智慧城市以及智慧医疗
能通过未来的智能交通来降低雾霾吗?
将不同的资源联系在一起,减少资源错配,就是通过所谓大数据和智能化来改造传统产业的一个最大效果。减少汽车数量,减少汽车空载率,才能提高交通运输的效率,减少拥堵和减少交通事故。
将公共交通网和私人交通网结合-这就是智能交通带给行业的最大变革。优化资源配置,减少资源错配和车辆的空载率。
Nature最新论文解读:最小车队问题与“乌托邦”交通系统
随着共享出行的普及,以及全路网的自动驾驶变得越来越可能,我们完全可以实现一个由算法管理的乌托邦式的城市交通系统。这样的系统可以做到按需交通(On-demand urban mobility),即根据每个人的需求动态地分配运载车辆,从而实现整体的最优化。从技术上说,作者首先把按需交通问题映射为一个理想化数学问题——最小车队问题,并在与实际纽约市出租汽车15亿条出行数据相结合的情况下,给出了该问题的最优解。结果表明,使用算法管理的交通系统可以将出租车使用数量减少40%左右。即使在考虑到出行需求可能实时提交处理的情况,这一缩减量也可以达到30%。因此,该问题的解决不仅可以大大提升共享出行系统的运行效率,也为未来人工智能治理的社会模式提供了一个非常好的示范案例。
自动驾驶与车联网,以及共享出行模式这三种大的趋势将会彻底变革我们未来的交通系统与出行模式,这使得整个交通系统都可能都统一被算法所管理。因此,一个“乌托邦式”的交通系统将不再遥远,在其中,算法可以调度每一部车辆,从而让系统在整体的运行效率达到最高,并能最大化地实现绿色环保。这种模式将会大大优于现有的交通模式,私家车、出租车、公交车将有可能成为历史。
要实现这样的“乌托邦式”交通系统,算法是其中最重要的一环。因为,为了满足所有市民的出行需求,我们需要合理地调度每一部奔跑在道路网络上的自动驾驶汽车,从而做到:(1)能够尽可能高效地满足每一位市民的出行需求;(2)能够在整体上达到成本最小,也就是用最少的车辆和交通来实现尽可能多的出行需求。这样的算法存在吗?一个来自MIT、意大利比萨信息与通信技术研究院以及康奈尔大学、康奈尔技术的合作研究团队给出了肯定的回答。

Nature 新论文:https://www.nature.com/articles/s41586-018-0095-1
1.最小车队问题
该合作团队首先将人们的出行需求简化成了一道并不简单的数学题。让我们来考虑A、B、C、D、E、F这六个人的出行需求,如图1所示:
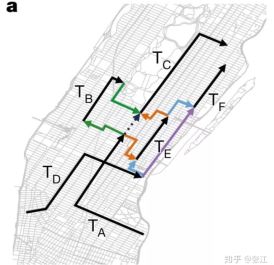
图1:ABCDEF六个人的出行轨迹示意图,分别用T_A、T_B……T_F来表示
T_A、T_B、……、T_F这每一段折线都代表一个用户的出行需求,即用户要从时间点t_p,和地点l_p出发,并在时间t_d到达地点l_d。其中,t_p是自动驾驶汽车能够接到用户A的最早时间,而t_d时间点则可以根据出发时间t_p和路网情况(交通流等因素)估计出来的时间点。
假设,我们可以调度一组自动驾驶车队来满足这一组用户的出行需求。于是,我们可以给每一条出行路线分配不同的汽车,也可以让同一辆汽车先后满足两个用户的出行需求,只需要第二个用户的出行需求与上一个用户的完成时间和空间都相隔不太远就可以完成。也就是说,一辆自动驾驶汽车在完成了一个用户的任务之后,还可以继续接另一个用户,只要该用户所产生的需求时间t_p与该自动驾驶汽车完成上一个任务的结束时间t_d,并考虑到自动驾驶汽车从上一个l_d开到下一个l_p之间的时间间隔不算太大就可以了。
在图1中,彩色的折线段就是一辆自动驾驶汽车在完成了上一个任务之后,进一步完成下一个任务的转换路径。例如,当自动驾驶汽车接到A,并完成任务后,就可能沿着绿色箭头走到B的出发点把B接上送到B的目的地,然后又可以顺着绿色折线箭头赶到C的出发点,从而满足C的需求。
当然,这辆接送A的自动驾驶汽车也可以在载完A后沿着橙色箭头走到E的出发点,然后又去接C,……。因此,在一组给定的用户出行的地点、时间和目的地的情况下,我们的自动驾驶汽车车队可以有不同的方式来满足尽可能多的出行需求。
那么,所谓的最小车队问题也就是:在一组给定的出行需求情况下,我们能否用最少的自动驾驶汽车数量来服务所有的出行任务?
