Uboot中start.S源码的指令级的详尽解析
第 3 章 相关知识点详解
目录
- 3.1. 如何查看C或汇编的源代码所对应的真正的汇编代码
- 3.2. uboot初始化中,为何要设置CPU为SVC模式而不是设置为其他模式
- 3.3. 什么是watchdog + 为何在要系统初始化的时候关闭watchdog
-
- 3.3.1. 什么是watchdog
- 3.3.2. 为何在要系统初始化的时候关闭watchdog
- 3.4. 为何ARM7中PC=PC+8
-
- 3.4.1. 为何ARM9和ARM7一样,也是PC=PC+8
- 3.5. AMR寄存器的别名 + APCS
-
- 3.5.1. ARM中的寄存器的别名
- 3.5.2. 什么是APCS
- 3.6. 为何C语言(的函数调用)需要堆栈,而汇编语言却不需要堆栈
-
- 3.6.1. 保存现场/上下文
-
- 3.6.1.1. 什么叫做上下文context
- 3.6.2. 传递参数
- 3.6.3. 举例分析C语言函数调用是如何使用堆栈的
- 3.7. 关于为何不直接用mov指令,而非要用adr伪指令
- 3.8. mov指令的操作数的取值范围到底是多少
- 3.9. 汇编学习总结记录
-
- 3.9.1. 汇编中的标号=C中的标号
- 3.9.2. 汇编中的跳转指令=C中的goto
- 3.9.3. 汇编中的.globl=C语言中的extern
- 3.9.4. 汇编中用bl指令和mov pc,lr来实现子函数调用和返回
- 3.9.5. 汇编中的对应位置有存储值的标号 = C语言中的指针变量
- 3.9.6. 汇编中的ldr+标号,来实现C中的函数调用
- 3.9.7. 汇编中设置某个寄存器的值或给某个地址赋值
摘要
3.1. 如何查看C或汇编的源代码所对应的真正的汇编代码
首先解释一下,由于汇编代码中会存在一些伪指令等内容,所以,写出来的汇编代码,并不一定是真正可以执行的代码,这些类似于伪指令的汇编代码,经过汇编器,转换或翻译成真正的可以执行的汇编指令。所以,上面才会有将“汇编源代码”转换为“真正的汇编代码”这一说。
然后,此处对于有些人不是很熟悉的,如何查看源代码真正对应的汇编代码。
此处,对于汇编代码,有两种:
- 一种是只是进过编译阶段,生成了对应的汇编代码
- 另外一种是,编译后的汇编代码,经过链接器链接后,对应的汇编代码。
总的来说,两者区别很小,后者主要是更新了外部函数的地址等等,对于汇编代码本身,至少对于我们一般所去查看源代码所对应的汇编来说,两者可以视为没区别。
在查看源代码所对应的真正的汇编代码之前,先要做一些相关准备工作:
- 编译uboot
在Linux下,一般编译uboot的方法是:
-
make distclean
去清除之前配置,编译等生成的一些文件。
-
make EmbedSky_config
去配置我们的uboot
-
make
去执行编译
-
- 查看源码所对应的汇编代码
对于我们此处的uboot的start.S来说:
- 对于编译所生成的汇编的查看方式是
用交叉编译器的dump工具去将汇编代码都导出来:
arm-linux-objdump –d cpu/arm920t/start.o > uboot_start.o_dump_result.txt
这样就把start.o中的汇编代码导出到uboot_start.o_dump_result.txt中了。
然后查看uboot_start.o_dump_result.txt,即可找到对应的汇编代码。
举例来说,对于start.S中的汇编代码:
/* Set up the stack */ stack_setup: ldr r0, _TEXT_BASE /* upper 128 KiB: relocated uboot */ sub r0, r0, #CFG_MALLOC_LEN /* malloc area */ sub r0, r0, #CFG_GBL_DATA_SIZE /* bdinfo */ #ifdef CONFIG_USE_IRQ sub r0, r0, #(CONFIG_STACKSIZE_IRQ+CONFIG_STACKSIZE_FIQ) #endif sub sp, r0, #12 /* leave 3 words for abort-stack */ bl clock_init去uboot_start.o_dump_result.txt中,搜索stack_setup,即可找到对应部分的汇编代码:
00000090
: 90: e51f0058 ldr r0, [pc, #-88] ; 40 <_TEXT_BASE> 94: e2400701 sub r0, r0, #262144 ; 0x40000 98: e2400080 sub r0, r0, #128 ; 0x80 9c: e240d00c sub sp, r0, #12 ; 0xc a0: ebfffffe bl 0 - 对于链接所生成的汇编的查看方式是
和上面方法一样,即:
arm-linux-objdump –d u-boot > whole_uboot_dump_result.txt
然后打开该txt,找到stack_setup部分的代码:
33d00090
: 33d00090: e51f0058 ldr r0, [pc, #-88] ; 33d00040 <_TEXT_BASE> 33d00094: e2400701 sub r0, r0, #262144 ; 0x40000 33d00098: e2400080 sub r0, r0, #128 ; 0x80 33d0009c: e240d00c sub sp, r0, #12 ; 0xc 33d000a0: eb000242 bl 33d009b0 两者不一样地方在于,我们uboot设置了text_base,即代码段的基地址,上面编译后的汇编代码,经过链接后,更新了对应的基地址,所以看起来,所以代码对应的地址,都变了,但是具体地址中的汇编代码,除了个别调用函数的地址和跳转到某个标号的地址之外,其他都还是一样的。
- 对于编译所生成的汇编的查看方式是
对于C语言的源码,也是同样的方法,用对应的dump工具,去从该C语言的.o文件中,dump出来汇编代码。
![[注意]](http://img.e-com-net.com/image/info8/7e6b0036d7374de09c9d94d8b5c7a31a.jpg) |
注意 |
|---|---|
| 【总结】 不论是C语言还是汇编语言的源文件,想要查看其对应的生成的汇编代码的话,方法很简单,就是用dump工具,从对应的.o目标文件中,导出对应的汇编代码,即可。 |
3.2. uboot初始化中,为何要设置CPU为SVC模式而不是设置为其他模式
