spark 与 hadoop的hdfs的连接(亲测有效)
出处::http://blog.csdn.net/oopsoom/article/details/24257981,
目前Spark的Run on的Hadoop版本大多是hadoop2以上,但是实际上各个公司的生产环境不尽相同,用到2.0以上的公司还是少数。
大多数公司还是停留在1代hadoop上,所以我就拿spark0.91 + hadoop0.20.2-cdh3u5来部署一个小集群,以供测试学习使用。
一、环境概况
Spark集群3台:
web01: slave
web02: master
db01: slave
Hadoop集群:
hadoop 0.20.2-cdh3u5 3台
2、编译Spark
编译spark我在这里就不赘述了,已经有好几篇编译的文章了
第一步、设置Spark要work with的Hadoop的版本号,可以在spark官网查找。
第二部、sbt/sbt assembly 编译发布spark核心包。
还是推荐大家用sbt编译,遇到问题可以看我的 spark编译sbt依赖问题。
3、配置
如果编译基本都ok了的话,会在/home/hadoop/shengli/spark/assembly/target/scala-2.10下生成spark和hadoop匹配的发布包。
- 总计 92896
- drwxr-xr-x 3 root root 4096 04-21 14:00 cache
- drwxrwxr-x 6 root root 4096 04-21 14:00 ..
- -rw-r--r-- 1 root root 95011766 04-21 14:16 spark-assembly-0.9.1-hadoop0.20.2-cdh3u5.jar
- drwxrwxr-x 3 root root 4096 04-21 14:20 .
而且在路径/home/hadoop/shengli/spark/lib_managed/jars下,你会找到hadoop-core-0.20.2-cdh3u5.jar这个文件。
4.spark配置
spark官网上提供了好多几种启动集群的方式,我比较推荐的是用官方的shell脚本。sbin/start-all.sh,简单快捷,如果需要定制的启动Master和Slave,就需要用到sbin/start-master.sh sbin/start-slave.sh了。
4.1 修改spark的spark环境
如果用到这种启动方式,首先要修改配置文件。
- cp spark-env.sh.template spark-env.sh
设置一下Master的IP和端口:(其它的配置以后再配了)
- #!/usr/bin/env bash
- # This file contains environment variables required to run Spark. Copy it as
- # spark-env.sh and edit that to configure Spark for your site.
- #
- # The following variables can be set in this file:
- # - SPARK_LOCAL_IP, to set the IP address Spark binds to on this node
- # - MESOS_NATIVE_LIBRARY, to point to your libmesos.so if you use Mesos
- # - SPARK_JAVA_OPTS, to set node-specific JVM options for Spark. Note that
- # we recommend setting app-wide options in the application's driver program.
- # Examples of node-specific options : -Dspark.local.dir, GC options
- # Examples of app-wide options : -Dspark.serializer
- #
- # If using the standalone deploy mode, you can also set variables for it here:
- # - SPARK_MASTER_IP, to bind the master to a different IP address or hostname
- # - SPARK_MASTER_PORT / SPARK_MASTER_WEBUI_PORT, to use non-default ports
- # - SPARK_WORKER_CORES, to set the number of cores to use on this machine
- # - SPARK_WORKER_MEMORY, to set how much memory to use (e.g. 1000m, 2g)
- # - SPARK_WORKER_PORT / SPARK_WORKER_WEBUI_PORT
- # - SPARK_WORKER_INSTANCES, to set the number of worker processes per node
- # - SPARK_WORKER_DIR, to set the working directory of worker processes
- export SPARK_MASTER_IP=web02.dw
- export SPARK_MASTER_PORT=7077
- export SPARK_WORKER_CORES=4
- export SPARK_WORKER_MEMORY=2g
- export SPARK_WORKER_INSTANCES=2
- #control executor mem
- export SPARK_EXECUTOR_MEMORY=1g
- export SPARK_JAVA_OPTS=-Dspark.executor.memory=1g
4.2 将hadoop配置文件加入classpath
将hadoop配置文件core-site.xml和hdfs-site.xml拷贝到spark/conf下。
4.3 设置slaves
- vim slaves
- # A Spark Worker will be started on each of the machines listed below.
