简介
在java的包java.util和java.util.concurrent里面定义了java的集合类框架。我们大部分日常使用到的数据结构都可以在这里找到一个对应的实现。在以往的学习过程中可能会接触过一些具体的结构。但是对于java集合类框架来说,他里面包含有哪些类别的结构呢?对于不同的结构,他们分别适用于哪些应用场景?集合类框架中这些类之间是否有着某种关系呢?在这里,我们尝试对所有这些集合类做一个总结。
总体结构
从总体来看,我们可以将集合类划分为两个大的部分。一种是可以按照一定顺序进行迭代访问的集合类。一种是通过名值对的映射建立关系进行访问的集合类。这两种集合类型分别构成了不同的类继承结构。对于可以迭代访问的集合类来说,他们主要的接口定义关系如下图所示:
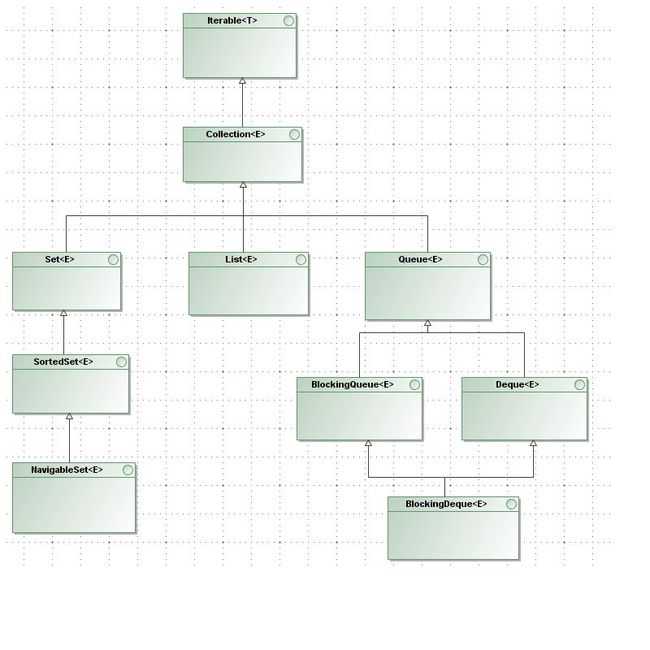
从前面的定义结构图我们可以看到。对于这个结构里面的所有接口,他们都继承自接口Iterable。而Iterable接口定义了用于迭代访问的协议。从某个角度来说,这也是为了方便我们后续可以使用foreach的方式来遍历这里所有集合类的元素。Iterable接口也和Iterator设计模式有紧密的关系。关于他们关系的描述详情可以参考我的另外一篇文章。 对于其他常见的几种类型,比如说Set, List, Queue等都是继承了Collection接口。关于这几种具体的类型我们在后续部分会详细介绍。
除了我们上述提到的可以迭代遍历的数据结构类型以外,我们还有一种就是名值对的结构,主要是继承自Map接口:
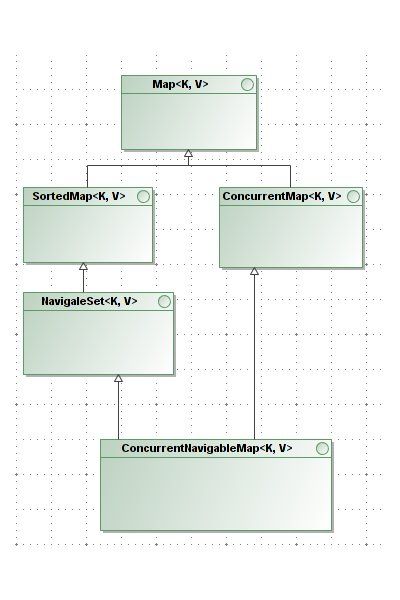
我们很多常用的数据结构,比如说HashMap, TreeMap, HashSet, TreeSet都是继承自这一系列接口。下面,我们再针对每个类别做一个更加详细的分析。
Collection
Collection接口是所有后续集合类型的一个公共抽象定义。它本身没有一个直接的实现,更多的是各种不同的集合类型在它的基础上继承了更多特殊的特性并做了一个实现。Collection接口里主要定义了一些作为集合类型比较通用的方法,比如说size, isEmpty, add, remove等。作为集合类型比较通用的一个定义,它主要用在一些需要比较高级别抽象的地方。比如说我们需要可以对所有集合类型进行通用操作。
Set
Set定义的是数学意义上的集合类型,通常里面的元素是要求不能重复的。它定义的系列类结构如下图:
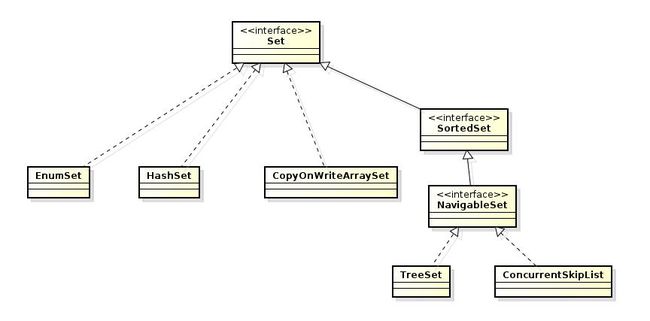
在常用的集合类型中,HashSet, TreeSet等具体的实现往往不一样。比如说HashSet本身的实现是引用了HashMap作为内部的元素。如果我们仔细检查他们的结构实现,会发现有的类型我们也可以通过foreach的循环来遍历。这是因为他们有的在实现Set定义接口的范围同时也继承了实现Collection接口的部分。可以说是两者兼有之。
在上面这些集合类型中,基于Hash表实现的主要有HashSet, LinkedHashSet。基于红黑树实现的有TreeSet.另外,CopyOnWriteArraySet内部的实现是采用了一个CopyOnWriteArrayList,这种数据结构有一个比较有意思的实现。对它调用某些增删元素的方法会产生一个全新的对象。这充分利用了immutable对象的实现思路,在并行程序的开发中有一定的应用。
List
List类型的数据结构算是我们平时接触最多而且看起来最简单的数据结构类型。最常用的两种是ArrayList和LinkedList,也就是我们常说的线性表和链表。线性表的结构一般如下图:

