网站自动化处理
网站自动化处理
本文思维导图

预备内容
预备技能栈
由于是 web 应用免不了 web 三大件,html、css、js。当然至少了解一下 html 即可,重点是 Dom 相关操作得了解一下,不然看着硕大的网页源码容易晕头转向。然后由于本文定位元素主要就是通过xpath 进行元素定位的,所以 xpath 是很有必要了解一下的。最后当然就提到了我们的程序设计语言 pyhon 啦,当然学会基本的函数处理即可,不涉及面向对象模块。
预备工具
首先,编程环境选择的是主流的pycharm环境,优缺点自然不用多说。然后 web 浏览器选择了谷歌浏览器,但是谷歌浏览器的缺点就是,进行自动化的时候,需要下载驱动(查看本地浏览器版本,下载对应驱动即可。)
程序功能
本程序功能,有以下几点:
- 自动化评价
- 自动化时长
- 仅当作学习技术的参考即可
程序逻辑
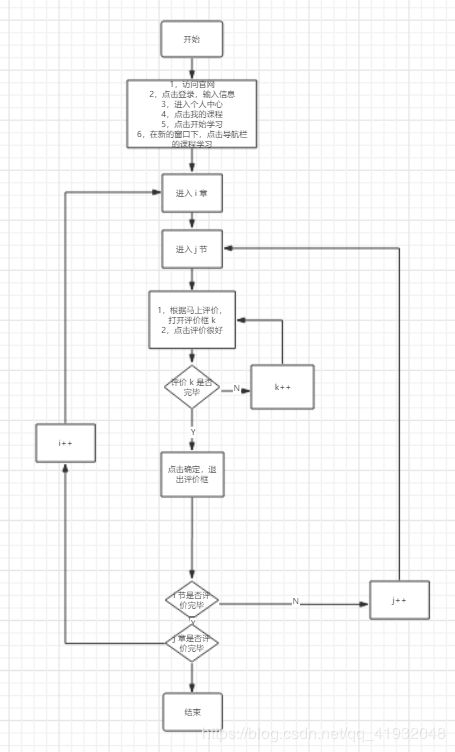
这个程序逻辑其实很简单,就是模拟人怎么取评价的,记住人每一步的操作就可以了,具体需要分析的就是 3 点
- 弹出框的时候是否内嵌 iframe (一般都是内嵌的)
- 页面刷新时,是否切换句柄(比如换窗口,肯定得切换句柄了)
- 章,节等怎么判断有几个(本文是通过 id,和 html 父节点和子节点关系来判断的)
注意以上三点,就可以啦,具体实现逻辑可看流程图。
程序实现
依赖库
这里依赖库主要用到的就是 selenium 库,库里的功能主要是
- 模拟浏览器
- 寻找网页节点模拟点击
- 页面切换功能
其次应该注意的是,pytesseract+PIL库可以帮助有效解决验证码识别问题,当然验证码识别需要依赖的系统是基于java 开发的一个 OCR,通过 pytesseract 连接使用即可,没有涉及太复杂的内容。
还有一些其他的库,以下是它们在本程序中所扮演的功能简述。
- time:等待页面刷新后,再进行操作
- re:对字符串进行匹配和操作
- os:python 对系统进行操作
代码如下:
from selenium import webdriver
import time
import pytesseract
from PIL import Image
import re # 用于正则
import os
主函数
直接从主函数开始,了解程序大体上进行了哪些工作,首先是加载驱动,由于 Google 浏览器的弊端,不同的版本要下载不同驱动,然后是输入一些基本信息,比如访问的浏览地址,用户名,密码等。
接着就可以开始尝试登录了,调用 login 函数,当然运行到这里由于本程序在图片识别上有比较大的问题,直接利用的原生的 OCR 系统,识别效果比较差,当然由于目标的图片内容比较简单,只需要反复运行几次就可以登录成功,就偷懒了。如果想要使得程序能够比较好的处理图片的话,笔者建议从以下方向进行优化:
- 一个方向就是反复进行图片识别,直到识别成功登录;(就是写一个 try except 语句,没成功重新运行)
- 第二个方向就是通过算法,对图片进行预处理,比如通过二值化等处理,使得图片上的噪声降低,便于 OCR 系统识别;
- 第三个方向,就是通过大量图片的案例,训练 OCR 系统模型,使得模型识别功能提高。
- 当然最好的方向还是多种方向结合处理。
然后是进入课程学习目录界面的函数 go_to_my_course,这个就是一些跳转,在这个函数里一定要注意页面刷新的问题,主要通过 time.sleep() 来解决。
最后就是一个比较复杂的函数 evaluate 即可开始评价。这里面多次涉及 xpath 定位元素的操作,这里简单介绍一下如何快速获得 xpath:
- 按键 F12,打开开发者工具

- 点击左上角箭头

- 点击一个元素,开发者工具中定位到这个页面

- 右键点击,然后进入 Copy,然后 CopyXpath 即可
主函数代码如下:
if __name__ == '__main__':
chrome_driver = r'xxx'
os.environ["webdriver.chrome.driver"] = chrome_driver
driver = webdriver.Chrome(chrome_driver)
# 登录网页
url = 'xxx'
driver.get(url)
# 用户名,密码
user = 'xxx'
password = 'xxx'
# 登录
login(driver, user, password)
# 进入课程学习
go_my_course(driver)
# 进行评价和时长
evaluate(driver)
# 爬取题目
#'spider_text(driver)'
# 进行刷题
子函数
- 登录函数 login
登录函数就是接受主函数传递的用户信息(账号,密码),通过判断函数 check_code 进行判断。其中 check_code 就依赖了 OCR 系统了。具体步骤如下:
首先打开登录窗口,按 F12 进入开发者页面,选中窗口元素,获取该元素的 xpath 定位,然后模拟点击登录按钮,可以打开登录框。
然后根据网页元素分析可以判断,登录窗口元素为内嵌窗口 iframe,于是需要显示的切换到内嵌窗口;接着根据弹出的窗口进行操作,输入用户名和密码,以及进行图片识别后输入,在图片识别功能中,作如下详细阐述:先对图片进行定位,通过图片截图的方式保存图片到本地,便于处理;接着,调用 pytesseract 库与 OCR 自动识别系统进行链接,将含有图片发送到 OCR 中进行字符串识别,返回一个识别后的字符串;最后通过 re 正则表达式,优化字符串,去除冗杂的符号。经过试验知道,由于验证码只有四位数,于是仅取前 4 个字符串。
最后点击登录,就自动登录了。代码如下:
def login(driver, user, password):
time.sleep(5)
driver.find_element_by_xpath('/html/body/div[2]/div/div/ul/li[4]/a[1]').click() # 登录窗口
driver.switch_to.frame('pageiframe')