- web01.dw
- db01.dw
4.4分发spark
最基本的默认配置以及配置好了,下面开始分发spark到各个slave节点,注意要先打包后分发,然后到各个节点去解压,不要直接scp。
5. 启动spark
5.1启动spark:
- [root@web02 spark]# sbin/start-all.sh
- starting org.apache.spark.deploy.master.Master, logging to /app/home/hadoop/shengli/spark/sbin/../logs/spark-root-org.apache.spark.deploy.master.Master-1-web02.dw.out
- web01.dw: starting org.apache.spark.deploy.worker.Worker, logging to /app/home/hadoop/shengli/spark/sbin/../logs/spark-root-org.apache.spark.deploy.worker.Worker-1-web01.dw.out
- db01.dw: starting org.apache.spark.deploy.worker.Worker, logging to /app/hadoop/shengli/spark/sbin/../logs/spark-root-org.apache.spark.deploy.worker.Worker-1-db01.dw.out
web02是Master,web01和db01是Worker.
- [root@web02 spark]# jps
- 25293 SecondaryNameNode
- 25390 JobTracker
- 18783 Jps
- 25118 NameNode
- 18677 Master
- [root@web01 conf]# jps
- 22733 DataNode
- 5697 Jps
- 22878 TaskTracker
- 5625 Worker
- 4839 jar
- [root@db01 assembly]# jps
- 16242 DataNode
- 16345 TaskTracker
- 30603 Worker
- 30697 Jps
5.2 web监控
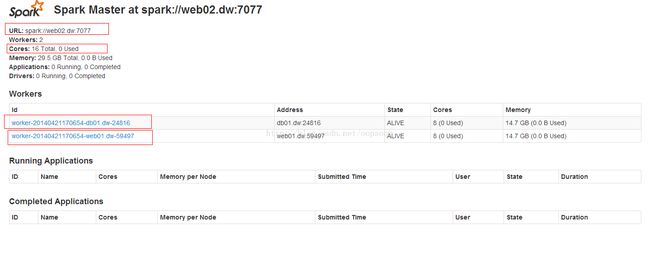
可以清晰的看到:
默认情况下Master的端口为7077,当然我们可以根据配置文件更改,这里暂不做更改。
2个worker,以及每个worker和集群的配置。
Master:
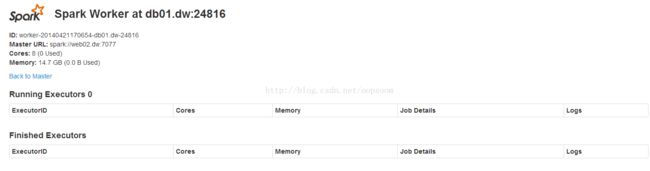
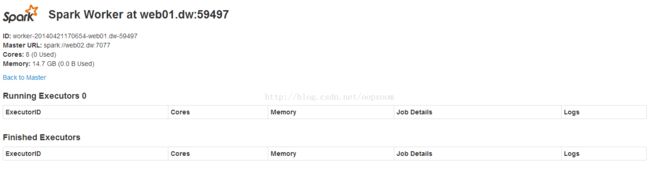
Slaves:
6. spark连接hdfs
6.1启动一个Application
首先我们要先启动一个Application,这个Application就是我们的spark-shell。
- SPARK_MASTER=spark://web02.dw:7077 bin/spark-shell
- [root@web02 spark]# SPARK_MASTER=spark://web02.dw:7077 bin/spark-shell
- 14/05/14 17:16:02 INFO HttpServer: Starting HTTP Server
- Welcome to
- ____ __
- / __/__ ___ _____/ /__
- _\ \/ _ \/ _ `/ __/ '_/
- /___/ .__/\_,_/_/ /_/\_\ version 0.9.1
- /_/
- Using Scala version 2.10.3 (Java HotSpot(TM) 64-Bit Server VM, Java 1.6.0_20)
- Type in expressions to have them evaluated.
- Type :help for more information.
