HAWQ取代传统数仓实践(十九)——OLAP
一、OLAP简介
1. 概念
OLAP是英文是On-Line Analytical Processing的缩写,意为联机分析处理。此概念最早由关系数据库之父E.F.Codd于1993年提出。OLAP允许以一种称为多维数据集的结构,访问业务数据源经过聚合和组织整理后的数据。以此为标准,OLAP作为单独的一类技术同联机事务处理(On-Line Transaction Processing,OLTP)得以明显区分。在计算领域,OLAP是一种快速应答多维分析查询的方法,也是商业智能的一个组成部分,与之相关的概念还包括数据仓库、报表系统、数据挖掘等。数据仓库用于数据的存储和组织,OLAP集中于数据的分析,数据挖掘则致力于知识的自动发现,报表系统则侧重于数据的展现。OLAP系统从数据仓库中的集成数据出发,构建面向分析的多维数据模型,再使用多维分析方法从多个不同的视角对多维数据集合进行分析比较,分析活动以数据驱动。通过使用OLAP工具,用户可以从多个视角交互式地查询多维数据。
OLAP由三个基本的分析操作构成:合并(上卷)、下钻和切片。合并是指数据的聚合,即数据可以在一个或多个维度上进行累积和计算。例如,所有的营业部数据被上卷到销售部门以分析销售趋势。下钻是一种由汇总数据向下浏览细节数据的技术。比如用户可以从产品分类的销售数据下钻查看单个产品的销售情况。切片则是这样一种特性,通过它用户可以获取OLAP立方体中的特定数据集合,并从不同的视角观察这些数据。这些观察数据的视角就是我们所说的维度。例如通过经销商、日期、客户、产品或区域等等,查看同一销售事实。
OLAP系统的核心是OLAP立方体,或称为多维立方体或超立方体。它由被称为度量的数值事实组成,这些度量被维度划分归类。一个OLAP立方体的例子如图1所示,数据单元位于立方体的交叉点上,每个数据单元跨越产品、时间、地区等多个维度。通常使用一个矩阵接口操作OLAP立方体,例如电子表格程序的数据透视表,可以按维度分组执行聚合或求平均值等操作。立方体的元数据一般由关系数据库中的星型模式或雪花模式生成,度量来自事实表的记录,维度来自维度表。
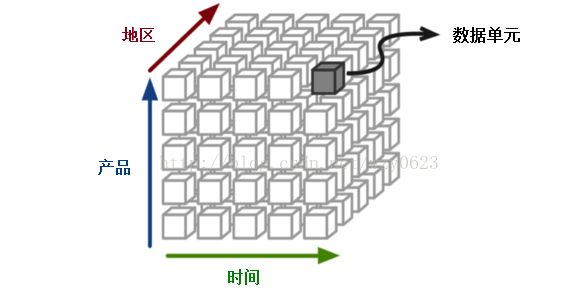
图1
2. 分类
通常可以将联机分析处理系统分为MOLAP、ROLAP、HOLAP三种类型。(1)MOLAP
MOLAP(multi-dimensional online analytical processing)是一种典型的OLAP形式,甚至有时就被用来表示OLAP。MOLAP将数据存储在一个经过优化的多维数组中,而不是存储在关系数据库中。某些MOLAP工具要求预先计算并存储计算后的结果数据,这种操作方式被称为预处理。MOLAP工具一般将预计算后的数据集合作为一个数据立方体使用。对于给定范围的问题,立方体中的数据包含所有可能的答案。预处理的好处是可以对问题作出非常快速地响应。然而另一方面,依赖于预计算的聚合程度,装载新数据可能会花费很长的时间。另外还有些MOLAP工具,尤其是那些实现了某些数据库功能的MOLAP工具,并不预先计算原始数据,而是在需要时才进行计算。
MOLAP的优点:
- 优化的数据存储、多维数据索引和缓存带来的快速查询性能。
- 相对于关系数据库,可以通过压缩技术,使数据存储需要更小的磁盘空间。
- MOLAP工具一般能够自动进行高级别的数据聚合。
- 对于低基数维度的数据集合是紧凑的。
- 数组模型提供了原生的索引功能。
- 某些MOLAP解决方案中的处理步骤可能需要很长的时间,尤其是当数据量很大时。要解决这个问题,通常只能增量处理变化的数据,而不是预处理整个数据集合。
- 可能引入较多的数据冗余。
商业的MOLAP产品主要有Cognos Powerplay、Oracle Database OLAP Option、MicroStrategy、Microsoft Analysis Services、Essbase等。
(2)ROLAP
