Fingerprint Recognition
1.简介
通过生物特征识别人是现代社会中的一种新兴现象。在上一阶段,由于对广泛应用程序的安全性需求,它受到越来越多的关注。在许多生物特征中,指纹被认为是最实用的特征之一。指纹识别需要用户付出最小的努力,除了捕获过程严格需要之外,不会捕获其他信息,并且提供了相对良好的性能。指纹普及的另一个原因是指纹传感器的价格相对较低,可以轻松集成到PC键盘,智能卡和无线硬件中(Maltoni等,2009)。
图1展示了通用指纹识别系统(FIS)的通用框架(Ji&Yi,2008)。指纹匹配是自动指纹识别系统(AFIS)的最后一步。指纹匹配技术可以分为三种类型:
-
基于相关的匹配,
-
基于细节的匹配,
-
非细节的基于特征的匹配。
基于细节的匹配是最流行和广泛使用的技术,是指纹比较的基础。
2.以前的工作和动机
在(Bazen&Gerez,2003)中,提出了一种新颖的细节匹配方法,该方法通过薄板样条模型描述了指纹中的弹性变形,该模型使用局部和全局匹配阶段进行估计。根据估计的模型对指纹进行配准后,可以使用非常严格的匹配阈值来计算匹配细节的数量。对于变形的指纹,与刚性匹配算法相比,该算法给出的匹配分数要高得多,而在1 GHz P-III机器上仅花费100毫秒。此外,表明观察到的变形与文献中提出的理论模型所描述的变形不同。
在(Liang&Asano,2006)中,细节图多边形用于匹配变形的指纹。Minutia多边形不仅描述了Minutia的类型和方向,而且还描述了Minutia的形状。这使得细节区域多边形可以比常规公差框更大,而不会丢失匹配精度。换句话说,细节多边形具有更高的能力

图1。
指纹识别系统的一般框图。
容忍失真。此外,提出的匹配方法采用带有参数的多二次基函数的改进的失真模型。可调参数使该模型更适合指纹失真。实验结果表明,所提出的方法比(Bazen&Gerez,2003)中的方法快两倍,且准确性更高(特别是在指纹严重失真的情况下)。
在(Jiang&Yau,2000)中,提出了一种新的指纹细节匹配技术,该技术通过使用细节细节的局部和全局结构来匹配指纹细节。Minutia的局部结构描述了Minutia在其附近的旋转和平移不变特征。它用于查找两个细节集的对应关系并增加全局匹配的可靠性。细节的全局结构可靠地确定了指纹的唯一性。因此,细节的局部和全局结构共同为可靠和强大的细节匹配提供了坚实的基础。所提出的细节匹配方案由于其高处理速度而适合于在线处理。他们的实验结果表明了该技术的性能。
在(Jain et al。,2001),提出了一种混合匹配算法,该算法同时使用细节(点)信息和纹理(区域)信息来匹配指纹。他们获得的结果表明,基于纹理的匹配和基于细节的匹配得分的组合导致整体匹配性能的显着提高。这项工作是由传感器为指尖提供的小接触区域所推动的,因此,仅感测到指纹的有限部分。因此,同一指纹的多次印记可能只有很小的重叠区域。仅在细节点附近才考虑山脊活动的基于细节的匹配算法,由于输入图像和模板图像中对应点的数量不足,因此不太可能在这些图像上表现良好。
在(Eckert等人,2005)中,提出了一种新的,有效的基于细节的指纹匹配方法,该方法对于指纹图案的平移,旋转和变形效果是不变的。该算法与先前的特征提取分离,并使用了指纹中细节特征的紧凑描述。匹配过程包括三个主要步骤:
-
在两个指纹模式中找到可能的对应细节对,
-
将这些对组合成每个四个细节的有效元组,每个模式包含两个细节。
-
第三步是匹配本身。
它是通过单调的树搜索实现的,该搜索可找到具有最大数量的不同细节对的元组的一致组合。该方法具有低且可扩展的存储器需求,并且在计算上不昂贵。
在(Yuliang et al。,2003)中,从以下三个方面介绍了三个想法:
-
将脊信息以简单但有效的方式引入到细节匹配过程中,解决了计算成本低的参考点对选择问题;
-
使用可变大小的边界框使它们的算法对指纹图像之间的非线性变形更加鲁棒;
-
在其算法中使用更简单的对齐方法。
他们使用2000年指纹验证竞赛(FVC2000)数据库和FVC2000性能评估进行的实验表明,这些想法是有效的。