- 14/05/14 17:16:06 INFO Slf4jLogger: Slf4jLogger started
- 14/05/14 17:16:06 INFO Remoting: Starting remoting
- 14/05/14 17:16:06 INFO Remoting: Remoting started; listening on addresses :[akka.tcp://[email protected]:16231]
- 14/05/14 17:16:06 INFO Remoting: Remoting now listens on addresses: [akka.tcp://[email protected]:16231]
- 14/05/14 17:16:06 INFO SparkEnv: Registering BlockManagerMaster
- 14/05/14 17:16:06 INFO DiskBlockManager: Created local directory at /tmp/spark-local-20140514171606-60f2
- 14/05/14 17:16:06 INFO MemoryStore: MemoryStore started with capacity 294.4 MB.
- 14/05/14 17:16:06 INFO ConnectionManager: Bound socket to port 60841 with id = ConnectionManagerId(web02.dw,60841)
- 14/05/14 17:16:06 INFO BlockManagerMaster: Trying to register BlockManager
- 14/05/14 17:16:06 INFO BlockManagerMasterActor$BlockManagerInfo: Registering block manager web02.dw:60841 with 294.4 MB RAM
- 14/05/14 17:16:06 INFO BlockManagerMaster: Registered BlockManager
- 14/05/14 17:16:06 INFO HttpServer: Starting HTTP Server
- 14/05/14 17:16:06 INFO HttpBroadcast: Broadcast server started at http://10.1.8.207:37532
- 14/05/14 17:16:06 INFO SparkEnv: Registering MapOutputTracker
- 14/05/14 17:16:06 INFO HttpFileServer: HTTP File server directory is /tmp/spark-f2865aa6-9bda-4980-a7ff-838f9ae87a18
- 14/05/14 17:16:06 INFO HttpServer: Starting HTTP Server
- 14/05/14 17:16:07 INFO SparkUI: Started Spark Web UI at http://web02.dw:4040
- 14/05/14 17:16:07 INFO AppClient$ClientActor: Connecting to master spark://web02.dw:7077...
- 14/05/14 17:16:07 INFO SparkDeploySchedulerBackend: Connected to Spark cluster with app ID app-20140514171607-0005
- 14/05/14 17:16:07 INFO AppClient$ClientActor: Executor added: app-20140514171607-0005/0 on worker-20140514155706-web01.dw-49813 (web01.dw:49813) with 4 cores
- 14/05/14 17:16:07 INFO SparkDeploySchedulerBackend: Granted executor ID app-20140514171607-0005/0 on hostPort web01.dw:49813 with 4 cores, 1024.0 MB RAM
- 14/05/14 17:16:07 INFO AppClient$ClientActor: Executor added: app-20140514171607-0005/1 on worker-20140514155704-db01.dw-30929 (db01.dw:30929) with 4 cores
- 14/05/14 17:16:07 INFO SparkDeploySchedulerBackend: Granted executor ID app-20140514171607-0005/1 on hostPort db01.dw:30929 with 4 cores, 1024.0 MB RAM
- 14/05/14 17:16:07 INFO AppClient$ClientActor: Executor added: app-20140514171607-0005/2 on worker-20140514155706-db01.dw-60995 (db01.dw:60995) with 4 cores
- 14/05/14 17:16:07 INFO SparkDeploySchedulerBackend: Granted executor ID app-20140514171607-0005/2 on hostPort db01.dw:60995 with 4 cores, 1024.0 MB RAM
- 14/05/14 17:16:07 INFO AppClient$ClientActor: Executor added: app-20140514171607-0005/3 on worker-20140514155704-web01.dw-50163 (web01.dw:50163) with 4 cores
- 14/05/14 17:16:07 INFO SparkDeploySchedulerBackend: Granted executor ID app-20140514171607-0005/3 on hostPort web01.dw:50163 with 4 cores, 1024.0 MB RAM
- 14/05/14 17:16:07 INFO AppClient$ClientActor: Executor updated: app-20140514171607-0005/0 is now RUNNING
- 14/05/14 17:16:07 INFO AppClient$ClientActor: Executor updated: app-20140514171607-0005/1 is now RUNNING
- 14/05/14 17:16:07 INFO AppClient$ClientActor: Executor updated: app-20140514171607-0005/3 is now RUNNING
- 14/05/14 17:16:07 INFO AppClient$ClientActor: Executor updated: app-20140514171607-0005/2 is now RUNNING
- Created spark context..