ROLAP直接使用关系数据库存储数据,不需要执行预计算。基础的事实数据及其维度表作为关系表被存储,而聚合信息存储在新创建的附加表中。ROLAP以数据库模式设计为基础,操作存储在关系数据库中的数据,实现传统的OLAP数据切片和分块功能。本质上讲,每种数据切片或分块行为都等同于在SQL语句中增加一个“WHERE”子句的过滤条件。ROLAP不使用预计算的数据立方体,取而代之的是查询标准的关系数据库表,返回回答问题所需的数据。与预计算的MOLAP不同,ROLAP工具有能力回答任意相关的数据分析问题,因为该技术不受立方体内容的限制。通过ROLAP还能够下钻到数据库中存储的最细节的数据。
由于ROLAP使用关系数据库,通常数据库模式必须经过仔细设计。为OLTP应用设计的数据库不能直接作为ROLAP数据库使用,这种投机取巧的做法并不能使ROLAP良好工作。因此ROLAP仍然需要创建额外的数据拷贝。但不管怎样,ROLAP毕竟用的是数据库,各种各样的数据库设计与优化技术都可以被有效利用。
ROLAP的优点:
- 在处理大量数据时,ROLAP更具可伸缩性,尤其是当模型中包含的维度具有很高的基数,例如,维度表中有上百万的成员时。
- 有很多可选用的数据装载工具,并且能够针对特定的数据模型精细调整ETL代码,数据装载所需时间通常比自动化的MOLAP装载少的多。
- 因为数据存储于标准关系数据库中,可以使用SQL报表工具访问数据,而不必是专有的OLAP工具。
- ROLAP更适合处理非聚合的事实,例如文本型描述。在MOLAP工具中查询文本型元素时性能会相对较差。
- 通过将数据存储从多维模型中解耦出来,相对于用使用严格的维度模型,这种更普通的关系模型增加了成功建模的可能性。
- ROLAP方法可以利用数据库的权限控制,例如通过行级安全性设置,可以用事先设定的条件过滤查询结果。例如Oracle的VPD技术,能够根据连接的用户自动在查询的SQL语句中拼接WHERE谓词条件。
- 业界普遍认为ROLAP工具比MOLAP查询速度慢。
- 聚合表的数据装载必须由用户自己定制的ETL代码控制。ROLAP工具不能自动完成这个任务,这意味着额外的开发工作量。
- 如果跳过创建聚合表的步骤,查询性能会大打折扣,因为不得不查询大量的细节数据表。虽然可以通过适当建立聚合表缓解性能问题,但对所有维度表及其属性的组合创建聚合表是不切实际的。
- ROLAP依赖于针对通用查询或缓存目标的数据库,因此并没有提供某些MOLAP工具所具有的特殊技术,如透视表等。但是现代ROLAP工具可以利用SQL语言中的CUBE、ROLLUP操作或其它SQL OLAP扩展。随着这些SQL扩展的逐步完善,MOLAP工具的优势也不那么明显了。
- 因为ROLAP工具的所有计算都依赖于SQL,对于某些不易转化为SQL的计算密集型模型,ROLAP不再适用。例如包含预算、拨款等条目的复杂财务报表或地理位置计算的场景。
使用ROLAP的商业产品包括Microsoft Analysis Services、MicroStrategy、SAP Business Objects、Oracle Business Intelligence Suite Enterprise Edition、 Tableau Software等等。也有开源的ROLAP服务器,如Mondrian。
(3)HOLAP
在额外的ETL开发成本与缓慢的查询性能之间难以选择,正是因为这种情况,现在大部分商业OLAP工具都使用一种混合型(Hybrid)方法,它允许模型设计者决定哪些数据存储在MOLAP中,哪些数据存储在ROLAP中。除了把数据划分成传统关系型存储和专有存储,业界对混合型OLAP并没有清晰的定义。例如,某些厂商的HOLAP数据库使用关系表存储大量的细节数据,而是用专用表保存少量的聚合数据。HOLAP结合了MOLAP和ROLAP两种方法的优点,可以同时利用预计算的多维立方体和关系数据源。HOLAP有以下两种划分数据的策略。
- 垂直分区。这种模式的HOLAP将聚合数据存储在MOLAP中,以支持良好的查询性能,而把细节数据存储在ROLAP中以减少立方体处理所需时间。
- 水平分区。这种模式的HOLAP按数据热度划分,将某些最近使用的数据分片存储在MOLAP中,而将老的数据存储在ROLAP。