在(Zhang et al。,2008)中,提出了一种新颖的细节索引方法,以加快指纹匹配速度,从而缩小了细节搜索空间,从而降低了计算成本。提取特征的有序序列以描述每个细节,并定义索引分数以从查询指纹中为输入指纹中的每个细节选择候选候选。该方法可应用于基于细节结构的验证和指纹识别。在大失真指纹数据库(FVC2004 DB1)上进行了实验,以验证该方法的有效性。
在大多数现有的基于细节的匹配方法中,分别从模板指纹和查询指纹中选择参考细节。当匹配两组细节时,模板和查询首先将参考细节对进行坐标和方向对齐,其次,评估其余细节的匹配分数。这种方法保证了与参考细节相邻区域的满意对齐。但是,远离参考细节的区域的排列通常不太令人满意。在(Zhu et al。,2005)提出了一种基于多对参考细节的全局对齐的细节匹配方法。这些参考细节通常分布在各个指纹区域中。匹配时,这些参考细节对将整体对齐,并且远离原始参考细节的那些区域对将更加令人满意地对齐。他们的实验表明,这种方法可以改善系统识别性能。
在(Jain等,1997a)中,描述了在线指纹验证系统的设计和实现。该系统分两个阶段运行:细节提取和细节匹配。(Ratha等人,1995年提出的Minutia提取算法的改进版本)的速度更快,更可靠,可用于从使用在线无墨扫描仪捕获的输入指纹图像中提取特征。对于细节匹配,已经开发了基于对齐的弹性匹配算法。该算法能够在不借助穷举搜索的情况下找到输入图像中细节与所存储模板之间的对应关系,并且能够自适应地补偿指纹之间的非线性变形和不精确的姿态变换。该系统已经在使用无墨扫描仪捕获的两组指纹图像上进行了测试。发现验证准确性是可以接受的。通常,在SPARC 20工作站上,完整的指纹验证过程平均大约需要八秒钟。
在(Luo et al。,2000)中,提出了一种改进(Jain et al。,1997a)算法的细节匹配算法。该算法可以更好地区分来自不同手指的两个图像,并且对非线性变形更鲁棒。对用无墨扫描仪捕获的一组指纹图像进行的实验表明,该算法快速且具有很高的准确性。
在(Jie et al。,2006)中,提出了一种新的指纹细节匹配算法,该算法快速,准确,适用于实时指纹识别系统。在该算法中,核心点用于确定参考点,而圆形边界框用于匹配。对用扫描仪捕获的一组指纹图像进行的实验表明,该算法比(Luo et al。,2000)算法更快,更准确。
传统的指纹表示方法有两个主要缺点(Jain等,2000):
-
对于很大一部分人口,很难自动提取基于指纹中完整脊结构的显式检测的表示。广泛使用的基于细节的表示形式并未利用指纹中可用的丰富区分信息的重要组成部分。局部脊结构不能完全由细节来表征。
-
此外,基于细节的匹配难以快速匹配包含不同数量的未注册细节点的两个指纹图像。
(Jain et al。,2000)中基于过滤器的算法使用一组Gabor过滤器以紧凑的固定长度FingerCode捕获指纹中的局部和全局细节。指纹匹配基于两个相应FingerCode之间的欧几里得距离,因此非常快。所获得的验证准确性仅次于公开文献中发表的基于细节的算法的最佳结果(Jain等,1997b)。当应用系统的性能要求不要求非常低的错误接受率时,建议的系统将比基于最新细节的系统具有更好的性能。最后,显示出可以通过基于互补(基于细节和基于过滤器)指纹信息组合匹配器的决策来提高匹配性能。
基于这一分析,本章提出了一种新的算法。这种新颖的算法是基于细节的匹配算法。在第3节中介绍了提出的匹配算法,在第4节中介绍了优点,最后在第5节中说明了该算法的实现,性能评估和结论。
3.提出的匹配算法
任何指纹识别系统(FIS)都有两个阶段,即指纹注册和指纹匹配(识别或验证)。
3.1。入学阶段
图2显示了提出的匹配算法的注册阶段的步骤,该步骤分为以下步骤:
-
应用增强过程后,获取要注册的指纹的核心点位置。
-
从指纹图像中提取所有细节。
-
从步骤2的输出数据中,获取细节位置(x,y坐标)及其类型:用于终止细节的type1和用于分支细节的type2。
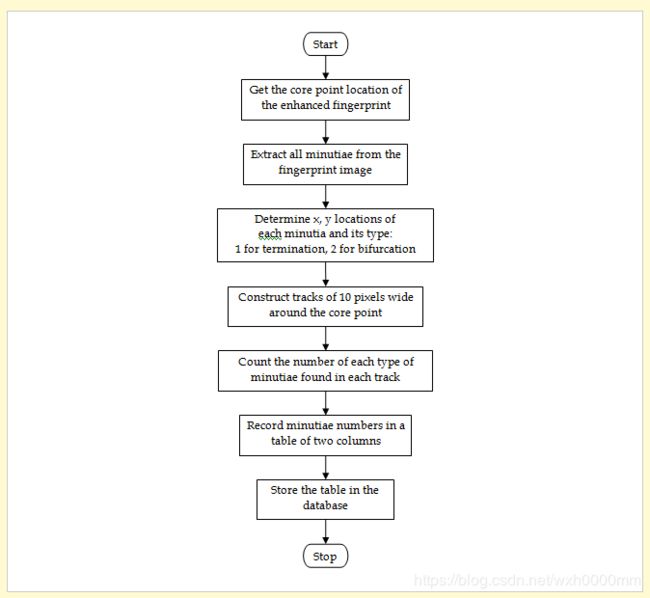
图2。
提出的匹配算法的注册阶段流程图。
-
以中心点为中心构造10像素宽的轨道。
-
在每个轨道中,计数类型1的细节和类型2的细节。
-
构造一个两列的表,第1列用于type1细节,第2列用于type2细节,其行数等于找到的轨道数。
-
在第一行中,记录在第一列的第一轨道中找到的类型1的细节,以及在第二列的第一轨道中找到的类型2的细节。
-
