URL原理、URL编码、URL特殊字符
From: http://blog.csdn.net/chenlycly/article/details/51820727
From: http://blog.csdn.net/zmx729618/article/details/51381655
From: http://www.cnblogs.com/coco1s/p/5038412.html
HTML URL 编码参考手册:https://www.w3cschool.cn/htmltags/html-urlencode.html
http://www.w3school.com.cn/tags/html_ref_urlencode.html
在线url网址编码、解码-BeJSON.com:http://www.bejson.com/enc/urlencode
站长工具 之 URL编码解码:http://tool.chinaz.com/Tools/URLEncode.aspx
通常如果一样东西需要编码,说明这样东西并不适合传输。原因多种多样,如Size过大,包含隐私数据,对于Url来说,之所以要进行编码,是因为Url中有些字符会引起歧义。
例如,Url参数字符串中使用key=value键值对这样的形式来传参,键值对之间以&符号分隔,如/s?q=abc&ie=utf-8。如果你的value字符串中包含了=或者&,那么势必会造成接收Url的服务器解析错误,因此必须将引起歧义的&和=符号进行转义,也就是对其进行编码。
又如,Url 的编码格式采用的是ASCII码,而不是Unicode,这也就是说你不能在Url中包含任何非ASCII字符,例如中文。否则如果客户端浏览器和服务端浏览器支持的字符集不同的情况下,中文可能会造成问题。
Url编码的原则:就是使用安全的字符(没有特殊用途或者特殊意义的可打印字符)去表示那些不安全的字符。
预备知识:URI是统一资源标识的意思,通常我们所说的URL只是URI的一种。
典型URL的格式如下所示。下面提到的URL编码,实际上应该指的是URI编码。
foo://example.com:8042/over/there?name=ferret#nose
\__/ \_______________/\_________/\__________/\__/
| | | | |scheme authority path query fragment
哪些字符需要编码
RFC3986文档规定,URL 中只允许包含英文字母(a-zA-Z)、数字(0-9)、-_.~ 4个特殊字符以及所有保留字符。RFC3986文档对Url的编解码问题做出了详细的建议,指出了哪些字符需要被编码才不会引起Url语义的转变,以及对为什么这些字符需要编码做出了相应的解释。
US-ASCII字符集中没有对应的可打印字符:Url中只允许使用可打印字符。US-ASCII码中的10-7F字节全都表示控制字符,这些字符都不能直接出现在Url中。同时,对于80-FF字节(ISO-8859-1),由于已经超出了US-ACII定义的字节范围,因此也不可以放在Url中。
保留字符:URL 可以划分成若干个组件,协议、主机、路径等。有一些字符(:/?#[]@)是用作分隔不同组件的。
例如:冒号用于分隔协议和主机,/用于分隔主机和路径,?用于分隔路径和查询参数,等等。还有一些字符(!$&'()*+,;=)用于在每个组件中起到分隔作用的,如=用于表示查询参数中的键值对,&符号用于分隔查询多个键值对。当组件中的普通数据包含这些特殊字符时,需要对其进行编码。
RFC3986中指定了以下字符为保留字符:! * ' ( ) ; : @ & = + $ , / ? # [ ]
不安全字符:还有一些字符,当他们直接放在URL中的时候,可能会引起解析程序的歧义。这些字符被视为不安全字符,原因有很多。
- 空格:Url在传输的过程,或者用户在排版的过程,或者文本处理程序在处理Url的过程,都有可能引入无关紧要的空格,或者将那些有意义的空格给去掉。
- 引号以及<>:引号和尖括号通常用于在普通文本中起到分隔Url的作用
- #:通常用于表示书签或者锚点
- %:百分号本身用作对不安全字符进行编码时使用的特殊字符,因此本身需要编码
- {}|\^[]`~:某一些网关或者传输代理会篡改这些字符
需要注意的是,对于Url中的合法字符,编码和不编码是等价的,但是对于上面提到的这些字符,如果不经过编码,那么它们有可能会造成Url语义的不同。因此对于Url而言,只有普通英文字符和数字,特殊字符$-_.+!*'()还有保留字符,才能出现在未经编码的Url之中。其他字符均需要经过编码之后才能出现在Url中。
但是由于历史原因,目前尚存在一些不标准的编码实现。例如对于~符号,虽然RFC3986文档规定,对于波浪符号~,不需要进行Url编码,但是还是有很多老的网关或者传输代理会进行编码。
URL编码遵循下列规则: 每对name/value由&;符分开;每对来自表单的name/value由=符分开。如果用户没有输入值给这个name,那么这个name还是出现,只是无值。任何特殊的字符(就是那些不是简单的七位ASCII,如汉字)将以百分符%用十六进制编码,当然也包括象 =,&;,和 % 这些特殊的字符。其实url编码就是一个字符ascii码的十六进制。不过稍微有些变动,需要在前面加上“%”。比如“\”,它的ascii码是92,92的十六进制是5c,所以“\”的url编码就是%5c。那么汉字的url编码呢?很简单,看例子:“胡”的ascii码是-17670,十六进制是BAFA,url编码是“%BA%FA”。
防止sql注入。URL编码平时是用不到的,因为IE会自动将输入到地址栏的非数字字母转换为url编码。曾有人提出数据库名字里带上“#”以防止被下载,因为IE遇到#就会忽略后面的字母。破解方法很简单——用url编码%23替换掉#。也可以使用 “双URL编码”
如何对 URL 中的非法字符进行编码
