Hello Flink
Setup
$ wget -O ~/data/gutenberg/hamlet.txt http://www.gutenberg.org/cache/epub/1787/pg1787.txt
$ cd ~/soft/flink-0.7.0-incubating
$ bin/start-local.sh
$ jps -m
18689 JobManager -executionMode local -configDir /home/hadoop/soft/flink-0.7.0-incubating/bin/../conf
17570 DataNode
17794 SecondaryNameNode
17955 ResourceManager
17429 NameNode
18094 NodeManager
$ bin/flink run \
--jarfile ./examples/flink-java-examples-0.7.0-incubating-WordCount.jar \
--arguments file:///home/hadoop/data/gutenberg/hamlet.txt file:///home/hadoop/data/gutenberg/wordcount-result.txt
01/19/2015 14:25:31: Job execution switched to status RUNNING
01/19/2015 14:25:31: CHAIN DataSource (TextInputFormat (file:/home/hadoop/data/gutenberg/hamlet.txt) - UTF-8) ->
FlatMap (org.apache.flink.examples.java.wordcount.WordCount$Tokenizer) -> Combine(SUM(1)) (1/1) switched to SCHEDULED
01/19/2015 14:25:31: CHAIN DataSource (TextInputFormat (file:/home/hadoop/data/gutenberg/hamlet.txt) - UTF-8) ->
FlatMap (org.apache.flink.examples.java.wordcount.WordCount$Tokenizer) -> Combine(SUM(1)) (1/1) switched to DEPLOYING
01/19/2015 14:25:31: CHAIN DataSource (TextInputFormat (file:/home/hadoop/data/gutenberg/hamlet.txt) - UTF-8) ->
FlatMap (org.apache.flink.examples.java.wordcount.WordCount$Tokenizer) -> Combine(SUM(1)) (1/1) switched to RUNNING
01/19/2015 14:25:31: Reduce (SUM(1)) (1/1) switched to SCHEDULED
01/19/2015 14:25:31: Reduce (SUM(1)) (1/1) switched to DEPLOYING
01/19/2015 14:25:31: Reduce (SUM(1)) (1/1) switched to RUNNING
01/19/2015 14:25:32: DataSink(CsvOutputFormat (path: file:/home/hadoop/data/gutenberg/wordcount-result.txt, delimiter: )) (1/1) switched to SCHEDULED
01/19/2015 14:25:32: DataSink(CsvOutputFormat (path: file:/home/hadoop/data/gutenberg/wordcount-result.txt, delimiter: )) (1/1) switched to DEPLOYING
01/19/2015 14:25:32: DataSink(CsvOutputFormat (path: file:/home/hadoop/data/gutenberg/wordcount-result.txt, delimiter: )) (1/1) switched to RUNNING
01/19/2015 14:25:32: CHAIN DataSource (TextInputFormat (file:/home/hadoop/data/gutenberg/hamlet.txt) - UTF-8) ->
FlatMap (org.apache.flink.examples.java.wordcount.WordCount$Tokenizer) -> Combine(SUM(1)) (1/1) switched to FINISHED
01/19/2015 14:25:32: DataSink(CsvOutputFormat (path: file:/home/hadoop/data/gutenberg/wordcount-result.txt, delimiter: )) (1/1) switched to FINISHED
01/19/2015 14:25:32: Reduce (SUM(1)) (1/1) switched to FINISHED
01/19/2015 14:25:32: Job execution switched to status FINISHED
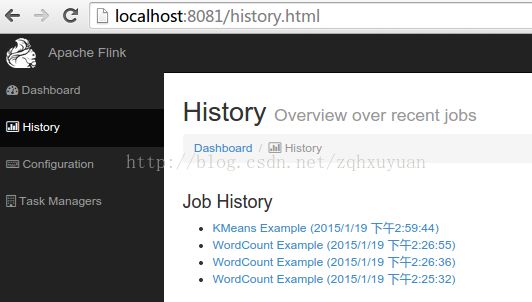
访问 http://localhost:8081/index.html

点击History, 点击倒数第一个的WordCount Example. 当点击Flow Layout上的某个阶段: 在Tasks上会显示这个任务的信息


Run Example
1) 输入数据
$ cd ~/soft/flink-0.7.0-incubating
$ mkdir kmeans && cd kmeans
$ java -cp ../examples/flink-java-examples-*-KMeans.jar \
org.apache.flink.examples.java.clustering.util.KMeansDataGenerator 500 10 0.08
$ cp /tmp/points .
$ cp /tmp/centers .
$ sudo apt-get install python-matplotlib
$ python plotPoints.py points ./points input
$ ll
hadoop@hadoop:~/soft/flink-0.7.0-incubating/kmeans$ ll
-rw-rw-r-- 1 hadoop hadoop 141 1月 19 14:45 centers
-rw-rw-r-- 1 hadoop hadoop 14014 1月 19 14:47 input-plot.pdf
-rw-r----- 1 hadoop hadoop 1626 1月 19 14:40 plotPoints.py
-rw-rw-r-- 1 hadoop hadoop 6211 1月 19 14:45 points
查看生成的input-plot.pdf