- Spark context available as sc.
- scala> 14/05/14 17:16:08 INFO SparkDeploySchedulerBackend: Registered executor: Actor[akka.tcp://[email protected]:60575/user/Executor#800679015] with ID 0
- 14/05/14 17:16:08 INFO SparkDeploySchedulerBackend: Registered executor: Actor[akka.tcp://[email protected]:3379/user/Executor#1116201144] with ID 3
- 14/05/14 17:16:08 INFO SparkDeploySchedulerBackend: Registered executor: Actor[akka.tcp://[email protected]:14501/user/Executor#-1849151050] with ID 1
- 14/05/14 17:16:08 INFO SparkDeploySchedulerBackend: Registered executor: Actor[akka.tcp://[email protected]:63875/user/Executor#-1596518942] with ID 2
- 14/05/14 17:16:09 INFO BlockManagerMasterActor$BlockManagerInfo: Registering block manager web01.dw:15040 with 588.8 MB RAM
- 14/05/14 17:16:09 INFO BlockManagerMasterActor$BlockManagerInfo: Registering block manager web01.dw:16038 with 588.8 MB RAM
- 14/05/14 17:16:09 INFO BlockManagerMasterActor$BlockManagerInfo: Registering block manager db01.dw:60398 with 588.8 MB RAM
- 14/05/14 17:16:09 INFO BlockManagerMasterActor$BlockManagerInfo: Registering block manager db01.dw:60074 with 588.8 MB RAM
这里可以看到其实创建一个Application就要初始化一个SparkContext。
大致流程是:
1. Master启动,启动一个监听端口注册BlockManager。
2. Master注册自己,并创建一个HTTP Server 广播给slaves
3. 注册MapOutputTracker,启动HTTP File Server
4.启动Spark WebUI
5.Client Actor连接上spark://web02.dw:7077
6.每个节点都启动了一个Executor等待执行任务。(有SparkDeploySchedulerBackend完成)
7.创建SparkContext
8.注册slave到BlockManger,主要以内存为单位。
6.2 读取hdfs文件
为了读取hdfs文件,首先要导入hadoop input format,和Writable类包。
然后spark context 的hadoopFile 方法 需要指定格式。见API:
- def
- hadoopFile[K, V, F <: InputFormat[K, V]](path: String)(implicit km: ClassTag[K], vm: ClassTag[V], fm: ClassTag[F]): RDD[(K, V)]
- Smarter version of hadoopFile() that uses class tags to figure out the classes of keys, values and the InputFormat so that users don't need to pass them directly. Instead, callers can just write, for example,
- val file = sparkContext.hadoopFile[LongWritable, Text, TextInputFormat](path)
- Note: Because Hadoop's RecordReader class re-uses the same Writable object for each record, directly caching the returned RDD will create many references to the same object. If you plan to directly cache Hadoop writable objects, you should first copy them using a map function.
接下来执行一下:
指定这个文件的格式是k,v格式即PairedRDD,key是longwritable,value是Text,指定读取格式为TextInputFormat,同时也支持sequencefile.