URL 编码通常也被称为 百分号编码(Url Encoding,also known as percent-encoding),是因为它的编码方式非常简单,使用%百分号加上两位的字符——0123456789ABCDEF——代表一个字节的十六进制形式。Url编码默认使用的字符集是US-ASCII。例如a在US-ASCII码中对应的字节是0x61,那么Url编码之后得到的就是%61,我们在地址栏上输入http://g.cn/search?q=%61%62%63,实际上就等同于在google上搜索abc了。又如@符号在ASCII字符集中对应的字节为0x40,经过Url编码之后得到的是%40。
对于非ASCII字符,需要使用ASCII字符集的超集进行编码得到相应的字节,然后对每个字节执行百分号编码。对于Unicode字符,RFC文档建议使用utf-8对其进行编码得到相应的字节,然后对每个字节执行百分号编码。如"中文"使用UTF-8字符集得到的字节为0xE4 0xB8 0xAD 0xE6 0x96 0x87,经过Url编码之后得到"%E4%B8%AD%E6%96%87"。
如果某个字节对应着ASCII字符集中的某个非保留字符,则此字节无需使用百分号表示。例如"Url编码",使用UTF-8编码得到的字节是0x55 0x72 0x6C 0xE7 0xBC 0x96 0xE7 0xA0 0x81,由于前三个字节对应着ASCII中的非保留字符"Url",因此这三个字节可以用非保留字符"Url"表示。最终的Url编码可以简化成"Url%E7%BC%96%E7%A0%81" ,当然,如果你用"%55%72%6C%E7%BC%96%E7%A0%81"也是可以的。
由于历史的原因,有一些Url编码实现并不完全遵循这样的原则,下面会提到。
Javascript中的escape, encodeURI和encodeURIComponent的区别
JavaScript中提供了3对函数用来对Url编码以得到合法的Url,它们分别是escape / unescape, encodeURI / decodeURI和encodeURIComponent / decodeURIComponent。由于解码和编码的过程是可逆的,因此这里只解释编码的过程。
这三个编码的函数——escape,encodeURI,encodeURIComponent——都是用于将不安全不合法的Url字符转换为合法的Url字符表示,它们有以下几个不同点。
安全字符不同:
下面列出了这三个函数的安全字符(即函数不会对这些字符进行编码)
- escape(69个):*/@+-._0-9a-zA-Z
- encodeURI(82个):!#$&'()*+,/:;=?@-._~0-9a-zA-Z
- encodeURIComponent(71个):!'()*-._~0-9a-zA-Z
兼容性不同:escape函数是从Javascript 1.0的时候就存在了,其他两个函数是在Javascript 1.5才引入的。但是由于Javascript 1.5已经非常普及了,所以实际上使用encodeURI和encodeURIComponent并不会有什么兼容性问题。
对Unicode字符的编码方式不同:这三个函数对于ASCII字符的编码方式相同,均是使用百分号+两位十六进制字符来表示。但是对于Unicode字符,escape的编码方式是%uxxxx,其中的xxxx是用来表示unicode字符的4位十六进制字符。这种方式已经被W3C废弃了。但是在ECMA-262标准中仍然保留着escape的这种编码语法。encodeURI和encodeURIComponent则使用UTF-8对非ASCII字符进行编码,然后再进行百分号编码。这是RFC推荐的。因此建议尽可能的使用这两个函数替代escape进行编码。
适用场合不同:encodeURI被用作对一个完整的URI进行编码,而encodeURIComponent被用作对URI的一个组件进行编码。从上面提到的安全字符范围表格来看,我们会发现,encodeURIComponent编码的字符范围要比encodeURI的大。我们上面提到过,保留字符一般是用来分隔URI组件(一个URI可以被切割成多个组件,参考预备知识一节)或者子组件(如URI中查询参数的分隔符),如:号用于分隔scheme和主机,?号用于分隔主机和路径。由于encodeURI操纵的对象是一个完整的的URI,这些字符在URI中本来就有特殊用途,因此这些保留字符不会被encodeURI编码,否则意义就变了。
组件内部有自己的数据表示格式,但是这些数据内部不能包含有分隔组件的保留字符,否则就会导致整个URI中组件的分隔混乱。因此对于单个组件使用encodeURIComponent,需要编码的字符就更多了。
表单提交
当Html的表单被提交时,每个表单域都会被Url编码之后才在被发送。由于历史的原因,表单使用的Url编码实现并不符合最新的标准。例如对于空格使用的编码并不是%20,而是+号,如果表单使用的是Post方法提交的,我们可以在HTTP头中看到有一个Content-Type的header,值为application/x-www-form-urlencoded。大部分应用程序均能处理这种非标准实现的Url编码,但是在客户端Javascript中,并没有一个函数能够将+号解码成空格,只能自己写转换函数。还有,对于非ASCII字符,使用的编码字符集取决于当前文档使用的字符集。例如我们在Html头部加上
这样浏览器就会使用gb2312去渲染此文档(注意,当HTML文档中没有设置此meta标签,则浏览器会根据当前用户喜好去自动选择字符集,用户也可以强制当前网站使用某个指定的字符集)。当提交表单时,Url编码使用的字符集就是gb2312。
之前在使用Aptana(为什么专指aptana下面会提到)遇到一个很迷惑的问题,就是在使用encodeURI的时候,发现它编码得到的结果和我想的很不一样。下面是我的示例代码:
运行结果输出%E6%B6%93%EE%85%9F%E6%9E%83。显然这并不是使用UTF-8字符集进行Url编码得到的结果(在Google上搜索"中文",Url中显示的是%E4%B8%AD%E6%96%87)。
