【一文读懂】Mysql索引原理之环环相扣
MySQL为什么要使用索引?
MySQL读写比例一般是10:1,大部分性能瓶颈在查询,所有优化性能的关键点都在查询,而索引可以有效的提升MySQL的查询性能。
为什么索引能提升查询性能?
索引通过特殊的数据结构和查询方式,能有效减少查询范围,减少IO的参数,从而提升查询效率
究竟什么是索引呢?
数据库索引本质上是一种数据结构(存储结构+算法),目的是为了加快搜索性能
那数据库索引的数据结构是什么样的?
以InnoDb引擎为例,主要支持三种数据结构,B+树、哈希索引、R树:
哈希索引:
实现原理:由索引列来决定存储位置。
优点:检索效率非常高,索引的检索可以一次到位,复杂度为O(1)
缺点:
1.索引无序,无法进行范围查询,只能用作IN,==等查询;无法排序
2.每次都要全表扫描
3.不符合最左缀原则,不能用部分索引建来搜索
4.当哈希值大量重复且数据量非常大时,由于哈希碰撞,查询效率会很低
B+树索引:
实现原理:参考【一文读懂】二叉树,平衡二叉树(AVL),红黑树,B+树的原理
优点:
1.与B-Tree比较,内节点不存储data只存储Key,叶子结点不存储指针,在大数据量情况下,能有效的减少IO次数
2.B+树的查询必须最终找到叶子节点,而B-树只需要找到匹配的元素即可,无论匹配元素是中间节点还是叶子节点。
因此B-树的查找性能不稳定(最好情况是只查根节点,最坏查到叶子节点),而B+树每次查找都是稳定点
3.B-树只能依靠繁琐的中序遍历,而B+树只需要在链表上遍历即可。范围查询更方便
4.B更充分利用磁盘预读
缺点:
精确查询效率不如哈希索引
R树索引:空间索引适用。
数据库索引怎么实现的?
在MySQL中,不同存储引擎对索引的实现方式是不同的,引擎主要有MyISAM(图1)和InnoDB(图2)两种
聚集索引:一种索引,该索引中键值的逻辑顺序决定了表中相应行的物理顺序。
非聚集索引:一种索引,该索引中索引的逻辑顺序与磁盘上行的物理存储顺序不同。相同点:
- 索引的数据结构都是B+Tree
不同点:
- MyISAM索引与数据文件分离,InnoDB数据文件本身就是索引文件
- MyISAM主索引叶结点的data域存放的是数据记录的地址(非聚集索引),InnoDB叶节点存放的则是完整的数据记录(聚集索引)。
- MyISAM辅助索引叶结点的data域存放的是数据记录的地址(和主索引一样), InnoDB的辅助索引data域存储相应记录主键的值。
- MyISAM对主键无要求,InnoDB要求主键最好不要过长(因为每一个辅助索引都引用主键)
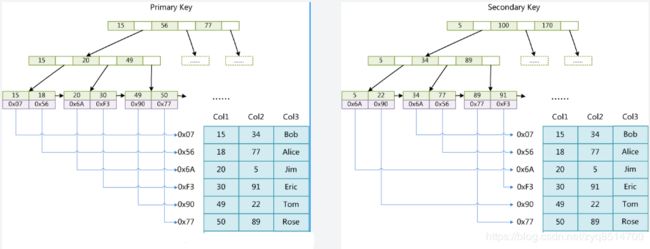
图1 MyIASM主索引(左)和辅助索引(右)
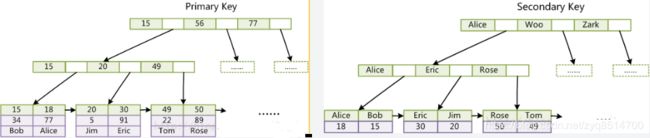
图2 InnoDB主索引(左)和辅助索引(右)
如何确定索引是否执行?
