hadoop-2.7.3 + hive-2.3.0 + zookeeper-3.4.8 + hbase-1.3.1 完全分布式安装配置
近期抽空搭建了一下hadoop-2.7.3 + hbase-1.3.1 + zookeeper-3.4.8 + hive-2.3.0完全分布式平台环境,网上查询了很多相关资料,安装成功后,特意记录下来以供参考。
一、软件准备
VMware12、hadoop-2.7.3、hbase-1.3.1、zookeeper-3.4.8、hive-2.3.0、jdk-8u65-linux-x64.tar.gz
二、hadoop安装配置
1.解压jdk:tar -zxvf jdk-8u65-linux-x64.tar.gz -C /home/zs/app/(提前建好的文件夹路径)
2. 解压hadoop tar -zxvf hadoop-2.7.0.tar.gz -C /home/zs/app/
3.配置环境变量: gedit /etc/proflie 打开文件添加:
# jdk
export JAVA_HOME=/home/zs/app/jdk1.8.0_65
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib:$CLASSPATH
export PATH=${JAVA_HOME}/bin:$PATH
# hadoop2.7.3
export HADOOP_HOME=/home/zs/app/hadoop-2.7.3
mapred-site.xml
4.配置Hadoop中的配置文件
主要配置四个文件,在Hadoop2.7.3/etc/hadoop中分别为core-site.xml hdfs-site.xml yarn-site.xml mapred-site.xml(拷贝mapred-site.xml.template产生) 同样用sudo gedit命令打开xml文件
1)core-site.xml
hadoop.tmp.dir
/home/zs/app/hadoop-2.7.3/tmp
fs.defaultFS
hdfs://master:9000 // master 也可改为机器IP
2)
hdfs-site.xml
这里是配置有多少个datanode节点,这里默认为master节点就是NameNode节点,slave节点就是datanode节点。我们这里有两个datanode节点。
dfs.replication
2
3)yarn-site.xml
yarn.resourcemanager.hostname
master
yarn.nodemanager.aux-services
mapreduce_shuffle
4)mapred-site.xml
mapreduce.framework.name
yarn
slave1 slave2
告诉master机器 子节点是什么
export JAVA_HOME=/home/zs/app/jdk1.8.0_65
首先通过命令 sudoapt-get install ssh 安装ssh
接下来用命令ssh-keygen -t rsa生成本机密钥,一路回车就好
用命令cat id_rsa.pub >> authorized_keys进行授权
配置好了之后可以用ssh localhost用来测试,如果无需密码弹出如下信息则配置成功
Welcome to Ubuntu 16.04 LTS (GNU/Linux 4.4.0-21-generic x86_64)
* Documentation: https://help.ubuntu.com/
302 packages can be updated.
4 updates are security updates.