所以我当时就很质疑,难道encodeURI还跟页面编码有关,但是我发现,正常情况下,如果你使用gb2312进行Url编码也不会得到这个结果的才是。后来终于被我发现,原来是页面文件存储使用的字符集和Meta标签中指定的字符集不一致导致的问题。Aptana的编辑器默认情况下使用UTF-8字符集。也就是说这个文件实际存储的时候使用的是UTF-8字符集。但是由于Meta标签中指定了gb2312,这个时候,浏览器就会按照gb2312去解析这个文档,那么自然在"中文"这个字符串这里就会出错,因为"中文"字符串用UTF-8编码过后得到的字节是0xE4 0xB8 0xAD 0xE6 0x96 0x87,这6个字节又被浏览器拿gb2312去解码,那么就会得到另外三个汉字"涓枃"(GBK中一个汉字占两个字节),这三个汉字在传入encodeURI函数之后得到的结果就是%E6%B6%93%EE%85%9F%E6%9E%83。因此,encodeURI使用的还是UTF-8,并不会受到页面字符集的影响。
对于包含中文的Url的处理问题,不同浏览器有不同的表现。例如对于IE,如果你勾选了高级设置"总是以UTF-8发送Url",那么Url中的路径部分的中文会使用UTF-8进行Url编码之后发送给服务端,而查询参数中的中文部分使用系统默认字符集进行Url编码。为了保证最大互操作性,建议所有放到Url中的组件全部显式指定某个字符集进行Url编码,而不依赖于浏览器的默认实现。
另外,很多HTTP监视工具或者浏览器地址栏等在显示Url的时候会自动将Url进行一次解码(使用UTF-8字符集),这就是为什么当你在Firefox中访问Google搜索中文的时候,地址栏显示的Url包含中文的缘故。但实际上发送给服务端的原始Url还是经过编码的。你可以在地址栏上使用Javascript访问location.href就可以看出来了。在研究Url编解码的时候千万别被这些假象给迷惑了。
URL 与 URI
很多人会混淆这两个名词。
URL:(Uniform/Universal Resource Locator 的缩写,统一资源定位符)。
URI:(Uniform Resource Identifier 的缩写,统一资源标识符)。
关系:
URI 属于 URL 更低层次的抽象,一种字符串文本标准。
就是说,URI 属于父类,而 URL 属于 URI 的子类。URL 是 URI 的一个子集。
二者的区别:
URI 表示请求服务器的路径,定义这么一个资源。而 URL 同时说明要如何访问这个资源(http://)。
端口 与 URL 标准格式
何为端口?端口(Port),相当于一种数据的传输通道。用于接受某些数据,然后传输给相应的服务,而电脑将这些数据处理后,再将相应的回复通过开启的端口传给对方。
端口的作用:因为 IP 地址与网络服务的关系是一对多的关系。所以实际上因特网上是通过 IP 地址加上端口号来区分不同的服务的。
端口是通过端口号来标记的,端口号只有整数,范围是从 0 到 65535。
URL 标准格式
通常而言,我们所熟悉的 URL 的常见定义格式为:
scheme://host[:port#]/path/.../[;url-params][?query-string][#anchor]
scheme //有我们很熟悉的http、https、ftp以及著名的ed2k,迅雷的thunder等。
host //HTTP服务器的IP地址或者域名
port# //HTTP服务器的默认端口是80,这种情况下端口号可以省略。如果使用了别的端口,必须指明,例如tomcat的默认端口是8080 http://localhost:8080/
path //访问资源的路径
url-params //所带参数
query-string //发送给http服务器的数据
anchor //锚点定位利用 标签自动解析 url
开发当中一个很常见的场景是,需要从 URL 中提取一些需要的元素,譬如 host 、 请求参数等等。
通常的做法是写正则去匹配相应的字段,当然,这里要安利下述这种方法,来自 James 的 blog,原理是动态创建一个 a 标签,利用浏览器的一些原生方法及一些正则(为了健壮性正则还是要的),完美解析 URL ,获取我们想要的任意一个部分。
代码如下:
// This function creates a new anchor element and uses location
// properties (inherent) to get the desired URL data. Some String
// operations are used (to normalize results across browsers).
function parseURL(url) {
var a = document.createElement('a');
a.href = url;
return {
source: url,
protocol: a.protocol.replace(':',''),
host: a.hostname,
port: a.port,
query: a.search,
params: (function(){
var ret = {},
seg = a.search.replace(/^\?/,'').split('&'),
len = seg.length, i = 0, s;
for (;iUsage 使用方法:
var myURL = parseURL('http://abc.com:8080/dir/index.html?id=255&m=hello#top');
myURL.file; // = 'index.html'
myURL.hash; // = 'top'
myURL.host; // = 'abc.com'
myURL.query; // = '?id=255&m=hello'
myURL.params; // = Object = { id: 255, m: hello }
myURL.path; // = '/dir/index.html'
myURL.segments; // = Array = ['dir', 'index.html']
myURL.port; // = '8080'
myURL.protocol; // = 'http'
myURL.source; // = 'http://abc.com:8080/dir/index.html?id=255&m=hello#top'利用上述方法,即可解析得到 URL 的任意部分。