对于线性表结构来说,它对于元素的随机访问比较快。对于表中间任意一个元素的访问,只需要映射到索引下标就可以了。但是,由于要保证线性表的连贯性,如果删除了表中间的元素,则需要对表进行元素移动,从而影响到它的执行效率。典型的ArrayList除了上述的特性以外还有一个比较显著的特点就是它可以根据需要自动增长。就是说,我们新建一个List对象的时候它有一个默认的长度,但是当我们往里面添加元素一直到这个表满了,则ArrayList会自动将自己的容量翻倍,再将元素放到这个新的列表里。
另外一种典型的List就是链表,它的结构如下图:

在链表中,我们对一个元素的访问一般是需要从头到尾的去遍历。只有找到需要操作的成员才能进行操作。所以我们对链表元素进行随机访问时效率会比较慢。不过对于元素的增删操作则比较快。因为只需要调整链表指针就可以了。我们可以根据需要选择合适的List数据类型。在JDK的内部实现里没有直接提供一个单链表的实现,LinkedList实际上是一个双向链表。关于ArrayList和LinkedList的详细实现分析可以参照我的这篇文章。
除了我们提到的这两种线性表结构,我们以前学习到的Stack, Queue等数学结构,很多也是内部采用线性表结构。比如说Stack内部实现是采用了Vector,而LinkedList本身也继承了Queue接口,提供了一个Queue的实现。这些详细的讨论也可以参考我的Stack分析和Queue分析文章。
Queue
对于Queue类型的数据结构来说,他本身的特性是要满足先进先出。它可以分为单队列和双端队列,具体的实现可以是数组也可以是链表。几个典型的Queue相关的类关系图如下:

最常见的几种Queue的数据类型有LinkedList, ArrayDeque, PriorityQueue。他们都最终实现了Queue接口。不过PriorityQueue稍微特殊一点,它本身是实现一个排序效果的队列。关于PriorityQueue的分析可以参考我另外一篇对于它源代码的分析文章。
Map
Map类型的数据结构重点在于一个名值对的集合体。它本身要保证里面有一个名字的键值作为元素的唯一识别,并关联对应的值。所以,如果我们去查看Map的的定义,里面会有很多关于键值和对应值的操作,比如说containsKey, containsValue,V get(Object key), V put(K key, V value)等方法。我们常用的HashTable, HashMap, TreeMap, ConcurrentHashMap都是对应Map接口的具体实现。
其中HashTable和HashMap是一种经典的哈希表实现,在很多面试的过程中也会讨论到这些问题。HashMap内部实现是使用一个数组,每个数组的元素又构成了一个链表结构。这可以说是教科书上定义的哈希表的一个经典实现。另外TreeMap的实现是使用了数据结构里面的红黑树,它可以保证里面所有的元素访问操作都是排序的,而且操作的时间复杂度都是在logN的级别。而对于ConcurrentHashMap来说,它内部是采用了分段,并对不同段采用独立的锁的机制进行设计,尽可能保证足够大的并行度。对于HashMap和TreeMap的具体实现分析也可以参照我的几篇文章(HashMap篇,TreeMap篇)。后续还会对ConcurrentHashMap的实现做一个详细分析。
总结
在这里,我们针对Java集合类中间主要的几种类型都做了一个描述和分析。按照一种不太严格的划分,Java集合类中大体包括可遍历的和名值对映射两种大类别。在实际实现的很多数据结构里兼有这两者的特性。对于遍历数据类型来说,主要包括有Set, List, Queue几个大类。而对于名值对映射的里面主要是对应Map接口的实现。常用的有SortedMap, ConcurrentMap。我们用到的HashMap是一种非排序的Map实现,而TreeMap是内部机制实现了排序的。另外,对于一些适合并行编程操作的数据结构来说,他们本身有的利用了immutable的机制实现有效的隔离效果,比如CopyOnWriteArrayList;有的利用一些内部加锁的机制来保证一定程度的并行性,比如说ConcurrentHashMap。在后续的一些文章里会重点针对这些并行的数据结构集合类型进行讨论。
参考材料
Java generics and collections