pandas数据处理基本操作
一.创建数据
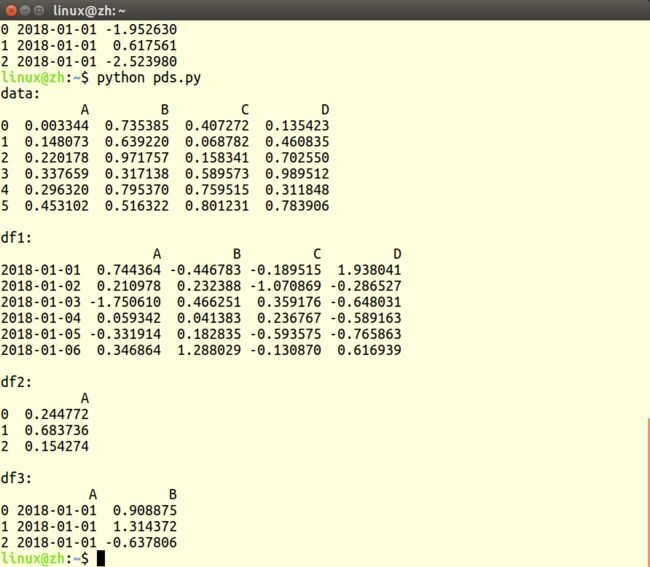
import pandas as pd
import numpy as np
# 生成6*4数据集
data = pd.DataFrame(np.random.rand(6,4), columns=list('ABCD'))
# 创建时间索引
date = pd.date_range('20180101', periods=6)
# 再创建6*4数据集
df1 = pd.DataFrame(np.random.randn(6,4),index=date,columns=list('ABCD'))
# 使用字典创建数据
df2 = pd.DataFrame({"A":np.random.randn(3)})
print(df2)
# 另一种字典创建数据集的方法
df3 = pd.DataFrame({'A':pd.Timestamp('20180101'),'B':np.random.randn(3)})
print(df3)运行结果
二.查看数据
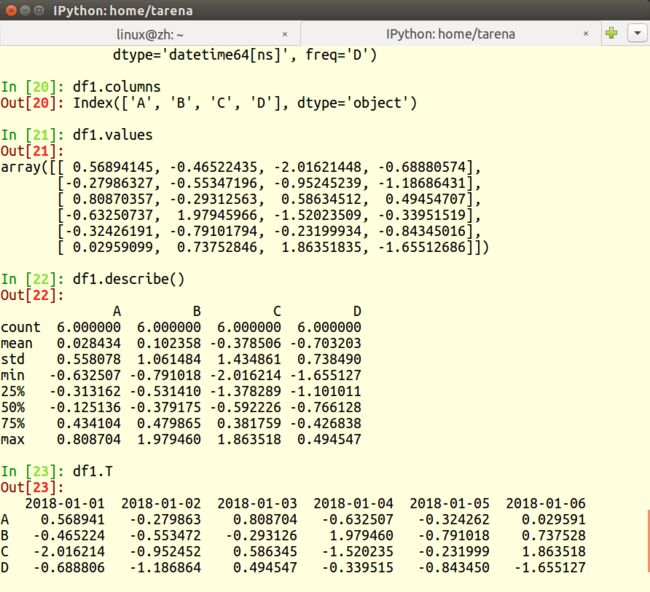
1.使用dtypes查看数据格式
df3.dtypes
2.查看所有数据
df3
3.使用head查看前几行数据,默认5行
df1.head()
4.使用tail查看后几行数据,默认5行
df1.tail()
5.查看数据索引
df1.index
6.columns查看列名
df1.columns
7.values查看数据值
df1.values
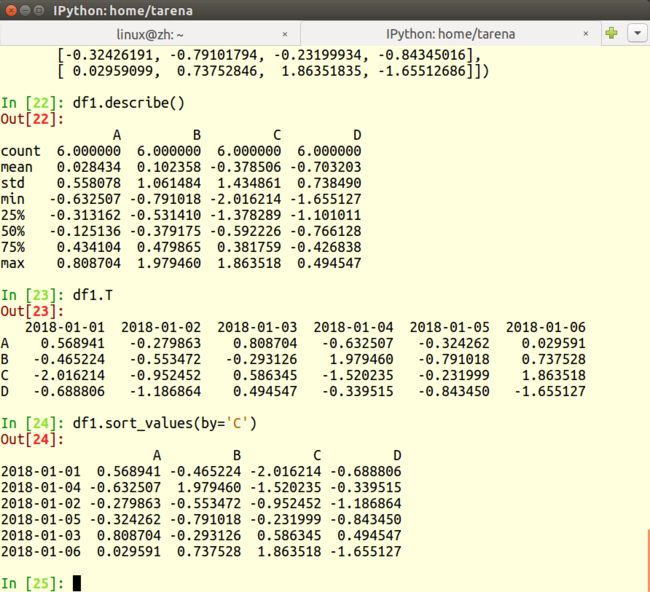
8.describe查看描述性统计
df1.describe()
9.T转置
df1.T
10.sort_values对数据排序
df1.sort_values(by='C')
运行结果如下

三、选择数据
偷懒不贴结果了...