- scala> import org.apache.hadoop.mapred._
- import org.apache.hadoop.mapred._
- scala> import org.apache.hadoop.io._
- import org.apache.hadoop.io._
- scala> val f = sc.hadoopFile[LongWritable, Text, TextInputFormat]("/dw/jyzj_market_trade.txt")
- 14/04/21 17:28:20 INFO MemoryStore: ensureFreeSpace(73490) called with curMem=0, maxMem=308713881
- 14/04/21 17:28:20 INFO MemoryStore: Block broadcast_0 stored as values to memory (estimated size 71.8 KB, free 294.3 MB)
- 14/04/21 17:28:20 DEBUG BlockManager: Put block broadcast_0 locally took 64 ms
- 14/04/21 17:28:20 DEBUG BlockManager: Put for block broadcast_0 without replication took 65 ms
- f: org.apache.spark.rdd.RDD[(org.apache.hadoop.io.LongWritable, org.apache.hadoop.io.Text)] = HadoopRDD[0] at hadoopFile at
: 18
执行流程(回头要详细研究一下):
1. MemoryStore首先要确保内存空余空间是否满足
2. Block广播存储在内存中
3. BlockManger将块放入内存了,因为这个文件实在太小了。
4. 没有指定备份
5. 最后f是一个HadoopRDD
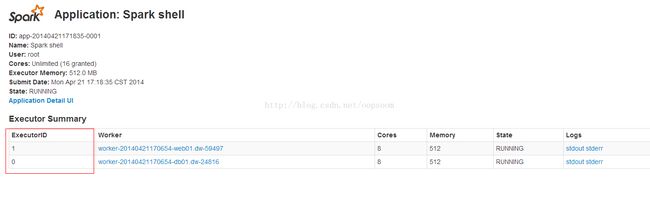
接下来看下监控页面已经监控到了程序的运行:

点击appid可以看到执行该app的监控:
这里的确是启动了2个Executor。
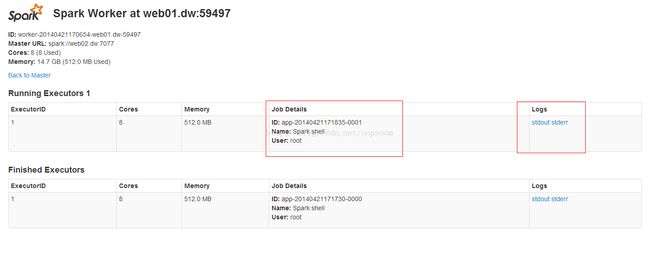
点击worker查看worker的运行状态:
看到wb01的Job详情,如果想看到输出,就点击logs下面的stdout。
因为transformation是lazy的,所以要等到计算完action的时候,我们才能看到stdout。
下面我们做什么示范好呢?wordcount吗?怎么每次想到的都是这个,没创意=。=
好吧,要注意我们这个RDD是K,V的。
- f.flatMap(_._2.toString().split("\t")).map(word=>(word,1)).reduceByKey(_+_) foreach println
介绍一下流程:
1. 因为访问的是hdfs,要用hadoop用户登录才有权限。
2. Client来连接hdfs,使用ClientProtocol,调用IPC
3. 获取协议Version。
4. 连接到datanode,获取文件的split,这里只有2个。
5.FileInputFormat读取文件。
6.SparkContext开始提交job
7.DAGScheduler开始优化解析执行Stage计划。
8.DaGScheduler对应每个Stage,提交不同的Task任务给Executor执行(执行优先考虑数据本地化)
9.TaskSetManger对Task进行管理序列化task与反序列化Task。有一个Pool来管理taskset。
10.MapOutputTrackerMasterActor被要求发送map output的地址到works的shuffler上。(此步骤在reduce Stage会触发)
11.ShuffleMapTask进行洗牌,因为有reduce的action.计算wordcount
12.最后合并结果输出。
- 14/04/21 17:46:26 DEBUG UserGroupInformation: hadoop login
- 14/04/21 17:46:26 DEBUG UserGroupInformation: hadoop login commit
- 14/04/21 17:46:26 DEBUG UserGroupInformation: using local user:UnixPrincipal: root
- 14/04/21 17:46:26 DEBUG UserGroupInformation: UGI loginUser:root (auth:SIMPLE)
- 14/04/21 17:46:26 DEBUG FileSystem: Creating filesystem for hdfs://web02.dw:9000
- 14/04/21 17:46:26 DEBUG Client: The ping interval is60000ms.
