MySQL 高级--优化 —— 复合索引(多列索引、联合索引)的定义、区别、创建和理解
文章目录
- 1、多列索引的定义与区别
- 2、创建多列索引的语法
- 4、多列索引的理解
- 4、通过示例加强理解:
- 6、存储过程 :快速生成 100W 测试数据
- 7、MySQL 存储引擎
- 8、适合建索引情况:
- 9、不适合建索引情况:
1、多列索引的定义与区别
索引的定义是 快速、高效地查询数据的数据结构。
索引的本质就是 数据结构。 可以理解为 排好序的、快速查找的数据结构。
mysql 中,索引有 单列索引,也有 多列索引 。
(1)单列索引 就是常用的一个列字段的索引,常见的索引。
(2)多列索引 就是含有多个列字段的索引 。
多列索引,也叫 多列组合索引、复合索引 、联合索引。
2、创建多列索引的语法
创建:
create index indexName on tableName (a,b(length),c) # length 是指定此列创建索引的长度,也可以不指定长度。
# 或者
alert tableName add index indexName on (a,b,c)
删除:
drop index indexName on tableName ;
查看索引:
show index from tableName ;
4、多列索引的理解
索引可以理解为 排好序的 快速查找的 数据结构 。
像新华字典的目录,按照a、b、c ... 这样排好序的;并且比如 a 中也是排好序的。
比如查找 中国 的中字,拼音是 zhong ,
首先是定位到 目录的 z 开头部分,
然后 查询到 zh 开头的部分,
然后 是 zho 、zhon、zhong 。
比如 索引 ( a , b, c) ,支持的索引有 a 、a,b、 a,b,c 3种索引 。
在任意一段a的下面b都是排好序的,任何一段b下面c都是排好序的;
示例:
where a=3 and b=45 and c=5 # 这种三个索引顺序使用中间没有断点,全部发挥作用;
where a=3 and c=5 # 这种情况下,b就是断点,a有效,c无效
where b=3 and c=4 # 这种情况下,a就是断点,在a后面的索引全部无效
where b=45 and c=5 and a=3 # 这个跟第一个一样,全部有效, abc跟书写的顺序无关
4、通过示例加强理解:
前提:在 mytable 表中创建 ( a ,b ,c ) 三个列的复合索引。
注意, ( a ,b ,c ) 索引 和 ( a ,c ,b ) 是不同的索引。
SQL语句:
(1) select * from mytable where a=3 and b=5 and c=4;
# abc 三列都使用索引,而且都有效
(2) select * from mytable where c=4 and b=6 and a=3;
# mysql没有那么笨,不会因为书写顺序而无法识辨索引。
# where里面的条件顺序在查询之前会被mysql自动优化,效果跟上一句一样。
(3) select * from mytable where a=3 and c=7;
# a 用到索引,sql中没有使用 b列,b列中断,c没有用到索引
(4) select * from mytable where a=3 and b>7 and c=3;
# a 用到索引,b也用到索引,c没有用到。
# 因为 b是范围索引,所以b处断点,复合索引中后序的列即使出现,索引也是无效的。
(5) select * from mytable where b=3 and c=4;
# sql中没有使用a列, 所以b,c 就无法使用到索引
(6) select * from mytable where a>4 and b=7 and c=9;
# a 用到索引, a是范围索引,索引在a处中断, b、c没有使用索引
(7) select * from mytable where a=3 order by b;
# a用到了索引,b在结果排序中也用到了索引的效果。前面说过,a下面任意一段的b是排好序的
(8) select * from mytable where a=3 order by c;
# a 用到了索引,sql中没有使用 b列,索引中断,c处没有使用索引,在 Extra列 可以看到 filesort
(9) select * from mytable where b=3 order by a;
# 此sql中,先b,后a,导致 b=3 索引无效,排序a也索引无效。
6、存储过程 :快速生成 100W 测试数据
快速生成 100W 测试数据。
创建测试表:
create table `ut_user` (
`id` int(10) not null auto_increment,
`name` varchar(20) default null comment '姓名',
`gender` int(11) default '0' comment '0:男,1:女',