可以想到,如果我们能够从数学上解决这个问题,那么我们就可以用一种最“经济”的方式来运作我们的自动驾驶交通系统,从而做到节约能源、绿色环保。
2.车辆共享网络
然而,这样的抽象问题一下子很难解决,我们必需一个中间过渡工具,这就是“车辆共享网络”(Vehicle-shareability network)。这一网络模型是在参考文献[7]中提出的一种描述共享交通模式的网络模型。他可以用来建模不同的车辆分配方案。例如,图2的有向网络就是一个车辆共享网络,它建模了图1所对应的不同的车辆分配方案:
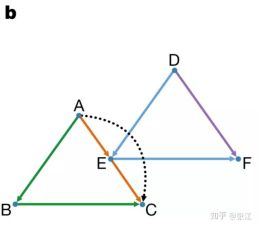
图2 图1所对应的车辆共享网络
在图2这张网络中,一个节点就对应了图1的一个用户的出行需求,因此A就对应图1中T_A这条出行路径。而该图中的一条有向连边则对应了一种可能的任务切换,换句话说,如果节点A和B之间有连边就表示自动驾驶汽车有可能在完成了A任务之后再去完成B任务;如果没有链接,就表示自动驾驶汽车可能在完成了A任务之后由于时间间隔太长,或空间距离太远而不可能再去完成任务B。
图1中的可能路径切换都对应到了图2中的有向连边中。其中,某一辆汽车的完成任务方案就对应为图2中的一条同颜色的有向路径。例如图2中的绿色路径则对应了陆续接送了A、B、C三个用户的自动驾驶汽车。
要想满足所有人的出行需求,就是要寻找到一组路径划分方案,从而使得这些路径能够覆盖共享出行网络上的所有点(服务所有出行需求)。很显然,这样的路径划分方案有很多种,那么什么是最优的呢?
非常有趣的是,这一最少覆盖路径问题恰好就是前文叙述的最小车队问题。于是,利用车辆共享网络,我们巧妙地将最小车队问题转化为了共享网络上的最少路径覆盖问题。
总结来看,我们可以从实际数据出发,利用车辆共享网络来构造一个“最少路径覆盖问题”,它的步骤如下:
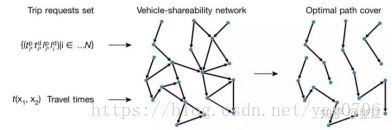
图3 最小车队问题解决流程
接下来,这个问题怎么求解呢?坏消息是,对于一般意义上的最优路径覆盖问题来说,这是一个NP难的问题,我们无法找到有效的计算求解方案;但好消息是,由于我们这个交通工具共享网络具有特殊性,即它是一个有向无环图(directed acycled graph)。这也就意味着,我们可以使用Hopcroft-Karp算法找到该问题的有效解法(具体参见论文附录)。
3.“乌托邦交通”的运行效果
接下来,就让我们来看看这样的最优共享方案的效果如何。作者们结合了纽约市2011年所有出租车的出行数据来构建车辆共享网络。这套数据集中包含了15亿条出行记录,每一条出行记录都对应了用户被出租车接上的时间,也就是t_p、地点,也就是l_p,以及在什么时间,即t_d,用户被送达到指定地点,也就是l_d。这样,我们就可以套用图3所示的算法流程,来计算出每一天,甚至每一小时最优的出租车数量,并与实际出租车使用数量进行对比。
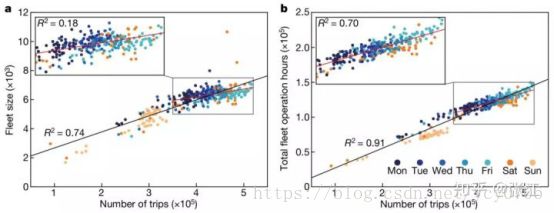
图4 在纽约市出租车出行数据上计算得出的最优汽车数量或总车队运行时间与不同工作日出行数量的关系
首先,如图4所示,我们看到最优的出租车使用数量是会随着人们出行需求的增加而线性增加的。其中不同颜色的点表示不同的工作日(周一、周二等)。右侧的图则展示了车队运行的总时间随着出行次数的增加而线性增加。而我们看到,当出行量在从300,000到550,000之间的时候,增长的斜率会小一些,这表明不仅仅是出行密度,人们出行的模式也会影响最优的数量。
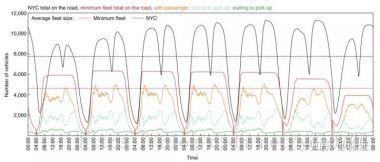
图5 最优车队数量、实际出租车使用数量随时间的变化曲线
其次,图5展示了实际出租车使用数量(黑色)、最优出租车使用数量(红色),以及处于不同模式的出行出租车数量(其它颜色)随时间的波动曲线。虚线对应的是它们的平均值。我们看到,如果使用算法来管理整个交通系统的话,我们每天平均仅需要实际出租车数量的60%就可以了,这足足减少了3000辆出租车的使用!