在看Uboot的start.S文件时候,发现其最开始初始化系统,做的第一件事情,就是将CPU设置为SVC模式,但是S3C2440的CPU的core是ARM920T,其有7种模式,为何非要设置为SVC模式,而不是设置为其他模式呢?对此,经过一些求证,得出如下原因:
首先,先要了解ARM的CPU的7种模式是哪些:
http://www.docin.com/p-73665362.html
表 3.1. ARM中CPU的模式
| 处理器模式 | 说明 | 备注 |
|---|---|---|
| 用户(usr) | 正常程序工作模式 | 此模式下程序不能够访问一些受操作系统保护的系统资源,应用程序也不能直接进行处理器模式的切换。 |
| 系统(sys) | 用于支持操作系统的特权任务等 | 与用户模式类似,但具有可以直接切换到其它模式等特权 |
| 快中断(fiq) | 支持高速数据传输及通道处理 | FIQ异常响应时进入此模式 |
| 中断(irq) | 用于通用中断处理 | IRQ异常响应时进入此模式 |
| 管理(svc) | 操作系统保护代码 | 系统复位和软件中断响应时进入此模式 |
| 中止(abt) | 用于支持虚拟内存和/或存储器保护 | 在ARM7TDMI没有大用处 |
| 未定义(und) | 支持硬件协处理器的软件仿真 | 未定义指令异常响应时进入此模式 |
另外,7种模式中,除用户usr模式外,其它模式均为特权模式。
对于为何此处是svc模式,而不是其他某种格式,其原因,可以从两方面来看:
-
我们先简单的来分析一下那7种模式:
- 中止abt和未定义und模式
首先可以排除的是,中止abt和未定义und模式,那都是不太正常的模式,此处程序是正常运行的,所以不应该设置CPU为其中任何一种模式,所以可以排除。
- 快中断fiq和中断irq模式
其次,对于快中断fiq和中断irq来说,此处uboot初始化的时候,也还没啥中断要处理和能够处理,而且即使是注册了终端服务程序后,能够处理中断,那么这两种模式,也是自动切换过去的,所以,此处也不应该设置为其中任何一种模式。
- 用户usr模式
虽然从理论上来说,可以设置CPU为用户usr模式,但是由于此模式无法直接访问很多的硬件资源,而uboot初始化,就必须要去访问这类资源,所以此处可以排除,不能设置为用户usr模式。
- 系统sys模式 vs 管理svc模式
首先,sys模式和usr模式相比,所用的寄存器组,都是一样的,但是增加了一些访问一些在usr模式下不能访问的资源。
而svc模式本身就属于特权模式,本身就可以访问那些受控资源,而且,比sys模式还多了些自己模式下的影子寄存器,所以,相对sys模式来说,可以访问资源的能力相同,但是拥有更多的硬件资源。
所以,从理论上来说,虽然可以设置为sys和svc模式的任一种,但是从uboot方面考虑,其要做的事情是初始化系统相关硬件资源,需要获取尽量多的权限,以方便操作硬件,初始化硬件。
从uboot的目的是初始化硬件的角度来说,设置为svc模式,更有利于其工作。
因此,此处将CPU设置为SVC模式。
- 中止abt和未定义und模式
-
uboot作为一个bootloader来说,最终目的是为了启动Linux的kernel,在做好准备工作(即初始化硬件,准备好kernel和rootfs等)跳转到kernel之前,本身就要满足一些条件,其中一个条件,就是要求CPU处于SVC模式的。
所以,uboot在最初的初始化阶段,就将CPU设置为SVC模式,也是最合适的。
![[提示]](http://img.e-com-net.com/image/info8/1c69aa3857084ae7b575d75973219cee.jpg)
提示 关于满足哪些条件,详情请参考
ARM Linux Kernel Boot Requirements
或者Linux内核文档:
kernel_source_root\documentation\arm\booting中也是同样的解释:
The CPU must be in SVC mode
所以,uboot在最初的初始化阶段,就将CPU设置为SVC模式,也是最合适的。
综上所述,uboot在初始化阶段,就应该将CPU设置为SVC模式。
3.3. 什么是watchdog + 为何在要系统初始化的时候关闭watchdog
关于Uboot初始化阶段,在start.S中,为何要去关闭watchdog,下面解释具体的原因:
3.3.1. 什么是watchdog
参考嵌入式系统之WATCHDOG(看门狗)概述
简要摘录如下:
watchdog一般是一个硬件模块,其作用是,在嵌入式操作系统中,很多应用情况是系统长期运行且无人看守,所以难免或者怕万一出现系统死机,那就杯具了,这时,watchdog就会自动帮你重启系统。
那么其是如何实现此功能的呢?那么就要简单解释一下其实现原理了。
watchdog硬件的逻辑就是,其硬件上有个记录超时功能,然后要求用户需要每隔一段时间(此时间可以根据自己需求而配置)去对其进行一定操作,比如往里面写一些固定的值,俗称“喂狗”,那么我发现超时了,即过了这么长时间你还不给偶喂食,那么偶就认为你系统是死机了,出问题了,偶就帮你重启系统。
说白了就是弄个看家狗dog,你要定期给其喂食,如果超时不喂食,那么狗就认为你,他的主人,你的系统,死机了,就帮你reset重启系统。
3.3.2. 为何在要系统初始化的时候关闭watchdog
了解了watchdog的原理后,此问题就很容易理解了。
如果不禁用watchdog,那么就要单独写程序去定期“喂狗”,那多麻烦,多无聊啊。
毕竟咱此处只是去用uboot初始化必要的硬件资源和系统资源而已,完全用不到这个watchdog的机制。需要用到,那也是你linux内核跑起来了,是你系统关心的事情,和我uboot没啥关系的,所以肯定此处要去关闭watchdog(的reset功能)了。
3.4. 为何ARM7中PC=PC+8
此处解释为何ARM7中,CPU地址,即PC,为何有PC=PC+8这一说法:
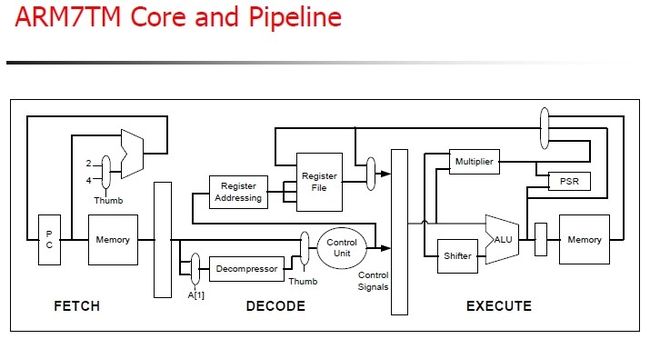
众所周知,AMR7,是三级流水线,其细节见图:
图 3.1. AMR7三级流水线
 |
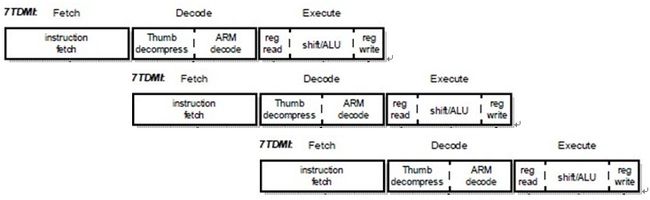
首先,对于ARM7对应的流水线的执行情况,如下面这个图所示:
图 3.2. ARM7三级流水线状态
 |
然后对于三级流水线举例如下:
图 3.3. ARM7三级流水线示例
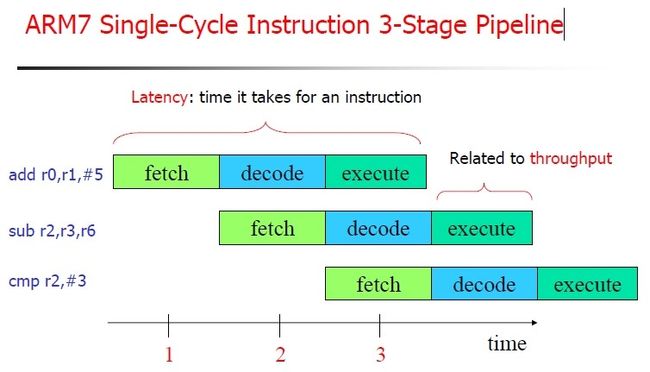 |
从上图,其实很容易看出,第一条指令:
add r0, r1,$5
执行的时候,此时PC已经指向第三条指令:
cmp r2,#3
的地址了,所以,是PC=PC+8.
