Hello Presto
◎ 架构

◎ 安装前提
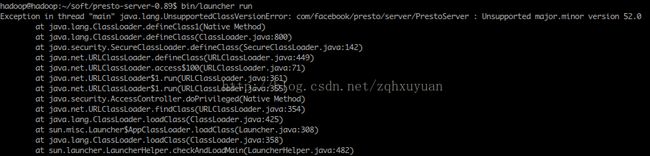
按照 http://prestodb.io/overview.html 其中要求jdk必须是1.8, 否则启动会报错版本不匹配.
◎ 配置文件
在presto-server安装目录下新建etc目录, 并新建以下配置文件和catalog目录
| 配置文件 |
配置项 |
|
| config.properties |
coordinator=true datasources=jmx node-scheduler.include-coordinator=true http-server.http.port=8080 task.max-memory=1GB discovery-server.enabled=true discovery.uri=http://localhost:8080 |
Presto 服务配置 |
| jvm.config |
-server -Xmx4G -XX:+UseConcMarkSweepGC -XX:+ExplicitGCInvokesConcurrent -XX:+CMSClassUnloadingEnabled -XX:+AggressiveOpts -XX:+HeapDumpOnOutOfMemoryError -XX:OnOutOfMemoryError=kill -9 %p -XX:PermSize=150M -XX:MaxPermSize=150M -XX:ReservedCodeCacheSize=150M |
JVM命令行选项 |
| log.properties |
com.facebook.presto=INFO |
日志信息 |
| node.properties |
node.environment=production node.id=ffffffff-ffff-ffff-ffff-ffffffffffff node.data-dir=/home/hadoop/data/presto/data |
环境变量配置,每个节点特定配置 |
| catalog/jmx.properties |
connector.name=jmx |
每个连接者配置(data sources) |
数据源可以选择jmx, hive等. 如果在这里配置了hive, 则要在catalog目录下新建一个hive.properties文件
http://yugouai.iteye.com/blog/2002504 这篇博客里由两个配置在新版本中不支持
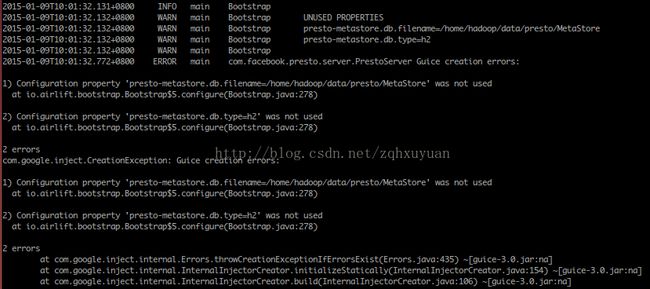
presto-metastore.db.type=h2
presto-metastore.db.filename=var/db/MetaStore
◎ 启动presto-server
hadoop@hadoop:~/soft/presto-server-0.89$ bin/launcher run
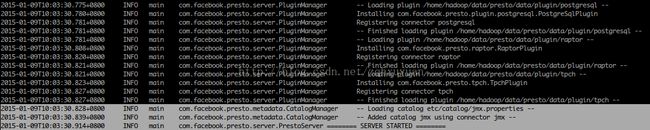
启动的过程报如下错, 这个暂时发现对下面的试验没有影响
2015-01-09T10:03:27.784+0800 ERROR Discovery-0 io.airlift.discovery.client.CachingServiceSelector Cannot connect to discovery server for refresh (collector/general): Lookup of collector failed for http://localhost:8080/v1/service/collector/general
2015-01-09T10:03:27.800+0800 ERROR Discovery-0 io.airlift.discovery.client.CachingServiceSelector Cannot connect to discovery server for refresh (presto/general): Lookup of presto failed for http://localhost:8080/v1/service/presto/general
◎ 命令行接口
http://prestodb.io/docs/current/installation/cli.html
hadoop@hadoop:~/install/bigdata/nosql$ ln -s presto-cli-0.89-executable.jar presto-cli
jmx connection
http://prestodb.io/docs/current/connector/jmx.html
hadoop@hadoop:~/install/bigdata/nosql$ ./presto-cli --server localhost:8080 --catalog jmx --schema jmx
bash: ./presto-cli: 权限不够
hadoop@hadoop:~/install/bigdata/nosql$ chmod 755 presto-cli*
hadoop@hadoop:~/install/bigdata/nosql$ ./presto-cli --server localhost:8080 --catalog jmx --schema jmx
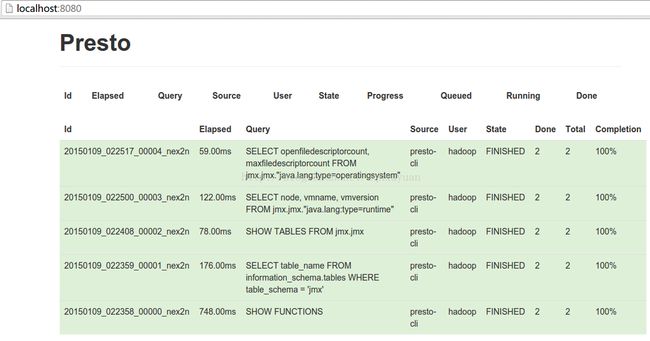
presto:jmx> SHOW TABLES FROM jmx.jmx;
Table
--------------------------------------------------------------------------------------
com.facebook.presto.execution:name=nodescheduler
com.facebook.presto.execution:name=queryexecution
com.facebook.presto.execution:name=querymanager
com.facebook.presto.execution:name=remotetaskfactory
com.facebook.presto.execution:name=taskexecutor
com.facebook.presto.execution:name=taskmanager
presto:jmx> SELECT node, vmname, vmversion
-> FROM jmx.jmx."java.lang:type=runtime";
node | vmname | vmversion
--------------------------------------+-----------------------------------+-----------
ffffffff-ffff-ffff-ffff-ffffffffffff | Java HotSpot(TM) 64-Bit Server VM | 25.25-b02
(1 row)
Query 20150109_022500_00003_nex2n, FINISHED, 1 node
Splits: 2 total, 2 done (100.00%)
0:00 [1 rows, 78B] [7 rows/s, 623B/s]
presto:jmx> SELECT openfiledescriptorcount, maxfiledescriptorcount
-> FROM jmx.jmx."java.lang:type=operatingsystem";
openfiledescriptorcount | maxfiledescriptorcount
-------------------------+------------------------
564 | 4096
(1 row)
Query 20150109_022517_00004_nex2n, FINISHED, 1 node
Splits: 2 total, 2 done (100.00%)
0:00 [1 rows, 16B] [14 rows/s, 238B/s]
hadoop@hadoop:~/install/bigdata/nosql$ jps -lm
9890 ./presto-cli --server localhost:8080 --catalog jmx --schema jmx
10469 sun.tools.jps.Jps -lm
9002 com.facebook.presto.server.PrestoServer