- 14/04/21 17:46:26 DEBUG Client: Use SIMPLE authentication for protocol ClientProtocol
- 14/04/21 17:46:26 DEBUG Client: Connecting to web02.dw/10.1.8.207:9000
- 14/04/21 17:46:26 DEBUG Client: IPC Client (47) connection to web02.dw/10.1.8.207:9000 from root: starting, having connections 1
- 14/04/21 17:46:26 DEBUG Client: IPC Client (47) connection to web02.dw/10.1.8.207:9000 from root sending #0
- 14/04/21 17:46:26 DEBUG Client: IPC Client (47) connection to web02.dw/10.1.8.207:9000 from root got value #0
- 14/04/21 17:46:26 DEBUG RPC: Call: getProtocolVersion 55
- 14/04/21 17:46:26 DEBUG DFSClient: Short circuit read is false
- 14/04/21 17:46:26 DEBUG DFSClient: Connect to datanode via hostname is false
- 14/04/21 17:46:26 DEBUG NativeCodeLoader: Trying to load the custom-built native-hadoop library...
- 14/04/21 17:46:26 DEBUG NativeCodeLoader: Failed to load native-hadoop with error: java.lang.UnsatisfiedLinkError: no hadoop in java.library.path
- 14/04/21 17:46:26 DEBUG NativeCodeLoader: java.library.path=
- 14/04/21 17:46:26 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
- 14/04/21 17:46:26 WARN LoadSnappy: Snappy native library not loaded
- 14/04/21 17:46:26 DEBUG Client: IPC Client (47) connection to web02.dw/10.1.8.207:9000 from root sending #1
- 14/04/21 17:46:26 DEBUG Client: IPC Client (47) connection to web02.dw/10.1.8.207:9000 from root got value #1
- 14/04/21 17:46:26 DEBUG RPC: Call: getFileInfo 72
- 14/04/21 17:46:26 INFO FileInputFormat: Total input paths to process : 1
- 14/04/21 17:46:26 DEBUG Client: IPC Client (47) connection to web02.dw/10.1.8.207:9000 from root sending #2
- 14/04/21 17:46:26 DEBUG Client: IPC Client (47) connection to web02.dw/10.1.8.207:9000 from root got value #2
- 14/04/21 17:46:26 DEBUG RPC: Call: getBlockLocations 4
- 14/04/21 17:46:26 DEBUG FileInputFormat: Total # of splits: 2
- 14/04/21 17:46:26 INFO SparkContext: Starting job: foreach at
: 21 - 14/04/21 17:46:26 INFO DAGScheduler: Registering RDD 3 (reduceByKey at
: 21) - 14/04/21 17:46:26 INFO DAGScheduler: Got job 0 (foreach at
: 21) with 2 output partitions (allowLocal=false) - 14/04/21 17:46:26 INFO DAGScheduler: Final stage: Stage 0 (foreach at
: 21) - 14/04/21 17:46:26 INFO DAGScheduler: Parents of final stage: List(Stage 1)
- 14/04/21 17:46:26 INFO DAGScheduler: Missing parents: List(Stage 1)
- 14/04/21 17:46:26 DEBUG DAGScheduler: submitStage(Stage 0)
- 14/04/21 17:46:26 DEBUG DAGScheduler: missing: List(Stage 1)
- 14/04/21 17:46:26 DEBUG DAGScheduler: submitStage(Stage 1)
- 14/04/21 17:46:26 DEBUG DAGScheduler: missing: List()
- 14/04/21 17:46:26 INFO DAGScheduler: Submitting Stage 1 (MapPartitionsRDD[3] at reduceByKey at
: 21), which has no missing parents - 14/04/21 17:46:26 DEBUG DAGScheduler: submitMissingTasks(Stage 1)
- 14/04/21 17:46:26 INFO DAGScheduler: Submitting 2 missing tasks from Stage 1 (MapPartitionsRDD[3] at reduceByKey at