1.根据列名选择数据
df1['A']
2.数组切片
df1[1:3]
3.通过行标签指定输出行(限定行,不限定列)
df1['20180101':'20180104']
4.使用loc方法选择多列数据(限定行,不限定列)
df1.loc[dates[0]:dates[2], :]
5.使用loc方法选择多列数据(限定列,不限定行)
df1.loc[:, 'B':'D']
6.使用loc方法选择多列数据(行列都限定,且列只要指定的类型)
df1.loc[dates[0]:dates[2], ['B': 'D']]
7.使用loc方法选择某行数据(指定行)
df1.loc[dates[0]]
8.使用loc方法只选择某个数据,可指定行和列
df1.loc[dates[0], 'B']
9.at方法专门获取某个值
df1.at[dates[0], 'B']
10.使用iloc方法提取某行数据(如第四行)
df1.iloc[3]
11.返回指定行列数据(如第4-5行,第2-3列)
df1.iloc[3:5, 1:3]
12.提取不连续的行和列的数据(如第2,4,6行的B列和D列)
df1.iloc[[1,3,5], [1,3]]
13.提取某几行数据,保留所有列
df1.iloc[1:3, :]
14.提前某个值(如第二行第二列)
df1.iloc[1, 1]
15.iat专门提取某个数
df1.iat[1, 1]
四、读取和保存文件
1.读取csv文件
df4 = pd.read_csv('csv文件路径', encoding='编码格式')
2.读取excel文件
exc = pd.read_excel('excel文件路径', encoding='编码格式')
3.读取.bat文件
tab = pd.read_table('.bat文件路径', encoding='编码格式')
4.保存为csv文件
DataFrame格式数据可直接用to_csv方法导出到csv文件中
dataframe.to_csv('csv文件路径', encoding='编码格式', index=False)
五、筛选数据
1.单条件筛选
df1[df1.D>0]
2.多条件筛选
df1[(df1.D>0) & (df1.C<0)]
df1[(df1.D>0) | (df1.C>0)]
3.限定所需列或行,再进行筛选
df1['A', 'C'][(df1.D>0) & (df1.C<0)]
4.isin方法筛选特定值
golist=[0.360401, 0.134254, 0.240838]
df1['D'].isin(golist)
六、增加删除
1.增加列
df1['E'] = pd.Series(np.random.randn(6), index=df1.index)
df1.insert(1, 'a', np.random.randn(6))
2.删除列
del df1['a']
df1.drop(['D', 'E'], axis=1) # 此方法不改变原数据,而是返回另一个DataFrame存放删除后的数据
七、计数统计
1.统计满足条件的数据的数量
df[条件][某列].value_counts()
2.统计满足条件的数据的总数
df[条件][某列].sum()
八、数据分组
1.groupby()分组
group_ID = df5.grouyby('ID') # 按ID分组
group_ID = df5.groupby(['ID', 'blank_id']) # 同ID数据按blank_id再分组
2.aggregate()分组计算
df5.groupby(['ID', 'blank_id']).aggregate(np.sum)
3.size()查看各组数据量
df5.size()
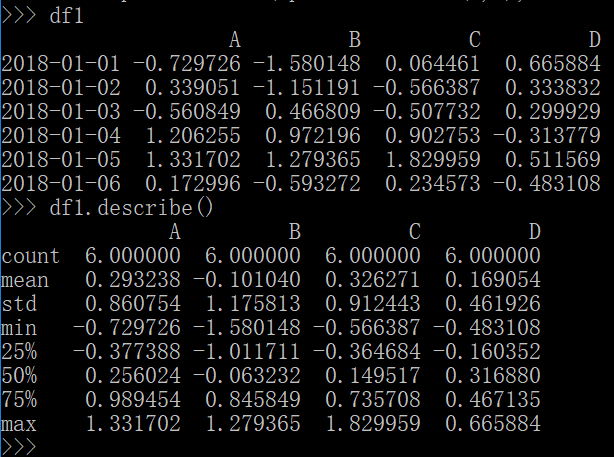
4.describe()对各组数据进行描述性统计
df1.describe()
结果:
5.agg分组多种计算
df1.agg([np.sum, np.mean, np.std]) # 计算各组数据的和、平均数、标准差
df1['A'].agg([np.sum, np.mean, np.std]) # 指定某列数据,计算和、平均数、标准差
df1['A'].agg({'和':np.sum, '平均数':np.mean, '标准差':np.std}) # 指定统计结果显示标题
九、缺失值处理
遇到缺失值,运算结果在相应位置也是缺失的,在描述性统计中,Nan是当作0来运算的
1.用固定值代替缺失值
df1.fillna(0)
df1.fillna('替代字符串')
2.用临近值代替缺失值
df1.fillna(method='pad') # 用前一个数据代替