3.4.1. 为何ARM9和ARM7一样,也是PC=PC+8
ARM7的三条流水线,PC=PC+8,很好理解,但是AMR9中,是五级流水线,为何还是PC=PC+8,而不是
PC
=PC+(5-1)*4
=PC + 16,
呢?
下面就需要好好解释一番了。
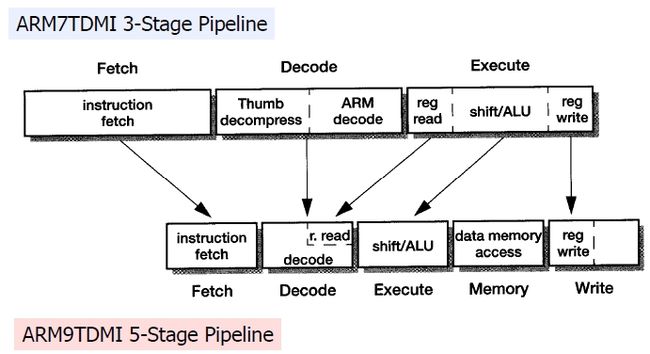
具体解释之前,先贴上ARM7和ARM9的流水线的区别和联系:
图 3.4. ARM7三级流水线 vs ARM9五级流水线
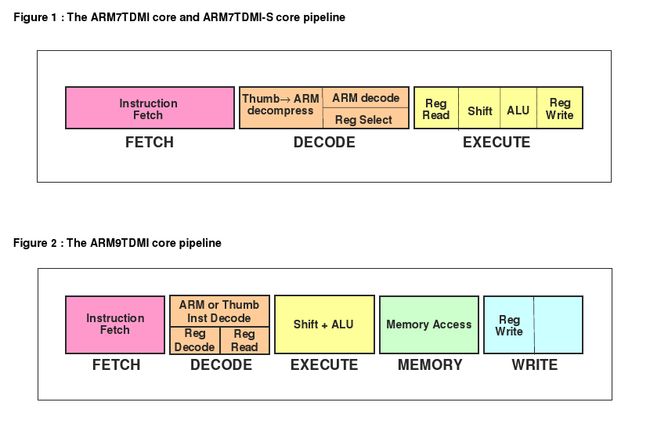 |
图 3.5. ARM7三级流水线到ARM9五级流水线的映射
 |
下面开始对为何ARM9也是PC=PC+8进行解释。
先列出ARM9的五级流水线的示例:
图 3.6. ARM9的五级流水线示例
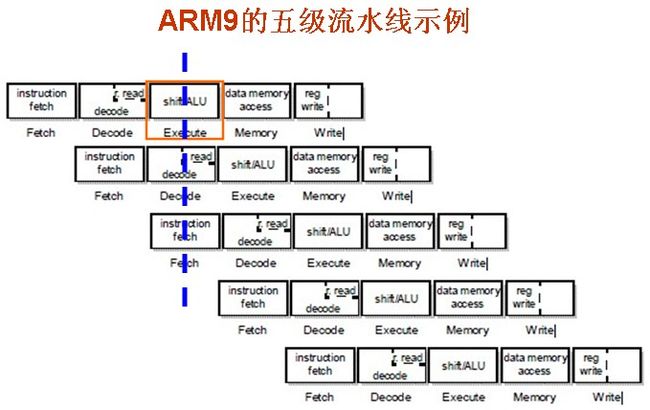 |
举例分析为何PC=PC+8
然后我们以下面uboot中的start.S的最开始的汇编代码为例来进行解释:
00000000 <_start>: 0: ea000014 b 584: e59ff014 ldr pc, [pc, #20] ; 20 <_undefined_instruction> 8: e59ff014 ldr pc, [pc, #20] ; 24 <_software_interrupt> c: e59ff014 ldr pc, [pc, #20] ; 28 <_prefetch_abort> 10: e59ff014 ldr pc, [pc, #20] ; 2c <_data_abort> 14: e59ff014 ldr pc, [pc, #20] ; 30 <_not_used> 18: e59ff014 ldr pc, [pc, #20] ; 34 <_irq> 1c: e59ff014 ldr pc, [pc, #20] ; 38 <_fiq> 00000020 <_undefined_instruction>: 20: 00000120 .word 0x00000120
下面对每一个指令周期,CPU做了哪些事情,分别详细进行阐述:
在看下面具体解释之前,有一句话要牢记,那就是:
PC不是指向你正在运行的指令,而是
PC始终指向你要取的指令的地址
认识清楚了这个前提,后面的举例讲解,就容易懂了。
- 指令周期Cycle1
- 取指
PC总是指向将要读取的指令的地址(即我们常说的,指向下一条指令的地址),而当前PC=4,
所以去取物理地址为4对对应的指令
ldr pc, [pc, #20]
其对应二进制代码为e59ff014。
此处取指完之后,自动更新PC的值,即PC=PC+4(单个指令占4字节,所以加4)=4+4=8
- 取指
- 指令周期Cycle2
- 译指
翻译指令e59ff014
- 同时再去取指
PC总是指向将要读取的指令的地址(即我们常说的,指向下一条指令的地址),而当前PC=8,
所以去物理地址为8所对应的指令“ldr pc, [pc, #20]” 其对应二进制代码为e59ff014。
此处取指完之后,自动更新PC的值,即PC=PC+4=8+4=12=0xc
- 译指
- 指令周期Cycle3
- 执行(指令)
执行“e59ff014”,即
ldr pc, [pc, #20]
所对表达的含义,即PC
= PC + 20
= 12 + 20
= 32
= 0x20
此处,只是计算出待会要赋值给PC的值是0x20,这个0x20还只是放在执行单元中内部的缓冲中。
- 译指
翻译e59ff014
- 取指
此步骤由于是和上面(1)中的执行同步做的,所以,未受到影响,继续取指,而取指的那一时刻,PC为上一Cycle更新后的值,即PC=0xc,所以是去取物理地址为0xc所对应的指令
ldr pc, [pc, #20]
对应二进制为e59ff014
- 执行(指令)
其实,分析到这里,大家就可以看出:
在Cycle3的时候,PC的值,刚好已经在Cycle1和Cycle2,分别加了4,所以Cycle3的时候,PC=PC+8,而同样道理,对于任何一条指令的,都是在Cycle3,指令的Execute执行阶段,如果用到PC的值,那么PC那一时刻,就是PC=PC+8。
所以,此处虽然是五级流水线,但是却不是PC=PC+16,而是PC=PC+8。
进一步地,我们发现,其实PC=PC+N的N,是和指令的执行阶段所处于流水线的深度有关,即此处指令的执行Execute阶段,是五级流水线中的第三个,而这个第三阶段的Execute和指令的第一个阶段的Fetch取指,相差的值是 3 -1 =2,即两个CPU的Cycle,而每个Cycle都会导致PC=+PC+4,所以,指令到了Execute阶段,才会发现,此时PC已经变成PC=PC+8了。
回过头来反观ARM7的三级流水线,也是同样的道理,指令的Execute执行阶段,是处于指令的第三个阶段,同理,在指令计算数据的时候,如果用到PC,就会发现此时PC=PC+8。
同理,假如ARM9的五级流水线,把指令的Execute执行阶段,设计在了第四个阶段,那么就是PC=PC+(第4阶段-1)*4个字节 = PC= PC+12了。
用图来说明PC=PC+8个过程
对于上面的文字的分析过程,可能看起来不是太容易理解,所以,下面这里通过图表来表示具体的流程,就更容易看懂了。其中,下图,是以ARM9的五级流水线的内部架构图为基础,而编辑的出来用于说明为何ARM9的五级流水线,也是PC=PC+8:
图 3.7. ARM9的五级流水线中为何PC=PC+8
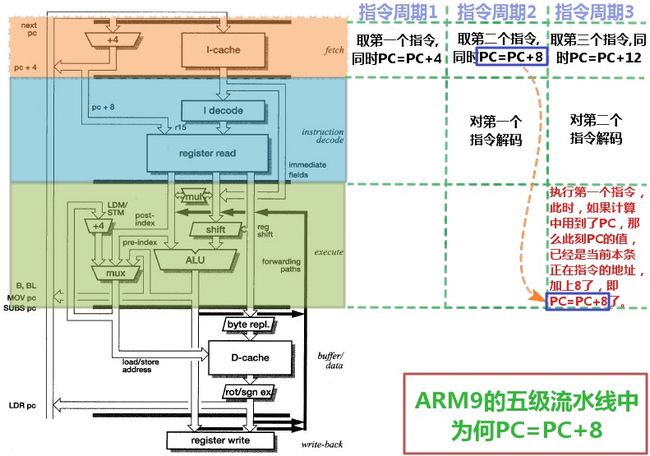 |
对于上图中的,第一个指令在执行的时候,是使用到了PC的值,其实,我们可以看到,
对于指令在执行中,不论是否用到PC的值,PC都会按照既定逻辑,没一个cycle,自动增加4的,套用《非诚勿扰2》中的经典对白,即为:
你(指令执行的时候)用,
或者不用,
PC就在那里,
自动增4
所以,经过两个cycle的增4,就到了指令执行的时候,此时PC已经增加了8了,即使你指令执行的时候,没有用到PC的值,其也还是已经加了8了。而一般来说,大多数的指令,肯定也都是没有用到PC的,但是其实任何指令执行的那一时刻,也已经是PC=PC+8,而多数指令没有用到,所以很多人没有注意到这点罢了。
|
PC(execute)=PC(fetch)+ 8 |
|---|---|
| 对于PC=PC+8中的两个PC,其实含义不完全一样.其更准确的表达,应该是这样: PC(execute)=PC(fetch)+ 8 其中: PC(fetch):当前正在执行的指令,就是之前取该指令时候的PC的值 PC(execute):当前指令执行的计算中,如果用到PC,则此时PC的值。 |
|
不同阶段的PC值的关系 |
|---|---|
| 对应地,在ARM7的三级流水线(取指,译指,执行)和ARM9的五级流水线(取指,译指,执行,存储,写回)中,可以这么说: PC, 总是指向当前正在被取指的指令的地址, PC-4,总是指向当前正在被译指的指令的地址, PC-8,总是指向当前的那条指令,即我们一般说的,正在被执行的指令的地址。 |
【总结】
ARM7的三级流水线,PC=PC+8,
ARM9的五级流水线,也是PC=PC+8,
根本的原因是,两者的流水线设计中,指令的Execute执行阶段,都是处于流水线的第三级。
所以使得PC=PC+8。
类似地,可以推导出:
假设,Execute阶段处于流水线中的第E阶段,每条指令是T个字节,那么
PC
= PC + N*T
= PC + (E - 1) * T
此处ARM7和ARM9:
Execute阶段都是第3阶段 ⇒ E=3
每条指令是4个字节 ⇒ T=4
所以:
PC
=PC + N* T
=PC + (3 -1 ) * 4
= PC + 8
|
关于直接改变PC的值,会导致流水线清空的解释 |
|---|---|
| 把PC的值直接赋值为0x20。而PC值更改,直接导致流水线的清空,即导致下一个cycle中的,对应的流水线中的其他几个步骤,包括接下来的同一个Cycle中的取指的工作被取消。在PC跳转到0x20的位置之后,流水线重新计算,重新一步步地按照流水线的逻辑,去一点点执行。当然要保证当前指令的执行完成,即执行之后,还有两个cycle,分别做的Memory和Write,会继续执行完成。 |
3.5. AMR寄存器的别名 + APCS
此处简单介绍一下,ARM寄存器的别名,以及什么是APCS。
用文字解释之前,先看这个版本的解释,显得很直观,很好理解:
图 3.8. ARM Application Procedure Call Standard (AAPCS)
 |
3.5.1. ARM中的寄存器的别名
默认的情况下,这些寄存器只是叫做r0,r1,...,r14等,而APCS 对其起了不同的别名。
使用汇编器预处理器的功能,你可以定义 R0 等名字,但在你修改其他人写的代码的时候,最好还是学习使用 APCS 名字。
一般编程过程中,最好按照其约定,使用对应的名字,这样使得程序可读性更好。
关于不同寄存器所对应的名字,见下表:
表 3.2. ARM寄存器的别名
| 寄存器名字 | ||
|---|---|---|
| Reg# | APCS | 意义 |
| R0 | a1 | 工作寄存器 |
| R1 | a2 | " |
| R2 | a3 | " |
| R3 | a4 | " |
| R4 | v1 | 必须保护 |
| R5 | v2 | " |
| R6 | v3 | " |
| R7 | v4 | " |
| R8 | v5 | " |
| R9 | v6 | " |
| R10 | sl | 栈限制 |
| R11 | fp | 桢指针 |
| R12 | ip | 内部过程调用寄存器 |
| R13 | sp | 栈指针 |
| R14 | lr | 连接寄存器 |
| R15 | pc | 程序计数器 |
更加详细一点,见下:
Predeclared register names
The following register names are predeclared:
- r0-r15 and R0-R15
- a1-a4 (argument, result, or scratch registers, synonyms for r0 to r3)
- v1-v8 (variable registers, r4 to r11)
- sb and SB (static base, r9)
- ip and IP (intra-procedure-call scratch register, r12)
- sp and SP (stack pointer, r13)
- lr and LR (link register, r14)
- pc and PC (program counter, r15).