: 21) - 14/04/21 17:46:26 DEBUG DAGScheduler: New pending tasks: Set(ShuffleMapTask(1, 0), ShuffleMapTask(1, 1))
- 14/04/21 17:46:26 INFO TaskSchedulerImpl: Adding task set 1.0 with 2 tasks
- 14/04/21 17:46:26 DEBUG TaskSetManager: Epoch for TaskSet 1.0: 0
- 14/04/21 17:46:26 DEBUG TaskSetManager: Valid locality levels for TaskSet 1.0: NODE_LOCAL, ANY
- 14/04/21 17:46:26 DEBUG DAGScheduler: submitStage(Stage 0)
- 14/04/21 17:46:26 DEBUG DAGScheduler: missing: List(Stage 1)
- 14/04/21 17:46:26 DEBUG DAGScheduler: submitStage(Stage 1)
- 14/04/21 17:46:26 DEBUG TaskSchedulerImpl: parentName: , name: TaskSet_1, runningTasks: 0
- 14/04/21 17:46:26 INFO TaskSetManager: Starting task 1.0:0 as TID 0 on executor 0: db01.dw (NODE_LOCAL)
- 14/04/21 17:46:26 INFO TaskSetManager: Serialized task 1.0:0 as 1896 bytes in 10 ms
- 14/04/21 17:46:26 INFO TaskSetManager: Starting task 1.0:1 as TID 1 on executor 0: db01.dw (NODE_LOCAL)
- 14/04/21 17:46:26 INFO TaskSetManager: Serialized task 1.0:1 as 1896 bytes in 1 ms
- 14/04/21 17:46:26 DEBUG DAGScheduler: submitStage(Stage 0)
- 14/04/21 17:46:26 DEBUG DAGScheduler: missing: List(Stage 1)
- 14/04/21 17:46:26 DEBUG DAGScheduler: submitStage(Stage 1)
- 14/04/21 17:46:26 DEBUG DAGScheduler: submitStage(Stage 0)
- 14/04/21 17:46:26 DEBUG DAGScheduler: missing: List(Stage 1)
- 14/04/21 17:46:26 DEBUG DAGScheduler: submitStage(Stage 1)
- 14/04/21 17:46:27 DEBUG TaskSchedulerImpl: parentName: , name: TaskSet_1, runningTasks: 2
- 14/04/21 17:46:27 DEBUG TaskSchedulerImpl: parentName: , name: TaskSet_1, runningTasks: 1
- 14/04/21 17:46:27 DEBUG TaskSchedulerImpl: parentName: , name: TaskSet_1, runningTasks: 0
- 14/04/21 17:46:28 INFO DAGScheduler: Completed ShuffleMapTask(1, 1)
- 14/04/21 17:46:28 INFO TaskSetManager: Finished TID 1 in 1345 ms on db01.dw (progress: 1/2)
- 14/04/21 17:46:28 INFO TaskSetManager: Finished TID 0 in 1371 ms on db01.dw (progress: 2/2)
- 14/04/21 17:46:28 INFO TaskSchedulerImpl: Removed TaskSet 1.0, whose tasks have all completed, from pool
- 14/04/21 17:46:28 DEBUG DAGScheduler: ShuffleMapTask finished on 0
- 14/04/21 17:46:28 DEBUG DAGScheduler: submitStage(Stage 0)
- 14/04/21 17:46:28 DEBUG DAGScheduler: missing: List(Stage 1)
- 14/04/21 17:46:28 DEBUG DAGScheduler: submitStage(Stage 1)
- 14/04/21 17:46:28 INFO DAGScheduler: Completed ShuffleMapTask(1, 0)
- 14/04/21 17:46:28 DEBUG DAGScheduler: ShuffleMapTask finished on 0
- 14/04/21 17:46:28 INFO DAGScheduler: Stage 1 (reduceByKey at
: 21) finished in 1.385 s - 14/04/21 17:46:28 INFO DAGScheduler: looking for newly runnable stages
- 14/04/21 17:46:28 INFO DAGScheduler: running: Set()
- 14/04/21 17:46:28 INFO DAGScheduler: waiting: Set(Stage 0)
- 14/04/21 17:46:28 INFO DAGScheduler: failed: Set()
- 14/04/21 17:46:28 DEBUG MapOutputTrackerMaster: Increasing epoch to 1
- 14/04/21 17:46:28 INFO DAGScheduler: Missing parents for Stage 0: List()
- 14/04/21 17:46:28 INFO DAGScheduler: Submitting Stage 0 (MapPartitionsRDD[5] at reduceByKey at