4.更现实的考虑
虽然60%这个数字是相当惊人的,但是这个数字是建立在一天内所有的需求都是同时提交给优化系统的假设前提下的,这样系统能够有条不紊地安排所有车辆的出行,从而最优化出行配置。
然而,现实情况会比这种情况更加“骨感”得多:一天内的出行需求不可能一下子同时提交给我们的服务器,而必然是实时地、一个个地提交给系统的。那么在这种情况下,我们就需要改进算法。于是,作者提供了两种改进,分别叫直接(on-the-fly)算法和批次算法(batch)。
在第一个算法中,出行需求是序列地一个个被处理的。系统会在所有的车辆中自动选择一个能够让用户等待时间最短的车辆来服务。
在批次算法中,系统是每间隔δ = 1分钟,收集一个批次的需求数据,并利用最大匹配算法来满足所有用户,并让等待时间最短。
为了对比这两种算法,我们使用比最小车队问题略大的车辆数(N_{min}x,其中N_{min}是最小车队数量,x是一个略大于1的参数)来运作,并通过比较两个不同算法的服务总需求的百分比作为评测的指标,结果如图所示:
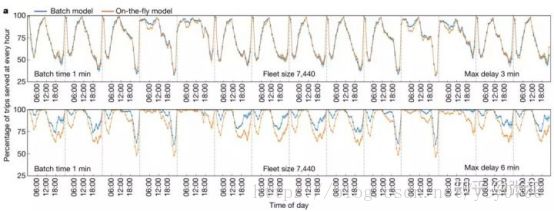
图6: 每天不同小时直接算法和批次算法的服务比率随时间的变化
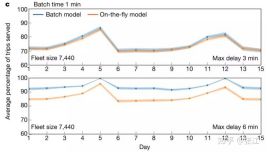
图7: 不同日期直接算法和批次算法所能服务的百分比随日期的变化
图6、7中的横坐标是时间,纵坐标是算法服务的出行百分比,这个百分比越高说明算法越好。我们看到,无论是从小时为单位衡量的出行还是以天为单位的出行,批模型的服务百分比更高。
通过结合出行实际数据和优化算法,我们发现,使用批次模型,我们可以使用实际数量70%的出租车来服务超过90%的出行需求。这虽然没有最优模型酷炫,但也说明考虑到实时服务的情况下,我们仍然可以做到尽可能的高效和足够多用户的满意。
5.人工智能社会的未来
最后,作者总结道:虽然这套算法仅仅解决了单一出行模式、单一车队的优化问题,但它完全可以扩展到多种出行模式的混合交通的优化问题,这为我们解决出行问题提供了更多的想象空间。尽管更便捷的出行很有可能刺激人们更多的出行需求,但是总体来讲,由高效算法管理的自动驾驶交通系统将必然会让我们的交通更加高效和智能。
笔者甚至认为,这篇工作的意义可能还可以延伸到更多的共享经济模式中。利用算法而非人类的主观决策来统一调配管理整个宏观系统将在未来成为可能。
参考文献:
[7] Santi, P. et al. Quantifying the benefits of vehicle pooling with shareability networks. Proc. Natl Acad. Sci. USA 111, 13290–13294 (2014).