Predeclared extension register names
The following extension register names are predeclared:
- d0-d31 and D0-D31(VFP double-precision registers)
- s0-s31 and S0-S31(VFP single-precision registers)
Predeclared coprocessor names
The following coprocessor names and coprocessor register names are predeclared:
- p0-p15 (coprocessors 0-15)
- c0-c15 (coprocessor registers 0-15).
3.5.2. 什么是APCS
APCS,ARM 过程调用标准(ARM Procedure Call Standard),提供了紧凑的编写例程的一种机制,定义的例程可以与其他例程交织在一起。最显著的一点是对这些例程来自哪里没有明确的限制。它们可以编译自 C、 Pascal、也可以是用汇编语言写成的。
APCS 定义了:
- 对寄存器使用的限制。
- 使用栈的惯例。
- 在函数调用之间传递/返回参数。
- 可以被"回溯"的基于栈的结构的格式,用来提供从失败点到程序入口的函数(和给予的参数)的列表。
3.6. 为何C语言(的函数调用)需要堆栈,而汇编语言却不需要堆栈
之前看了很多关于uboot的分析,其中就有说要为C语言的运行,准备好堆栈。
而自己在Uboot的start.S汇编代码中,关于系统初始化,也看到有堆栈指针初始化这个动作。但是,从来只是看到有人说系统初始化要初始化堆栈,即正确给堆栈指针sp赋值,但是却从来没有看到有人解释,为何要初始化堆栈。所以,接下来的内容,就是经过一定的探究,试图来解释一下,为何要初始化堆栈,即:
为何C语言的函数调用要用到堆栈,而汇编却不需要初始化堆栈。
要明白这个问题,首先要了解堆栈的作用。
关于堆栈的作用,要详细讲解的话,要很长的篇幅,所以此处只是做简略介绍。
总的来说,堆栈的作用就是:保存现场/上下文,传递参数。
3.6.1. 保存现场/上下文
现场,意思就相当于案发现场,总有一些现场的情况,要记录下来的,否则被别人破坏掉之后,你就无法恢复现场了。而此处说的现场,就是指CPU运行的时候,用到了一些寄存器,比如r0,r1等等,对于这些寄存器的值,如果你不保存而直接跳转到子函数中去执行,那么很可能就被其破坏了,因为其函数执行也要用到这些寄存器。
因此,在函数调用之前,应该将这些寄存器等现场,暂时保持起来,等调用函数执行完毕返回后,再恢复现场。这样CPU就可以正确的继续执行了。
在计算机中,你常可以看到上下文这个词,对应的英文是context。那么:
3.6.1.1. 什么叫做上下文context
保存现场,也叫保存上下文。
上下文,英文叫做context,就是上面的文章,和下面的文章,即与你此刻,当前CPU运行有关系的内容,即那些你用到寄存器。所以,和上面的现场,是一个意思。
保存寄存器的值,一般用的是push指令,将对应的某些寄存器的值,一个个放到堆栈中,把对应的值压入到堆栈里面,即所谓的压栈。
然后待被调用的子函数执行完毕的时候,再调用pop,把堆栈中的一个个的值,赋值给对应的那些你刚开始压栈时用到的寄存器,把对应的值从堆栈中弹出去,即所谓的出栈。
其中保存的寄存器中,也包括lr的值(因为用bl指令进行跳转的话,那么之前的pc的值是存在lr中的),然后在子程序执行完毕的时候,再把堆栈中的lr的值pop出来,赋值给pc,这样就实现了子函数的正确的返回。
3.6.2. 传递参数
C语言进行函数调用的时候,常常会传递给被调用的函数一些参数,对于这些C语言级别的参数,被编译器翻译成汇编语言的时候,就要找个地方存放一下,并且让被调用的函数能够访问,否则就没发实现传递参数了。对于找个地方放一下,分两种情况。
一种情况是,本身传递的参数就很少,就可以通过寄存器传送参数。
因为在前面的保存现场的动作中,已经保存好了对应的寄存器的值,那么此时,这些寄存器就是空闲的,可以供我们使用的了,那就可以放参数,而参数少的情况下,就足够存放参数了,比如参数有2个,那么就用r0和r1存放即可。(关于参数1和参数2,具体哪个放在r0,哪个放在r1,就是和APCS中的“在函数调用之间传递/返回参数”相关了,APCS中会有详细的约定。感兴趣的自己去研究。)
但是如果参数太多,寄存器不够用,那么就得把多余的参数堆栈中了。
即,可以用堆栈来传递所有的或寄存器放不下的那些多余的参数。
3.6.3. 举例分析C语言函数调用是如何使用堆栈的
对于上面的解释的堆栈的作用显得有些抽象,此处再用例子来简单说明一下,就容易明白了:
用:
arm-inux-objdump –d u-boot > dump_u-boot.txt
可以得到dump_u-boot.txt文件。该文件就是中,包含了u-boot中的程序的可执行的汇编代码,其中我们可以看到C语言的函数的源代码,到底对应着那些汇编代码。
下面贴出两个函数的汇编代码,
一个是clock_init,另一个是与clock_init在同一C源文件中的,另外一个函数CopyCode2Ram
33d0091c: 33d0091c: e92d4070 push {r4, r5, r6, lr} 33d00920: e1a06000 mov r6, r0 33d00924: e1a05001 mov r5, r1 33d00928: e1a04002 mov r4, r2 33d0092c: ebffffef bl 33d008f0 ... ... 33d00984: ebffff14 bl 33d005dc ... ... 33d009a8: e3a00000 mov r0, #0 ; 0x0 33d009ac: e8bd8070 pop {r4, r5, r6, pc} 33d009b0 : 33d009b0: e3a02313 mov r2, #1275068416 ; 0x4c000000 33d009b4: e3a03005 mov r3, #5 ; 0x5 33d009b8: e5823014 str r3, [r2, #20] ... ... 33d009f8: e1a0f00e mov pc, lr