`age` int(11) default null comment '年龄',
`createtime` datetime default null,
primary key (`id`)
) engine=innodb auto_increment=1001 default charset=utf8
存储过程:
存储过程中 开启事务的格式:
begin
set autocommit=0; ## 取消自动提交
start transaction; ## 开启事务
要执行的操作
commit; ## 提交事务
end ;
完整的存储过程SQL:
delimiter $$
drop procedure if exists `addUtUserData`$$
create definer=`root`@`localhost` procedure `addUtUserData`(in num int)
begin
declare v_cnt int(10) default 0 ;
set autocommit=0;
start transaction;
repeat
insert into ut_user values
(null,genLName() ,floor(rand()*2),rand()*50 ,now() ),
(null,genLName() ,floor(rand()*2),rand()*50 ,now() ),
(null,genLName() ,floor(rand()*2),rand()*50 ,now() ),
(null,genLName() ,floor(rand()*2),rand()*50 ,now() ),
(null,genLName() ,floor(rand()*2),rand()*50 ,now() ),
(null,genLName() ,floor(rand()*2),rand()*50 ,now() ),
(null,genLName() ,floor(rand()*2),rand()*50 ,now() ),
(null,genLName() ,floor(rand()*2),rand()*50 ,now() ),
(null,genLName() ,floor(rand()*2),rand()*50 ,now() ),
(null,genLName() ,floor(rand()*2),rand()*50 ,now() );
set v_cnt = v_cnt+10 ;
until v_cnt = num
end repeat;
commit; ## 提交
end$$
delimiter ;
调用存储过程:
call addData(100000);
说明: genLName() 函数,请参考: mysql 生成随机数
7、MySQL 存储引擎
show engines;
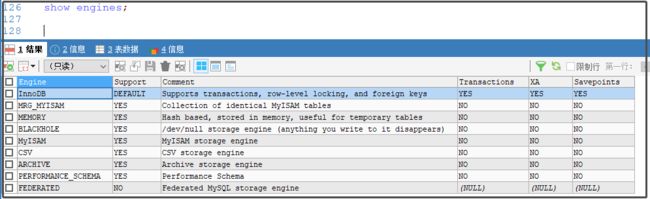
阿里巴巴开源的 AliSql 、AliRedis
| 存储引擎 | 事务 | 锁 | 支持的索引结构 | 不支持的索引结构 |
|---|---|---|---|---|
| InnoDB | 支持事务 | 行锁 | 支持 B-tree、Full-text 等索引 | 不支持 Hash 索引 |
| MyISAM | 不支持事务 | 表锁 | 支持 B-tree、Full-text 等索引 | 不支持 Hash 索引 |
| Memory | 不支持事务 | 表锁 | 支持 B-tree、Hash 等索引 | 不支持 Full-text 索引 |
索引种类
BTree索引、Hash索引、full-text全文索引、R-Tree索引
Btree类型的索引:b+树,层数越多,数据量指数级增长(我们就用它,因为innodb默认支持它)
Hash类型的索引:查询单条快,范围查询慢
8、适合建索引情况:
- 主键自动建立唯一索引
- 频繁作为查询条件的字段应该创建索引
- 与其它表关联的字段,外键关系建立索引
- 单键/组合索引的选择问题,(在高并发下,倾向创建组合索引)
- 排序的字段
排序字段若通过索引去访问将大大提高排序速度 - 统计、分组的字段
9、不适合建索引情况:
- Where条件里用不到的字段不创建索引。
- 频繁更新的 字段 不适合建索引 (每次更新记录,还要更新索引)
- 经常增删改的表。
索引可以提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT、UPDATE和DELETE。
因为更新表时,mysql不仅要保存数据,还要保存一下索引文件,加重了IO负担) - 数据重复且分布平均的表字段。
因此应该只为最经常查询和最经常排序的数据列建立索引。
如果某个数据列包含许多重复的内容,为它建立索引就没有太大的实际效果。
比如一个字段的值只 有0、1 表示男女,完全不需要建索引。 - 表记录太少。