论文下载:链接:https://pan.baidu.com/s/1weycQSRQISv8xEl1cgtkkg 密码:0zpw
转载:https://zhuanlan.zhihu.com/p/37328166?utm_source=qq&utm_medium=social&utm_oi=836599536712585216
印度成为全球企业提供智能交通的热门地点
印度对智能交通的需求使该国成为国际公司提供最新技术的热门地点,如出租车、超级高铁、电动车、缆车和索道等。
其中一家公司skyTran是美国国家航空航天局的技术合作伙伴,正在开发一种吊舱车系统——一种沿预定路线运行的无人驾驶车辆。该公司已表示有兴趣在印度建造一条1公里长的领航路,以展示其技术。根据skyTran的说法,它的产品可以作为一种大众快速运输系统,以每小时120公里的速度往返于城市间的通勤,以及每小时200-250公里往返于市内交通。
Virgin Hyperloop One公司原为Hyperloop One,成立于2014年,总部位于洛杉矶,也计划设置低压或真空管,这可以帮助运送货物和人员,通过磁悬浮的pod型汽车,时速可达1000 - 1200公里。
这些海外科技巨头对印度的智能交通表现出强烈的兴趣,这主要归功于印度公路运输部长Nitin Gadkari,他在2014年上任时决定尝试新技术和更快的交通技术。
从那以后,一些关键的举措,比如从Gurugram到Manesar的新型交通工具,以乙醇为基础的公共汽车燃料,将印度的四轮机队转变为电动汽车的想法,都开始提上日程。Gadkari对智能移动的定义是“快速和绿色”。
“我想改变印度的移动体验。我们正在寻找不同的解决方案,我愿意接受新的想法和实验,只要它们环境友好,价格低廉,大众就可以使用它。”Gadkari说,他的议会选区,Nagpur市,是一个测试地区,他曾试图展示几个新的智能移动计划,包括电动出租车和以乙醇为燃料基础的公共汽车。“没有什么是不可能的,”他说。
印度的智能交通仍在发展,这是需要各方协同促进的事情,提出从出租车到公交车等的智能交通解决方案;如何通过移动应用程序或网站访问服务;对于车主来说,如何在路上行驶,如何通过电子方式支付通行费,或者在到达目的地的时候收到短信提醒,甚至在你到达目的地之前预定一个停车位。这些都是需要考虑和解决的。
在这个过程中,印度的移动业务会逐渐变得智能和绿色。如印度国家公路管理局(NHAI)推出的FASTag,制定国家高速公路行驶距离的收费标准,关于国家高速公路交通状况的短信警报,提供地铁和其他公共交通的智能卡,作为迈向智能交通的手段。像Ola和Uber这样的出租车聚合器的移动应用,以及在线预订公交车票的移动应用,也在帮助印度朝着同样的目标前进。
印度决定将电动交通用于公共交通,也将推动绿色交通的实现。像印度公路运输部长Nitin Gadkari这样的强有力的领导者,通过向电动汽车推出大规模转变,改变了汽车行业的发展,可以很快见证诸如pod型出租车和超级高铁等技术。
虽然新技术正在排队以促成智能交通,但有趣的是,缆车和索道等旧技术也重新引起人们的关注。
欧洲公司Doppelmayr的印度业务负责人VikramSinghal表示,缆车或索道不再局限于旅游目的地,它们正在成为空间非常严格的解压缩城市距离的最佳非车辆运输解决方案。事实上,联合国人居署(联合国人类住区计划)也已将缆车视为环境和社会可持续的非车辆运输解决方案。
在过去几个月中,印度各省邦政府也一直表示有兴趣采用缆车作为智能交通的解决方案。当北阿坎德邦计划将其两个著名的城市德拉敦和穆索里使用缆车连接起来时,这将把原本3个小时的旅行时间减少到20分钟。马哈拉施特拉邦正在考察印度在阿拉伯海的第一条索道,连接孟买和埃勒凡塔石窟。该项目是由孟买港口信托公司构想和实施的。
同样地,古吉拉特邦正在吉纳尔建造一条缆车路,而果阿正在建造一条索道,将帕纳吉和雷伊斯马戈斯斯连接到曼多维河的两端。
到目前为止,印度还没有把缆车看成一种大众运输系统。但缆车也有不同的方式可以支持印度智能交通,包括与地铁最后一英里连接,从一个城市到另一个城市旅行,或在丘陵地形的情况下也可以布置缆车作为运输工具。缆车的优势是装置费用不到地铁的60%,项目可以在两年内完成且不影响正常交通。
转载:https://zhuanlan.zhihu.com/p/37526258?utm_source=qq&utm_medium=social&utm_oi=836599536712585216
人工智能在医疗领域的机遇
首先分享一个好消息。粗略统计,今天台下听众本人是90后或孩子是90后的人占到了70-80%。我做医学研究的时候曾看到这样一篇报道说,按照医学的发展速度,2000年左右出生的人,超过一半寿命将超过100岁。这将是一个非常了不起的成就,我非常期待。看到这个好消息,我非常振奋也很好奇,就去查阅了这篇文章背后的学术论文。
我看到一篇2009年在英国《柳叶刀》杂志上发表的论文,它标题写的是“未来的挑战”。假如未来超过一半的人寿命超过100岁,对社会医疗系统将是非常大的挑战。现在人口老龄化已经非常严重,通常来说,人的年纪越大医疗成本就越高。假如超过一半人活过100岁,而我们又没有更好的医疗方法,将给社会带来很大的成本。我们刚开始做医疗研究时,美国每年大约有14%的GDP耗费在医疗上,现在这一占比已经上升到了18%,越来越高了。按这个趋势发展下去,社会将无法承受。我们相信,解决这个问题一定要靠技术。如果没有新的技术,就无法给大家提供好的医疗条件,让大家健康快乐地活到100岁。
我举一个医疗领域的例子——病理切片的解读,这在中国是一个特别大的挑战。中国每10万人口中只有不到两位病理医生,美国每10万人中有超过50位病理医生,日本每10万人中也有超过10位病理医生。也就是说,中国的病理医生非常缺乏。我们再看病理医生要做哪些工作:假如一个人不幸患了肺肿瘤,病理医生要把他的切片切成二三十片,然后仔细观察其中哪一类是病变的,是什么样的病变,A、B、C类型病变的百分比各是多少。这个工作很耗时间,另外,训练这样的专业人才也很困难。假如我们可以用电脑辅助医生做这些工作,是不是可以让他们更加高效?
