[转]高性能IO之Reactor模式
原文地址:http://www.cnblogs.com/doit8791/p/7461479.html
讲到高性能IO绕不开Reactor模式,它是大多数IO相关组件如Netty、Redis在使用的IO模式,为什么需要这种模式,它是如何设计来解决高性能并发的呢?
最最原始的网络编程思路就是服务器用一个while循环,不断监听端口是否有新的套接字连接,如果有,那么就调用一个处理函数处理,类似:
while(true){
socket = accept();
handle(socket)
}
这种方法的最大问题是无法并发,效率太低,如果当前的请求没有处理完,那么后面的请求只能被阻塞,服务器的吞吐量太低。
之后,想到了使用多线程,也就是很经典的connection per thread,每一个连接用一个线程处理,类似:
while(true){
socket = accept();
new thread(socket);
}
tomcat服务器的早期版本确实是这样实现的。多线程的方式确实一定程度上极大地提高了服务器的吞吐量,因为之前的请求在read阻塞以后,不会影响到后续的请求,因为他们在不同的线程中。这也是为什么通常会讲“一个线程只能对应一个socket”的原因。最开始对这句话很不理解,线程中创建多个socket不行吗?语法上确实可以,但是实际上没有用,每一个socket都是阻塞的,所以在一个线程里只能处理一个socket,就算accept了多个也没用,前一个socket被阻塞了,后面的是无法被执行到的。
缺点在于资源要求太高,系统中创建线程是需要比较高的系统资源的,如果连接数太高,系统无法承受,而且,线程的反复创建-销毁也需要代价。
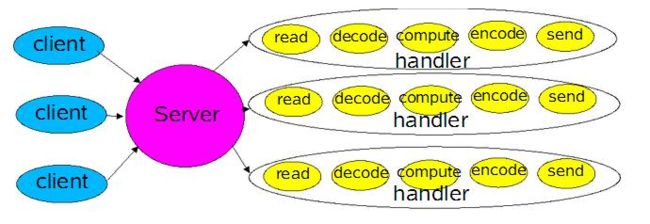
线程池本身可以缓解线程创建-销毁的代价,这样优化确实会好很多,不过还是存在一些问题的,就是线程的粒度太大。每一个线程把一次交互的事情全部做了,包括读取和返回,甚至连接,表面上似乎连接不在线程里,但是如果线程不够,有了新的连接,也无法得到处理,所以,目前的方案线程里可以看成要做三件事,连接,读取和写入。
线程同步的粒度太大了,限制了吞吐量。应该把一次连接的操作分为更细的粒度或者过程,这些更细的粒度是更小的线程。整个线程池的数目会翻倍,但是线程更简单,任务更加单一。这其实就是Reactor出现的原因,在Reactor中,这些被拆分的小线程或者子过程对应的是handler,每一种handler会出处理一种event。这里会有一个全局的管理者selector,我们需要把channel注册感兴趣的事件,那么这个selector就会不断在channel上检测是否有该类型的事件发生,如果没有,那么主线程就会被阻塞,否则就会调用相应的事件处理函数即handler来处理。典型的事件有连接,读取和写入,当然我们就需要为这些事件分别提供处理器,每一个处理器可以采用线程的方式实现。一个连接来了,显示被读取线程或者handler处理了,然后再执行写入,那么之前的读取就可以被后面的请求复用,吞吐量就提高了。【Java】Reactor模式
几乎所有的网络连接都会经过读请求内容——》解码——》计算处理——》编码回复——》回复的过程,Reactor模式的的演化过程如下:
流程:
① 服务器端的Server是一个线程,线程中执行一个死循环来阻塞的监听客户端的连接请求和通信。
② 当客户端向服务器端发送一个连接请求后,服务器端的Server会接受客户端的请求,ServerSocket.accept()从阻塞中返回,得到一个与客户端连接相对于的Socket。
③ 构建一个handler,将Socket传入该handler。创建一个线程并启动该线程,在线程中执行handler,这样与客户端的所有的通信以及数据处理都在该线程中执行。当该客户端和服务器端完成通信关闭连接后,线程就会被销毁。
④ 然后Server继续执行accept()操作等待新的连接请求。优点:
① 使用简单,容易编程
② 在多核系统下,能够充分利用了多核CPU的资源。即,当I/O阻塞系统,但CPU空闲的时候,可以利用多线程使用CPU资源。缺点:
该模式的本质问题在于严重依赖线程,但线程Java虚拟机非常宝贵的资源。随着客户端并发访问量的急剧增加,线程数量的不断膨胀将服务器端的性能将急剧下降。
① 线程生命周期的开销非常高。线程的创建与销毁并不是没有代价的。在Linux这样的操作系统中,线程本质上就是一个进程,创建和销毁都是重量级的系统函数。
② 资源消耗。内存:大量空闲的线程会占用许多内存,给垃圾回收器带来压力;CPU:如果你已经拥有足够多的线程使所有CPU保持忙碌状态,那么再创建更过的线程反而会降低性能。
③ 稳定性。在可创建线程的数量上存在一个限制。这个限制值将随着平台的不同而不同,并且受多个因素制约:a)JVM的启动参数、b)Threa的构造函数中请求的栈大小、c)底层操作系统对线程的限制 等。如果破坏了这些限制,那么很可能抛出OutOfMemoryError异常。
④ 线程的切换成本是很高的。操作系统发生线程切换的时候,需要保留线程的上下文,然后执行系统调用。如果线程数过高,不仅会带来许多无用的上下文切换,还可能导致执行线程切换的时间甚至会大于线程执行的时间,这时候带来的表现往往是系统负载偏高、CPU sy(系统CPU)使用率特别高,导致系统几乎陷入不可用的状态。
⑤ 容易造成锯齿状的系统负载。一旦线程数量高但外部网络环境不是很稳定,就很容易造成大量请求的结果同时返回,激活大量阻塞线程从而使系统负载压力过大。
⑥ 若是长连接的情况下并且客户端与服务器端交互并不频繁的,那么客户端和服务器端的连接会一直保留着,对应的线程也就一直存在在,但因为不频繁的通信,导致大量线程在大量时间内都处于空置状态。适用场景:如果你有少量的连接使用非常高的带宽,一次发送大量的数据,也许典型的IO服务器实现可能非常契合。
这种模型由于IO在阻塞时会一直等待,因此在用户负载增加时,性能下降的非常快。
server导致阻塞的原因:
1、serversocket的accept方法,阻塞等待client连接,直到client连接成功。
2、线程从socket inputstream读入数据,会进入阻塞状态,直到全部数据读完。
3、线程向socket outputstream写入数据,会阻塞直到全部数据写完。
改进:采用基于事件驱动的设计,当有事件触发时,才会调用处理器进行数据处理。
Reactor:负责响应IO事件,当检测到一个新的事件,将其发送给相应的Handler去处理。
Handler:负责处理非阻塞的行为,标识系统管理的资源;同时将handler与事件绑定。
Reactor为单个线程,需要处理accept连接,同时发送请求到处理器中。
由于只有单个线程,所以处理器中的业务需要能够快速处理完。
流程:
① 服务器端的Reactor是一个线程对象,该线程会启动事件循环,并使用Selector来实现IO的多路复用。注册一个Acceptor事件处理器到Reactor中,Acceptor事件处理器所关注的事件是ACCEPT事件,这样Reactor会监听客户端向服务器端发起的连接请求事件(ACCEPT事件)。
② 客户端向服务器端发起一个连接请求,Reactor监听到了该ACCEPT事件的发生并将该ACCEPT事件派发给相应的Acceptor处理器来进行处理。Acceptor处理器通过accept()方法得到与这个客户端对应的连接(SocketChannel),然后将该连接所关注的READ事件以及对应的READ事件处理器注册到Reactor中,这样一来Reactor就会监听该连接的READ事件了。或者当你需要向客户端发送数据时,就向Reactor注册该连接的WRITE事件和其处理器。
③ 当Reactor监听到有读或者写事件发生时,将相关的事件派发给对应的处理器进行处理。比如,读处理器会通过SocketChannel的read()方法读取数据,此时read()操作可以直接读取到数据,而不会堵塞与等待可读的数据到来。
④ 每当处理完所有就绪的感兴趣的I/O事件后,Reactor线程会再次执行select()阻塞等待新的事件就绪并将其分派给对应处理器进行处理。注意,Reactor的单线程模式的单线程主要是针对于I/O操作而言,也就是所以的I/O的accept()、read()、write()以及connect()操作都在一个线程上完成的。