对其余的指纹轨迹重复步骤7,然后将表存储在数据库中。
对于同一用户指纹的所有打印,将重复此注册阶段。打印数量取决于进行用户注册的应用程序要求。对于FVC2000(Maio等,2002),每个指纹有8张照片。因此,每个用户需要八次注册才能在应用程序中注册。最后,数据库中的每个用户可以使用八个表。
3.2。验证阶段
为了验证用户,应在用户指纹上应用验证阶段,以便在应用程序上进行验证。图3。显示了提出的匹配算法的验证阶段的步骤,该步骤分为以下步骤:
-
捕获待验证用户的指纹。
-
对捕获的指纹应用第3.1节中所述的注册阶段步骤,以获取其详细信息表T。
-
从数据库中获取与要求保护的指纹的不同打印内容相对应的所有细节表。
-
从数据库中获取详细信息表T和声明的指纹的所有详细信息表之间的绝对差异(逐个单元),现在我们有了八个差异表。
-
为每个差异表获取第1列(类型1)和第2列(类型2)中的每个单元的所有单元格的总和,现在我们有16个总和。
-
获取类型1列的八个求和的几何平均值(gm1),以及类型2列的八个求和的几何平均值(gm2)。
-
检查:如果gm1 <= threshold1和gm2 <= threshold2,则该用户是真实的并接受他;否则,用户会冒名顶替并拒绝他。
4.提出的匹配算法的优点
所提出的基于细节的匹配算法具有以下优点:
-
由于每个细节表中代表数据库中指纹的所有单元格在指纹核心点周围的每个磁道中仅包含type1或type2的细节数,因此既没有位置(x或y)也没有方位(θ)被认为; 该算法是旋转和平移 不变的。
-
与传统的基于细节的基于匹配的算法相比,这些细节需要存储在数据库中,而传统的基于细节的匹配算法存储每个细节的位置和方向。实验表明,存储空间减少了近50%。
-
匹配相本身花费较少的 时间,如将在下面的章节显示的,达到0.00134秒。
5.提出的匹配算法的实现
使用MATLAB版本7.9.0.529(R2009b),拟议的注册和验证阶段均如以下两个小节中所述实现:
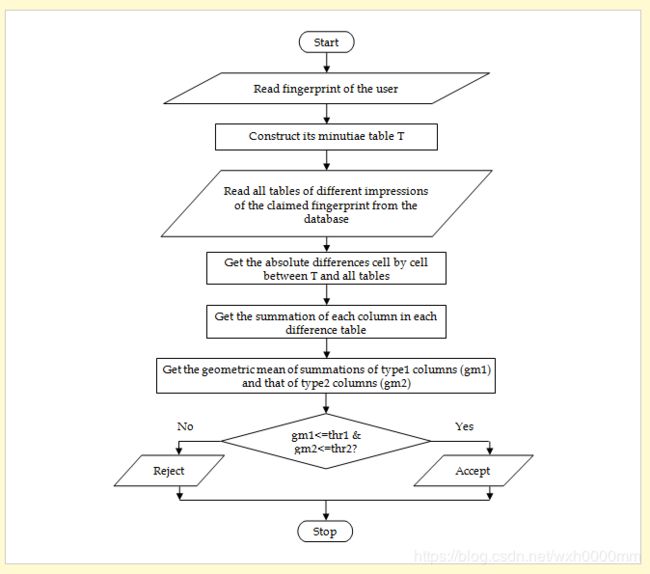
图3。
提议的验证阶段的流程图。
5.1。入学阶段
5.1.1。增强指纹图像
第一步是使用短时傅立叶变换STFT分析来增强指纹图像(O'Gorman,1998)。指纹匹配算法的性能关键取决于输入指纹图像的质量。尽管不能客观地测量指纹图像的质量,但是其大致对应于指纹图像中的脊结构的清晰度,因此有必要增强指纹图像。由于指纹图像可能被认为是具有非平稳特性的定向纹理系统,因此传统的傅立叶分析不足以像STFT分析那样完全分析图像(Yang和Park,2008年)。指纹增强MATLAB代码可在(http://www.hackchina.com/en/cont/18456)。
图像增强算法包括两个阶段,概述如下:
-
STFT分析
-
对于图像中的每个重叠块,通过计算块中像素的梯度来生成和重构脊取向图像,通过获得块的FFT值来生成脊频率图像,并且通过对FFT值的幂进行求和来生成能量图像;
-
使用矢量平均值对定向图像进行平滑处理,以生成平滑的定向图像,并使用平滑的定向图像生成相干图像;
-
通过对能量图像进行阈值生成区域蒙版;
-
应用增强
对于图像中的每个重叠块,将应用以下五个子步骤:
-
生成一个以平滑的定向图像中的定向为中心的角度滤波器Fa,其带宽与相干图像成反比;
-
生成以频率图像为中心的径向滤波器Fr;
-
对FFT域中的一个块进行滤波,F = F×Fa×Fr;
-
通过傅里叶逆变换IFFT(F)生成增强块;
-
通过合成增强块来重建增强图像,并使用区域蒙版生成最终的增强图像。
增强处理的结果示于图4,其中图4 .A从FVC2000 DB1_B(108_5)和截取图4 .B是的增强版本图4 .A。
5.1.2。获取增强指纹的核心点
核心MATLAB代码可在(http://www.hackchina.com/en/cont/18456)中确定参考点的想法来自(Yang&Park,2008),其描述如下:
参考点定义为“凸脊上最大曲率的点(Liu等,2005)”,通常位于指纹的中心区域。参考点位置的可靠检测可以通过使用复杂的滤波方法检测最大曲率来实现(Nilsson和Bigun,2003年)。
他们将复杂的滤波器应用于从原始指纹图像生成的脊取向场图像。下面总结了使用复杂的滤波方法对参考点的可靠检测:
-
对于图像中的每个重叠块;
-
使用STFT分析中的相同方法生成山脊取向图像;

图4。
a)FVC2000中DB1_B的指纹图像108_5,b)指纹图像108_5的增强版。
-
应用相应的复数滤波器h =(x + iy)m g(x,y)以取向图像中的像素方向为中心,其中m和g(x,y)= exp {-(((x 2 + y 2) /2σ 2))}表示的复合过滤器和高斯窗,分别的顺序;
-
对于m = 1 ,可以通过卷积h * O(x,y)= g(y)*((xg(x))t * O(x,y))+ ig来获得每个块的滤波器响应(x)t *((yg(y)* O(x,y)))
其中O(x,y)表示像素取向图像;
-
通过组成过滤后的块来重建过滤后的图像。
滤波图像中复合滤波器的最大响应可以视为参考点。由于只有一个输出,因此将唯一的输出点作为参考点(核心点)。
5.1.3。细节提取
为了从增强的指纹图像中提取细节,使用了细节提取方法(Maltoni et al。,2003)。因此,每个细节都有三个信息:x和y位置坐标,细节类型(如果类型1是终止点,则类型1,如果是分支则是type2)。
此细节提取阶段的结果显示在图5中,其中图5.a与图4.b相同,图5.b显示圆形的终止细节和钻石中的分叉细节以及钻石的分叉细节。指纹的核心点带有星号。

图5。
a)FVC2000中DB1_B的增强指纹图像108_5,b)核心点(星号),终端(圆)和分叉(菱形)。
5.1.4。构造细节表
从细节提取步骤的输出中,建议的细节表的构造如下:
-
获取所有细节位置及其类型。
-
使用欧几里得距离,获取所有细节点和指纹核心点之间的距离:如果核心位置在(x c,y c)上,并且细节点位置在(x,y),则它们之间的欧几里德距离将是:
-
构造以中心点为中心的宽度为10×n像素(其中n = 1…max_distance / 10)的轨道,直到耗尽所有细节为止,将轨道宽度选择为10,因为两个连续脊之间的平均距离(以像素为单位)为10个像素,这是在图 5.a中的指纹108_5中实现的。分辨率为96 dpi。
-
在每个轨道中,计算类型1存在的细节和类型2存在的细节的数量。
-
构造一个两列的表,第1列用于type1细节,第2列用于type2细节,其行数等于找到的轨道数。
-
在第一行中,记录在第一列的第一轨道中找到的type1的细节数量,并在第二列中记录在第一轨道中找到的type2的细节数量。
-
对指纹的其余轨道重复最后一步,直到处理完所有轨道,然后将详细信息表存储在数据库中。
从图5.b得到的细节表如表1所示。第一列仅用于说明,但在MATLAB中不存在,它用作仅由两列组成的详细信息表的每一行的索引。
为了验证该表的数据,在图5.b中发现了两种类型的指纹108_5的细节总数:终止和分叉,它们是细节表的两列的总和,等于51个细节。
| 指纹 | 108_5 | 108_7 | ||
| 追踪号码 | Type1细节的数量 | Type2细节的数量 | Type1细节的数量 | Type2细节的数量 |
| 1个 | 0 | 0 | 1个 | 0 |
| 2 | 1个 | 2 | 1个 | 2 |
| 3 | 0 | 0 | 1个 | 0 |
| 4 | 0 | 1个 | 0 | 0 |
| 5 | 0 | 1个 | 1个 | 2 |
| 6 | 0 | 2 | 1个 | 1个 |
| 7 | 0 | 3 | 6 | 1个 |
| 8 | 2 | 2 | 5 | 1个 |
| 9 | 0 | 2 | 2 | 1个 |
| 10 | 1个 | 2 | 4 | 0 |
| 11 | 6 | 1个 | 3 | 1个 |
| 12 | 3 | 1个 | 2 | 0 |
| 13 | 3 | 0 | 5 | 1个 |
| 14 | 4 | 1个 | 1个 | 1个 |
| 15 | 1个 | 2 | 3 | 1个 |
| 16 | 0 | 1个 | 2 | 1个 |
| 17 | 0 | 0 | 0 | 2 |
| 18 | 1个 | 0 | 2 | 0 |
| 19 | 1个 | 0 | 4 | 1个 |
| 20 | 0 | 0 | 4 | 1个 |
| 21 | 0 | 0 | 3 | 2 |
| 22 | 1个 | 0 | 1个 | 0 |