弱监督学习
所以我们提出了机器学习,这就带出了我的下一个话题——弱监督学习。为什么要提弱监督学习?面对一个病理切片,我们通常有三个目标——分类、切割或聚类。病理图片通常很大,一张病理图片可以达到5万X5万像素,甚至更大。训练模型有三种方法:一是没有标签的训练,这对病理图片来说很难;二是弱标签训练,即利用相对简单的标签学习;三是带详细标签的训练,比如刚才提到的肺肿瘤的例子,你需要标注每一个肿瘤组织的情况。
下面给大家展示两张图片,看看人类是如何学习的。
我给几位医生看过这两张图片,他们很快就发现了其中的差别:上面这张图片中有两种鱼,除了橘色的小丑鱼,还有一种黑白相间的鱼;下面这样图片则只有小丑鱼。使用弱监督学习的时候,只要告诉系统这两张图片有差别,不需要说明差别在哪,让他自己学习就好了。这样一来,标注的工作就少了很多。
回到病理切片的例子,下面这张图片中既有癌细胞又有正常细胞:上面的是癌细胞,下面的是正常细胞。就像前面讲的,我们只需要提供这两类图片,无需勾画所有癌细胞和正常细胞的边界,系统就能学习。这样的好处在于:中国的病理医生很缺乏,让他们标这些图像的边界是非常大的工作量而且也很难。现在只需要标出有没有癌细胞,就相对容易多了。弱监督学习的优势就在于在减少标注工作量的情况下,更充分、有效地利用数据。
这种弱监督学习的方法我们从2012年就开始使用了,当时还没有深度学习。下面介绍一项新的研究成果——把弱监督学习和深度学习结合在一起。大家如果感兴趣,可以查阅我们去年11月发表的论文。

这个方法的基本概念是训练两个分类器,上面是正常细胞,下面是有癌细胞。我们希望自动训练分类器,让它在像素级别告诉我们一个细胞到底是癌细胞还是正常细胞。我们统计出图片中的细胞有癌还是无癌后,再把它放到下图中的训练方程式里。
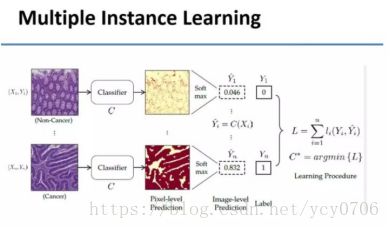
下面是一张比较完整的架构图,我们不仅分了好几层,还用到了Area Constraints。
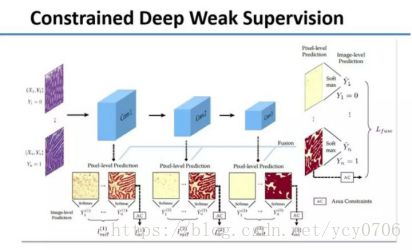
如果光用刚才讲的分类的方法,不管一张图片中有10%的面积是癌细胞,还是60%的面积是癌细胞,它训练的评价模式是一样的。所以它倾向于把越来越多的细胞当成癌细胞。我们想,能不能继续减少标注量,同时还能得到更好的效果?于是我们加入了Area Constraints。医生只需要估计里面到底有10%、20%还是30%的面积是癌细胞就可以了,而不用标出癌细胞在哪,这又减轻了工作量。我们让两位医生标注,如果标注结果不统一,再请第三位医生来看哪个标注结果是正确的。