使用MapReduce实现两个文件的Join操作
文章目录
- 数据结构
- customer
- order
- MapJoin
- 描述
- 主函数入口
- 构造类代码
- 执行结果
- MapJoin采坑记录
- ReduceJoin
- 描述
- 主函数入口
- 构造类代码
- 结果
- ReduceJoin采坑记录
数据结构
customer
| USER_ID | NAME | PHONE |
|---|---|---|
| 1 | 大树 | 13111111111 |
| 2 | 小十七 | 13122222222 |
| 3 | 小海 | 13133333333 |
| 4 | jeff | 13100000000 |
| 5 | zz | 13155555555 |
| 6 | 蝶舞 | 13166666666 |
| 7 | 阿伟 | 13188888888 |
| 8 | 大国 | 13199999999 |
order
| USER_ID | NAME | PRICE | TIME |
|---|---|---|---|
| 1 | 《精准表达》 | 50 | 2019-1-1 |
| 4 | 《羊皮卷》 | 80 | 2019-1-1 |
| 3 | 《厚黑学》 | 70 | 2019-1-6 |
| 2 | 《狼道》 | 65 | 2019-1-2 |
| 6 | 《人性的弱点》 | 66 | 2019-1-9 |
| 1 | 《为人三会》 | 12 | 2019-1-6 |
| 3 | 《口才三绝》 | 35 | 2019-1-3 |
| 7 | 《修心三不》 | 41 | 2019-1-1 |
| 4 | 《法则》 | 48 | 2019-1-5 |
| 5 | 《社交》 | 56 | 2019-1-4 |
| 3 | 《职场》 | 54 | 2019-1-3 |
| 5 | 《交流》 | 32 | 2019-1-2 |
| 6 | 《谋略》 | 12 | 2019-2-3 |
| 3 | 《所谓情商高就是会说话》 | 96 | 2019-3-6 |
| 2 | 《女人的资本》 | 54 | 2019-3-5 |
MapJoin
描述
- 场景:MapJoin 适用于有一份数据较小的连接情况。
- 做法:直接将较小的数据加载到内存中,按照连接的关键字建立索引,大份数据作为MapTask的输入数据对 map()方法的每次输入都去内存当中直接去匹配连接。然后把连接结果按 key 输出,这种方法要使用 hadoop中的 DistributedCache 把小份数据分布到各个计算节点,每个 maptask 执行任务的节点都需要加载该数据到内存,并且按连接关键字建立索引。
主函数入口
package com.ruozedata.bigdata.myself.MapJoin;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import javax.xml.transform.OutputKeys;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URI;
import java.util.HashMap;
import java.util.Map;
public class JoinMapperDemo extends Configured implements Tool {
// 定义缓存文件的读取路径
// private static String cacheFile = "/D:/ruozedata_workspace/g6_java/input/customer";
// private static String cacheFile = "D:\\ruozedata_workspace\\g6_java\\input\\customer";
private static String cacheFile = "hdfs://hadoop614:9000/g6/hadoop/MapReduceJoin/input/customer";
// 定义map处理类模板
public static class map extends Mapper {
private Text OutputValue = new Text();
Map map = null;
@Override
public void setup(Context context) throws IOException, InterruptedException {
// 读取缓存文件
FileSystem fileSystem = FileSystem.get( URI.create( cacheFile ), context.getConfiguration() );
FSDataInputStream fsDataInputStream = fileSystem.open( new Path( cacheFile ) );
BufferedReader bufferedReader = new BufferedReader( new InputStreamReader( fsDataInputStream ) );
// 创建一个map集合来保存读取文件的数据
map = new HashMap();
String line = null;
while ((line = bufferedReader.readLine()) != null) {
String[] split = line.split( "," );
if (split.length != 3) {
continue;
}
Customer customer = new Customer( Integer.parseInt( split[0] ), split[1], split[2] );
map.put( customer.getCid(), customer );
}
// 关闭 I/O 流
bufferedReader.close();
}
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
// 将 Customer表 和order表的数据进行合并
String string = value.toString();
String[] Orders = string.split( "," );
int joinID = Integer.valueOf( Orders[0] );
Customer customerid = map.get( joinID );
StringBuffer stringBuffer = new StringBuffer();
stringBuffer.append( Orders[0] ).append( "," )
.append( customerid.getCname() ).append( "," )
.append( customerid.getCphone() ).append( "," )
.append( Orders[1] ).append( "," )
.append( Orders[2] ).append( "," )
.append( Orders[3] ).append( "," );
