性,则使用B+索引是比较合适的。
五、联合索引
联合索引还是一个B+树,不同的是记录节点的键值数量不是1,而是大于等于2,并按顺序排列,所以联合索引才会有最左匹配原则。