| 23 | 1个 | 4 | 1个 | 1个 |
| 24 | 0 | 1个 | - | - |
表格1。
FVC2000中DB1_B的指纹108_5和108_7的细节表
5.2。验证阶段
5.2.1。捕获要验证的指纹
声称自己是(例如M)的用户将手指放在扫描仪上,以便在他要访问的应用程序处捕获。现在,可以使用指纹进行验证,以检查他是否实际上是M,以便将其接受或拒绝,从而将其拒绝。
5.2.2。构造该指纹的细节表
5.1节中说明的相同注册步骤将应用于从上一步获得的指纹。现在,将建立对应于被测指纹的细节表T。
5.2.3。从数据库中获取所有对应的细节表
在FVC2000中(Maio等,2002),每个指纹都有八张指纹,因此要验证某个输入指纹,必须获取数据库中存储的该指纹的不同指纹的所有相应细节表。
以作为一个例子的指纹108_7(参见图6从DB1_B在FVC2000采取.a)中进行验证,并应用注册的相同的步骤,该结果示于图6,其中图6 .B示出了增强版本的图6。A,和图6与圆圈的端子,在钻石的分叉并最终在星号核心点的.c显示其减薄版本一起。如图所示,由于图像质量较差,因此细节的数量是如此不同。
现在,细节表已准备就绪,如表1所示。将两种类型的所有细节相加得出的73个细节与之前的指纹108_5的51个细节不同。
遵循相同的步骤,从FVC2000中的DB1_B中获取指纹108_1、108_2、108_3、108_4、108_6和108_8,并将其相应的详细信息表构建在六个表中。
5.2.4。计算输入指纹的细节表与要求保护的指纹的所有细节表之间的绝对差
现在,计算与指纹108_7相对应的细节表与与指纹108_1、108_2、108_3、108_4、108_5、108_6和108_8相对应的所有细节表之间的绝对差。由于细节表的大小(行数)不相等,因此必须确定最小大小,以便能够对不同表的相同大小执行绝对减法。在DB1_B中找到的最小轨道(行)数为14。
因此,在绝对差计算过程中将仅考虑每个细节表的前14行。表2示出了指纹108_7的细节表与指纹108_1和108_2的细节表之间的绝对差。
5.2.5。获取每个差异表中每一列的总和
在标题为“ sum”的行的表2的底部,绘制每个差异表中各列的总和,采用相同的步骤来计算指纹108_7的细节表和指纹108_3的细节表之间的绝对差, 108_4、108_5、108_6和108_8将为type1列生成七个求和,对于type2列生成其他七个求和。

图6。
a)FVC2000中DB1_B的指纹图像108_7,b)指纹图像108_7的增强版,c)核心点(星号),终端(圆)和分叉(菱形)。
5.2.6。获取类型1和类型2的结果求和的几何平均值
获取所有差异表中type1列的总和的几何平均值。在数学中,几何均值是一种均值或平均值,它表示一组数字的中心趋势或典型值(http://en.wikipedia.org/wiki/Geometric_mean)。它类似于算术平均值,是大多数人对“平均值”一词的看法,只是将数字相乘然后是结果乘积的第n 个根(其中n是集合中数字的个数)被采取。
获取所有差异表中type2列的总和的几何平均值。
检查gm1和gm2的值:
如果gm1 <= threshold1和gm2 <= threshold2,则
用户是真实的并接受他
其他
用户冒名顶替并拒绝他
| 绝对(108_7-108_1) | 绝对(108_7-108_2) | |||
| 追踪号码 | Type1细节的数量 | Type2细节的数量 | Type1细节的数量 | Type2细节的数量 |
| 1个 | 0 | 0 | 1个 | 0 |
| 2 | 0 | 2 | 1个 | 1个 |
| 3 | 0 | 0 | 0 | 0 |
| 4 | 0 | 1个 | 2 | 0 |
| 5 | 2 | 1个 | 0 | 1个 |
| 6 | 2 | 1个 | 1个 | 1个 |
| 7 | 2 | 1个 | 3 | 1个 |
| 8 | 5 | 0 | 4 | 1个 |
| 9 | 2 | 0 | 1个 | 1个 |
| 10 | 4 | 0 | 2 | 0 |
| 11 | 2 | 1个 | 3 | 1个 |
| 12 | 1个 | 1个 | 1个 | 0 |
| 13 | 4 | 1个 | 4 | 1个 |
