数据挖掘之科比投球案例分析
为了弥补在特征工程中的不足,学习一下如何从数据获取以后进行数据处理分析,以下为数据处理学习内容:
在学习过程中遇到问题:
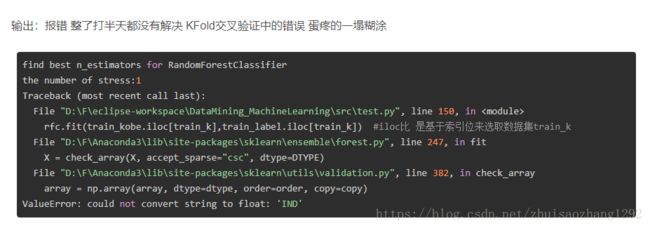
原因1:后来发现是学习视频中介绍导包的文件不对,下面这两个都是KFold交叉验证的包,但是用法不同
原因2:某些特征中存在字符串 没法将其转换为float或int计算,如上面错误中的’IND‘ 就是其中一个特征中的值,
在后面的交叉验证前进行了 相关特征剔除,保证了验证的顺利运行,但是肯定会导致精度下降,后期再将其进行map映射或这one-hot编码
# from sklearn.model_selection import KFold
from sklearn.cross_validation import KFold'''
Created on 2018年8月8日
@author: hcl
'''
'''
Created on
@author: hcl
'''
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
file_path = 'data.csv'
raw = pd.read_csv(file_path)
#看一下样本的分布情况 及样式
# print(raw.shape)
# # print(raw.head())
# print(raw.tail())
#查找空值 在这里直接把它当成需要预测的目标
# kobe = raw[pd.isnull(raw['shot_made_flag'])]
# kobe = raw[pd.notnull(raw['shot_made_flag'])]
# print(kobe.shape)
#数据可视化 可能可以用来分析 是否存在相关性较高的特征
# alpha = 0.02 #点的透明程度
# plt.figure(figsize=(10,10))
# plt.subplot(121)
# plt.scatter(kobe.loc_x,kobe.loc_y,color= 'blue',alpha=alpha)
# plt.title('loc_x and loc_y')
# plt.subplot(122)
# plt.scatter(kobe.lon,kobe.lat,color= 'green',alpha=alpha)
# plt.title('lat and lon')
# plt.show()
#通过unique()去获取某一特种中不重复的属性
# print(kobe.action_type.unique())
# print(kobe.combined_shot_type.unique())
# print(kobe.shot_type.unique())
#通过value_counts() 特征中不同属性出现的次数,且貌似是默认降序排列
# print(kobe.shot_type.value_counts())
# print(kobe.action_type.value_counts())
#因为机器学习算法不认识特殊字符串 所以需要进行处理 这边处理为字符串的右半边并转换为整型 具体情况具体调整策略
# print(kobe.season.unique()) #和下面的效果一样
# print(kobe['season'].unique())
# raw['season'] = raw['season'].apply(lambda x : int(x.split('-')[1])) #因为这边的season中的内容是例如 2018-01
# print(raw['season'].unique())
#查看与哪队打比赛 并生成DataFrame
# kd = pd.DataFrame({'matchup':kobe.matchup,'opponent':kobe.opponent})
# print(kd)
#程序运行会报错 原始数据没有dist字段,课件内容主要是想阐述 这两个字段会呈现出正相关性
# plt.figure(figsize=(5,5))
# print(raw.keys())#检查发现原始数据没有dist字段
# plt.scatter(raw.dist,raw.shot_distance,color = 'blue')
# plt.title('dist and shot_distance')
# plt.show()
#查看出手投球的区域 通过分组以后的gs 把他当作一个key 然后对其他组或列进行计算
# gs = kobe.groupby('shot_zone_area')
# print(len(gs))
# print(kobe['shot_zone_area'].value_counts())
# import matplotlib.cm as cm
# plt.figure(figsize = (20,10))
# def scatter_plot_by_category(feat):
# alpha = 0.1
# gs = kobe.groupby(feat) #还是原来的数据 只不过以feat字段/特征进行了分组
# cs = cm.rainbow(np.linspace(0,1,len(gs)))
# for g,c in zip(gs,cs):
# plt.scatter(g[1].loc_x,g[1].loc_y,color =c ,alpha= alpha)
# plt.subplot(131)
# scatter_plot_by_category('shot_zone_area')
# plt.title('shot_zone_area')
# plt.subplot(132)
# scatter_plot_by_category('shot_zone_basic')
# plt.title('shot_zone_basic')
# plt.subplot(133)
# scatter_plot_by_category('shot_zone_range')
# plt.title('shot_zone_range')
# plt.show()
#去除某一个字段 drops中为需要删除的字段
