死磕Zookeeper分布式过程协同
微信公众号:Collision Resistance
前言
当今如此庞大的数据量背后,⽆法依赖单个服务器的性能升级来处理,优化变得异常困难,也无法进行水平扩展,分布式系统和应用受到青睐。它不仅可以提供强大的计算能力,而且具有容灾性(即在机器发生故障时,系统的可用性基本不受影响)。
在⼤数据和云计算盛⾏的今天,应⽤服务由很多个独⽴的程序组成,如何让⼀个应⽤中多个独⽴的程序协同⼯作?ZooKeeper从⽂件系统API得到启发,提供⼀组简单的API,使得开发⼈员可以实现通⽤的协作任务,包括选举主节点、管理组内成员关系、管理元数据等。
使⽤ZooKeeper来设计应⽤,最好将应⽤数据和协同数据独⽴开。⽐如,⽹络邮箱服务的⽤户对⾃⼰邮箱中的内容感兴趣,但是并不关⼼由哪台服务器来处理特定邮箱的请求。邮箱内容就是应⽤数据,⽽从邮箱到某⼀台邮箱服务器之间的映射关系就是协同数据(或称元数据)。整个ZooKeeper服务所管理的就是后者,Zookeeper可以在分布式系统中协同多个任务。
正文
可能看了前面的内容,依然有疑问:Zookeeper到底能用来干什么?
首先,什么是分布式系统?书中定义为:分布式系统是同时跨越多个物理主机,独⽴运⾏的多个软件组件所组成的系统。我们采⽤分布式去设计系统有很多原因,分布式系统能够利⽤多处理器的运算能⼒来运⾏组件,⽐如并⾏复制任务。⼀个系统也许由于战略原因,需要分布在不同地点,⽐如⼀个应⽤由多个不同地点的服务器提供服务。
不难发现,分布式系统的协调工作就显得尤为重要,也就是解决分布式系统的一致性问题。是否能通过某种方式,从节点的信息能够实现同步与共享,共享存储就是一种解决办法。
Zookeeper存储了任务的分配、完成情况等共享信息:
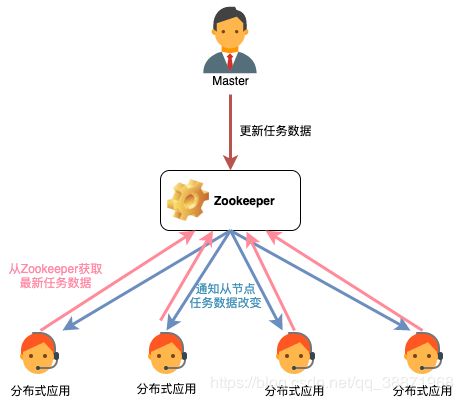
ZooKeeper使⽤共享存储模型来实现应⽤间的协作和同步原语。对于共享存储本⾝,又需要在进程和存储间进⾏⽹络通信。我们强调⽹络通信的重要性,因为它是分布式系统中并发设计的基础。
分布式系统的主-从架构与Zookeeper待解决的问题
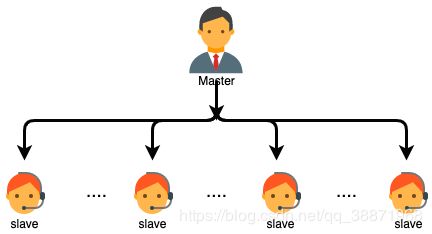
很明显,广泛应用的主-从模式有几个主要问题:
- 主节点失效
- 从节点失效
- 通信故障
主节点失效
如果主节点失效或报错,系统无法分配新的任务或重新分配失败的任务。所以我们就需要一个备份的主节点,接替出错的主节点的角色,进行故障转移,然而,新的主要主节点需要能够恢复到旧的主要主节点崩溃时的状态,而不是单单处理新进入主节点的请求。对于主节点状态的可恢复性,我们不能依靠从已经崩溃的主节点来获取这些信息,⽽需要从其他地⽅获取,也就是通过ZooKeeper来获取。
状态恢复并不是唯⼀的重要问题。假如主节点有效,备份主节点却认为主节点已经崩溃。例如主节点负载很⾼,导致消息任意延迟,备份主节点将会接管成为主节点的角⾊,执⾏所有必需的程序,最终可能以主节点的角色⾊开始执⾏,成为第⼆个主要主节点。更糟的是,如果⼀些从节点⽆法与主要主节点通信,如由于⽹络分区错误导致,这 些从节点可能会停⽌与主要主节点的通信,⽽与第⼆个主要主节点建⽴主从关系。针对这个场景中导致的问题,我们⼀般称之为脑裂。系统中两个或者多个部分开始独⽴⼯作,导致整体⾏为不⼀致性。我们需要找出⼀种⽅法来处理主节点失效的情况,关键是我们需要避免发⽣脑裂的情况。