|
|
此处就是我们所期望的,用push指令,保存了r4,r5,r以及lr。 用push去保存r4,r5,r6,那是因为所谓的保存现场,以后后续函数返回时候再恢复现场, |
|
|
上述用push去保存lr,那是因为函数CopyCode2Ram里面在此处调用了bBootFrmNORFlash 以及也调用了nand_read_ll: 33d00984: ebffff14 bl 33d005dc 也用到了bl指令,会改变我们最开始进入clock_init时候的lr的值,所以我们要用push也暂时保存起来。 |
|
|
把0赋值给r0寄存器,这个就是我们所谓返回值的传递,是通过r0寄存器的。 此处的返回值是0,也对应着C语言的源码中的“return 0”. |
|
|
把之前push的值,给pop出来,还给对应的寄存器,其中最后一个是将开始push的lr的值,pop出来给赋给PC,因为实现了函数的返回。 |
|
|
可以看到此处是该函数第一行 其中没有我们所期望的push指令,没有去将一些寄存器的值放到堆栈中。这是因为,我们clock_init这部分的内容,所用到的r2,r3等寄存器,和前面调用clock_init之前所用到的寄存器r0,没有冲突,所以此处可以不用push去保存这类寄存器的值,不过有个寄存器要注意,那就是r14,即lr,其是在前面调用clock_init的时候,用的是bl指令,所以会自动把跳转时候的pc的值赋值给lr,所以也不需要push指令去将PC的值保存到堆栈中。 |
|
|
而此处是clock_init的代码的最后一行 就是我们常见的mov pc, lr,把lr的值,即之前保存的函数调用时候的PC值,赋值给现在的PC,这样就实现了函数的正确的返回,即返回到了函数调用时候下一个指令的位置。 这样CPU就可以继续执行原先函数内剩下那部分的代码了。 |





|
对于使用哪个寄存器来传递返回值 |
|---|---|
| 当然你也可以用其他暂时空闲没有用到的寄存器来传递返回值,但是这些处理方式,本身是根据ARM的APCS的寄存器的使用的约定而设计的,你最好不要随便改变使用方式,最好还是按照其约定的来处理,这样程序更加符合规范。 |
3.7. 关于为何不直接用mov指令,而非要用adr伪指令
在分析uboot的start.S中,看到一些指令,比如:
adr r0, _start
觉得好像可以直接用mov指令实现即可,为啥还要这么麻烦地,去用ldr去实现?
关于此处的代码,为何要用adr指令:
adr r0, _start
|
adr r0, _start会被翻译为真正的汇编指令 |
|---|---|
| 其被编译器编译后,会被翻译成: sub r0, pc, #172 |
而不直接用mov指令直接将_start的值赋值给r0,类似于这样:
mov r0, _start
呢?
其原因主要是,
sub r0, pc, #172
这样的代码,所处理的值,都是相对于PC的偏移量来说的,这样的代码中,没有绝对的物理地址值,都是相对的值,利用产生位置无关代码。因为如果用mov指令:
mov r0, _start
那么就会被编译成这样的代码:
mov r0, 0x33d00000
如果用了上面这样的代码:
mov r0, 0x33d00000
那么,如果整个代码,即要执行的程序的指令,被移动到其他位置,那么
mov r0, 0x33d00000
这行指令,执行的功能,就是跳转到绝对的物理地址,而不是跳转到相对的_start的位置了,就不能实现我们想要的功能了,这样包含了绝对物理地址的代码,也就不是位置无关的代码了。
与此相对,这行指令:
sub r0, pc, #172
即使程序被移动到其他位置,那么该行指令还是可以跳转到相对PC往前172字节的地方,也还是我们想要的_start的位置,这样包含的都是相对的偏移位置的代码,就叫做位置无关代码。其优点就是不用担心你的代码被移动,即使程序的基地址变了,所有的代码的相对位置还是固定的,程序还是可以正常运行的。
关于,之所以不用上面的:
mov r0, 0x33d00000
类似的代码,除了上面说的,不是位置无关的代码之外,其还有个潜在的问题,那就是,关于mov指令的源操作数,此处即为0x33d00000,不一定是合法的mov 指令所允许的值,这也正是下面要详细解释的内容第 3.8 节 “mov指令的操作数的取值范围到底是多少”
【总结】
之所以用adr而不用mov,主要是为了生成地址无关代码,以及由于不方便判断一个数,是否是有效的mov的操作数。
3.8. mov指令的操作数的取值范围到底是多少
关于mov指令操作数的取值范围,网上看到一些人说是0x00-0xFF,也有人说是其他的值的,但是经过一番求证,发现这些说法都不对。下面就是来详细解释,mov指令的操作数的取指范围,到底是多少。
在看了我说的,关于这行代码:
mov r0, 0x33d00000
的源操作数0x33d0000,可能是mov指令所不允许的,这句话后,可能有人会说,我知道,那是因为mov的操作数的值,不允许大于255,至少网上很多人的资料介绍中,都是这么说的。
对此,要说的是,你的回答是错误的。
关于mov操作数的真正的允许的取值范围,还真的不是那么容易就能搞懂的,下面就来详细解释解释。
总的来说,我是从ARM 汇编的mov操作立即数的疑问
里面,才算清楚mov的取值范围,以及找了相应的datasheet,才最终看懂整个事情的来龙去脉的。
首先,mov的指令,是属于ARM指令集中,数据处理(Data Process)分类中的其中一个指令,
而数据处理指令的具体格式是:ARM Processor Instruction Set
图 3.9. 数据处理指令的指令格式
 |
对于此格式,我们可以拿:
arm-linux-objdump –d u-boot > dump_u-boot.txt
中得到的汇编代码中关于:
ldr r0, =0x53000000
所对应的,真正的汇编代码:
33d00068: e3a00453 mov r0, #1392508928 ; 0x53000000
来分析,就容易看懂了:
mov r0, #1392508928