3. 性能
OLAP分析所需的原始数据量是非常庞大的。一个分析模型,往往会涉及数千万或数亿条甚至更多的数据,而且分析模型中包含多个维度数据,这些维度又可以由用户作任意的组合。这样的结果就是大量的实时运算导致过长的响应时间。想象一个1000万条记录的分析模型,如果一次提取4个维度进行组合分析,每个维度有10个不同的取值,理论上的运算次数将达到10的12次方。这样的运算量将导致数十分钟乃至更长的等待时间。如果用户对维组合次序进行调整,或增加、或减少某些维度的话,又将是一个重新的计算过程。从上面的分析中可以得出结论,如果不能解决OLAP运算效率问题的话,OLAP将只会是一个没有实用价值的概念。在OLAP的发展历史中,常见的解决方案是用多维数据库代替关系数据库设计,将数据根据维度进行最大限度的聚合运算,运算中会考虑到各种维度组合情况,运算结果将生成一个数据立方体,并保存在磁盘上,用这种预运算方式提高OLAP的速度。例如Kylin就是使用这种以空间换时间的方式来提高查询速度,而HAWQ在性能上的优势,也使它较为适合OLAP应用。HAWQ与Hive的性能对比,参见“HAWQ与Hive查询性能对比测试”。(http://blog.csdn.net/wzy0623/article/details/71479539)
二、OLAP实例
要做好OLAP类的应用,需要对业务数据有深入的理解。只有了解了业务,才能知道需要分析哪些指标,从而有的放矢地剖析相关数据,得出可信的结论来辅助决策。下面就以销售订单数据仓库为例,提出若干问题,然后使用HAWQ查询数据以回答这些问题:- 每种产品类型以及单个产品的累积销售量和销售额是多少?
- 每种产品类型以及单个产品在每个省、每个城市的月销售量和销售额趋势是什么?
- 每种产品类型销售量和销售额和同比如何?
- 每个省以及每个城市的客户数量及其消费金额汇总是多少?
- 迟到订单的比例是多少?
- 客户年消费金额的平均数和中位数是多少?
- 客户年消费金额分布处于25%、50%、75%位置的消费金额是多少?
- 客户年消费金额为“高”、“中”、“低”档的人数及消费金额所占比例是多少?
- 每个城市按销售金额排在前三位的商品是什么?
- 所有产品的销售百分比排名?
1. 每种产品类型以及单个产品的累积销售量和销售额是多少?
使用HAWQ的group by rollup求小计和总计。dw=> select t2.product_category, t2.product_name, sum(nq), sum(order_amount)
dw-> from v_sales_order_fact t1, product_dim t2
dw-> where t1.product_sk = t2.product_sk
dw-> group by rollup (t2.product_category, t2.product_name)
dw-> order by t2.product_category, t2.product_name;
product_category | product_name | sum | sum
------------------+-----------------+-----+-----------
monitor | flat panel | | 49666.00
monitor | lcd panel | 11 | 3087.00
monitor | | 11 | 52753.00
peripheral | keyboard | 38 | 67387.00
peripheral | | 38 | 67387.00
storage | floppy drive | 52 | 348655.00
storage | hard disk drive | 80 | 375481.00
storage | | 132 | 724136.00
| | 181 | 844276.00
(9 rows)2. 每种产品类型以及单个产品在每个省、每个城市的月销售量和销售额是多少?