| 14 | 1个 | 0 | 1个 | 1个 |
| 和 | 25 | 9 | 24 | 9 |
表2。
指纹108_7的细节表与指纹108_1、108_2的两个细节表之间的绝对差。
5.3。绩效评估
为了评估任何匹配算法的性能,必须测量一些重要的量,例如(Maio等,2002):
-
错误不匹配率(FNMR)通常称为错误拒绝率(FRR)
-
错误匹配率(FMR)通常称为错误接受率(FAR)
-
均等错误率(EER)
-
零核磁共振
-
零FMR
-
平均入学时间
-
平均比赛时间
因为在FVC2000中不能保证指纹核心和增量的存在,因为没有注意检查传感器上正确的手指位置(Maio等,2002),并且核心点检测是所提出的匹配的第一步通过算法,另一组指纹已通过实验捕获;该组包含20个不同人的正确食指,每个人被捕获3次,具有60个不同的指纹图像。它们的编号如下:101_1、101_2、101_3、102_1,....,120_1、120_2、120_3。所有这些指纹都有一个核心点。将首先测试该组,然后再测试四个数据库DB1,DB2,DB3和DB4(来自FVC2000)。实现了用于评估所提出算法性能的所有步骤。
5.3.1。计算错误的非匹配率(FNMR)或错误拒绝率(FRR)
将每个指纹模板(细节表)T ij,i = 1…20,j = 1…3与F i的指纹图像(细节表)进行匹配,并存储相应的正版匹配分数(GMS)。匹配数(表示为NGRA –真正的认可尝试数(Maio等,2002))为20×3 = 60。
现在,可以根据不同阈值从GMS分布轻松计算FRR(t)曲线。给定的阈值吨,FRR(吨)表示的GMS≥百分比吨。在这里,由于验证了输入指纹是否在对应的细节表之间给出的差值较小,因此较低的分数与更紧密匹配的图像相关联。这与指纹验证中大多数指纹匹配算法相反,在指纹验证算法中,更高的分数与更紧密匹配的图像相关联。因此,FRR(t)(或FNMR(t))曲线将通常从左侧开始,而不是从右侧开始。另外,值得注意的是,FRR(t)的曲线将是2D曲面(FRR(t 1,t 2)),因为前一节提到了两个阈值。
例如,考虑将指纹101_1或其任何稍有不同的版本与其他指纹101_2、101_3相匹配,这被认为是真正的识别尝试,因为它们都来自同一指纹。图7显示了指纹101_1及其增强的减薄版本,其中实点显示为实心圆,终端显示为圆圈,而分叉显示为菱形。
作为示例,一些噪声被施加在指纹101_1的细节表上,以充当新用户的指纹。噪声是来自均匀离散分布的伪随机整数序列,用于从细节表中随机选择轨道,将通过在终止(或分叉)列下的值加“ 1”并在分支(或分叉)下的值减去“ 1”来更改终止”列)。使用称为“ randi”的Matlab函数生成的数字序列由统一伪随机数生成器的内部状态确定。随机选择的轨道数是每个数据库中轨道总数的恒定比率(30%)。
现在,将从数据库中获取指纹101_1、101_2和101_3的详细信息表。发现正在研究的数据库中所有细节表的最小行数(轨道)为13,因此在绝对差的计算过程中仅考虑任何细节表的前13行。

图7。
指纹101_1及其增强的细化版本。
第二步是计算类型1和类型2绝对差之和的几何平均值:
然后,由于两个几何均数满足以下条件,则将接受用户:
使用Demorgan定律,(FNMR)或错误拒绝率的计算如下:
其中NGMS1s是根据gm1值计算出的真实匹配分数的数量,NGMS2s是根据gm2值计算出的真实匹配分数的数量,NGRA是真实识别尝试的次数,其值为60。阈值t 1和t 2,从1到100不等。
对所有60个实例的其余指纹执行相同的步骤。前面的示例被认为是一次真正的识别尝试,因为在这三张照片的第一张的嘈杂版本与从数据库中获取的三张真实版本之间进行了比较。
5.3.2。计算错误匹配率(FMR)或错误接受率(FAR)
数据库中的每个指纹模板(细节表)T ij,i = 1…20,j = 1…3与来自不同手指的其他指纹图像(细节表)F k,k ≠ i和对应的冒名顶替者匹配分数进行匹配即时消息已存储。冒名顶替者识别尝试次数为(20×3)×(20-1)= 60×19 = 1140。