$ cd ..
$ bin/start-webclient.sh
查看进程, 多了flink的web进程
$ jps -lm
20559 WebFrontend -configDir /home/hadoop/soft/flink-0.7.0-incubating/bin/../conf
2) Inspect and Run the K-Means Example Program
打开 http://localhost:8080/launch.html 管理页面
① 选择examples下的flink-java-examples-0.7.0-incubating-KMeans.jar
② 填写参数
file:///home/hadoop/soft/flink-0.7.0-incubating/kmeans/points file:///home/hadoop/soft/flink-0.7.0-incubating/kmeans/centers file:///home/hadoop/soft/flink-0.7.0-incubating/kmeans/result 10
③ 点击RunJob
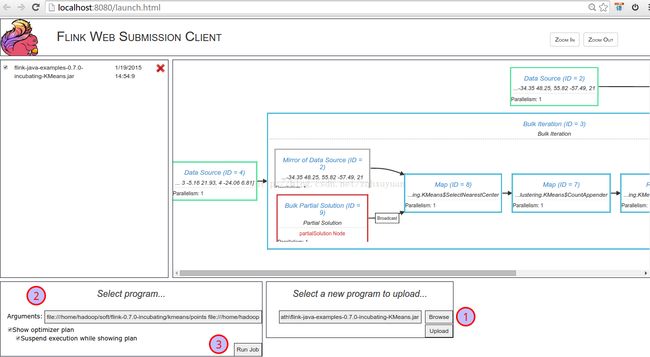
点击Continue

由于数据量很小, 这个几乎是瞬时完成, 所以下面的截图直接来自官网的例子

可以查看history

3) 分析结果
$ cd kmeans
$ python plotPoints.py result ./result clusters
$ ll
-rw-rw-r-- 1 hadoop hadoop 141 1月 19 14:45 centers
-rw-rw-r-- 1 hadoop hadoop 11959 1月 19 15:02 clusters-plot.pdf
-rw-rw-r-- 1 hadoop hadoop 14014 1月 19 14:47 input-plot.pdf
-rw-r----- 1 hadoop hadoop 1626 1月 19 14:40 plotPoints.py
-rw-rw-r-- 1 hadoop hadoop 6211 1月 19 14:45 points
-rw-rw-r-- 1 hadoop hadoop 7198 1月 19 14:59 result
查看新生成的clusters-plot.pdf

4) 停止flink
bin/stop-local.sh
bin/stop-webclient.sh
Flink on YARN
$ cd ~/soft/flink-yarn-0.7.0-incubating
hadoop@hadoop:~/soft/flink-yarn-0.7.0-incubating$ bin/yarn-session.sh -n 1

只要上面的yarn-session没有关闭, 则下面的yarn的Progress就不会结束.

点击TrackingUI的Applicationmaster. Flink on YARN使用的端口是YARN的8088端口. 由于没有job, 所以Jobs Finish=0

提交作业的方式和前面的setup一样, 只不过我们现在是在flink-yarn目录下!
$ cd ~/soft/flink-yarn-0.7.0-incubating
$ bin/flink run \
--jarfile ./examples/flink-java-examples-0.7.0-incubating-WordCount.jar \
--arguments file:///home/hadoop/data/gutenberg/hamlet.txt file:///home/hadoop/data/gutenberg/wordcount-result3.txt

可以在flink on yarn的web页面看到job数量+1

当停掉yarn-session后, yarn web ui显示flink job的progress=100%
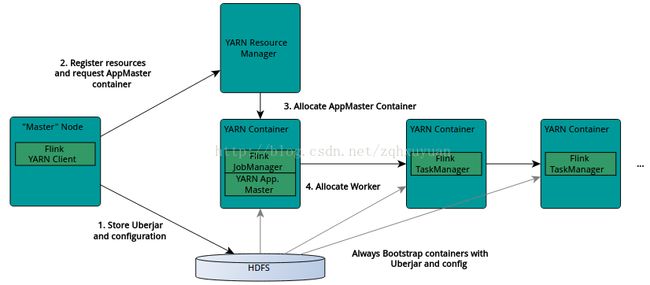
下面是Flink on Yarn的架构图, 描述了Flink如何和Yarn进行交互
When starting a new Flink YARN session, the client first checks if the requested resources (containers and memory) are available. After that, it uploads a jar that contains Flink and the configuration to HDFS (step 1).
The next step of the client is to request (step 2) a YARN container to start the ApplicationMaster (step 3). Since the client registered the configuration and jar-file as a resource for the container, the NodeManager of YARN running on that particular machine will take care of preparing the container (e.g. downloading the files). Once that has finished, the ApplicationMaster(AM) is started.
The JobManager and AM are running in the same container. Once they successfully started, the AM knows the address of the JobManager (its own host). It is generating a new Flink configuration file for the TaskManagers (so that they can connect to the JobManager). The file is also uploaded to HDFS. Additionally, the AM container is also serving Flink's web interface. The ports Flink is using for its services are the standard ports configured by the user + the application id as an offset. This allows users to execute multiple Flink YARN sessions in parallel.
After that, the AM starts allocating the containers for Flink's TaskManagers, which will download the jar file and the modified configuration from the HDFS. Once these steps are completed, Flink is set up and ready to accept Jobs.
顺便扒下官网的System Overview: 可以看到flink在数据获取, 部署方式, API上都由很多接口.