从节点失效
主节点接收到由客户端传来的请求任务,再将任务发送到有效的从节点。从节点接收任务、处理任务,执行完毕将结果返回给主节点,汇报执行状态。下一步主节点将结果提交给客户端,完毕。
如果从节点崩溃了,主节点需要重新派发所有已派发给这个从节点且尚未完成的任务。其中⾸要需求是让主节点具有检测从节点的崩溃的能⼒。主节点必须能够检测到从节点的崩溃,并确定哪些从节点是否有效以便派发崩溃节点的任务。⼀个从节点崩溃时,从节点也许执⾏了部分任务,也许全部执⾏完,但没有报告结果。如果整个运算过程产⽣了其他作⽤,我们还有必要执⾏某些恢复过程来清除之前的状态。
通信故障
如果⼀个从节点与主节点的⽹络连接断开,可能由于⽹络分区导致,重新分配⼀个任务可能会导致两个从节点执⾏相同的任务。如果⼀个任务允许多次执⾏,我们在进⾏任务再分配时可以不⽤验证第⼀个从节点是否完成了该任务。如果⼀个任务不允许,那么我们的应⽤需要适应多个从节点执⾏相同任务的可能性。
通信故障会影响锁与同步原语,网络分区的系统中节点崩溃锁服务会阻止任务的执行,ZooKeeper也需要实现处理这些情况的机制。⾸先,客户端可以告诉ZooKeeper某些数据的状态是临时状态;其次,同时ZooKeeper需要客户端定时发送是否存活的通知,如果⼀个客户端未能及时发送通知,那么所有从属于这个客户端的临时状态的数据将全部被删除。通过这两个机制,在崩溃或通信故障发⽣时,我们就可以预防客户端独⽴运⾏⽽发⽣的应⽤宕机。——摘自原文
分布式协作难点
当开发分布式应⽤时,其复杂性会⽴即突显出来。例如,当我们的应⽤启动后,所有不同的进程通过某种⽅法,需要知道应⽤的配置信息,⼀段时间之后,配置信息也许发⽣了变化,我们可以停⽌所有进程,重新分发配置信息的⽂件,然后重新启动,但是重新配置就会延长应⽤的停机时间。
与配置信息问题相关的是组成员关系的问题,当负载变化时,我们希望增加或减少新机器和进程。可能还会⾯对故障,如崩溃、通信故障等各种情况。
分布式系统重要定理
现实生活中的系统往往都是异步系统。首先,共识机制在分布式系统中是无解的,为什么说是无解,众多的节点之间通信,必然存在网络自身不可靠的原因、主机故障原因、恶意操控等原因,故无法保证实现完全的共识,Fischer、Lynch和Patterson三位在1985年就提出了一个FLP不可能原理:在网络可靠的前提下,任意节点失效,一个或者多个的最小化异步模型系统中,不可能存在一个解决一致性问题的确定性算法。FLP说明在异步分布式系统中完全一致性是不可能的,但这是一个科学理论,应用到现实工程中,我们可以牺牲一些代价把不可能变成可能,这就是科学和工程的最大区别。
一个分布式系统最多只能同时满足一致性Consistency、可用性Availability和容错性Partition tolerance中的两项,听起来很悲观,但这也是分布式计算领域的公认定理。所以在实际运用中需要结合工程环境,适当取舍这三者。
结尾
我们⽆法拥有⼀个理想的故障容错的、分布式的、真实环境存在的系统来处理可能发⽣的所有问题。但我们还是可以争取⼀个稍微不那么宏伟的⽬标。完美的解决⽅案是不存在的,ZooKeeper⽆法解决分布式应⽤开发者⾯对的所有问题,⽽是为开发者提供了⼀个优雅的框架来处理这些问题。