现在,可以根据不同阈值的IMS分布轻松计算FAR(t 1,t 2)曲面。给定阈值t 1和t 2,FAR(t 1,t 2)表示IMS1s <= t 1和IMS2s <= t 2的百分比。这里,因为如果输入指纹在相应的细节表之间给出高差值,则拒绝输入指纹;分数越高,图像就越不匹配。这与指纹验证中大多数指纹匹配算法相反,在指纹验证算法中,较低的分数与不匹配的图像相关。因此,FAR(t 1,t 2)(或FMR(t 1,t 2))表面将通常从右侧开始而不是从左侧开始。
例如,考虑将指纹101_1的嘈杂版本与另一个指纹(如103)进行匹配,这被视为冒名顶替者的尝试,因为它们来自不同的手指。现在,必须从数据库中提取指纹103_1、103_2和103_3的所有细节表。如前所述,由于最小行数为13,因此在绝对差值表的计算过程中仅考虑任何细节表的前13行。
几何平均值gm1和gm2计算如下:
其余指纹执行相同的步骤。所有60个实例(20个指纹,每个指纹具有3个印象)将与其他19个指纹匹配,因此共有1140个IMS。
FMR(t 1,t 2)的计算如下:
其中NIMS1s是根据gm1值计算出的冒名顶替者匹配分数的数量,NIMS2s是根据gm2值计算出的冒名顶替者匹配分数的数量,NIRA是冒名顶替者识别尝试的次数,即1140。阈值t 1和t 2,从1到70。
图8中分别用蓝色和红色绘制了两个表面FRR(t 1,t 2)和FAR(t 1,t 2)。两个表面之间的交点用下一节中使用的实线绘制。
5.3.3。均等错误率EER
均等错误率被计算为FMR(t)= FNMR(t)的点。根据图8,为了确定相等的错误率,绘制了两个表面之间的相交线,然后沿着这条线的错误率的最小值是EER,从中可以确定阈值t 1和t 2的值。

图8。
FRR和FAR曲面,其中两个曲面之间的交点用实线绘制。
在图8中,示出了EER = 0.0179,其中其对应于t 1= 16.92 的阈值和t 2= 8.21的阈值,阈值的值并不总是整数,因为两个表面不必在阈值的整数值。
现在要确定对应于错误率FRR和FAR的阈值的整数值,测试了之前给出的两个阈值周围的四个阈值可能组合,并给出了FRR和FAR之间的最小差值的两个值组合(因为定义了EER (FRR和FAR相等的点)被认为是阈值t 1和t 2,该阈值将用于该数据库以用于以后的任何指纹识别操作。
因此,阈值t 1和t 2可以采用四个可能的组合:(16,8),(16,9),(17,8)和(17,9)。通过实验发现,组合(17,8)使FAR和FRR之间的差异最小。因此,当在建议的匹配算法中使用这些阈值时,结果是FRR = 0.0167和FAR = 0.0184。
真实接受率为
真正的拒绝率是
因此,当阈值为t 1 = 17且t 2 = 8 时,识别精度约为98%。
5.3.4。ZeroFMR和ZeroFNMR
ZeroFMR被定义为不发生错误匹配的最低FNMR,ZeroFNMR被定义为不发生错误不匹配的最低FMR(Maio等,2002):
因为现在将FRR(FNMR)和FAR(FMR)绘制为2D表面,所以确定了具有零值的FAR点的所有位置,并且在这些位置处相应的FRR值的最小值为ZeroFAR。另外,为了计算ZeroFAR值,确定具有零值的FRR点的所有位置,并且在这些位置处的相应FAR值的最小值为ZeroFRR。
从图8中得出以下值:
5.3.5。绘制ROC曲线
给出了ROC(接收工作曲线),其中将FNMR绘制为FMR的函数;为了更好地理解,曲线以对数-对数比例绘制(Maio等,2002)。为了在x轴和y轴的正数部分绘制曲线,在对数上应用FMR和FNMR值之前,将其乘以100。图9显示了提出的匹配算法的ROC曲线。为了得到一条曲线,在将FAR矩阵的一列乘以100并在两者上均采用对数后,仅在FRR矩阵的一列上绘制FAR矩阵的一列。可以证明,与(O'Gorman,1998)所见的良好识别性能系统的曲线相比,识别性能良好。注意,图9中的曲线移至绘图区域的右上方,而(O'Gorman,1998)中的良好识别性能曲线则移至绘图区域的左下方。
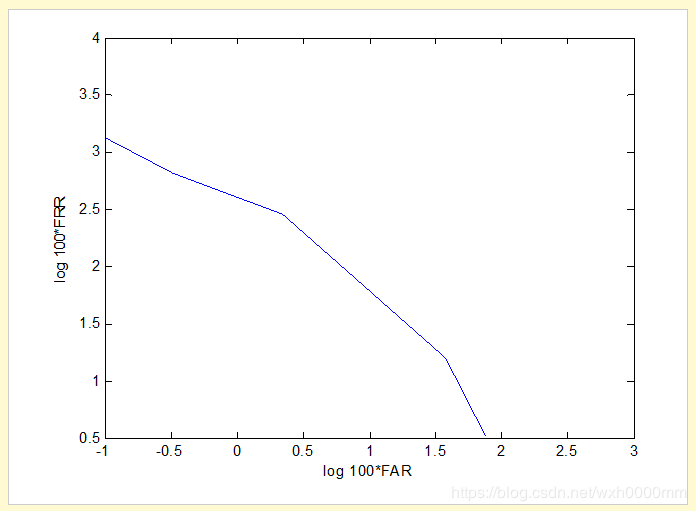
图9。
ROC曲线
绘制区域,这是因为在提出的匹配算法中,较低的分数与匹配的指纹相关联,而较高的分数与不匹配的指纹相关联。这与指纹验证中大多数指纹匹配算法相反。
5.3.6。提出的匹配算法在FVC2000上的应用