查询语句与上一个问题类似,只是多关联了邮编维度表,并且在group by rollup中增加了省、市两列。dw=> select t2.product_category, t2.product_name, t3.state, t3.city, sum(nq), sum(order_amount)
dw-> from v_sales_order_fact t1, product_dim t2, zip_code_dim t3
dw-> where t1.product_sk = t2.product_sk
dw-> and t1.customer_zip_code_sk = t3.zip_code_sk
dw-> group by rollup (t2.product_category, t2.product_name, t3.state, t3.city)
dw-> order by t2.product_category, t2.product_name, t3.state, t3.city;
product_category | product_name | state | city | sum | sum
------------------+-----------------+-------+---------------+-----+-----------
monitor | flat panel | oh | cleveland | | 7431.00
monitor | flat panel | oh | | | 7431.00
monitor | flat panel | pa | mechanicsburg | | 10630.00
monitor | flat panel | pa | pittsburgh | | 31605.00
monitor | flat panel | pa | | | 42235.00
monitor | flat panel | | | | 49666.00
monitor | lcd panel | pa | pittsburgh | 11 | 3087.00
monitor | lcd panel | pa | | 11 | 3087.00
monitor | lcd panel | | | 11 | 3087.00
monitor | | | | 11 | 52753.00
peripheral | keyboard | oh | cleveland | 38 | 10875.00
peripheral | keyboard | oh | | 38 | 10875.00
peripheral | keyboard | pa | mechanicsburg | | 29629.00
peripheral | keyboard | pa | pittsburgh | | 26883.00
peripheral | keyboard | pa | | | 56512.00
peripheral | keyboard | | | 38 | 67387.00
peripheral | | | | 38 | 67387.00
storage | floppy drive | oh | cleveland | | 8229.00
storage | floppy drive | oh | | | 8229.00
storage | floppy drive | pa | mechanicsburg | | 140410.00
storage | floppy drive | pa | pittsburgh | 52 | 200016.00
storage | floppy drive | pa | | 52 | 340426.00
storage | floppy drive | | | 52 | 348655.00
storage | hard disk drive | oh | cleveland | | 8646.00
storage | hard disk drive | oh | | | 8646.00
storage | hard disk drive | pa | mechanicsburg | 80 | 194444.00
storage | hard disk drive | pa | pittsburgh | | 172391.00
storage | hard disk drive | pa | | 80 | 366835.00
storage | hard disk drive | | | 80 | 375481.00
storage | | | | 132 | 724136.00
| | | | 181 | 844276.00
(31 rows)3. 每种产品类型销售量和销售额和同比如何?
需要查询周期快照v_month_end_sales_order_fact。dw=> select t2.product_category,
dw-> t1.year_month,
dw-> sum(quantity1) quantity_cur,
dw-> sum(quantity2) quantity_pre,
dw-> round((sum(quantity1) - sum(quantity2)) / sum(quantity2),2) pct_quantity,
dw-> sum(amount1) amount_cur,
dw-> sum(amount2) amount_pre,
dw-> round((sum(amount1) - sum(amount2)) / sum(amount2),2) pct_amount
dw-> from (select t1.product_sk,
dw(> t1.year_month,
dw(> t1.month_order_quantity quantity1,
dw(> t2.month_order_quantity quantity2,
dw(> t1.month_order_amount amount1,
dw(> t2.month_order_amount amount2
dw(> from v_month_end_sales_order_fact t1
dw(> join v_month_end_sales_order_fact t2
dw(> on t1.product_sk = t2.product_sk
dw(> and t1.year_month/100 = t2.year_month/100 + 1
dw(> and t1.year_month - t1.year_month/100*100 = t2.year_month - t2.year_month/100*100) t1,
dw-> product_dim t2
dw-> where t1.product_sk = t2.product_sk
dw-> group by t2.product_category, t1.year_month
dw-> order by t2.product_category, t1.year_month;
product_category | year_month | quantity_cur | quantity_pre | pct_quantity | amount_cur | amount_pre | pct_amount
------------------+------------+--------------+--------------+--------------+------------+------------+------------
storage | 201705 | 943 | | | 142814.00 | 110172.00 | 0.30
storage | 201706 | 110 | | | 9132.00 | 116418.00 | -0.92
(2 rows)4. 每个省以及每个城市的客户数量及其消费金额汇总是多少?