# drops = ['action_type', 'combined_shot_type', 'game_event_id', 'game_id', 'lat',
# 'loc_x', 'loc_y', 'lon', 'minutes_remaining', 'period', 'playoffs',
# 'season', 'seconds_remaining', 'shot_distance', 'shot_type',
# 'shot_zone_area', 'shot_zone_basic', 'shot_zone_range', 'team_id',
# 'team_name', 'game_date', 'matchup', 'opponent', 'shot_id']
# for drop in drops:
# raw = raw.drop(drop,1)
# print(raw.keys())
#对某一列特征进行one-hot编码 在pandas中利用dummies进行one-hot编码 并可以产生新创建的列 新建列名为 prefix指定前缀+ '_' + 原有特征属性
# print(raw['combined_shot_type'].value_counts())
# data_oneshot = pd.get_dummies(raw['combined_shot_type'],prefix = 'combined_shot_type')[0:2] #prefix为设置列名前缀,可以不加 试一下效果
# print(data_oneshot)
# print(raw.keys())
#对需要onghot编码的字段/列进行操作 并删除原始列
# categorical_vars = ['combined_shot_type']#'action_type',,'shot_type','opponent','period','season'
# print(raw.keys())
# for var in categorical_vars:
# raw = pd.concat([raw,pd.get_dummies(raw[var], prefix=var)],1) #产生新的列名 并对其做行拼接(指定了1,若指定为0 表示列拼接)
# raw = raw.drop(var,1) #删除原始列
# print(raw.keys())
#***********************输出************************
# Index(['action_type', 'combined_shot_type', 'game_event_id', 'game_id', 'lat',
# 'loc_x', 'loc_y', 'lon', 'minutes_remaining', 'period', 'playoffs',
# 'season', 'seconds_remaining', 'shot_distance', 'shot_made_flag',
# 'shot_type', 'shot_zone_area', 'shot_zone_basic', 'shot_zone_range',
# 'team_id', 'team_name', 'game_date', 'matchup', 'opponent', 'shot_id'],
# dtype='object')
# Index(['action_type', 'game_event_id', 'game_id', 'lat', 'loc_x', 'loc_y',
# 'lon', 'minutes_remaining', 'period', 'playoffs', 'season',
# 'seconds_remaining', 'shot_distance', 'shot_made_flag', 'shot_type',
# 'shot_zone_area', 'shot_zone_basic', 'shot_zone_range', 'team_id',
# 'team_name', 'game_date', 'matchup', 'opponent', 'shot_id',
# 'combined_shot_type_Bank Shot', 'combined_shot_type_Dunk',
# 'combined_shot_type_Hook Shot', 'combined_shot_type_Jump Shot',
# 'combined_shot_type_Layup', 'combined_shot_type_Tip Shot'],
# dtype='object')
#**********这段代码不能用 因为有个错误出现在了KFold交叉验证过程中****************
train_kobe = raw[pd.notnull(raw['shot_made_flag'])]
train_label = train_kobe['shot_made_flag']
train_kobe = train_kobe.drop('shot_made_flag',1) #axis=1 删除指定列
test_kobe = raw[pd.isnull(raw['shot_made_flag'])]
test_kobe = test_kobe.drop('shot_made_flag',1)
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import confusion_matrix,log_loss
# from sklearn.model_selection import KFold
from sklearn.cross_validation import KFold
import time
drops = ['action_type','combined_shot_type','season','shot_type', 'shot_zone_area','shot_zone_basic','shot_zone_range','team_name','game_date', 'matchup', 'opponent']
for drop in drops:
train_kobe = train_kobe.drop(drop,1)
test_kobe = test_kobe.drop(drop,1)
print('find best n_estimators for RandomForestClassifier')
min_score = 100000
best_n = 0
scores_n = []
range_n = np.logspace(0,2,num=3).astype(int)#表示1 10 100
for n in range_n:
print('the number of stress:{0}'.format(n))
t1 = time.time()