: 21), which is now runnable - 14/04/21 17:46:28 DEBUG DAGScheduler: submitMissingTasks(Stage 0)
- 14/04/21 17:46:28 INFO DAGScheduler: Submitting 2 missing tasks from Stage 0 (MapPartitionsRDD[5] at reduceByKey at
: 21) - 14/04/21 17:46:28 DEBUG DAGScheduler: New pending tasks: Set(ResultTask(0, 1), ResultTask(0, 0))
- 14/04/21 17:46:28 INFO TaskSchedulerImpl: Adding task set 0.0 with 2 tasks
- 14/04/21 17:46:28 DEBUG TaskSetManager: Epoch for TaskSet 0.0: 1
- 14/04/21 17:46:28 DEBUG TaskSetManager: Valid locality levels for TaskSet 0.0: ANY
- 14/04/21 17:46:28 DEBUG TaskSchedulerImpl: parentName: , name: TaskSet_0, runningTasks: 0
- 14/04/21 17:46:28 INFO TaskSetManager: Starting task 0.0:0 as TID 2 on executor 1: web01.dw (PROCESS_LOCAL)
- 14/04/21 17:46:28 INFO TaskSetManager: Serialized task 0.0:0 as 1765 bytes in 0 ms
- 14/04/21 17:46:28 INFO TaskSetManager: Starting task 0.0:1 as TID 3 on executor 0: db01.dw (PROCESS_LOCAL)
- 14/04/21 17:46:28 INFO TaskSetManager: Serialized task 0.0:1 as 1765 bytes in 0 ms
- 14/04/21 17:46:28 INFO MapOutputTrackerMasterActor: Asked to send map output locations for shuffle 0 to spark@db01.dw:36699
- 14/04/21 17:46:28 INFO MapOutputTrackerMaster: Size of output statuses for shuffle 0 is 134 bytes
- 14/04/21 17:46:28 DEBUG TaskSchedulerImpl: parentName: , name: TaskSet_0, runningTasks: 2
- 14/04/21 17:46:28 DEBUG TaskSchedulerImpl: parentName: , name: TaskSet_0, runningTasks: 1
- 14/04/21 17:46:28 INFO DAGScheduler: Completed ResultTask(0, 1)
- 14/04/21 17:46:28 INFO TaskSetManager: Finished TID 3 in 286 ms on db01.dw (progress: 1/2)
- 14/04/21 17:46:28 INFO MapOutputTrackerMasterActor: Asked to send map output locations for shuffle 0 to spark@web01.dw:45200
- 14/04/21 17:46:29 DEBUG TaskSchedulerImpl: parentName: , name: TaskSet_0, runningTasks: 0
- 14/04/21 17:46:29 INFO DAGScheduler: Completed ResultTask(0, 0)
- 14/04/21 17:46:29 INFO TaskSetManager: Finished TID 2 in 1019 ms on web01.dw (progress: 2/2)
- 14/04/21 17:46:29 INFO DAGScheduler: Stage 0 (foreach at
: 21) finished in 1.020 s - 14/04/21 17:46:29 INFO TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool
- 14/04/21 17:46:29 DEBUG DAGScheduler: After removal of stage 0, remaining stages = 1
- 14/04/21 17:46:29 DEBUG DAGScheduler: After removal of stage 1, remaining stages = 0
- 14/04/21 17:46:29 INFO SparkContext: Job finished: foreach at
: 21, took 2.547314739 s - scala> 14/04/21 17:46:36 DEBUG Client: IPC Client (47) connection to web02.dw/10.1.8.207:9000 from root: closed
- 14/04/21 17:46:36 DEBUG Client: IPC Client (47) connection to web02.dw/10.1.8.207:9000 from root: stopped, remaining connections 0
结果如图:
第一个slave:

第二个slave:

注意一下,这里执行用了2.5s
如果我把 f 缓存到集群里:
- scala> f.cache
- res1: org.apache.spark.rdd.RDD[(org.apache.hadoop.io.LongWritable, org.apache.hadoop.io.Text)] = HadoopRDD[0] at hadoopFile at
: 18
再次执行,只用了0.14秒:
- 14/04/21 18:14:10 INFO SparkContext: Job finished: foreach at
: 21, took 0.144185907 s