dw=> select t2.state,
dw-> t2.city,
dw-> count(distinct customer_sk) sum_customer_num,
dw-> sum(order_amount) sum_order_amount
dw-> from v_sales_order_fact t1, zip_code_dim t2
dw-> where t1.customer_zip_code_sk = t2.zip_code_sk
dw-> group by rollup (t2.state, t2.city)
dw-> order by t2.state, t2.city;
state | city | sum_customer_num | sum_order_amount
-------+---------------+------------------+------------------
oh | cleveland | 4 | 35181.00
oh | | 4 | 35181.00
pa | mechanicsburg | 8 | 375113.00
pa | pittsburgh | 12 | 433982.00
pa | | 20 | 809095.00
| | 24 | 844276.00
(6 rows)5. 迟到订单的比例是多少?
注意,sum_late需要显式转化为numeric数据类型。dw=> select sum_total, sum_late, round(cast(sum_late as numeric)/sum_total,4) late_pct
dw-> from (select sum(case when status_date_sk < entry_date_sk then 1
dw(> else 0
dw(> end) sum_late,
dw(> count(*) sum_total
dw(> from sales_order_fact) t;
sum_total | sum_late | late_pct
-----------+----------+----------
151 | 2 | 0.0132
(1 row)6. 客户年消费金额的平均数和中位数是多少?
分别使用两种方法求得平均数和中位数。HAWQ为分析型应用提供了丰富的聚合函数。dw=> select round(avg(sum_order_amount),2) avg_amount,
dw-> round(sum(sum_order_amount)/count(customer_sk),2) avg_amount1,
dw-> percentile_cont(0.5) within group (order by sum_order_amount) median_amount,
dw-> median(sum_order_amount) median_amount1
dw-> from (select customer_sk,sum(order_amount) sum_order_amount
dw(> from v_sales_order_fact
dw(> group by customer_sk) t1;
avg_amount | avg_amount1 | median_amount | median_amount1
------------+-------------+---------------+----------------
35178.17 | 35178.17 | 14277 | 14277
(1 row)7. 客户年消费金额分布处于25%、50%、75%位置的消费金额是多少?
dw=> select percentile_cont(0.25) within group (order by sum_order_amount desc) max_amount_25,
dw-> percentile_cont(0.50) within group (order by sum_order_amount desc) max_amount_50,
dw-> percentile_cont(0.75) within group (order by sum_order_amount desc) max_amount_75
dw-> from (select customer_sk,sum(order_amount) sum_order_amount
dw(> from v_sales_order_fact
dw(> group by customer_sk) t1;
max_amount_25 | max_amount_50 | max_amount_75
---------------+---------------+---------------
50536.5 | 14277 | 8342.25
(1 row)8. 客户年消费金额为“高”、“中”、“低”档的人数及消费金额所占比例是多少?