OutputValue.set( stringBuffer.toString() );
context.write(NullWritable.get(), OutputValue );
}
}
//无reduce程序
//配置Driver模块
@Override
public int run(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//获取配置配置文件对象
Configuration configuration = new Configuration();
configuration.set( "fs.defaultFS","hdfs://hadoop614:9000" );
//创建给mapreduce处理的任务
Job job = Job.getInstance( configuration, this.getClass().getSimpleName() );
//获取将要读取到内存的文件的路径,并加载进内存
job.addCacheFile( URI.create( cacheFile ) );
//创建输入路径
Path source_path = new Path( args[0] );
//创建输出路径
Path des_path = new Path( args[1] );
//创建操作hdfs的FileSystem对象
FileSystem fs = FileSystem.get( configuration );
if (fs.exists( des_path )) {
fs.delete( des_path, true );
}
FileInputFormat.addInputPath( job, source_path );
FileOutputFormat.setOutputPath( job, des_path );
//设置让任务打包jar运行
job.setJarByClass( JoinMapperDemo.class );
//设置map
job.setMapperClass( map.class );
job.setMapOutputKeyClass( LongWritable.class );
job.setMapOutputValueClass( Text.class );
//设置reduceTask的任务数为0,即没有reduce阶段和shuffle阶段
job.setNumReduceTasks( 0 );
//提交job到yarn组件上
boolean isSuccess = job.waitForCompletion( true );
return isSuccess ? 0 : 1;
}
public static void main(String[] args) throws Exception {
if (args.length != 2) {
System.out.println( "Please input 2 params: input output" );
System.exit( 0 );
}
String input = args[0];
String output = args[1];
// 设置执行job的用户
System.setProperty( "HADOOP_USER_NAME", "hadoop" );
System.setProperty( "hadoop.home.dir", "D:\\software\\hadoopapp\\hadoop-2.6.0-cdh5.7.0" );
Configuration configuration = new Configuration();
int status = 0;
try {
status = ToolRunner.run( configuration, new JoinMapperDemo(), args );
} catch (Exception e) {
e.printStackTrace();
}
// 退出
System.exit( status );
}
}
构造类代码
package com.ruozedata.bigdata.myself.MapJoin;
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class Customer implements Writable {
private int cid;
private String cname;
private String cphone;
private DataOutput out;
public int getCid() {
return cid;
}
public void setCid(int cid) {
this.cid = cid;
}
public String getCname() {
return cname;
}
public void setCname(String cname) {
this.cname = cname;
}
public String getCphone() {
return cphone;
}
public void setCphone(String cphone) {
this.cphone = cphone;
}
public Customer(int cid, String cname, String cphone) {
super();
this.cid = cid;
this.cname = cname;
this.cphone = cphone;
}
@Override
public void write(DataOutput out) throws IOException {
out.writeInt( this.cid );
out.writeUTF( this.cname );
out.writeUTF( this.cphone );
}
@Override
public void readFields(DataInput in) throws IOException {
this.cid = in.readInt();
this.cname = in.readUTF();
this.cphone = in.readUTF();
}
@Override
public String toString() {
return String.format( "Customer [cid=%s, cname=%s, cphone=%s]", cid, cname, cphone );
}
}
执行结果
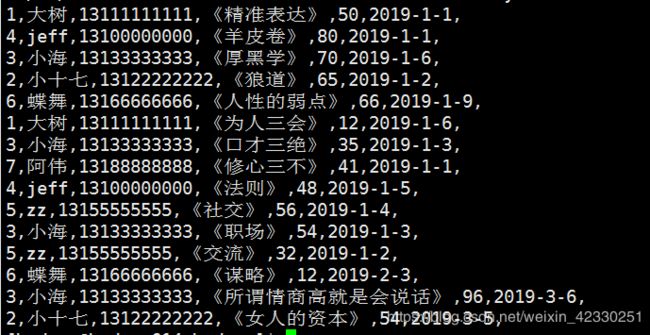
MapJoin采坑记录
- MapJoin采坑记录入口
ReduceJoin
描述
- 在map阶段, 把关键字作为key输出,并在value中标记出数据是来自data1还是data2。因为在shuffle阶段已经自然按key分组,reduce阶段,判断每一个value是来自data1还是data2,在内部分成2组,做集合的乘积。
- 这种方法有2个问题:
- map阶段没有对数据瘦身,shuffle的网络传输和排序性能很低。
- reduce端对2个集合做乘积计算,很耗内存,容易导致OOM。.