但在目前的单线程Reactor模式中,不仅I/O操作在该Reactor线程上,连非I/O的业务操作也在该线程上进行处理了,这可能会大大延迟I/O请求的响应。所以我们应该将非I/O的业务逻辑操作从Reactor线程上卸载,以此来加速Reactor线程对I/O请求的响应。
改进:使用多线程处理业务逻辑。
将处理器的执行放入线程池,多线程进行业务处理。但Reactor仍为单个线程。
与单线程Reactor模式不同的是,添加了一个工作者线程池,并将非I/O操作从Reactor线程中移出转交给工作者线程池来执行。这样能够提高Reactor线程的I/O响应,不至于因为一些耗时的业务逻辑而延迟对后面I/O请求的处理。
使用线程池的优势:
① 通过重用现有的线程而不是创建新线程,可以在处理多个请求时分摊在线程创建和销毁过程产生的巨大开销。
② 另一个额外的好处是,当请求到达时,工作线程通常已经存在,因此不会由于等待创建线程而延迟任务的执行,从而提高了响应性。
③ 通过适当调整线程池的大小,可以创建足够多的线程以便使处理器保持忙碌状态。同时还可以防止过多线程相互竞争资源而使应用程序耗尽内存或失败。注意,在上图的改进的版本中,所以的I/O操作依旧由一个Reactor来完成,包括I/O的accept()、read()、write()以及connect()操作。
对于一些小容量应用场景,可以使用单线程模型。但是对于高负载、大并发或大数据量的应用场景却不合适,主要原因如下:
① 一个NIO线程同时处理成百上千的链路,性能上无法支撑,即便NIO线程的CPU负荷达到100%,也无法满足海量消息的读取和发送;
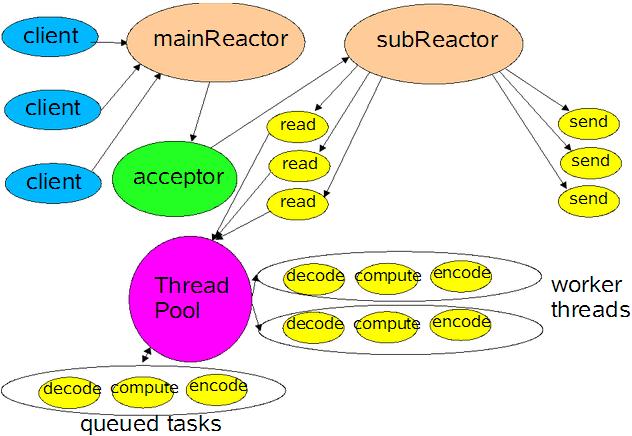
② 当NIO线程负载过重之后,处理速度将变慢,这会导致大量客户端连接超时,超时之后往往会进行重发,这更加重了NIO线程的负载,最终会导致大量消息积压和处理超时,成为系统的性能瓶颈;继续改进:对于多个CPU的机器,为充分利用系统资源,将Reactor拆分为两部分。
Using Multiple Reactors
mainReactor负责监听连接,accept连接给subReactor处理,为什么要单独分一个Reactor来处理监听呢?因为像TCP这样需要经过3次握手才能建立连接,这个建立连接的过程也是要耗时间和资源的,单独分一个Reactor来处理,可以提高性能。
Reactor线程池中的每一Reactor线程都会有自己的Selector、线程和分发的事件循环逻辑。
mainReactor可以只有一个,但subReactor一般会有多个。mainReactor线程主要负责接收客户端的连接请求,然后将接收到的SocketChannel传递给subReactor,由subReactor来完成和客户端的通信。流程:
① 注册一个Acceptor事件处理器到mainReactor中,Acceptor事件处理器所关注的事件是ACCEPT事件,这样mainReactor会监听客户端向服务器端发起的连接请求事件(ACCEPT事件)。启动mainReactor的事件循环。
② 客户端向服务器端发起一个连接请求,mainReactor监听到了该ACCEPT事件并将该ACCEPT事件派发给Acceptor处理器来进行处理。Acceptor处理器通过accept()方法得到与这个客户端对应的连接(SocketChannel),然后将这个SocketChannel传递给subReactor线程池。
③ subReactor线程池分配一个subReactor线程给这个SocketChannel,即,将SocketChannel关注的READ事件以及对应的READ事件处理器注册到subReactor线程中。当然你也注册WRITE事件以及WRITE事件处理器到subReactor线程中以完成I/O写操作。Reactor线程池中的每一Reactor线程都会有自己的Selector、线程和分发的循环逻辑。
④ 当有I/O事件就绪时,相关的subReactor就将事件派发给响应的处理器处理。注意,这里subReactor线程只负责完成I/O的read()操作,在读取到数据后将业务逻辑的处理放入到线程池中完成,若完成业务逻辑后需要返回数据给客户端,则相关的I/O的write操作还是会被提交回subReactor线程来完成。注意,所以的I/O操作(包括,I/O的accept()、read()、write()以及connect()操作)依旧还是在Reactor线程(mainReactor线程 或 subReactor线程)中完成的。Thread Pool(线程池)仅用来处理非I/O操作的逻辑。
