mysql 8 中的hash join
原文地址 : https://mysqlserverteam.com/hash-join-in-mysql-8/
在mysql 8 前,join 主要是使用的 nested loop 算法(或是该算法的改良版本)。mysql 8 推出了 hash join 算法,本文主要说明mysql 中的hash join 算法。
什么是hash join
所谓的hash join 定义:使用hash 表来进行多个表中行数据的匹配操作的join 实现。
通常情况下,hash join 效率比nested loop join 快(当join 中的某一张表数据量小,可以完全缓存到内存中时,hash join 效率是最好的)。
Hash Join 处理过程
下面我们使用一个例子来进行说明。
SELECT
given_name, country_name
FROM
persons JOIN countries ON persons.country_id = countries.country_id;
hash join 通常可分为两部分:hash 表构建过程 和 基于hash 表的探测比较部分。
hash 表构建过程
在构建hash 表时,mysql 将join 中的某一张数据表的数据 缓存到 此hash 表中。通常情况下,选择 数据量较小的表 来构建hash 表(则需要缓存的数据量相对较小)。
hash 表使用 join 使用的 join 中的此表使用的条件作为 hash key.
例如上面例子中, country 表作为一个 基础元素表,数据量相对较小,则选择缓存 country表数据。另外,join 条件为 persons.country_id = countries.country_id ,则使用 countries表的country_id 字段值作为 hash key。
当country 表中的所有相关的数据行都缓存起来是,构建过程结束。
问题1:
是会缓存 country 表的所有数据列么,还是只缓存 country 的相关列?

探测(probe)过程
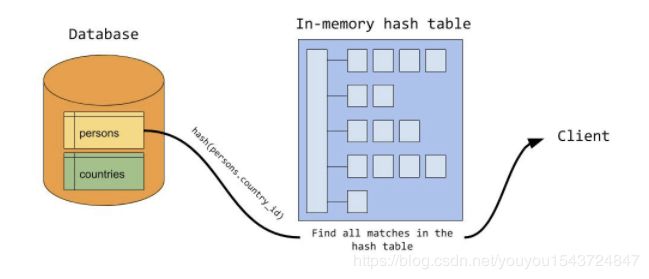
在探测阶段, 数据库 从需要探测的数据表读取数据行(这个例子中是 person 表)。
对于读取到的每一行数据, mysql 会使用 行中的 country_id 值 查询hash 表,每匹配到一行数据,则找到一个 合理的 join 结果数据。
总体来说,mysql 只需要对每一张表,只扫描一次。对于探测表扫描时,每扫描到一条数据,然后使用常量时间基于hash 表来进行 数据结果匹配。
数据表拆分
当 某一张数据表( 作为hash 表源数据的表)可以缓存到内存中时,hash join 的效率很快。
那 hash join 可使用的hash 缓存有多大呢?
这是 通过 系统 变量 join_buffer_size 控制的。该变量可以随时修改,立即生效。
那么如果作为join 的数据表数据量 都很大,无法完成缓存,那应该怎么处理呢?
如果在构建hash 表的过程中,如果达到 join_buffer_size 值,则 mysql 将剩下的数据写入到磁盘中的文件块中。
在写文件块的时候,mysql 会尽量 控制每个块的大小,使得后续这个块可以刚好加载到 join_buffer_size 大小的hash 缓存中。(但是 mysql 也有一个最大的限制,对于每个 join ,最大128 个 磁盘数据块)。
当数据写入到磁盘文件块中后,那我怎么知道哪一行数据被写入到那个文件块了呢?
这里有一个新的hash 函数,用于定位数据块。
那为什么会使用一个新的hash 函数呢?这个原因后续会说。

在数据探测阶段,mysql 进行数据匹配的过程和没有写 磁盘块文件的过程是一样的(就像所有的数据都写入了内存hash 表一样):在探测表中,每扫描到一行数据,就到 内存中的hash 表中进行 匹配,找到符合条件的 数据。
但是不同的是,如果进行了磁盘块写的操作,则在 探测表中每扫描到一行数据A , 在 hash 表进行匹配操作后, 还需要写入到磁盘文件块中(因为对于数据行A ,也有可能匹配到 之前写入到磁盘块中的数据)。
需要注意的时,将探测表写入到 磁盘文件块时,将数据行定位到 特定数据块的 hash 函数 和 将hash 表源表数据写入到数据块的 算法是一致的。 所以 匹配的数据 都会写入到 同一对 数据块中。
例如,country 表数据量很大,只能将 以A - D 开头的国家写入到 内存 hash 表中。另外,将 剩下的国家数据 写入到磁盘文件块中。
如果国家 HXX 写入到 hash 表块 HA 中。在扫描Person 表时,如果某一个人员的国家也是HXX ,则同理,会将 该调数据写入到 探测表HXX 块号中。

当探测阶段完成后,会继续处理 磁盘文件块中的数据。
首先,会处理 块号相同的 hash 输入块 和 探测文件表,过程 和 之前描述的 hash ,probe 过程相同。直到处理完所有的文件块对。

在这里,有两个地方需要说明:
- 在当初写 磁盘文件块时,就需要注意 每一个文件块大小不要超过 join buffer size, 所有,某一个 hash 磁盘文件块可以正好加载到 hash join 表中;
- 为什么使用不同的hash 算法来将不同的数据行分配到不同的 磁盘数据块中? 如果算法相同,则将一个块的数据加载到 join hash 表中,则大量的数据都会在hash 表的同一行,大量的冲突数据。
怎么使用hash join
默认情况下,hash join 是开启的。
可以在explain 中加入 “FORMAT = tree” 查看某一个sql
mysql> EXPLAIN FORMAT=tree
-> SELECT
-> given_name, country_name
-> FROM
-> persons JOIN countries ON persons.country_id = countries.country_id;
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| EXPLAIN |
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| -> Inner hash join (countries.country_id = persons.country_id) (cost=0.70 rows=1)
-> Table scan on countries (cost=0.35 rows=1)
-> Hash
-> Table scan on persons (cost=0.35 rows=1)
|
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.01 sec)
通常情况下,如果join 使用了 等值条件 (一个或多个)、并且,没有 索引可用,就会使用hash join 。
(也就是说,如果存在索引,则mysql 还是会优先使用 所有查询)
我们也可以使用通过命令来关闭 hash join :
mysql> SET optimizer_switch="hash_join=off";
Query OK, 0 rows affected (0.00 sec)
mysql> EXPLAIN FORMAT=tree
-> SELECT
-> given_name, country_name
-> FROM
-> persons JOIN countries ON persons.country_id = countries.country_id;
+----------------------------------------+
| EXPLAIN |
+----------------------------------------+
|
|
+----------------------------------------+
1 row in set (0.00 sec)