URL 编码
为什么要进行URL编码?通常如果一样东西需要编码,说明这样东西并不适合直接进行传输。
1、会引起歧义:例如 URL 参数字符串中使用 key=value 这样的键值对形式来传参,键值对之间以 & 符号分隔,如 ?postid=5038412&t=1450591802326,服务器会根据参数串的 & 和 = 对参数进行解析,如果 value 字符串中包含了 = 或者 & ,如宝洁公司的简称为P&G,假设需要当做参数去传递,那么可能URL所带参数可能会是这样 ?name=P&G&t=1450591802326,因为参数中多了一个&势必会造成接收 URL 的服务器解析错误,因此必须将引起歧义的 & 和 = 符号进行转义, 也就是对其进行编码。
2、非法字符:又如,URL 的编码格式采用的是 ASCII 码,而不是 Unicode,这也就是说你不能在 URL 中包含任何非 ASCII 字符,例如中文。否则如果客户端浏览器和服务端浏览器支持的字符集不同的情况下,中文可能会造成问题。
那么如何编码?如下:
escape 、 encodeURI 、encodeURIComponent
escape()
首先想声明的是,W3C把这个函数废弃了,身为一名前端如果还用这个函数是要打脸的。
escape只是对字符串进行编码(而其余两种是对URL进行编码),与URL编码无关。编码之后的效果是以 %XX 或者 %uXXXX 这种形式呈现的。它不会对 ASCII字符、数字 以及 @ * / + 进行编码。
根据 MDN 的说明,escape 应当换用为 encodeURI 或 encodeURIComponent;unescape 应当换用为 decodeURI 或 decodeURIComponent。escape 应该避免使用。举例如下:
encodeURI('https://www.baidu.com/ a b c')
// "https://www.baidu.com/%20a%20b%20c"
encodeURIComponent('https://www.baidu.com/ a b c')
// "https%3A%2F%2Fwww.baidu.com%2F%20a%20b%20c"
//而 escape 会编码成下面这样,eocode 了冒号却没 encode 斜杠,十分怪异,故废弃之
escape('https://www.baidu.com/ a b c')
// "https%3A//www.baidu.com/%20a%20b%20c"
encodeURI()
encodeURI() 是 Javascript 中真正用来对 URL 编码的函数。它着眼于对整个URL进行编码。
encodeURI("http://www.cnblogs.com/season-huang/some other thing");
//"http://www.cnblogs.com/season-huang/some%20other%20thing";编码后变为上述结果,可以看到空格被编码成了%20,而斜杠 / ,冒号 : 并没有被编码。是的,它用于对整个 URL 直接编码,不会对 ASCII字母 、数字 、 ~ ! @ # $ & * ( ) = : / , ; ? + ' 进行编码。
encodeURI("~!@#$&*()=:/,;?+'")
// ~!@#$&*()=:/,;?+'
encodeURIComponent()
嘿,有的时候,我们的 URL 长这样子,请求参数中带了另一个 URL :
var URL = "http://www.a.com?foo=http://www.b.com?t=123&s=456";直接进行 encodeURI 显然是不行的。因为 encodeURI 不会对冒号 : 及斜杠 / 进行转义,那么就会出现上述所说的服务器接受到之后解析会有歧义。
encodeURI(URL)
// "http://www.a.com?foo=http://www.b.com?t=123&b=456"这个时候,就该用到 encodeURIComponent() 。它的作用是对 URL 中的参数进行编码,记住是对参数,而不是对整个 URL 进行编码。
因为它仅仅不对 ASCII字母、数字 ~ ! * ( ) ' 进行编码。
错误的用法:
var URL = "http://www.a.com?foo=http://www.b.com?t=123&s=456";
encodeURIComponent(URL);
// "http%3A%2F%2Fwww.a.com%3Ffoo%3Dhttp%3A%2F%2Fwww.b.com%3Ft%3D123%26s%3D456"
// 错误的用法,看到第一个 http 的冒号及斜杠也被 encode 了正确的用法:encodeURIComponent() 着眼于对单个的参数进行编码:
var param = "http://www.b.com?t=123&s=456"; // 要被编码的参数
URL = "http://www.a.com?foo="+encodeURIComponent(param);
//"http://www.a.com?foo=http%3A%2F%2Fwww.b.com%3Ft%3D123%26s%3D456"利用上述的使用标签解析 URL 以及根据业务场景配合 encodeURI() 与 encodeURIComponent() 便能够很好的处理 URL 的编码问题。
应用场景最常见的一个是手工拼接 URL 的时候,对每对 key-value 用 encodeURIComponent 进行转义,再进行传输。
ASCII码表可以看成由三部分组成:
第一部分:非打印的控制字符。由00H到1FH共32个,一般用来通讯或作为控制之用。有些可以显示在屏幕上,有些则不能显示,但能看到其效果(如换行、退格).如下表:
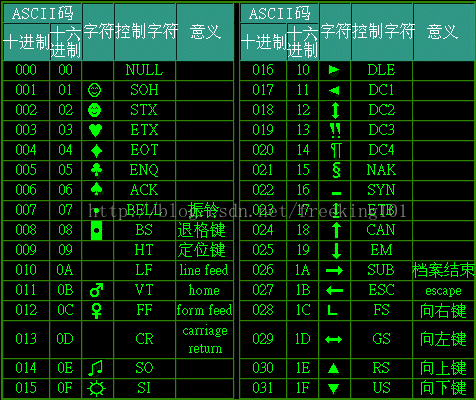
第二部分:打印字符。由20H到7FH共96个,这95个字符是用来表示阿拉伯数字、英文字母大小写和下划线、括号等符号,都可以显示在屏幕上.如下表:

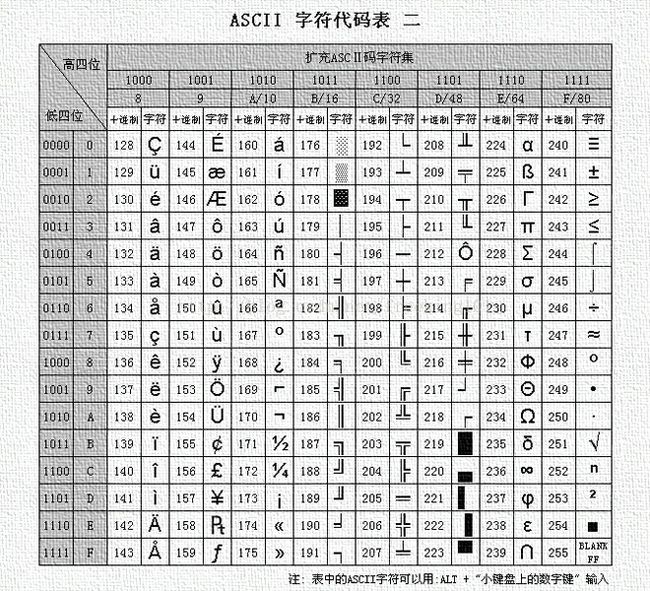
第三部分:扩展 ASCII 打印字符。由80H到0FFH共128个字符,一般称为"扩充字符",这128个扩充字符是由IBM制定的,并非标准的ASCII码.这些字符是用来表示框线、音标和其它欧洲非英语系的字母。
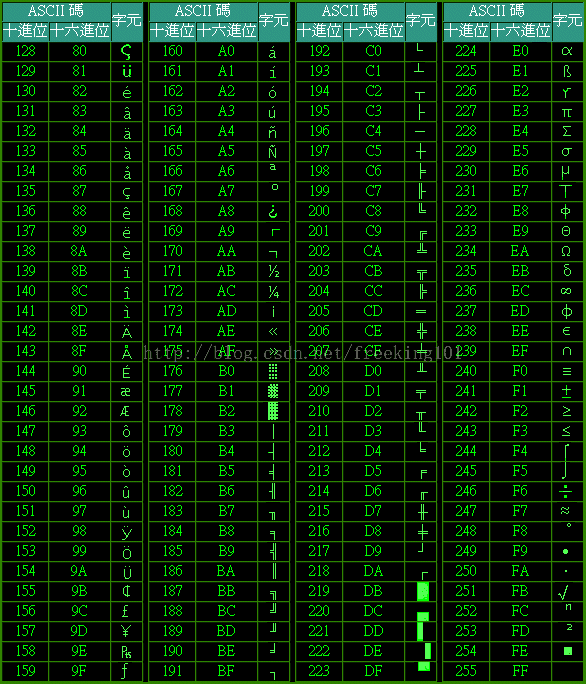
ASCII 表 1