多Reactor线程模式将“接受客户端的连接请求”和“与该客户端的通信”分在了两个Reactor线程来完成。mainReactor完成接收客户端连接请求的操作,它不负责与客户端的通信,而是将建立好的连接转交给subReactor线程来完成与客户端的通信,这样一来就不会因为read()数据量太大而导致后面的客户端连接请求得不到即时处理的情况。并且多Reactor线程模式在海量的客户端并发请求的情况下,还可以通过实现subReactor线程池来将海量的连接分发给多个subReactor线程,在多核的操作系统中这能大大提升应用的负载和吞吐量。


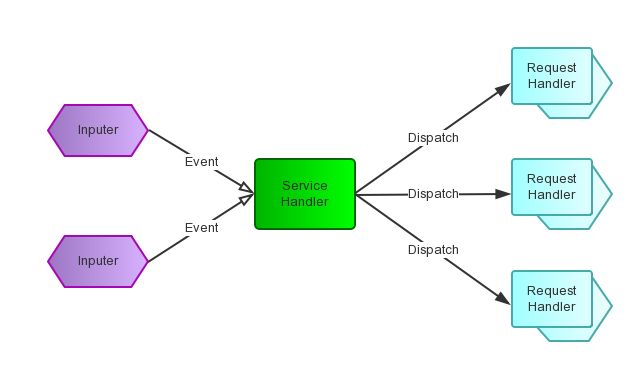
Reactor模式是什么,有哪些优缺点?
Wikipedia上说:“The reactor design pattern is an event handling pattern for handling service requests delivered concurrently by one or more inputs. The service handler then demultiplexes the incoming requests and dispatches them synchronously to associated request handlers.”。从这个描述中,我们知道Reactor模式首先是事件驱动的,有一个或多个并发输入源,有一个Service Handler,有多个Request Handlers;这个Service Handler会同步的将输入的请求(Event)多路复用的分发给相应的Request Handler。如果用图来表达:
从结构上,这有点类似生产者消费者模式,即有一个或多个生产者将事件放入一个Queue中,而一个或多个消费者主动的从这个Queue中Poll事件来处理;而Reactor模式则并没有Queue来做缓冲,每当一个Event输入到Service Handler之后,该Service Handler会主动的根据不同的Event类型将其分发给对应的Request Handler来处理。Reactor模式结构
在解决了什么是Reactor模式后,我们来看看Reactor模式是由什么模块构成。图是一种比较简洁形象的表现方式,因而先上一张图来表达各个模块的名称和他们之间的关系:
Handle:即操作系统中的句柄,是对资源在操作系统层面上的一种抽象,它可以是打开的文件、一个连接(Socket)、Timer等。由于Reactor模式一般使用在网络编程中,因而这里一般指Socket Handle,即一个网络连接(Connection,在Java NIO中的Channel)。这个Channel注册到Synchronous Event Demultiplexer中,以监听Handle中发生的事件,对ServerSocketChannnel可以是CONNECT事件,对SocketChannel可以是READ、WRITE、CLOSE事件等。
Synchronous Event Demultiplexer:阻塞等待一系列的Handle中的事件到来,如果阻塞等待返回,即表示在返回的Handle中可以不阻塞的执行返回的事件类型。这个模块一般使用操作系统的select来实现。在Java NIO中用Selector来封装,当Selector.select()返回时,可以调用Selector的selectedKeys()方法获取Set,一个SelectionKey表达一个有事件发生的Channel以及该Channel上的事件类型。上图的“Synchronous Event Demultiplexer ---notifies--> Handle”的流程如果是对的,那内部实现应该是select()方法在事件到来后会先设置Handle的状态,然后返回。不了解内部实现机制,因而保留原图。