df1.fillna(method='bfill') # 用后一个数据代替
df1.fillna(method='padd', limit=1) # 限制每列可替代次数
3.用统计值代替缺失值
df1.fillna(df1.mean) # 用平均数代替,也可使用其他描述性统计量
df1.fillna(df1.mean)['A':'C'] # 指定哪一列的数据缺失值进行处理
4.插入法填补缺失值
插入法是通过两个点估算中间点的值
df1.interpolate()
df1.interpolate(method='values') # index为数字时,可用参数method='values'插入值
df1.interpolate(method='time') # index为时间时,可用参数method='time'插入值
5.删除缺失值
可选择删除列或删除行,使用方法都是DataFrame.dropna()
df1.dropna(axis=0) # 删除行
df1.dropna(axis=1) # 删除列
6.值替换
ser = pd.Series([0,1,2,3,4])
ser.replace(0, 8) # 用8替换0(全部替换)
ser['列名'][切片索引:切片索引] # 只替换指定位置的数据值
ser.replace([0,1,2,3,4], [9,8,7,6,5]) # 用新列表替换原列表
ser.replace({1:11, 2:22}) # 用字典形式将1替换成11,将2替换成22
十、排序与合并
1.排序 sort_values(by='列名')
df1.sort_values(by='A') # 按A列数据值大小排序
2.合并 merge()
类似与关系型数据库的join操作
data_train = pd.merge(df1, df2, how='right', on='ID') # 两表按ID合并,以右表数据值为准
3.合并 concat()
pd.concat([df1, df2]) # 直接合并,默认按索引拼接(不改变原索引),缺失值用Nan填充
pd.concat([df1, df2], igore_index=True) # 直接合并,重新生成索引
pd.concat([df1, df2], axis=1) # 按索引合并,相同索引合并成同一行
十一、可视化操作
1.散点图
plt = data.plot(kind='scatter', x='X', y='Y').get_figure()
plt.savefig('图片保存地址')
2.柱状图
plt2 = data.plot(kind='bar').get_figure()
plt2.savefig('图片保存地址')
3.堆积直方图
plt3 = data.plot(kind='bar', stacked=True).get_figure()
4.箱状图(用于显示数据基本统计量:中位数、平均数、四分位数等)
import matplotlib.pyplot as plt
data.boxplt()
十二、字符串操作
1.生成字符串
s = pd.Series(list('字符串'))
2.大小写转换
s.str.lower()
s.str.upper()
3.获取长度
s.str.len()
4.切割字符串,转换list
s.str.split()
5.获取某个字符
s.str.get(下标数字)
6.替换字符
s.str.replace('正则表达式', '替换字符')
7.字符串匹配
s.str.contains(正则表达式, na=False) # na参数用于规定将Nan数据匹配成True或False
s.strr.match(正则表达式, na=False)
8.判断开头结尾
s.str.startswith('A', na=False) # 判断是否以xx开头
s.str.endswith('A', na=False) # 判断是否以xx结尾
十三、广播
一个矩阵或向量减去一个常数,通常是矩阵中的每个元素减去这个常数,这就是广播
row = df.ix[1]
df.sub(row, axis='column') # 将df中的每一行与row做减法,axis参数指定广播维度
十四、数据库操作
import MySQLdb
con = MySQLdb.connect(host='localhost', db='数据库名')
sql = 'sql语句'
1.读取数据
df = pd.read_sql(sql, con)
2.将某列数据设置为索引
df = pd.read_sql(sql, con, index_col=['列名', ...])
3.删除表
con.execute('sql语句')
4.将数据保存到指定表中