使用在“ HAWQ取代传统数仓实践(十二)——维度表技术之分段维度”中定义的分段进行查询。dw=> select year1,
dw-> bn,
dw-> c_count,
dw-> sum_band,
dw-> sum_total,
dw-> round(sum_band/sum_total,4) band_pct
dw-> from (select count(a.customer_sk) c_count,
dw(> sum(annual_order_amount) sum_band,
dw(> a.year year1,
dw(> band_name bn
dw(> from annual_customer_segment_fact a,
dw(> annual_order_segment_dim b,
dw(> annual_sales_order_fact d
dw(> where a.segment_sk = b.segment_sk
dw(> and a.customer_sk = d.customer_sk
dw(> and a.year = d.year
dw(> and b.segment_name = 'grid'
dw(> group by a.year, bn) t1,
dw-> (select sum(annual_order_amount) sum_total
dw(> from annual_sales_order_fact) t2
dw-> order by year1, bn;
year1 | bn | c_count | sum_band | sum_total | band_pct
-------+------+---------+-----------+-----------+----------
2016 | high | 6 | 572190.00 | 572190.00 | 1.0000
(1 row)9. 每个城市按销售金额排在前三位的商品是什么?
使用HAWQ提供的窗口函数row_number(),按城市分区,按销售额倒序,取得销售排名。dw=> select case when t1.rn =1 then t1.city end city,
dw-> t2.product_name,
dw-> t1.sum_order_amount,
dw-> t1.rn
dw-> from (select city,
dw(> product_sk,
dw(> sum_order_amount,
dw(> row_number() over (partition by city order by sum_order_amount desc) rn
dw(> from (select t2.state||':'||t2.city city,
dw(> product_sk,
dw(> sum(order_amount) sum_order_amount
dw(> from v_sales_order_fact t1, zip_code_dim t2
dw(> where t1.customer_zip_code_sk = t2.zip_code_sk
dw(> group by t2.state||':'||t2.city, product_sk) t) t1
dw-> inner join product_dim t2 on t1.product_sk = t2.product_sk
dw-> where t1.rn <= 3
dw-> order by t1.city, t1.rn;
city | product_name | sum_order_amount | rn
------------------+-----------------+------------------+----
oh:cleveland | keyboard | 10875.00 | 1
| hard disk drive | 8646.00 | 2
| floppy drive | 8229.00 | 3
pa:mechanicsburg | hard disk drive | 194444.00 | 1
| floppy drive | 140410.00 | 2
| keyboard | 29629.00 | 3
pa:pittsburgh | floppy drive | 200016.00 | 1
| hard disk drive | 172391.00 | 2
| flat panel | 31605.00 | 3
(9 rows)10. 所有产品的销售百分比排名?