= mov r0, #0x53000000
的作用就是,把0x53000000移动到r0中去。
其对应的二进制指令是上面的:
0xe3a00453 = 1110 0011 1010 0000 0000 0100 0101 0011 b
下面对照mov指令的格式,来分析这些位所对应的含义:
表 3.3. mov指令0xe3a00453的位域含义解析
| 31-28 | 27-26 | 25 | 24-21 | 20 | 19-16 | 15-12 | 11-0 | |
|---|---|---|---|---|---|---|---|---|
| Condition Field | 00 | I(Immediate Operand) | OpCode(Operation Code) | S(Set Condition Code) | Rn(1st Operand Register) | Rd(Destination Register) | Operand 2
1 = operand |
|
| 11-8:Rotate | 7-0:Imm | |||||||
| 1110 | 00 | 1 | 1101 | 0 | 0000 | 0000 | 0100 | 0101 0011 |
| 表明是立即数 | 1101对应的是MOV指令 | MOV指令做的事情是: Rd:= Op2,和Rn无关,所以忽略这个Rn | 表示0000号寄存器,即r0 | 0100=4,含义参见注释1 | 0x53 | |||
|
注意 |
|---|---|
| 上述datasheet中写到:
意思是,对于bit[11:8]的值,是个4位,无符号的整型,其指定了bit[7:0]的8bit立即数值的位移操作。具体如何指定呢,那就是将bit[7:0]的值,循环右移2x bit[11:8]位。 对于我们的例子,就是,将bit[7:0]的值0x53,循环右移 2xbit[11:8]= 2 x 4 = 8位, 而0x53循环右移8位,就得到了0x53000000,就是我们要mov值,mov到目的寄存器rd,此处为r0中。 而上面英文最后一句说的是,通过将bit[7:0]的值,循环右移 2xbit[11:8]的方式,就可以产生出很多个数值了,即mov的操作数中,其中符合可以通过0x00-0xFF循环右移偶数位而产生的数值,都是合法的mov的操作数,而这样的数,其实是很多的。 |
|
总结mov取值范围 |
|---|---|
| 所以,mov指令的操作数的真正的取指范围,即不是0-0xFF(0-255),也不是只有2的倍数,而是: 只要该数,可以通过0x00-0xFF中某个数,循环右移偶数位而产生,就是合法的mov的操作数,否则就是非法的mov的操作数。 |
3.9. 汇编学习总结记录
对于我们之前分析的start.S中,涉及到很多的汇编的语句,其中,可以看出,很多包含了很多种不同的语法,使用惯例等,下面,就对此进行一些总结,借以实现一定的举一反三或者说触类旁通,这样,可以起到一定的借鉴功能,方便以后看其他类似汇编代码, 容易看懂汇编代码所要表达的含义。
3.9.1. 汇编中的标号=C中的标号
像前面汇编代码中,有很多的,以点开头,加上一个名字的形式的标号,比如:
reset:
/*
* set the cpu to SVC32 mode
*/
mrs r0,cpsr
中的reset,就是汇编中的标号,相对来说,比较容易理解,就相当于C语言的标号。
比如,C语言中定义一个标号ERR_NODEV:
ERR_NODEV: /* no device error */
... /* c code here */
然后对应在别处,使用goto去跳转到这个标号ERR_NODEV:
if (something)
goto ERR_NODEV ;
|
【总结】 |
|---|---|
| 汇编中的标号 = C语言中的标号Label |
3.9.2. 汇编中的跳转指令=C中的goto
对应地,和上面的例子中的C语言中的编号和掉转到标号的goto类似,汇编中,对于定义了标号,那么也会有对应的指令,去跳转到对应的汇编中的标号。
这些跳转的指令,就是b指令,b是branch的缩写。
b指令的格式是:
b{cond} label
简单说就是跳转到label处。
用和上面的例子相关的代码来举例:
.globl _start
_start: b reset
就是用b指令跳转到上面那个reset的标号。
|
【总结】 |
|---|---|
| 汇编中的b跳转指令 = C语言中的goto |
3.9.3. 汇编中的.globl=C语言中的extern
对于上面例子中:
.globl _start
中的.global,就是声明_start为全局变量/标号,可以供其他源文件所访问。
即汇编器,在编译此汇编代码的时候,会将此变量记下来,知道其是个全局变量,遇到其他文件是用到此变量的的时候,知道是访问这个全局变量的。
因此,从功能上来说,就相当于C语言用extern去生命一个变量,以实现本文件外部访问此变量。
|
【总结】 |
|---|---|
| 汇编中的.globl或.global = C语言中的extern |
3.9.4. 汇编中用bl指令和mov pc,lr来实现子函数调用和返回
和b指令类似的,另外还有一个bl指令,语法是:
BL{cond} label
其作用是,除了b指令跳转到label之外,在跳转之前,先把下一条指令地址存到lr寄存器中,以方便跳转到那边执行完毕后,将lr再赋值给pc,以实现函数返回,继续执行下面的指令的效果。
用下面这个start.S中的例子来说明:
bl cpu_init_crit
......
cpu_init_crit:
......
mov pc, lr
其中,就是先调用bl掉转到对应的标号cpu_init_crit,其实就是相当于一个函数了,
然后在cpu_init_crit部分,执行完毕后,最后调用 mov pc, lr,将lr中的值,赋给pc,即实现函数的返回原先 bl cpu_init_crit下面那条代码,继续执行函数。
上面的整个过程,用C语言表示的话,就相当于
......
cpu_init_crit();
......
void cpu_init_crit(void)
{
......