Initiation Dispatcher:用于管理Event Handler,即EventHandler的容器,用以注册、移除EventHandler等;另外,它还作为Reactor模式的入口调用Synchronous Event Demultiplexer的select方法以阻塞等待事件返回,当阻塞等待返回时,根据事件发生的Handle将其分发给对应的Event Handler处理,即回调EventHandler中的handle_event()方法。
Event Handler:定义事件处理方法:handle_event(),以供InitiationDispatcher回调使用。
Concrete Event Handler:事件EventHandler接口,实现特定事件处理逻辑。Reactor模式详解
优点
1)响应快,不必为单个同步时间所阻塞,虽然Reactor本身依然是同步的;
2)编程相对简单,可以最大程度的避免复杂的多线程及同步问题,并且避免了多线程/进程的切换开销;
3)可扩展性,可以方便的通过增加Reactor实例个数来充分利用CPU资源;
4)可复用性,reactor框架本身与具体事件处理逻辑无关,具有很高的复用性;
缺点1)相比传统的简单模型,Reactor增加了一定的复杂性,因而有一定的门槛,并且不易于调试。
2)Reactor模式需要底层的Synchronous Event Demultiplexer支持,比如Java中的Selector支持,操作系统的select系统调用支持,如果要自己实现Synchronous Event Demultiplexer可能不会有那么高效。
3) Reactor模式在IO读写数据时还是在同一个线程中实现的,即使使用多个Reactor机制的情况下,那些共享一个Reactor的Channel如果出现一个长时间的数据读写,会影响这个Reactor中其他Channel的相应时间,比如在大文件传输时,IO操作就会影响其他Client的相应时间,因而对这种操作,使用传统的Thread-Per-Connection或许是一个更好的选择,或则此时使用Proactor模式。另一篇:
https://blog.csdn.net/sshhbb/article/details/6331954
在高性能的I/O设计中,有两个比较著名的模式Reactor和Proactor模式,其中Reactor模式用于同步I/O,而Proactor运用于异步I/O操作。
在比较这两个模式之前,我们首先的搞明白几个概念,什么是阻塞和非阻塞,什么是同步和异步,同步和异步是针对应用程序和内核的交互而言的,同步指的是用户进程触发IO操作并等待或者轮询的去查看IO操作是否就绪,而异步是指用户进程触发IO操作以后便开始做自己的事情,而当IO操作已经完成的时候会得到IO完成的通知(异步的特点就是通知)。而阻塞和非阻塞是针对于进程在访问数据的时候,根据IO操作的就绪状态来采取的不同方式,说白了是一种读取或者写入操作函数的实现方式,阻塞方式下读取或者写入函数将一直等待,而非阻塞方式下,读取或者写入函数会立即返回一个状态值。
一般来说I/O模型可以分为:同步阻塞,同步非阻塞,异步阻塞,异步非阻塞IO
同步阻塞IO:
在此种方式下,用户进程在发起一个IO操作以后,必须等待IO操作的完成,只有当真正完成了IO操作以后,用户进程才能运行。JAVA传统的IO模型属于此种方式!
同步非阻塞IO:
在此种方式下,用户进程发起一个IO操作以后边可返回做其它事情,但是用户进程需要时不时的询问IO操作是否就绪,这就要求用户进程不停的去询问,从而引入不必要的CPU资源浪费。其中目前JAVA的NIO就属于同步非阻塞IO。
异步阻塞IO:
此种方式下是指应用发起一个IO操作以后,不等待内核IO操作的完成,等内核完成IO操作以后会通知应用程序,这其实就是同步和异步最关键的区别,同步必须等待或者主动的去询问IO是否完成,那么为什么说是阻塞的呢?因为此时是通过select系统调用来完成的,而select函数本身的实现方式是阻塞的,而采用select函数有个好处就是它可以同时监听多个文件句柄(如果从UNP的角度看,select属于同步操作。因为select之后,进程还需要读写数据),从而提高系统的并发性!