*** System restart required ***
Last login: Sat Dec 3 06:16:02 2016 from 127.0.0.1
6.克隆虚拟机两份,作为slave节点
7.修改主机名称
使用sudo gedit /etc/hostname修改主机名称,主机为master。其余的两台分别为slave1和slave2
8.修改hosts
同样用sudo gedit /etc/hosts ,修改内容如下,其中IP可以使用ifconfig命令查看
192.168.71.134 master
192.168.71.135 slave1
192.168.71.136 slave2
三台虚拟机都要修改
至此,Hadoop的配置环境就建立好了
验证:在master节点中格式化namenode节点
hadoop namenode -format
之后启动hadoop集群
start-all.sh
之后可以使用jps命令查看每台机器上的Java进程
master节点:
30976 Jps
29922 NameNode
30134 SecondaryNameNode
30286 ResourceManager
slave1节点:
2567 Jps
2346 NodeManager
2171 DataNode
slave2节点:2306 NodeManager
2107 DataNode
2557 Jps
三、hive安装配置(基于MySQL的本地模式安装)
1.解压hive tar -zxvf apache-hive-2.3.0-bin.tar.gz -C /home/zs/app
2.添加MySQL驱动:
下载mysql-connector-Java-x.y.z-bin.jar文件并放到apache-hive-2.1.1-bin/lib目录下面。
3.配置环境变量 sudo /etc/profile 添加:
#hive export HIVE_HOME=/home/zs/app/hive-2.3.0 export PATH=$PATH:$HIVE_HOME/bin
4.修改hive-site.xml(hive-default.xml 复制重命名而成):
- <configuration>
- <property>
- <name>javax.jdo.option.ConnectionURLname>
- <value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=truevalue>
- <description>JDBC connect string for a JDBC metastoredescription>
- property>
- <property>
- <name>javax.jdo.option.ConnectionDriverNamename>
- <value>com.mysql.jdbc.Drivervalue>
- <description>Driver class name for a JDBC metastoredescription>
- property>
- <property>
- <name>javax.jdo.option.ConnectionUserNamename>
- <value>hivevalue>
- <description>username to use against metastore databasedescription>
- property>
- <property>
- <name>javax.jdo.option.ConnectionPasswordname>
- <value>123456value>
- <description>password to use against metastore databasedescription>
- property>
- configuration>
5.修改hive-env.sh(hive-env.sh.template 复制重命名而成)
- export HADOOP_HEAPSIZE=1024
- HADOOP_HOME=/home/zs/app/hadoop-2.7.3 #这里设置成自己的hadoop路径
- export HIVE_CONF_DIR=/home/zs/app/hive-2.3.0/conf
- export HIVE_AUX_JARS_PATH=/home/zs/app/hive-2.3.0/lib
- mysql -uroot -p
- Enter password:
- ......此处省略部分日志......
- mysql> <u>create user 'hive' identified by 'hive';u>
- Query OK, 0 rows affected (0.05 sec)
- mysql> <u>grant all privileges on *.* to 'hive' with grant option;u>
- Query OK, 0 rows affected (0.00 sec)
- mysql> <u>flush privileges;u>
- Query OK, 0 rows affected (0.00 sec)
bin/schematool -initSchema -dbType mysql
8.先启动Hadoop,然后进入hive的lib目录,使用:hive 命令 启动hive
三、zookeeper安装配置
1.部署说明
ZK官网建议安装在至少3台机器上,故这里将ZK分别安装三台机器组成的集群中
2.解压zookeeper 到/home/zs/app/ 下面
3.设置myid
# IP(可换成hosts中配置的名字) 标识数值
192.168.68.122 1
192.168.68.123 2
192.168.68.124 3
4.修改conf/zoo.cfg(zoo_sample.cfg 复制重命名而来)
tickTime=2000
5:启动zk
每台机器上执行:[master@master1 zookeeper]$ sudo bin/zkServer.sh start
之后我们可以使用 sudo bin/zkServer.sh status 查看状态
sudo bin/zkServer.sh stop 停止服务
四:Hbase的安装配置
1.解压Hbase 到/home/zs/app 下
2.配置环境变量 sudo /etc/profile
#hbase export HBASE_HOME=/home/zs/app/hbase-1.3.1 export PATH=$HBASE_HOME/bin:$PATH
3.配置hbase-env.sh
4.配置hbase-site.xml
5.配置regionservers
清空该文件,加入集群的节点,例如我这里是
slave1
slave2
6.将hbase scp到节点
sudo scp/home/zs/app/hbase-1.3.1 slave1:/home/zs/app/
sudo scp /home/zs/app/hbase-1.3.1 slave1:/home/zs/app/
7.启动
启动之前得保证ZK和hadoop已经启动
bin/start-hbase.sh最终jps效果如下:
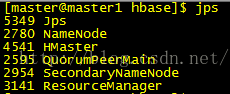
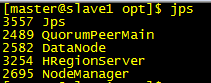

8.Web界面访问
貌似从1.0版本以后端口改为16010端口了,所以web访问为:http://192.168.68.122:16010/