rfc_score = 0
rfc = RandomForestClassifier(n_estimators=n)#指定用多少棵树进行训练
#shuffle 在每次划分时,是否进行洗牌 train_k,test_k为索引值
print(train_kobe.columns)
for train_k,test_k in KFold(len(train_kobe),n_folds=10,shuffle = True):
#代码出错在没法将特征中的IND字符串转换为 float类型
rfc.fit(train_kobe.iloc[train_k],train_label.iloc[train_k]) #iloc比 是基于索引位来选取数据集train_k
pred = rfc.predict(train_kobe.iloc[test_k])
rfc_score += log_loss(train_label.iloc[test_k],pred)/10
scores_n.append(rfc_score)
if rfc_score < min_score:
min_score = rfc_score
best_n = n
t2 = time.time()
print('Done processing {0} trees ({1:.3f}sec)'.format(n,t2-t1))
print(best_n,min_score)
print('find best max_depth for RandomForestClassifier')
min_score = 100000
best_m = 0
scores_m = []
range_m = np.logspace(0,2,num=3).astype(int)
for m in range_m:
print('the number of stress:{0}'.format(m))
t1 = time.time()
rfc_score = 0
rfc = RandomForestClassifier(max_depth=m,n_estimators=n)#max_depth 指定用多少深度/层的树
for train_k,test_k in KFold(len(train_kobe),n_folds=10,shuffle = True):
rfc.fit(train_kobe.iloc[train_k],train_label.iloc[train_k])
pred = rfc.predict(train_kobe.iloc[test_k])
rfc_score += log_loss(train_label.iloc[test_k],pred)/10
scores_n.append(rfc_score)
if rfc_score < min_score:
min_score = rfc_score
best_m = m
t2 = time.time()
print('Done processing {0} trees ({1:.3f}sec)'.format(m,t2-t1))
print(best_m,min_score)
输出:
D:\F\Anaconda3\lib\site-packages\sklearn\cross_validation.py:44: DeprecationWarning: This module was deprecated in version 0.18 in favor of the model_selection module into which all the refactored classes and functions are moved. Also note that the interface of the new CV iterators are different from that of this module. This module will be removed in 0.20.
"This module will be removed in 0.20.", DeprecationWarning)
find best n_estimators for RandomForestClassifier
the number of stress:1
Index(['game_event_id', 'game_id', 'lat', 'loc_x', 'loc_y', 'lon',
'minutes_remaining', 'period', 'playoffs', 'seconds_remaining',
'shot_distance', 'team_id', 'shot_id'],
dtype='object')
Done processing 1 trees (0.436sec)
the number of stress:10
Index(['game_event_id', 'game_id', 'lat', 'loc_x', 'loc_y', 'lon',
'minutes_remaining', 'period', 'playoffs', 'seconds_remaining',
'shot_distance', 'team_id', 'shot_id'],
dtype='object')
Done processing 10 trees (3.580sec)
the number of stress:100
Index(['game_event_id', 'game_id', 'lat', 'loc_x', 'loc_y', 'lon',
'minutes_remaining', 'period', 'playoffs', 'seconds_remaining',
'shot_distance', 'team_id', 'shot_id'],
dtype='object')
Done processing 100 trees (35.179sec)
100 14.3857894832007
find best max_depth for RandomForestClassifier
the number of stress:1
Done processing 1 trees (4.125sec)
the number of stress:10
Done processing 10 trees (18.522sec)
the number of stress:100
Done processing 100 trees (35.063sec)
10 13.498644347528199