异步非阻塞IO:
在此种模式下,用户进程只需要发起一个IO操作然后立即返回,等IO操作真正的完成以后,应用程序会得到IO操作完成的通知,此时用户进程只需要对数据进行处理就好了,不需要进行实际的IO读写操作,因为真正的IO读取或者写入操作已经由内核完成了。目前Java中还没有支持此种IO模型。
搞清楚了以上概念以后,我们再回过头来看看,Reactor模式和Proactor模式。
(其实阻塞与非阻塞都可以理解为同步范畴下才有的概念,对于异步,就不会再去分阻塞非阻塞。对于用户进程,接到异步通知后,就直接操作进程用户态空间里的数据好了。)
首先来看看Reactor模式,Reactor模式应用于同步I/O的场景。我们分别以读操作和写操作为例来看看Reactor中的具体步骤:
读取操作:
1. 应用程序注册读就绪事件和相关联的事件处理器
2. 事件分离器等待事件的发生
3. 当发生读就绪事件的时候,事件分离器调用第一步注册的事件处理器
4. 事件处理器首先执行实际的读取操作,然后根据读取到的内容进行进一步的处理
写入操作类似于读取操作,只不过第一步注册的是写就绪事件。
下面我们来看看Proactor模式中读取操作和写入操作的过程:
读取操作:
1. 应用程序初始化一个异步读取操作,然后注册相应的事件处理器,此时事件处理器不关注读取就绪事件,而是关注读取完成事件,这是区别于Reactor的关键。
2. 事件分离器等待读取操作完成事件
3. 在事件分离器等待读取操作完成的时候,操作系统调用内核线程完成读取操作(异步IO都是操作系统负责将数据读写到应用传递进来的缓冲区供应用程序操作,操作系统扮演了重要角色),并将读取的内容放入用户传递过来的缓存区中。这也是区别于Reactor的一点,Proactor中,应用程序需要传递缓存区。
4. 事件分离器捕获到读取完成事件后,激活应用程序注册的事件处理器,事件处理器直接从缓存区读取数据,而不需要进行实际的读取操作。
Proactor中写入操作和读取操作,只不过感兴趣的事件是写入完成事件。
从上面可以看出,Reactor和Proactor模式的主要区别就是真正的读取和写入操作是有谁来完成的,Reactor中需要应用程序自己读取或者写入数据,而Proactor模式中,应用程序不需要进行实际的读写过程,它只需要从缓存区读取或者写入即可,操作系统会读取缓存区或者写入缓存区到真正的IO设备.
综上所述,同步和异步是相对于应用和内核的交互方式而言的,同步需要主动去询问,而异步的时候内核在IO事件发生的时候通知应用程序,而阻塞和非阻塞仅仅是系统在调用系统调用的时候函数的实现方式而已。

![[转]高性能IO之Reactor模式_第1张图片](http://img.e-com-net.com/image/info8/a74a2fcba7194618be147c87fbfeb4ad.jpg)
经过上面的介绍,会发现non-blocking IO和asynchronous IO的区别还是很明显的。在non-blocking IO中,虽然进程大部分时间都不会被block,但是它仍然要求进程去主动的check,并且当数据准备完成以后,也需要进程主动的再次调用recvfrom来将数据拷贝到用户内存。而asynchronous IO则完全不同。它就像是用户进程将整个IO操作交给了他人(kernel)完成,然后他人做完后发信号通知。在此期间,用户进程不需要去检查IO操作的状态,也不需要主动的去拷贝数据。
最后,再举几个不是很恰当的例子来说明这四个IO Model:
有A,B,C,D四个人在钓鱼:
A用的是最老式的鱼竿,所以呢,得一直守着,等到鱼上钩了再拉杆;
B的鱼竿有个功能,能够显示是否有鱼上钩,所以呢,B就和旁边的MM聊天,隔会再看看有没有鱼上钩,有的话就迅速拉杆;
C用的鱼竿和B差不多,但他想了一个好办法,就是同时放好几根鱼竿,然后守在旁边,一旦有显示说鱼上钩了,它就将对应的鱼竿拉起来;
D是个有钱人,干脆雇了一个人帮他钓鱼,一旦那个人把鱼钓上来了,就给D发个短信。