主函数入口
package com.ruozedata.bigdata.myself.Reducejoin;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import org.apache.hadoop.yarn.webapp.hamlet.Hamlet;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
public class JoinReduceDemo extends Configured implements Tool {
//定义map处理类模板
public static class mapClass
extends Mapper {
private IntWritable outputkey = new IntWritable();
private DataJoin dataJoin = new DataJoin();
protected void map(LongWritable key, Text values, Context context)
throws IOException, InterruptedException {
// 获取字符串
String str = values.toString();
System.out.println( str );
// 对字符串进行分割
String[] value = str.split( "," );
System.out.println( Arrays.toString( value ) );
// 过滤非法数据
int len = value.length;
if (len != 3 && len != 4) {
return;
}
// 取出 ID
String cid = value[0];
// 判断是customer表还是order表
if (len == 3) {
// 表示是customer表
String cname = value[1];
String cphone = value[2];
dataJoin.set( "Customer", cid + "," + cname + "," + cphone );
}
if (len == 4) {
// 表示是order表
String oname = value[1];
String oprice = value[2];
String otime = value[3];
dataJoin.set( "Order", oname + "," + oprice + "," + otime );
}
outputkey.set( Integer.valueOf( cid ) );
context.write( outputkey, dataJoin );
}
}
// 定义 reduce 处理类模板
public static class reduceClass extends Reducer {
private Text outputvalue = new Text();
@Override
protected void reduce(IntWritable key, Iterable values,
Context context) throws IOException, InterruptedException {
// 定义一个字符串保存客户信息
String customerInfo = null;
// 定义一个list,保存客户订单信息
List list = new ArrayList();
for (DataJoin dataJoin : values) {
if (dataJoin.getTag().equals( "Customer" )) {
customerInfo = dataJoin.getData();
System.out.println( customerInfo );
}
if (dataJoin.getTag().equals( "Order" )) {
list.add( dataJoin.getData() );
}
}
// 进行输出
for (String s : list) {
outputvalue.set( customerInfo + "," + s );
context.write( NullWritable.get(), outputvalue );
}
}
}
@Override
public int run(String[] args) throws Exception {
// 获取配置文件对象
Configuration configuration = new Configuration();
System.out.println( configuration );
// 创建给 MapReduce 处理的任务
Job job = null;
try {
job = Job.getInstance( configuration, this.getClass().getSimpleName() );
} catch (IOException e) {
e.printStackTrace();
}
try {
// 创建输入路径
Path source_path = new Path( args[0] );
if (job != null) {
FileInputFormat.addInputPath( job, source_path );
}
// 创建输出路径
Path des_path = new Path( args[1] );
if (job != null) {
FileOutputFormat.setOutputPath( job, des_path );
}
} catch (IllegalArgumentException | IOException e) {
e.printStackTrace();
}
// 设置 让任务打包jar运行
if (job != null) {
job.setJarByClass( JoinReduceDemo.class );
}
// 设置map
assert job != null;
job.setMapperClass( mapClass.class );
job.setMapOutputKeyClass( IntWritable.class );
job.setMapOutputValueClass( DataJoin.class );
// 设置 Reduce
job.setReducerClass( reduceClass.class );
job.setOutputKeyClass( NullWritable.class );
job.setOutputValueClass( Text.class );
// 移交 job 到yarn
boolean isSuccess = false;
try {
isSuccess = job.waitForCompletion( true );
} catch (ClassNotFoundException | IOException | InterruptedException e) {
e.printStackTrace();
}
return isSuccess ? 0 : 1;
}
public static void main(String[] args) throws Exception {
if (args.length != 2) {
System.err.println( "Please input 2 params: input output" );
System.exit( 0 );
}
String input = args[0];
String output = args[1];
// 设置执行job的用户
System.setProperty( "HADOOP_USER_NAME", "hadoop" );
System.setProperty( "hadoop.home.dir", "D:\\software\\hadoopapp\\hadoop-2.6.0-cdh5.7.0" );
Configuration configuration = new Configuration();
FileSystem fileSystem = FileSystem.get( configuration );
Path outputPath = new Path( output );
System.out.println( outputPath );
if (fileSystem.exists( outputPath )){
fileSystem.delete( outputPath,true );
}
// 运行job
int status = 0;
try {
status = ToolRunner.run( configuration, new JoinReduceDemo(), args );
} catch (Exception e) {
e.printStackTrace();
}
// 退出
System.exit( status );
}
}
构造类代码
package com.ruozedata.bigdata.myself.Reducejoin;
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class DataJoin implements Writable {
private String tag;
private String data;
public String getTag() {
return tag;
}
public String getData() {
return data;
}
public void set(String tag ,String data) {
this.tag = tag;
this.data = data;
}
@Override
public String toString() {
return tag + data;
}
public void write(DataOutput output) throws IOException {
output.writeUTF( this.tag );
output.writeUTF( this.data);
}
public void readFields(DataInput input) throws IOException {
this.tag = input.readUTF();
this.data = input.readUTF();
}
}
结果
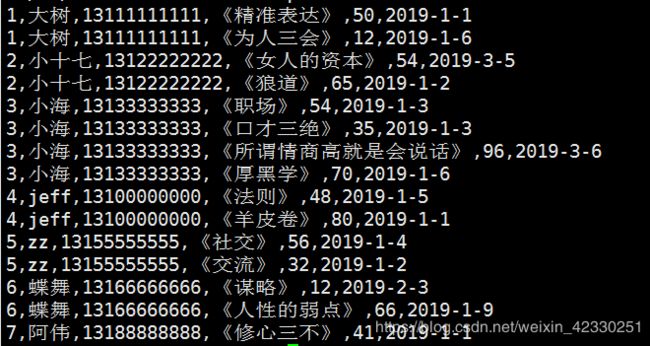
ReduceJoin采坑记录
- ReduceJoin采坑记录入口
最后感谢 尼美美 博客的支持
Map Join和Reduce Join的区别以及代码实现