Mancs: A Multi-task Attentional Network with Curriculum Sampling for Person Re-identification 论文笔记
一、提出问题
- 损失函数的选择
- 行人错位问题
- 发现具有差异性的地方特征
- 如何在优化排名损失函数时对训练数据进行采样
二、论文贡献
- 提出Mancs模型,模型中的基本骨干网络受到排名损失(三重损失triplet loss)和分类损失(焦点损失focal loss)的监督。本文提出了一种新的课程抽样策略来训练排名损失,该训练策略有助于由易到难的训练网络;
- 为了处理错位问题并定位差异性局部特征,本文提出了一种新的全注意力模块(FAB),它可以创建通道方面和空间方面的注意信息,以挖掘行人重识别的有用特征;
- 为了更好地了解网络中的FAB,本文通过为每个FAB添加分类损失函数来深度监督模型,这种分类损失函数被称为注意力损失。最后,将triplet loss,focal loss和注意力损失结合起来,以多任务方式训练网络。
三、模型结构

图3-1 模型结构
3.1 训练结构
用于训练的网络架构如图3-1所示,主要包含三个部分:骨干网络,注意力模块和损失函数。
骨干网络作为多尺度特征提取器,本文使用的是ResNet-50,采用conv-2,conv-3和conv-4特征映射用于生成注意力mask,然后将这些mask添加回主分支,最后一个conv-5特征映射用于生成最终的人物身份特征。
3.2 全注意力模块

图3-2 SE模块和FAB模块
FAB模块受压缩奖惩网络(SENet)的启发,该方法说明了特征映射的不同通道在指定对象上映射出的特征不同。 SENet中的SE模块(图3-2(a))根据通道的偏好并给特征图的每个通道赋一个加权系数,但是SE模块仅在通道方面重新校准了特征响应,而忽略了在使用全局池化情况下的空间响应,这导致丢失空间结构信息。为了解决这个问题,本文提出的 FAB模块舍弃了池化层并使用1×1卷积层而非全连接层来重新获取空间信息。由此可以获得具有相同大小的输入特征图的注意力mask,FAB模块如图3-2(b)所示。
给定卷积特征映射Fi,其注意力映射计算如下:

其中,两个Conv运算是1×1卷积,内部Conv用于压缩,外部Conv用于激励。在获得注意力特征图M之后,Fi的输出特征图为:
![]()
其中,运算符*和+是矩阵相乘和矩阵相加,这就表示将注意力特征图添加到原始特征图中以强调可辨别的特征。FAB是可选择添加与否的,并且可以应用于任何现有的CNN结构中,因为FAB不会改变卷积特征映射的大小。
3.3 ReID任务#1:三重损失与课程抽样
排名损失对于重新识别深度网络至关重要,尤其是当训练数据集不够大时,它具有比收缩损失或分类损失更好的泛化能力。在模型引入一个三重损失的排名分支,将三重态损失的图像![]() 的特征表示为
的特征表示为![]() ,其中
,其中![]() 表示用于对特征进行排序的特征提取网络。如图3-1所示,
表示用于对特征进行排序的特征提取网络。如图3-1所示,![]() 与其他分支共享骨干网络,并拥有池化层和FC层。当使用三重损失时,其采样算法很重要。
与其他分支共享骨干网络,并拥有池化层和FC层。当使用三重损失时,其采样算法很重要。
大多数行人重识别工作采用facenet提出的三元损失,facenat的主要思想是通过所谓的PK采样方法进行在线困难三元组采样,该方法随机采样P个id,然后随机抽取每个id的K图像,形成一个大小为P×K的小批量样本。在小批量![]() 中,每个图像都被认为是锚图像
中,每个图像都被认为是锚图像![]() ,并且在I中找到对于
,并且在I中找到对于![]() 来说最困难的正样本和最困难的负样本,分别表示为
来说最困难的正样本和最困难的负样本,分别表示为![]() 和
和![]() 。
。![]() 是三元的并且可以获得PK三元组,上述抽样过程也称为在线困难实例挖掘(OHEM),但是OHEM每个选择最困难的样本进行参数更新容易导致训练过程中模型坍塌。 受课程学习的启发,本文提出了一种新的抽样方式,即课程抽样,从易到难训练三元组。
是三元的并且可以获得PK三元组,上述抽样过程也称为在线困难实例挖掘(OHEM),但是OHEM每个选择最困难的样本进行参数更新容易导致训练过程中模型坍塌。 受课程学习的启发,本文提出了一种新的抽样方式,即课程抽样,从易到难训练三元组。
具体地,本文放弃了在训练开始时对最难实例进行抽样的方法,而是从简单实例开始。给定锚实例![]() ,先随机选择其中一个正样本为
,先随机选择其中一个正样本为![]() ; 其次,根据它们到锚点的距离从小到大排序负样本,也就是将样本从难到易进行排序;然后,给每个负样本一个被选中的概率,这些概率服从高斯分布N(μ,σ),其中μ和σ定义如下:
; 其次,根据它们到锚点的距离从小到大排序负样本,也就是将样本从难到易进行排序;然后,给每个负样本一个被选中的概率,这些概率服从高斯分布N(μ,σ),其中μ和σ定义如下:

其中![]() ,Nn是负实例的数量。 a是初始std值,b是t> t0时的衰减指数。t0和t1是超参数,可以控制学习过程从简单到困难的速度。上述过程选择锚点,正实例和负实例以形成三元组。接下来,目标仍然是一样的;随机选择另一个不同的正实例,再次进行上述过程。然后,基于先前的概率分布选择另一个负实例(锚实例仍是相同的),完成了第二个三元组的选择。当选完此锚点的所有正实例时,我们将移动到下一个锚点。上述过程完成了PK(K - 1)个三元组的选择。 PK是锚的数量。 K-1是每个锚的正实例数。
,Nn是负实例的数量。 a是初始std值,b是t> t0时的衰减指数。t0和t1是超参数,可以控制学习过程从简单到困难的速度。上述过程选择锚点,正实例和负实例以形成三元组。接下来,目标仍然是一样的;随机选择另一个不同的正实例,再次进行上述过程。然后,基于先前的概率分布选择另一个负实例(锚实例仍是相同的),完成了第二个三元组的选择。当选完此锚点的所有正实例时,我们将移动到下一个锚点。上述过程完成了PK(K - 1)个三元组的选择。 PK是锚的数量。 K-1是每个锚的正实例数。
根据课程抽样方法,排名分支的最终损失可以定义为:

其中D(·,·)是两个特征向量之间的欧式距离,![]() 的概率定义如下:
的概率定义如下:

3.4 ReID任务#2:具有focal loss的行人分类
最近的研究表明,将排名损失和分类损失相结合有助于行人重识别,在Mancs模型中同样也设置了一个分类分支。由于困难挖掘实例在排名损失中是必不可少的,可以认为它也能应用于分类任务。由于学习困难样本比学习简单样本更重要,所以可以选择提高负样本在总损失中所占的比例。而用于密集物体检测的focal loss正适合这种情况,它可以让困难样本比简单的样本具有更高的权重。
将分类分支的特征提取器表示为![]() 。 给定图像
。 给定图像![]() 及其真实身份
及其真实身份![]() ,
,![]() 属于第c类的概率表示如下:
属于第c类的概率表示如下:

其中Sigmoid的下标ci表示取其第c维的输出值。分类的foal loss可以定义如下:

3.5 ReID任务#3:深入监督以获得更好的关注
如图3-1所示,可以根据不同的中间特征水平获得不同尺度的注意力响应。 受到深受监督的网络工作的启发,为了获得准确的注意力图,使用行人身份信息对其进行深度监督,深度监督有助于缓解梯度消失的问题。
为了实现这一目标,多尺度注意力图在空间上经过平均池化变成一维特征向量;然后,将特征向量连接成注意力特征向量。将注意特征提取器表示为![]() ,与3.4节中的设置类似,
,与3.4节中的设置类似,![]() 属于第c类的概率如下:
属于第c类的概率如下:

然后,将注意力分支的损失函数定义为:
其中![]() ,如果
,如果![]() 属于c级,则
属于c级,则![]() 。
。
3.6 多任务学习
如图3-1所示,这三个任务共享相同的骨干网。 在训练中,相应的三个损失函数被联合优化,最终损失为:

其中λrank,λcls和λatt为损失函数的权重。
3.7 推断(Inference)

图3-4 推断网络
在测试中,推理网络非常简单,如图3-4所示。由于课程抽样提出的三重损失可以产生具有更好泛化能力的深层特征,所以选择![]() 作为每个实例的最终重识别特征。
作为每个实例的最终重识别特征。
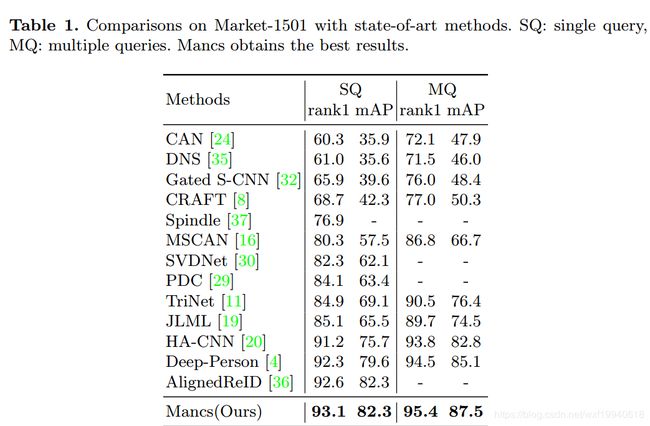
四、实验结果