「自然语言处理(NLP)论文推送」会话响应生成(含源码)【美国卡耐基梅隆大学】
来源:AINLPer微信公众号
编辑: ShuYini
校稿: ShuYini
时间: 2019-8-24
引言
本次主要给大家介绍两篇文章。第一篇文章主要讲的是会话响应生成,其主要针对的是当前神经网络对话系统倾向于在语料库中生成响应的问题,这样不利于会话响应的多样性。第二篇文章主要针对的是模型会话一致检测的问题,怎么才能评估呢?作者提出一种自动在数据集提取实例进行评估的方法。
PS:欢迎关注AINLPer微信公众号,论文解读会每日更新,等你来看。
First Blood
TILE: Boosting Dialog Response Generation
Contributor : Carnegie Mellon University
Paper: https://www.aclweb.org/anthology/P19-1005
Code: None
文章摘要
神经模型已成为对话响应生成的重要方法之一。然而,它们始终倾向于在语料库中生成最常见和通用的响应。针对这一问题,我们设计了一种基于boost的迭代训练过程和集成方法。该方法以不同的训练和解码范式为基础,包括基于互信息的解码和基于奖励增强的最大似然学习。实证结果表明,本文方法可以显著提高所有基本模型所产生的响应的多样性和相关性,并得到客观测量和人类评价的支持
本文创新点介绍
我们相信对话响应的生成也可以从boost中受益。在这项工作中,我们根据最近发展起来的促进生成模型的理论,设计了一个促进响应生成的原则框架。此外,我们将boost与不同的训练和/或解码范式相结合,并通过实验证明,无论是在定量还是定性评估方面,boost都得到不错的效果。
boost应用于对话生成的实际问题考虑
数据权重
在生成式增强方法中,数据的权重与响应的置信度成反比。然而,在实验中发现,一般的反应并不总是有较低的置信度。如果没有正确地处理,这些响应最终会得到增强,并在下一次迭代中成为频繁生成的响应。
为此我们使用一个简单的基于规则的鉴别器。在每次迭代中,我们维护一个最频繁生成响应的列表 C t C_t Ct。我们选择一个二元函数sim(y,z)来判断两个响应y,z是否相似。鉴别器定义为
其中第t轮的数据权重为:

模型合并
在解码时,由于文本数据的离散性,对于具有最高概率(或互信息)的响应的优化是难以处理的,因此我们使用以下启发方式。利用波束搜索从单个最优模型中生成候选响应。然后,所有的模特都会给候选人打分,平均分最高的模特会被选中。模型权重 α t α_t αt将制服。由于每个模型对不同权重的数据进行训练,其非标准化概率密度估计可能具有不同的尺度。因此,在解码时,每个模型的得分都是z归一化的,并根据训练数据计算出平均值和标准差。
算法细节介绍
对于RAML,奖励函数基于TD-IDF匹配,即每个单词的词频与逆文档频率乘积的和除以长度。其基本原理是激励模型在其生成代中包含关键内容词。根据经验,我们观察到,即使没有提高,有上述奖励的RAML也能比MLE基线产生更好的反应。温度参数τ是0.1。为了近似RAML目标中的期望项,在开始时,从训练数据中为每个消息-响应对选择三个附加的激励最高的响应。为了进行公平的比较,我们不会在下面的迭代中采样新的响应。
实验结果
定量评估
为了测量响应的多样性,我们使用10个簇对它们的嵌入进行k-means聚类,并测量惯性。惯性越大,多样性越强。定量评估结果图如下:
定性评估
为了确保多样化的响应与增强之前一样相关,我们要求5个注释器对每个基本模型的100个示例的随机抽样子集与增强后的对应模型进行评估。每个上下文都对应两个响应——一个来自基本模型,另一个来自增强模型。注释器被要求选择最合适的响应,或者如果它们相等,则打成平手。结果如表1所示。 平均来看,在38%到47%的情况下,注释者没有表现出任何偏好,并且在36%到45%的试验中,增强模型优于基本模型。请注意,所有单独的测试都显示注释器更喜欢增强模型而不是基本模型,但有一种情况例外,注释器更经常地选择MMI基本模型而不是增强模型。
平均来看,在38%到47%的情况下,注释者没有表现出任何偏好,并且在36%到45%的试验中,增强模型优于基本模型。请注意,所有单独的测试都显示注释器更喜欢增强模型而不是基本模型,但有一种情况例外,注释器更经常地选择MMI基本模型而不是增强模型。
Double Kill
TILE: Are Red Roses Red? Evaluating Consistency of Question-Answering Models
Contributor : Microsoft Research
Paper: https://www.aclweb.org/anthology/P19-1621
Code: https://github.com/marcotcr/qa_consistency
文章摘要
虽然目前对答题系统的评估将预测单独对待,但我们需要考虑预测之间的关系来衡量真正的理解。如果一个模型在玫瑰是红色的前提下,对“玫瑰是红色的吗?”这个问题的答案回答的是“否”,那么它就应该受到惩罚。那么本文提出了一种方法来自动地从两个QA数据集(VQA和SQuAD)中提取实例的这种含义,然后用它们来评估模型的一致性。认为的评估表明,这些产生的影响是良好的和有效的。一致性评估提供了对现有模型缺陷的洞察能力,并通过含意增强数据进行再训练,提高了对人工和人工生成影响的一致性。
本文主要看
本文建议对QA系统进行评估,以度量模型预测的一致性程度。
1、首先自动生成数据集中现有实例所暗示的新问答对(如下图所示)。
 与原始实例相比,人工评估验证了生成的含义是有效的,并且形式良好,因此可以用于评估和深入了解VQA和班组的模型。
与原始实例相比,人工评估验证了生成的含义是有效的,并且形式良好,因此可以用于评估和深入了解VQA和班组的模型。
2、提出了一个简单的数据扩充过程,其结果是模型几乎与原始数据上的原始模型一样精确,而通过我们的含义和人类生成的含义进行度量时,模型更加一致。
含义生成
让QA数据集中的一个实例用 ( c , q , a ) (c,q,a) (c,q,a)表示,分别表示上下文(图像或段落)、问题和答案。我们将逻辑蕴涵定义为 ( c , q , a ) → ( c , q ′ , a ′ ) (c,q,a)→(c,q^{'},a^{'}) (c,q,a)→(c,q′,a′),即a对q的回答意味着 a ′ a^{'} a′是相同上下文下问题 q ′ q^{'} q′的答案。我们现在提出一个基于规则的系统,它接受 ( q , a ) (q,a) (q,a)并生成 ( q , a ) → ( q ′ , a ′ ) (q,a)→(q^{'},a^{'}) (q,a)→(q′,a′)。
Visual QA
( q , a ) (q,a) (q,a)对在VQA中的通常有正面和负面含义,我们将其编码为三种类型的yes/no含义,如下图所示:

SQuAD
我们使用了[Demszky]的QA2D系统。将 a ( q , a ) a (q,a) a(q,a)转换为陈述性形式d,然后使用d的依赖关系解析提取关于主语(Subj)、直接宾语(Dobj)、形容词修饰词(Amod)或介词短语(Prep)的问题。为了决定引入哪个WH-word,我们使用NER tagger和试探法,例如,如果答案是“in DATE”或“in LOC”,那么WH-word分别是“when”和“where”
一致性评估
我们希望生成的含义满足以下条件:(1)问题格式良好,(2)答案正确,(3)隐含是有效的,即如果生成一个隐含 ( q , a ) → ( q ′ , a ′ ) (q,a)→(q^{'},a^{'}) (q,a)→(q′,a′),那么a到q的答案实际上意味着 a ′ a^{'} a′就是 q ′ q^{'} q′的答案。如果这些得到满足,我们可以评估的一致性预测在这些数据集的大部分(67.3%的VQA和73.2%的SQuAD)通过 ( q , a ) (q,a) (q,a)实例预测正确的模型,产生影响 ( q , a ) → ( q ′ , a ′ ) (q,a)→(q^{'},a^{'}) (q,a)→(q′,a′)和测量的频率模型预测正确生成的问题。
实验结果
含义质量评估
 我们要求工作人员评估给定问题和上下文的答案的正确性()。上图中的结果表明,所有标准的平均得分在原始实例和生成的暗示之间几乎没有区别,这表明暗示问题的形式很好,答案是正确的。
我们要求工作人员评估给定问题和上下文的答案的正确性()。上图中的结果表明,所有标准的平均得分在原始实例和生成的暗示之间几乎没有区别,这表明暗示问题的形式很好,答案是正确的。
含义有效性评估
为了检查(q,a)是否真的意味着 ( q ′ , a ′ ) (q^{'},a^{'}) (q′,a′),我们在没有上下文的情况下向工作人员显示(q,a),并让他们回答隐含问题 q ′ q^{'} q′,假设原始答案a是正确的。如果 ( q , a ) → ( q ′ , a ′ ) (q,a)→(q^{'},a^{'}) (q,a)→(q′,a′),即使没有图像或段落,工人也应该能够正确地回答 q ′ q^{'} q′。如下图所示:

评估QA模型的一致性
在得出我们生成的含义是高质量的并且通常是有效的结论之后,我们继续使用它们来评估模型的逻辑一致性。如下图所示: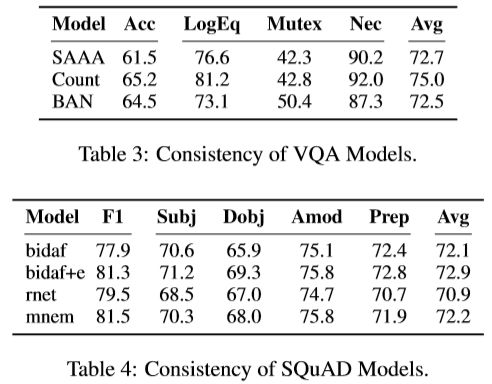
ACED
Attention
更多自然语言处理相关知识,还请关注AINLPer公众号,极品干货即刻送达。