# 输入账号
driver.find_element_by_xpath('//').send_keys(user)
# 输入密码
driver.find_element_by_xpath('//').send_keys(password)
# 输入验证码
driver.find_element_by_xpath('//').send_keys(check_code())
# 登录按钮
driver.find_element_by_xpath('//').click()
return True
- 进入课程学习函数 go_to_my_course
这个函数的功能,主要是实现页面刷新和窗口(句柄)切换,最后可以成功切换到要进行处理的界面,即课程学习的目录界面。操作如下:页面刷新操作,进入个人中心,点击我的课程,点击开始学习;然后通过网页分析,涉及到切换句柄,通过代码: driver.window_handles 。即可实现切换句柄到新窗口,然后可以在新窗口进行操作;最后就点击导航的课程学习即可。(注意,这里的点击都是默认程序通过 xpath 路径进行的,本文不加赘述)
代码如下:
def go_my_course(driver):
try:
time.sleep(3) # 跳转页面
# 进入个人中心
driver.find_element_by_xpath('/html/body/div[2]/div/div/ul/li[4]/a').click()
# 点我的课程
driver.find_element_by_xpath('//').click()
# 进入学习
driver.find_element_by_xpath('//').click()
# 切换新网页句柄
wins = driver.window_handles
driver.switch_to.window(wins[1])
# time.sleep(5) # 跳转页面
# 点击课程学习
driver.find_element_by_xpath("//").click()
return True
except:
print('进入失败,重新运行代码')
- 评价函数 evalute
评价函数 evaluete 是本程序主要实现的功能。
在此函数中,比较复杂的就是循环终止条件的确定,来自动更新元素的 xpath 路径。首先是章数的确定,直接分析网页即可轻松知道,章数变化的是部分主要是 id ,于是可以从网页知道第 i 章 xpath路径为:(见代码)。id 的范围是 [538, 551](这里由于第一章内容提前处理了,所以忽略了第一章的内容,如需改进程序,可以将第一章预操作)。进入第 i 章后,就是进入第 j 节。而共有多少小节可以直接根据父节点也就是章节点进行直接获取子节点的数量。当然在本文中还是通过绝对路径直接的 xpath 进行获取,即发现通过 xpath 路径:(见代码) 就可以判断有多少个几点。
进入小节后,可以通过一个比较简单的方法定位评价按钮,即通过文本匹配 “马上评价”关键字即可轻松实现定位评价按钮,并获得按钮的总数,以此来确定循环终止条件。
代码如下:
# 媒体评价和时长
def evaluate(driver):
try:
# 第 i 章
for i in range(538, 551):
strTitle = '//' + str(i) + '"]'
# driver.find_element_by_xpath(strTitle).click() # 点击第 i 章
test = driver.find_element_by_xpath(strTitle)
driver.execute_script("arguments[0].click();", test)
# 这里因为定位小节时 id 改变了
strTitle2 = '//' + str(i) + '"]'
strNode = strTitle2 + '/ul/li'
le = len(driver.find_elements_by_xpath(strNode)) # 每个章的小节数量不同
# 依次点击 k 小节下的 a 标签
for k in range(1, le + 1):
strA = strNode + str([k]) + '/a'
# driver.find_element_by_xpath(strA).click()
test2 = driver.find_element_by_xpath(strA)
driver.execute_script("arguments[0].click();", test2)
time.sleep(2)
# a 标签下的媒体评价
# 根据 ‘马上评价’文本定位节点
strEvaluate = '// / div[1] / dl / dd / p / a / span / span[contains(text(), "马上评价")]'
dr = driver.find_elements_by_xpath(strEvaluate)
# 每个文本进行点击
for j in range(0, len(dr)):
strEvaluate = '/// div[1] / dl / dd / p / a / span / span[contains(text(), "马上评价")]'
drChild = driver.find_element_by_xpath(strEvaluate)
drChild.click()
# 对弹出页面进行操作
## 点击很好
## 转到 iframe
driver.switch_to.frame('pageiframe')
strGood = '/html/body/div[2]/div/div[2]/div/p/input[3]'
time.sleep(2)
driver.find_element_by_xpath(strGood).click()
### 点击确定,没有确定则不管
try:
strSure = '/html/body/div[1]/div/table/tbody/tr[2]/td[2]/div/table/tbody/tr[3]/td/div/button[1]'