ASCII 表 2
一、问题的由来
问题:当url地址中包含&、+、%等特殊字符(主要是传递参数时,参数的内容中包含这些字符)时,地址无效。比如http://10.190.0.0:108/doc/test+desc2.bmp,若文件名中出现+/&等特殊字符,后台报404错误,即web服务器找不到页面或者资源。
-------------------------------------------------------------------------------------------------------------------------------------
URL就是网址,只要上网,就一定会用到。

一般来说,URL只能使用英文字母、阿拉伯数字和某些标点符号,不能使用其他文字和符号。比如,世界上有英文字母的网址“http://www.abc.com”,但是没有希腊字母的网址“http://www.aβγ.com”(读作阿尔法-贝塔-伽玛.com)。这是因为网络标准RFC 1738做了硬性规定:
"...Only alphanumerics [0-9a-zA-Z], the special characters "$-_.+!*'()," [not including the quotes - ed], and reserved characters used for their reserved purposes may be used unencoded within a URL."
“只有字母和数字[0-9a-zA-Z]、一些特殊符号“$-_.+!*'(),”[不包括双引号]、以及某些保留字,才可以不经过编码直接用于URL。”
这意味着,如果URL中有汉字,就必须编码后使用。但是麻烦的是,RFC 1738没有规定具体的编码方法,而是交给应用程序(浏览器)自己决定。这导致“URL编码”成为了一个混乱的领域。
在使用url进行参数传递时,经常会传递一些中文名(或含有特殊字符)的参数或URL地址,在后台处理时会发生转换错误。这些特殊符号在URL中是不能直接传递的,如果要在URL中传递这些特殊符号,那么就要使用他们的编码了。编码的格式为:%加字符的ASCII码,即一个百分号%,后面跟对应字符的ASCII(16进制)码值。例如空格的编码值是"%20"。下表中列出了一些URL特殊符号及编码。
| 序号 | 特殊字符 | 含义 | 十六进制值 |
| 1. | + | URL 中+号表示空格 | %2B |
| 2. | 空格 | URL中的空格可以用+号或者编码 | %20 |
| 3. | / | 分隔目录和子目录 | %2F |
| 4. | ? | 分隔实际的 URL 和参数 | %3F |
| 5. | % | 指定特殊字符 | %25 |
| 6. | # | 表示书签 | %23 |
| 7. | & | URL 中指定的参数间的分隔符 | %26 |
| 8. | = | URL 中指定参数的值 | %3D |
例:要传递字符串“this%is#te=st&o k?+/”作为参数t传给te.asp,则URL可以是:
te.asp?t=this%is#te=st&o k?+/ 或者
te.asp?t=this%is#te=st&o+k?+/ (空格可以用 或+代替)
java中URL 的编码和解码函数
java.net.URLEncoder.encode(String s)和java.net.URLDecoder.decode(String s);
在javascript 中URL 的编码和解码函数
escape(String s)和(String s) ;
如果使用escape()函数,汉字也会转为乱码。后来就写了一段js重新实现escape()的功能,这里拿#为例子来说明一下:(其他符号同)
function encodeValue(objValue)
{
if(objValue.indexOf("#")!= -1)
{
objValue=objValue.replace("#","#");
objValue=encodeValue(objValue);
}
return objValue;
}最后说一点:在url中中如果得遇到#会自动转成#,这样 request.getParameter("参数")就可以得到正确的结果。
下面就让我们看看,“URL编码”到底有多混乱。我会依次分析四种不同的情况,在每一种情况中,浏览器的URL编码方法都不一样。把它们的差异解释清楚之后,我再说如何用JavaScript找到一个统一的编码方法。
二、情况1:网址路径中包含汉字
打开IE(我用的是8.0版),输入网址“http://zh.wikipedia.org/wiki/春节”。注意,“春节”这两个字此时是网址路径的一部分。