}
而关于C语言中,函数的跳转前后所要做的事情,都是C语言编译器帮我们实现好了,会将此C语言中的函数调用,转化为对应的汇编代码的。
其中,此处所说的,函数掉转前后所要做的事情,就是:
- 函数跳转前
要将当前指令的下一条指令的地址,保存到lr寄存器中
- 函数调用完毕后
将之前保存的lr的值给pc,实现函数跳转回来。继续执行下一条指令。
而如果你本身自己写汇编语言的话,那么这些函数跳转前后要做的事情,都是你程序员自己要关心,要实现的事情。
|
总结汇编中的:bl + mov pc,lr |
|---|---|
| 汇编中bl + mov pc,lr = C语言中的子函数调用和返回 |
3.9.5. 汇编中的对应位置有存储值的标号 = C语言中的指针变量
像前文所解析的代码中类似于这样的:
LABEL1:.word Value2
比如:
_TEXT_BASE:
.word TEXT_BASE
所对应的含义是,有一个标号_TEXT_BASE
而该标号中对应的位置,所存放的是一个word的值,具体的数值是TEXT_BASE,此处的TEXT_BASE是在别处定义的一个宏,值是0x33D00000。
所以,即为:
有一个标号_TEXT_BASE,其对应的位置中,所存放的是一个word的值,值为
TEXT_BASE=0x33D00000
总的来说,此种用法的含义,如果用C语言来表示,其实更加容易理解:
int *_TEXT_BASE = TEXT_BASE = 0x33D00000
即:
int *_TEXT_BASE = 0x33D00000
|
C语言中如何引用汇编中的标号 |
|---|---|
| 不过,对于这样的类似于C语言中的指针的汇编中的标号,在C语言中调用到的话,却是这样引用的: /* for the following variables, see start.S */
extern ulong _armboot_start; /* code start */
extern ulong _bss_start; /* code + data end == BSS start */
......
IRQ_STACK_START = _armboot_start - CFG_MALLOC_LEN - CFG_GBL_DATA_SIZE - 4;
......
而不是我原以为的,直接当做指针来引用该变量的方式: *IRQ_STACK_START = *_armboot_start - CFG_MALLOC_LEN - CFG_GBL_DATA_SIZE - 4;
其中,对应的汇编中的代码为: .globl _armboot_start
_armboot_start:
.word _start
所以,针对这点,还是需要注意一下的。至少以后如果自己写代码的时候,在C语言中引用汇编中的global的标号的时候,知道是如何引用该变量的。 |
|
【总结】 |
|---|---|
| 汇编中类似这样的代码: label1: .word value2 就相当于C语言中的: int *label1 = value2 但是在C语言中引用该标号/变量的时候,却是直接拿来用的,就像这样: label1 = other_value 其中label1就是个int型的变量。 |
3.9.6. 汇编中的ldr+标号,来实现C中的函数调用
接着上面的内容,继续解释,对于汇编中这样的代码:
第一种:
ldr pc, 标号1
......
标号1:.word 标号2
......
标号2:
......(具体要执行的代码)
或者是,
第二种:
ldr pc, 标号1
......
标号1:.word XXX(C语言中某个函数的函数名)
的意思就是,将地址为标号1中内容载入到pc中。
而地址为标号1中的内容,就是标号2。
TEXT_BASE=0x33D00000
所以上面第一种的意思:
就很容易看出来,就是把标号2这个地址值,给pc,即实现了跳转到标号2的位置执行代码,
就相当于调用一个函数,该函数名为标号2.
第二种的意思,和上面类似,是将C语言中某个函数的函数名,即某个地址值,给pc,实现调用C中对应的那个函数。
两种做法,其含义用C语言表达,其实很简单:
PC = *(标号1) = 标号2
例 3.1. 汇编中的ldr加标号实现函数调用 示例
举个例子就是:
第一种:
......
ldr pc, _software_interrupt
......
_software_interrupt: .word software_interrupt
......
software_interrupt:
get_bad_stack
bad_save_user_regs
bl do_software_interrupt
就是实现了将标号1,_software_interrupt,对应的位置中的值,标号2,software_interrupt,给pc,即实现了将pc掉转到software_interrupt的位置,即实现了调用函数software_interrupt的效果。
第二种:
ldr pc, _start_armboot
_start_armboot: .word start_armboot
含义就是,将标号1,_start_armboot,所对应的位置中的值,start_armboot给pc,即实现了调用函数start_armboot的目的。
其中,start_armboot是C语言文件中某个C语言的函数。
|
总结汇编中实现函数调用的方式 |
|---|---|
| 汇编中,实现函数调用的效果,有如下两种方法:
|
3.9.7. 汇编中设置某个寄存器的值或给某个地址赋值
在汇编代码start.S中,看到不止一处, 类似于这样的代码:
形式1:
# define pWTCON 0x53000000
......
ldr r0, =pWTCON
mov r1, #0x0
str r1, [r0]
或者是,
形式2:
# define INTSUBMSK 0x4A00001C
......
ldr r1, =0x7fff
ldr r0, =INTSUBMSK
str r1, [r0]
其含义,都是将某个值,赋给某个地址,此处的地址,是用宏定义来定义的,对应着某个寄存器的地址。
其中,形式1是直接通过mov指令来将0这个值赋给r1寄存器,和形式2中的通过ldr伪指令来将0x3ff赋给r1寄存器,两者区别是,前者是因为已经确定所要赋的值0x0是mov的有效操作数,而后者对于0x3ff不确定是否是mov的有效操作数
![[警告]](http://img.e-com-net.com/image/info8/d85492c47407428d9742d512802531ef.jpg) |
警告 |
|---|---|
| 如果不是,则该指令无效,编译的时候,也无法通过编译,会出现类似于这样的错误:: start.S: Assembler messages:
start.S:149: Error: invalid constant -- 'mov r1,#0xFFEFDFFF'
make[1]: *** [start.o] 错误 1
make: *** [cpu/arm920t/start.o] 错误 2
|
所以才用ldr伪指令,让编译器来帮你自动判断:
- 如果该操作数是mov的有效操作数,那么ldr伪指令就会被翻译成对应的mov指令
例 3.2.
举例说明:
汇编代码:
# define pWTCON 0x53000000 ...... ldr r0, =pWTCON被翻译后的真正的汇编代码:
33d00068: e3a00453 mov r0, #1392508928 ; 0x53000000 - 如果该操作数不是mov的有效操作数,那么ldr伪指令就会被翻译成ldr指令
例 3.3.
举例说明:
汇编代码:
ldr r1, =0x7fff被翻译后的真正的汇编代码:
33d00080: e59f13f8 ldr r1, [pc, #1016] ; 33d00480
即把ldr伪指令翻译成真正的ldr指令,并且另外分配了一个word的地址空间用于存放该数值,然后用ldr指令将对应地址中的值载入,赋值给r1寄存器。
|
总结汇编中给某个地址赋值的方法 |
|---|---|
| 汇编中,一个常用的,用来给某个地址赋值的方法,类似如下形式: #define 宏的名字 寄存器地址 ...... ldr r1, =要赋的值 ldr r0, =宏的名字 str r1, [r0] |