driver.find_element_by_xpath(strSure).click()
time.sleep(2)
finally:
# 转到主界面, 才能关闭 iframe
driver.switch_to.parent_frame()
# 关闭弹出页面, 进行下一次评价
strClose = '/html/body/div[1]/div/table/tbody/tr[2]/td[2]/div/table/tbody/tr[1]/td/div/a'
driver.find_element_by_xpath(strClose).click()
time.sleep(2)
time.sleep(2)
time.sleep(2)
return True
except:
print('评价失败,重新运行代码')
总结
优点
本次实验基于用户行为,模拟了人工智能。
缺点和改进措施
在这里主要提出以下缺点,以及它们的改进措施
- 缺失第一章:由于第一章内容提前处理了,所以忽略了第一章的内容,如需改进程序,可以将第一章预操作。
- 图片识别功能改进:本文是基于 OCR 系统进行图片识别的,但是识别效果较差。改进措施主要有三个方向。一个方向就是反复进行验证码识别,直到识别成功登录;第二个方向就是通过算法,对图片进行预处理,比如通过二值化等处理,使得图片上的噪声降低,便于 OCR 系统识别;第三个方向,就是通过大量图片的案例,训练 OCR 系统模型,使得模型识别功能提高。当然最好的方向还是多种方向结合处理。
- 页面跳转处理改进:页面跳转的函数,是简单的根据time.sleep()进行等待的,当超出等待时,很容易使得程序返回错误信息。改进方法,第一是优化等待的方式,比如等待页面加载就开始处理,而不是仅仅通过预设等待时间;第二,就是比较笨的方法了,多运行几次。
- 代码优化:面向过程,代码复用率较差,可进行代码优化实现面向对象,提高代码复用率;代码存在大量重复的代码,可以设计成一个单独的功能,比如获取节点xpath功能可以单独进行设计,以期优化代码。
附录:完整代码:
from selenium import webdriver
import time
import pytesseract
from PIL import Image
import re # 用于正则
import os
# 验证码识别
def check_code():
# 通过截图来获取验证码
checkCode = driver.find_element_by_xpath('//')
checkCode.screenshot('checkZS2.png')
imageObject = Image.open('checkZS2.png')
result = pytesseract.image_to_string(imageObject) # 图片转文字
resultj = re.sub(u"([^\u4e00-\u9fa5\u0030-\u0039\u0041-\u005a\u0061-\u007a])", "", result) # 去除识别出来的特殊字符
result_four = resultj[0:4] # 只获取前4个字符 # 登录功能
return result_four
def login(driver, user, password):
time.sleep(5)
driver.find_element_by_xpath('/html/body/div[2]/div/div/ul/li[4]/a[1]').click() # 登录窗口
driver.switch_to.frame('pageiframe')
# 输入账号
driver.find_element_by_xpath('//').send_keys(user)
# 输入密码
driver.find_element_by_xpath('//').send_keys(password)
# 输入验证码
driver.find_element_by_xpath('//').send_keys(check_code())
# 登录按钮
driver.find_element_by_xpath('//').click()
return True
# 进入课程学习界面
def go_my_course(driver):
try:
time.sleep(3) # 跳转页面
# 进入个人中心
driver.find_element_by_xpath('/html/body/div[2]/div/div/ul/li[4]/a').click()
# 点我的课程
driver.find_element_by_xpath('///div/div[1]/dl/dd[9]/a').click()
# 进入学习
driver.find_element_by_xpath('///div/table/tbody/tr[2]/td[6]/a').click()
# 切换新网页句柄
wins = driver.window_handles
driver.switch_to.window(wins[1])
# time.sleep(5) # 跳转页面
# 点击课程学习
driver.find_element_by_xpath("///div[2]/div/a[2]").click()
return True
except:
print('进入失败,重新运行代码')
# 媒体评价和时长
def evaluate(driver):
try:
# 第 i 章
for i in range(538, 551):
strTitle = '//' + str(i) + '"]'
# driver.find_element_by_xpath(strTitle).click() # 点击第 i 章
test = driver.find_element_by_xpath(strTitle)
driver.execute_script("arguments[0].click();", test)