点击第一个Job

hive connection
http://prestodb.io/docs/current/connector/hive.html
hadoop@hadoop:~/soft/presto-server-0.89/etc$ cat config.properties
coordinator=true
datasources=jmx,hive
node-scheduler.include-coordinator=true
http-server.http.port=8080
task.max-memory=1GB
discovery-server.enabled=true
discovery.uri=http://localhost:8080
hadoop@hadoop:~/soft/presto-server-0.89/etc$ cat catalog/hive.properties
connector.name=hive-cdh5
hive.metastore.uri=thrift://localhost:9083
hadoop@hadoop:~/soft/cdh5.2.0/hive-0.13.1-cdh5.2.0/conf$ tail -f hive-site.xml
启动hive-meta和hive-server2
hive --service hiveserver2 &
hive --service metastore &

hadoop@hadoop:~/install/bigdata/nosql$ ./presto-cli --server localhost:8080 --catalog hive --schema default
presto:default> DESCRIBE hive.saledata.tbldate; ==> saledata表示hive中的database
Column | Type | Null | Partition Key | Comment
--------------+---------+------+---------------+---------
dateid | varchar | true | false |
theyearmonth | varchar | true | false |
theyear | varchar | true | false |
themonth | varchar | true | false |
thedate | varchar | true | false |
theweek | varchar | true | false |
theweeks | varchar | true | false |
thequot | varchar | true | false |
thetenday | varchar | true | false |
thehalfmonth | varchar | true | false |
(10 rows)
Query 20150109_072540_00010_scd3k, FINISHED, 1 node
Splits: 2 total, 2 done (100.00%)
0:00 [10 rows, 2.03KB] [51 rows/s, 10.4KB/s]
presto:default> select * from hive.saledata.tbldate;
dateid | theyearmonth | theyear | themonth | thedate | theweek | theweeks | thequot | thetenday | thehalfmonth
------------+--------------+---------+----------+---------+---------+----------+---------+-----------+--------------
2003-1-1 | 200301 | 2003 | 1 | 1 | 3 | 1 | 1 | 1 | 1
2003-1-2 | 200301 | 2003 | 1 | 2 | 4 | 1 | 1 | 1 | 1
2003-1-3 | 200301 | 2003 | 1 | 3 | 5 | 1 | 1 | 1 | 1
2003-1-4 | 200301 | 2003 | 1 | 4 | 6 | 1 | 1 | 1 | 1
2003-1-5 | 200301 | 2003 | 1 | 5 | 7 | 1 | 1 | 1 | 1
2003-1-6 | 200301 | 2003 | 1 | 6 | 1 | 2 | 1 | 1 | 1
presto:default> select count(*) from hive.saledata.tbldate;
_col0
-------
4383
(1 row)
Query 20150109_072649_00012_scd3k, FINISHED, 1 node
Splits: 2 total, 2 done (100.00%)
0:00 [4.38K rows, 172KB] [23.5K rows/s, 922KB/s]
presto:default>

对比hive使用count(*)查询
hive> use saledata;
hive> desc tbldate;
OK
dateid string
theyearmonth string
theyear string
themonth string
thedate string
theweek string
theweeks string
thequot string
thetenday string
thehalfmonth string
Time taken: 0.075 seconds, Fetched: 10 row(s)
hive> select count(*) from tbldate;
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=
In order to set a constant number of reducers:
set mapreduce.job.reduces=
Starting Job = job_1420787592849_0001, Tracking URL = http://localhost:8088/proxy/application_1420787592849_0001/
Kill Command = /home/hadoop/soft/cdh5.2.0/hadoop-2.5.0-cdh5.2.0/bin/hadoop job -kill job_1420787592849_0001
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2015-01-09 15:27:16,054 Stage-1 map = 0%, reduce = 0%
2015-01-09 15:27:21,318 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.03 sec
2015-01-09 15:27:27,555 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 2.49 sec
MapReduce Total cumulative CPU time: 2 seconds 490 msec
Ended Job = job_1420787592849_0001
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 2.49 sec HDFS Read: 176119 HDFS Write: 5 SUCCESS
Total MapReduce CPU Time Spent: 2 seconds 490 msec
OK
4383
Time taken: 21.025 seconds, Fetched: 1 row(s)
可以看出21s/173ms ≈ 21s/210ms=100倍
TODO...