查看HTTP请求的头信息,会发现IE实际查询的网址是“http://zh.wikipedia.org/wiki/%E6%98%A5%E8%8A%82”。也就是说,IE自动将“春节”编码成了“%E6%98%A5%E8%8A%82”。

我们知道,“春”和“节”的utf-8编码分别是“E6 98 A5”和“E8 8A 82”,因此,“%E6%98%A5%E8%8A%82”就是按照顺序,在每个字节前加上%而得到的。
在Firefox中测试,也得到了同样的结果。所以,结论1就是,网址路径的编码,用的是utf-8编码。
三、情况2:查询字符串包含汉字
在IE中输入网址“http://www.baidu.com/s?wd=春节”。注意,“春节”这两个字此时属于查询字符串,不属于网址路径,不要与情况1混淆。

查看HTTP请求的头信息,会发现IE将“春节”转化成了一个乱码。

切换到十六进制方式,才能清楚地看到,“春节”被转成了“B4 BA BD DA”。
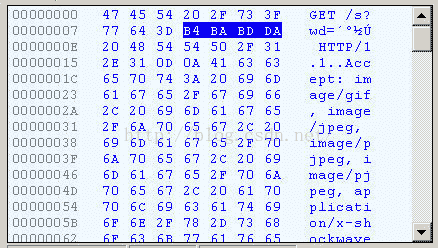
我们知道,“春”和“节”的GB2312编码(我的操作系统“Windows XP”中文版的默认编码)分别是“B4 BA”和“BD DA”。因此,IE实际上就是将查询字符串,以GB2312编码的格式发送出去。
Firefox的处理方法,略有不同。它发送的HTTP Head是“wd=%B4%BA%BD%DA”。也就是说,同样采用GB2312编码,但是在每个字节前加上了%。
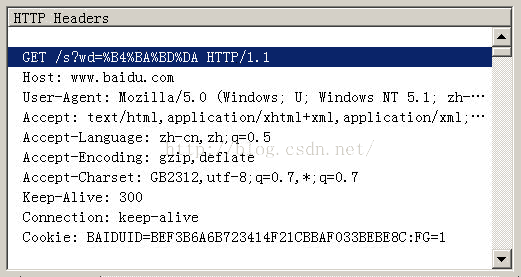
所以,结论2就是,查询字符串的编码,用的是操作系统的默认编码。
四、情况3:Get方法生成的URL包含汉字
前面说的是直接输入网址的情况,但是更常见的情况是,在已打开的网页上,直接用Get或Post方法发出HTTP请求。
根据台湾中兴大学吕瑞麟老师的试验,这时的编码方法由网页的编码决定,也就是由HTML源码中字符集的设定决定。
如果上面这一行最后的charset是UTF-8,则URL就以UTF-8编码;如果是GB2312,URL 就以GB2312编码。
举例来说,百度是GB2312编码,Google是UTF-8编码。因此,从它们的搜索框中搜索同一个词“春节”,生成的查询字符串是不一样的。
百度生成的是%B4%BA%BD%DA,这是GB2312编码。