dw=> select product_name,
dw-> sum_order_amount,
dw-> percent_rank() over (order by sum_order_amount desc) rank
dw-> from (select product_sk,sum(order_amount) sum_order_amount
dw(> from v_sales_order_fact
dw(> group by product_sk) t1, product_dim t2
dw-> where t1.product_sk = t2.product_sk
dw-> order by rank;
product_name | sum_order_amount | rank
-----------------+------------------+------
hard disk drive | 375481.00 | 0
floppy drive | 348655.00 | 0.25
keyboard | 67387.00 | 0.5
flat panel | 49666.00 | 0.75
lcd panel | 3087.00 | 1
(5 rows)三、交互查询与图形化显示
1. Zeppelin简介
Zeppelin是一个基于Web的软件,用于交互式地数据分析。它一开始是Apache软件基金会的孵化项目,2016年5月正式成为顶级项目。Zeppelin描述自己是一个可以进行数据摄取、数据发现、数据分析、数据可视化的笔记本,用以帮助开发者、数据科学家以及相关用户更有效地处理数据,而不必使用复杂的命令行,也不必关心集群的实现细节。Zeppelin的架构如图2所示。
图2
从上图中可以看到,Zeppelin具有客户端/服务器架构,客户端一般就是指浏览器。服务器接收客户端的请求,并将请求通过Thrift协议发送给翻译器组。翻译器组物理表现为JVM进程,负责实际处理客户端的请求并与服务器进行通信。
翻译器是一个插件式的体系结构,允许任何语言或后端数据处理程序以插件的形式添加到Zeppelin中。特别需要指出的是,Zeppelin内建Spark翻译器,因此不需要构建单独的模块、插件或库。翻译器的架构如图3所示。

图3
当前的Zeppelin已经支持很多翻译器,如Zeppelin 0.6.0版本自带的翻译器有alluxio、cassandra、file、hbase、ignite、kylin、md、phoenix、sh、tajo、angular、elasticsearch、flink、hive、jdbc、lens、psql、spark等18种之多。插件式架构允许用户在Zeppelin中使用自己熟悉的特定程序语言或数据处理方式。例如,通过使用%spark翻译器,可以在Zeppelin中使用Scala语言代码。
在数据可视化方面,Zeppelin已经包含一些基本的图表,如柱状图、饼图、线形图、散点图等,任何支持的后端语言输出都可以被图形化表示。
在Zeppelin中,用户建立的每一个查询叫做一个note,note的URL在多用户间共享,Zeppelin将向所有用户实时广播note的变化。Zeppelin还提供一个只显示查询结果的URL,该页不包括任何菜单和按钮。用这种方式可以方便地将结果页作为一帧嵌入到自己的web站点中。
2. 使用Zeppelin执行HAWQ查询
(1)安装ZeppelinHDP 2.5.0安装包中已经集成了Zeppelin 0.6.0,因此不需要单独进行复杂的安装配置,只要启动Zeppelin服务就可以了。
(2)配置Zeppelin支持HAWQ
Zeppelin 0.6.0通过JDBC翻译器解析HAWQ查询,只需进行简单的配置即可,步骤如下。
- 在Ambari控制台主页面中,点击Services -> Zeppelin Notebook -> Quick Links -> Zeppelin UI,打开Zeppelin UI主页面。
- 在Zeppelin UI主页面中,点击anonymous -> interpreter,进入翻译器页面。
- 点击edit编辑jdbc翻译器,配置default.driver、default.password、default.url、default.user四个属性的值,我的配置如图4所示。
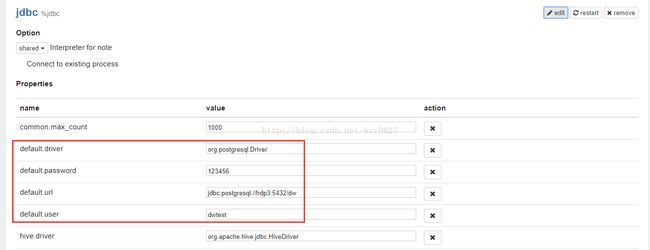
图4
- 配置好后点击Save保存配置,然后点击restart重启jdbc翻译器,至此配置完成。