在数据库FVC2000的前几节中应用建议的匹配算法和所有上述步骤,与前几节中获得的结果相比,预期不会获得良好的结果。这是由于5.3节开头提到的原因。表3和表4显示了在FVC2000上提出的匹配算法的结果。
如图所示,识别精度的范围从(DB2_B为1-0.2315)77%到(DB3_B为1-0.0882)91%。
| 数据库 | 能源效率 | Ť 1 | 第2 |
| DB1_A | 0.2109 | 18岁 | 6.99 |
| DB1_B | 0.1988 | 31.68 | 10 |
| DB2_A | 0.1649 | 18.48 | 8 |
| DB2_B | 0.2315 | 24.096 | 14 |
| DB3_A | 0.1454 | 28 | 12.55 |
| DB3_B | 0.0882 | 28 | 12.85 |
| DB4_A | 0.1815 | 10 | 4.88998 |
| DB4_B | 0.1206 | 14.35 | 9 |
表3。
在FVC2000上应用提出的匹配算法后的EER结果及其对应的阈值
| 数据库 | 远 | 财务报告率 | Ť 1 | 第2 |
| DB1_A | 0.2113 | 0.2105 | 18岁 | 7 |
| DB1_B | 0.2049 | 0.1944 | 32 | 10 |
| DB2_A | 0.1835 | 0.15 | 18岁 | 9 |
| DB2_B | 0.2403 | 0.2375 | 24 | 15 |
| DB3_A | 0.1325 | 0.1525 | 29 | 12 |
| DB3_B | 0.0944 | 0.075 | 28 | 13 |
| DB4_A | 0.1844 | 0.1788 | 10 | 5 |
| DB4_B | 0.1153 | 0.125 | 14 | 10 |
表4。
在FVC2000上应用建议的匹配算法后,FAR和FRR的结果及其对应的阈值
图10和图11分别显示了数据库DB1_A,DB2_A,DB2_B,DB3_A和DB4_A的左侧FRR和FAR表面以及右侧的ROC曲线。
5.3.7。计算平均注册时间
平均注册时间计算为单个注册操作所花费的平均CPU时间(Maio等,2002)。录入步骤将在5.1节中讨论。表5显示了注册阶段每个步骤的详细时间安排。这些结果是使用MATLAB版本7.9.0529(R2009b)作为编程平台来实现的。程序在具有1.99 GB RAM的2.00GHz个人计算机上进行了测试。
发现总注册时间为6.043秒
| 步 | 平均耗时(秒) |
| 增强指纹 | 3.7 |
| 核心点检测 | 0.54 |
| 稀疏和细节提取 | 1.8 |
| 细节表构造 | 0.003 |
| 总注册时间 | 6.043 |
表5。
报名时间详情
5.3.8。计算平均比赛时间
平均匹配时间被计算为模板和指纹图像之间的单个匹配操作所花费的平均CPU时间(Maio等,2002)。匹配步骤在5.2节中讨论。表6显示了在构造对应于输入指纹的细节表之后,匹配阶段中每个步骤的详细时序,根据第5.3.7节已将其估计为6.043秒。
发现总比赛时间为0.00134秒
| 步 | 平均耗时(秒) |
| 获取存储在数据库中的已声明指纹的所有细节表 | 0.0011 |
| 计算输入的fgp细节表与从上一步获得的所有细节表之间的绝对差,并获得两个几何平均值 | 0.0002 |
| 将结果均值与两个阈值进行比较,并确定用户是被接受还是被拒绝 | 0.00004 |
| 总比赛时间 | 0.00134 |
表6。
比赛时间细节

图10。
分别针对DB1_A,DB2_A和DB2_B的FAR,FRR和ROC曲线。
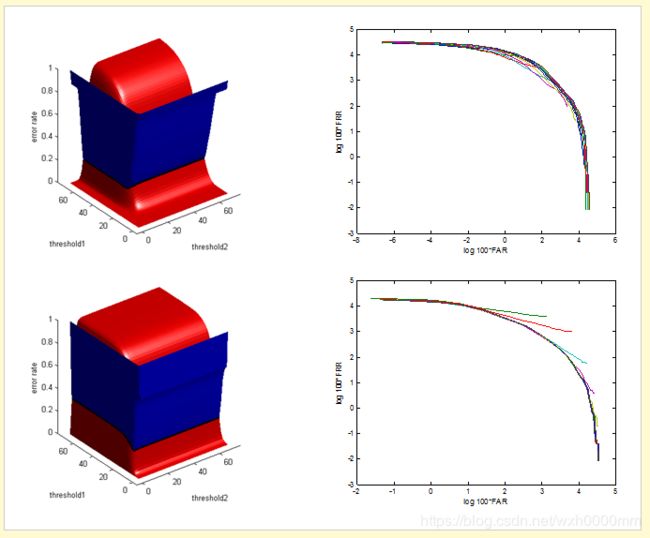
图11。
DB3_A,DB4_A的FAR,FRR和ROC曲线分别。
六,结论
如图所示,使用我们的算法进行匹配的时间非常短,因为所有过程都采用绝对差的几何平均值。不需要任何预对准,这是非常复杂且耗时的过程。结果,我们的算法是平移和旋转不变的。
此外,存储任何细节表所需的空间平均为21(作为所有数据库中的平均轨道数)×2×4 = 168位= 168/8字节= 21字节,与85的大小相比较小字节(Jain&Uludag,2002),其中传统方法将每个细节的位置和方向存储为元组