Google生成的是%E6%98%A5%E8%8A%82,这是UTF-8编码。

所以,结论3就是,GET和POST方法的编码,用的是网页的编码。
五、情况4:Ajax调用的URL包含汉字
前面三种情况都是由浏览器发出HTTP请求,最后一种情况则是由Javascript生成HTTP请求,也就是Ajax调用。还是根据吕瑞麟老师的文章,在这种情况下,IE和Firefox的处理方式完全不一样。
举例来说,有这样两行代码:
url = url + "?q=" +document.myform.elements[0].value; // 假定用户在表单中提交的值是“春节”这两个字
http_request.open('GET', url, true);
那么,无论网页使用什么字符集,IE传送给服务器的总是“q=%B4%BA%BD%DA”,而Firefox传送给服务器的总是“q=%E6%98%A5%E8%8A%82”。也就是说,在Ajax调用中,IE总是采用GB2312编码(操作系统的默认编码),而Firefox总是采用utf-8编码。这就是我们的结论4。
六、Javascript函数:escape()
好了,到此为止,四种情况都说完了。
假定前面你都看懂了,那么此时你应该会感到很头痛。因为,实在太混乱了。不同的操作系统、不同的浏览器、不同的网页字符集,将导致完全不同的编码结果。如果程序员要把每一种结果都考虑进去,是不是太恐怖了?有没有办法,能够保证客户端只用一种编码方法向服务器发出请求?
回答是有的,就是使用Javascript先对URL编码,然后再向服务器提交,不要给浏览器插手的机会。因为Javascript的输出总是一致的,所以就保证了服务器得到的数据是格式统一的。
Javascript语言用于编码的函数,一共有三个,最古老的一个就是escape()。虽然这个函数现在已经不提倡使用了,但是由于历史原因,很多地方还在使用它,所以有必要先从它讲起。
实际上,escape()不能直接用于URL编码,它的真正作用是返回一个字符的Unicode编码值。比如“春节”的返回结果是%u6625%u8282,也就是说在Unicode字符集中,“春”是第6625个(十六进制)字符,“节”是第8282个(十六进制)字符。

它的具体规则是,除了ASCII字母、数字、标点符号“@ * _ + - . /”以外,对其他所有字符进行编码。在\u0000到\u00ff之间的符号被转成%xx的形式,其余符号被转成%uxxxx的形式。对应的解码函数是unescape()。
所以,“Hello World”的escape()编码就是“Hello%20World”。因为空格的Unicode值是20(十六进制)。

还有两个地方需要注意。
首先,无论网页的原始编码是什么,一旦被Javascript编码,就都变为unicode字符。也就是说,Javascipt函数的输入和输出,默认都是Unicode字符。这一点对下面两个函数也适用。

其次,escape()不对“+”编码。但是我们知道,网页在提交表单的时候,如果有空格,则会被转化为+字符。服务器处理数据的时候,会把+号处理成空格。所以,使用的时候要小心。
七、Javascript函数:encodeURI()
encodeURI()是Javascript中真正用来对URL编码的函数。
它着眼于对整个URL进行编码,因此除了常见的符号以外,对其他一些在网址中有特殊含义的符号“; / ? : @ & = + $ , #”,也不进行编码。编码后,它输出符号的utf-8形式,并且在每个字节前加上%。

它对应的解码函数是decodeURI()。

需要注意的是,它不对单引号'编码。
八、Javascript函数:encodeURIComponent()
最后一个Javascript编码函数是encodeURIComponent()。与encodeURI()的区别是,它用于对URL的组成部分进行个别编码,而不用于对整个URL进行编码。
因此,“; / ? : @ & = + $ , #”,这些在encodeURI()中不被编码的符号,在encodeURIComponent()中统统会被编码。至于具体的编码方法,两者是一样。

它对应的解码函数是decodeURIComponent()。