大数据实战第三十六课 - 生产预警平台01
第一章: 项目背景
- 1.1 早期运维-ELK
- 1.2 生产预警平台的架构
- 1.3 Flume二次开发
- 1.4 生产Flume源码导入IDEA
第二章: 进行开发
- 2.1 自定义flume二次开发
第一章:项目背景
项目名称:生产预警平台
背景:
- 外资车载导航、硬件、传感器、GPS等等
1、服务挂了,不能及时通知
2、服务不能达到秒级通知,前两年基本都是分钟级别,5min左右
3、对于一些即将出现的问题可以提前预知
4、有效的扩展到实时计算、日志
5、如MYSQL 、SQL的error、慢sql
6、如Nginx、Tomcat、Linux系统级别的日志
涉及到甲方和乙方:
SLA:Service-Level Agreement(服务等级协议) 99%
J总当时遇到一个问题:
- CDH的NN进程,NameNode挂了,在它挂之前会抛出一些异常:比如说内存不够,会先抛出warning警告,warning警告抛了两分钟,然后抛error;然后OOM挂了。
- 一些系统挂之前都会报一些警告,很多情况下有些服务不是直接挂的,Tomcat会先抛出一些异常,然后抛出error,然后Tomcat还没有挂:因为写代码的时候try、catch住了,这样对用户体验就不是很好。
1.1 早期运维ELK
1、ELK入门实战(算一个小项目),写完后可以写在简历中
- https://www.bilibili.com/video/av35467284?from=search&seid=8348847599548114860
ELK项目在行业中有两家公司在做:1、日志易(3、4年前是使用ELK做的) 2、SPLUNK公司
- 对于知识面的拓展来说是很重要的。
1.2 生产预警平台的架构
- https://ruozedata.github.io/categories/%E7%94%9F%E4%BA%A7%E9%A2%84%E8%AD%A6%E5%B9%B3%E5%8F%B0%E9%A1%B9%E7%9B%AE/page/2/
车载导航的日志、系统运行日志(app、各个传感器温度、经纬度、高度)、用户行为日志;
上报数据的日志有两个维度:
维度一:1min/5min/10min
维度二:数据量达到10kb就上传
特斯拉系统就是后台导航远程在监控;数据上报过来之后在Tomcat采集器,车载导航把所有数据发送给Tomcat采集器,数据落地到磁盘文件;Linux --> ELK进行分析预警;开发人员去查看有无问题。
AWS集群,公司面对车场的业务,腾讯有软件公司对外接服务,选择了XX公司,在初中时代10快钱一个月的彩铃包月、导航业务(付费业务)
对于我们现有学习来说:
我们采集CDH的NN进程的日志 --> flume --> kafka --> Spark Streaming --> influxdb --> grafana
第一座山:
第二座山:
1、NameNode的log是log4j的形式,以列的形式:时间 日志级别 日志详细信息
- cd /var/log/hadoop-hdfs
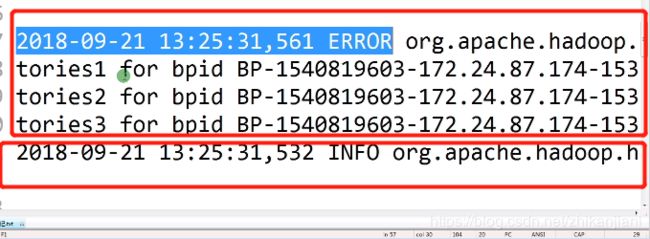
我们把日志贴出来,常见的日志就是时间、级别、详细信息;
- 2018-09-21 13:25:31,527 INFO org.apache.hadoop.hdfs.server.common.Storage: Using 1 threads to upgrade data directories (dfs.datanode.parallel.volumes.load.threads.num=1, dataDirs=1)
- 2018-09-21 13:25:31,532 INFO org.apache.hadoop.hdfs.server.common.Storage: Lock on /dfs/dn/in_use.lock acquired by nodename 21317@hadoop002
我们既然要用到Spark,使用DF操作,就是要使用RDD+schema来进行操作;
2、改造日志,改造成带有schema信息的;
- cluster --> 选中HDFS --> configuration --> 选中NameNode,输入LOG进行搜索;

NameNode Logging Advanced Configuration Snippet (Safety Valve):后面跟上这样一段话:
log4j.appender.RFA.layout.ConversionPattern = {"time":"%d{yyyy-MM-dd HH:mm:ss,SSS}","logtype":"%p","loginfo":"%c:%m"}%n
如上JSON格式解析:
time:时间 logtype:日志类型 loginfo:报错信息 %n换行符
在NameNode和DataNode中都进行配置:保存完了之后回到首页;重启HDFS即可(Restart Stale Service)。

那我们想要有Schema,最好就是构建JSON格式,并且JSON格式能够转换成DF的;
生产上每台机器不可能只运行1个服务,肯定是多个服务并存的,在我们采集这条数据的时候,我们要明白这条数据来自哪台机器;
- 假设我们把所有的日志都放到一个文件中,任意抽取出一条数据,我们并不知道这条数据来自哪里,所以我们需要添加两列:机器名称和服务名称。
1.3 flume的二次开发
- hadoop-cmf-hdfs-DATANODE-hadoop002.log.out,服务一直写的就是这个文件,写满100M就切换,什么意思呢?
- 写满100M,文件进行重命名,mv hadoop002.log hadoop002.log1,touch的新文件还是hadoop002.log。
NameNode Logging Threshold:
NameNode Max Log Size:NameNode Default Group:200MB
NameNode Maximum Log File Backups:NameNode Default Group:10
- 每隔200MB就切换到下一个文件,且每份文件保留10份。
我们想个问题,我们使用Exec Source就够了,思考:我们的服务挂了,数据丢失一点有没有关系?
不同的场景采用不同的source,在生产过程中,采用flume是没有发生过故障的,我们选择exec source
flume-ng的tail -f参数所诱发的血案:
- http://blog.itpub.net/30089851/viewspace-2134067/
原因是tail -f 文件被切走之后新建的原文件,tail -f不能识别。
1.4 生产flume源码导入IDEA
- https://blog.csdn.net/zhikanjiani/article/details/100678368
1、首先要找到Exec的源代码:
2.1 自定义flume二次开发
1、添加两列:机器名称、服务名称
2、日志折断
3、在构建hdfs日志的时候,spark作业出现一个json串的时候无法生效,就无法转化为DF,我们需要做的是清洗+JSON校验 --> 校验成功写到channel memory --> kafka.
- 选择磁盘和内存都可以,选择磁盘性能降低,不会丢数据;选择内存,性能高,有可能会丢数据。
概念:linux中error信息,从上面到下面是一整条信息;抛exception的时候错误信息是有很多行的;
解决:
1、在每一行加上时间+日志级别+机器名称:问题:后续进行分析分辨不清楚哪条日志是否是一个整体
2、采取的措施:把换行符换成自己特有的分割符,使其变成一个整体
自定义source和service,拿到这两个参数后,来自哪个服务是通过参数配置的,一个flume进程只采集一个配置;
验证tmpevent是否为json格式,不验证的话,会导致job计算失败:
if (jsonvalidator.validate(tmpevent)){
eventList.add(EventBuilder.withBody(tmpevent))
} else{
输出到某个errorparse.log
}
自定义代码搞完之后,只打包flume-ng-core工程下的文件;打完包后去到target下显示的打包文件目录。
注意:
以后打包的时候,class文件不生效的话,记得先去clean一下。
打包方式:J总以前是单独打包两个文件,今天我们使用IDEA maven打包一个整的jar包。