# 这里因为定位小节时 id 改变了
strTitle2 = '//' + str(i) + '"]'
strNode = strTitle2 + '/ul/li'
le = len(driver.find_elements_by_xpath(strNode)) # 每个章的小节数量不同
# 依次点击 k 小节下的 a 标签
for k in range(1, le + 1):
strA = strNode + str([k]) + '/a'
# driver.find_element_by_xpath(strA).click()
test2 = driver.find_element_by_xpath(strA)
driver.execute_script("arguments[0].click();", test2)
time.sleep(2)
# a 标签下的媒体评价
# 根据 ‘马上评价’文本定位节点
strEvaluate = '// / div[1] / dl / dd / p / a / span / span[contains(text(), "马上评价")]'
dr = driver.find_elements_by_xpath(strEvaluate)
# 每个文本进行点击
for j in range(0, len(dr)):
strEvaluate = '/// div[1] / dl / dd / p / a / span / span[contains(text(), "马上评价")]'
drChild = driver.find_element_by_xpath(strEvaluate)
drChild.click()
# 对弹出页面进行操作
## 点击很好
## 转到 iframe
driver.switch_to.frame('pageiframe')
strGood = '/html/body/div[2]/div/div[2]/div/p/input[3]'
time.sleep(2)
driver.find_element_by_xpath(strGood).click()
### 点击确定,没有确定则不管
try:
strSure = '/html/body/div[1]/div/table/tbody/tr[2]/td[2]/div/table/tbody/tr[3]/td/div/button[1]'
driver.find_element_by_xpath(strSure).click()
time.sleep(2)
finally:
# 转到主界面, 才能关闭 iframe
driver.switch_to.parent_frame()
# 关闭弹出页面, 进行下一次评价
strClose = '/html/body/div[1]/div/table/tbody/tr[2]/td[2]/div/table/tbody/tr[1]/td/div/a'
driver.find_element_by_xpath(strClose).click()
time.sleep(2)
time.sleep(2)
time.sleep(2)
return True
except:
print('评价失败,重新运行代码')
# 获得题目
def spider_text(driver):
for i in range(538, 551):
strTitle = '//' + str(i) + '"]'
# driver.find_element_by_xpath(strTitle).click() # 点击第 i 章
test = driver.find_element_by_xpath(strTitle)
driver.execute_script("arguments[0].click();", test)
# 这里因为定位小节时 id 改变了
strTitle2 = '//' + str(i) + '"]'
strNode = strTitle2 + '/ul/li'
le = len(driver.find_elements_by_xpath(strNode)) # 每个章的小节数量不同
# 定位到 k 小节
for k in range(1, le + 1):
strA = strNode + str([k]) + '/a'
# driver.find_element_by_xpath(strA).click()
test2 = driver.find_element_by_xpath(strA)
driver.execute_script("arguments[0].click();", test2)
time.sleep(2)
# 包含题目文本的标签
strText = '///div[2]/dl/dd[1]/ul/li/p'
texts = driver.find_elements_by_xpath(strText);
for t in texts:
text = t.text
print(text)
with open('./TK.txt', 'a', encoding='utf-8') as f:
f.write(text + '\n')
time.sleep(3)
return True
# 刷题
def do_homework(driver):
pass
if __name__ == '__main__':
chrome_driver = r'xxx'
os.environ["webdriver.chrome.driver"] = chrome_driver
driver = webdriver.Chrome(chrome_driver)
# 登录网页
url = ''
driver.get(url)
# 用户名,密码
user = ''
password = ''
# 登录
login(driver, user, password)
# 进入课程学习
go_my_course(driver)
# 进行评价和时长
evaluate(driver)
# 爬取题目
#'spider_text(driver)'
# 进行刷题