在select语句之前加入explain关键字,通过查看type字段可以确定是否使用索引(为All表示未使用索引),possible_keys列出所有可能使用的索引,key是优化器选择后真正使用的索引

type 常用的类型有: ALL、index、range、 ref、eq_ref、const、system、NULL(从左到右,性能从差到好)
ALL:Full Table Scan, MySQL将遍历全表以找到匹配的行
index: Full Index Scan,index与ALL区别为index类型只遍历索引树
range:只检索给定范围的行,使用一个索引来选择行
ref: 表示上述表的连接匹配条件,即哪些列或常量被用于查找索引列上的值
eq_ref: 类似ref,区别就在使用的索引是唯一索引,对于每个索引键值,表中只有一条记录匹配,简单来说,就是多表连接中使用primary key或者 unique key作为关联条件
const、system: 当MySQL对查询某部分进行优化,并转换为一个常量时,使用这些类型访问。如将主键置于where列表中,MySQL就能将该查询转换为一个常量,system是const类型的特例,当查询的表只有一行的情况下,使用system
NULL: MySQL在优化过程中分解语句,执行时甚至不用访问表或索引,例如从一个索引列里选取最小值可以通过单独索引查找完成。
MySQL如何选择索引?
采用查询优化器
MsSQL不使用索引的可能情况?
- MySQL估计使用索引比全表扫描更慢,则不使用索引
- 复合索引,如果索引列不是复合索引的第一部分,则不使用索引(即不符合最左前缀)
- 如果like是以‘%'开始的,则该列上的索引不会被使用。例如
select * from table_name where key1 like '%a';该查询即使key1上存在索引,也不会被使用。 - 如果列为字符串,则where条件中必须将字符常量值加引号,否则即使该列上存在索引,也不会被使用。
MySQL索引优化规则?
索引创建:
- 如果建立了(a,b)联合索引,就不必再单独建立 a 索引。同理,如果建立了(a,b,c)联合索引,就不必再单独建立 a、(a,b) 索引。
- 存在非等号和等号混合判断条件时,在建索引时,请把等号条件的列前置。如 where a>? and b=?,那么即使 a 的区分度更高,也必须把 b 放在索引的最前列。最左侧查询需求,并不是指 SQL 语句的 where 顺序要和联合索引一致(优化器会自动调整),但是推荐顺序保持一致。select * from table where a<100 and b=10
-
利用覆盖索引来进行查询操作,避免回表。比如下面语句,可以建立索引(a,b,c)覆盖索引(所有数据都在索引里面),避免回表。select id, a from table where b=? and c=?
-
如果有 order by,可以建立联合索引,将order by的字段放在联合索引最后(防止file_sort的情况,影响性能)
-
业务上具有唯一特性的字段,必须建成唯一索引。
-
单表索引建议控制在5个以内,单索引字段数不允许超过5个。
-
尽量使用数字型字段,若只含数值信息的字段尽量不要设计为字符型,这会降低查询和连接的性能,并会增加存储开销。这是因为引擎在处理查询和连接时会逐个比较字符串中每一个字符,而对于数字型而言只需要比较一次就够了。
索引使用:
- 建立索引的列,不允许为 null。应尽量避免在 where 子句中对字段进行 null 值判断;尽量避免在 where 子句中使用!=或<>操作符。
- 范围列可以用到索引(联合索引必须是最左前缀)。但是范围列后面的列无法用到索引,索引最多用于一个范围列。比如联合索引(a,b),在下面语句中,只能a用到索引,b用不到
-
in 和 not in 也要慎用,多值查询一般是走索引的。但能用 between 就不要用 in,也可以考虑用exists代替。
-
不要在SQL操作中计算
-
SQL 性能优化 explain 中的 type:至少要达到 range 级别,要求是 ref 级别,如果可以是 consts 最好。
索引口诀:
全值匹配我最爱,最左前缀要遵守;
带头大哥不能死,中间兄弟不能断;
索引列上少计算,范围之后全失效;
LIKE百分写最右,覆盖索引不写星;
不等空值还有or,索引失效要少用。
送上一波练习题?
https://www.cnblogs.com/developer_chan/p/9223671.html