点击Notebook -> Create new note,新建一个note,在其中输入查询语句,如“每种产品类型以及单个产品在每个省、每个城市的月销售量和销售额是多少?”的查询。
%jdbc
select t2.product_category, t2.product_name, t3.state, t3.city, sum(nq) sq, sum(order_amount) sa
from v_sales_order_fact t1, product_dim t2, zip_code_dim t3
where t1.product_sk = t2.product_sk
and t1.customer_zip_code_sk = t3.zip_code_sk
group by t2.product_category, t2.product_name, t3.state, t3.city
order by t2.product_category, t2.product_name, t3.state, t3.city;
图5
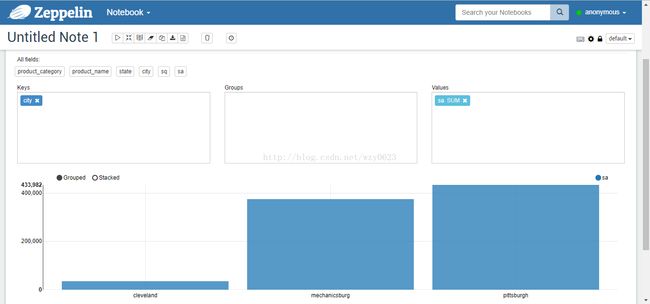
图6

图7

图8
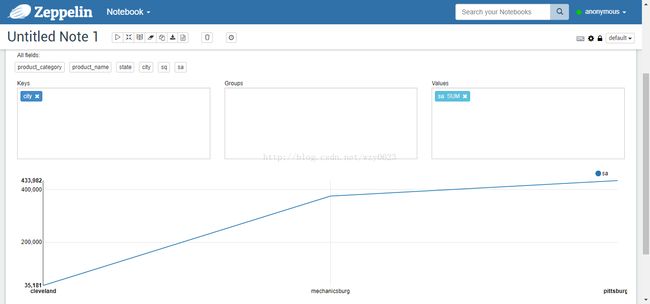
图9
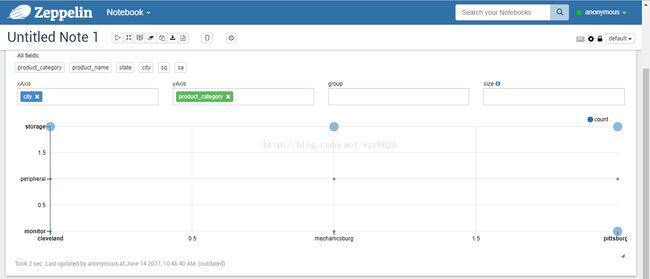
图10
一个note中可以独立执行多个查询语句。图形显示可以根据不同的“settings”联机分析不同的指标。报表有default、simple、report三种可选样式。例如,报表样式的饼图表示如图11所示。
图11
可以点击如图12红框中所示的链接单独引用此报表。

图12
单独的页面能根据查询或设置的修改而实时变化,比如将Values由sa列改为sq列,饼图表变为图13的样子。

图13
单独链接的页面也随之自动发生变化,如图14所示。
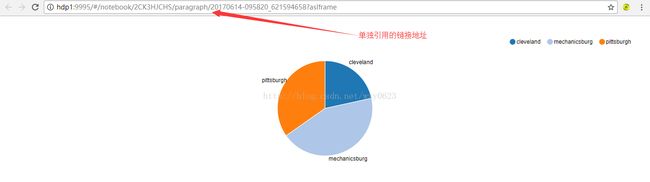
图14
Zeppelin支持联机输入变量值,例如,要查询某一年的销售情况,查询语句改为:
%jdbc
select t2.product_category, t2.product_name, t3.state, t3.city, sum(nq) sq, sum(order_amount) sa
from v_sales_order_fact t1, product_dim t2, zip_code_dim t3
where t1.product_sk = t2.product_sk
and t1.customer_zip_code_sk = t3.zip_code_sk
and t1.year_month/100 = ${year}
group by t2.product_category, t2.product_name, t3.state, t3.city
order by t2.product_category, t2.product_name, t3.state, t3.city;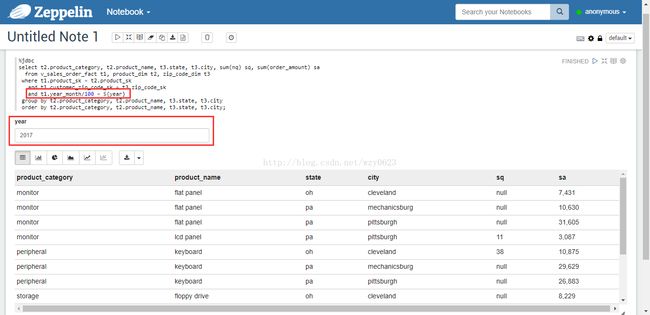
图15
甚至可以动态定义查询的列,例如查询语句改为:
%jdbc
select ${checkbox:fields=t2.product_category, t2.product_category|t2.product_name},t3.state, t3.city, sum(nq) sq, sum(order_amount) sa
from v_sales_order_fact t1, product_dim t2, zip_code_dim t3
where t1.product_sk = t2.product_sk
and t1.customer_zip_code_sk = t3.zip_code_sk
and t1.year_month/100 = ${year}
group by ${checkbox:fields=t2.product_category, t2.product_category|t2.product_name}, t3.state, t3.city
order by ${checkbox:fields=t2.product_category, t2.product_category|t2.product_name}, t3.state, t3.city;
图16
参考: https://zeppelin.apache.org/docs/latest/manual/dynamicform.html