Mysql基础2(引擎,体系结构,查询机制)
文章最前: 我是Octopus,这个名字来源于我的中文名--章鱼;我热爱编程、热爱算法、热爱开源。所有源码在我的个人github ;这博客是记录我学习的点点滴滴,如果您对 Python、Java、AI、算法有兴趣,可以关注我的动态,一起学习,共同进步。
相关文章:
- Mysql基础1(索引)
- Mysql基础2(引擎,体系结构,查询机制))
- Mysql基础3(事务,锁,mvcc)
- Mysql基础4(深入理解mvcc)
文章目录:
1.mysql插拔式存储引擎
2.mysql的体系结构:
3.mysql查询优化详解
1.mysql插拔式存储引擎
存储引擎介绍:
1)插拔式的插件方式
2)存储引擎是指定在表之上的,即一个库中的每一个表都可以指定专用的存储引擎;
3)不管采用什么样的存储引擎,都会在数据区,产生对应的一个frm文件(表结构定义扫描文件)
1.1CSV存储引擎
数据存储以csv文件的形式
特点:不能定义没有索引,列定义必须在not null,不能设置自增列-->不适用大表或者数据处理
CSV数据的存储用,隔开,可直接编辑CSV文件进行数据的编排-->数据安全性低
注:编辑之后,要生效使用flush table xxx命令
应用场景:数据的快速导入导出
表格直接换成csv格式
1.2 Archive 存储引擎
压缩协议进行数据的存储
数据存储为arz文件格式
特点:只支持insert和select两种操作
只允许自增ID列建立索引
行级锁
不支持事务操作
数据占用磁盘少
应用场景:日志系统
大量的设备数据采集
1.3 Memory存储引擎
数据都是存储在内存中,IO效率要比其他引擎高很多,服务重启数据丢失,内存数据表默认只有16M
特点:支持hash索引,b tree索引,默认hash(查找复杂度O(1))
字段长度都是固定长度varchar(32)=char(32)
不支持大数据存储类型字段如blog,text
表级锁
应用场景:等值查找热度较高的数据
查询结果内存中计算,大多数都是采用这种存储引擎,作为临键表存储需计算的数据
1.4 myisam存储引擎
mysql5.5版本之前的默认存储引擎,较多的系统表也还是使用这个存储引擎,系统临时表也会用到myisam存储引擎
特点: select count(*) from table无需进行数据的扫描
数据(myd)和索引(myi)分开存储
表级锁
不支持事务操作
1.5 InnoDB存储引擎
mysql5.5级以后版本的默认存储引擎
特点:支持事务的ACID操作
行级锁
聚集索引(主键索引)方式进行数据存储
支持外键保证数据完整性
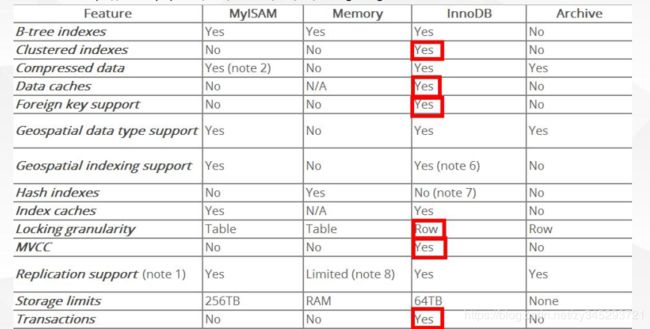
每一个存储引擎之间对比:
2.mysql的体系结构:
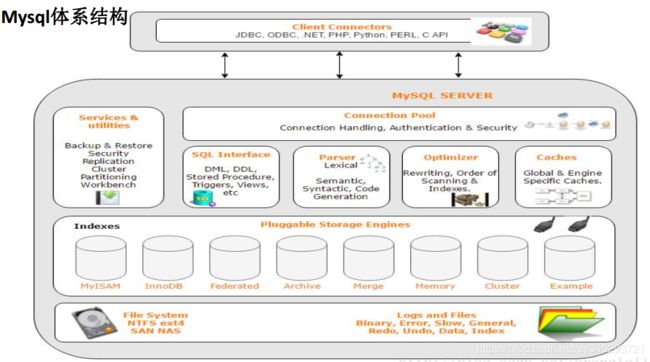
mysql的体系结构:
Client Connectors(接入方支持很多协议)
Management和Services&Utilities(系统管理和控制工具,mysqldump,mysql复制集群,分区管理)
connection pool(连接池,用户名,密码,权限校验)
SQL Interface(sql接口,接收用户sql命令,返回需要查询的结果)
Parser(解析器,SQL命令传递解析器时候被验证和解析,解析器由Lex实现)
Optimizer(查询器优化器,sql语句在查询之前会通过查询优化器进行查询优化)
Cache和Buffer(高速缓存区)查询缓存,如果查询缓存有命中的查询结果,查询语句可以直接去查询缓存中的数据
Pluggable storage Engines(插件式存储引擎-存储引擎是Mysql中具体的与文件打交道的子系统)
File System:文件系统,数据, 日志(redo,undo),索引,错误日志,查询记录,慢查询等
3.mysql查询优化详解
查询执行的路径:
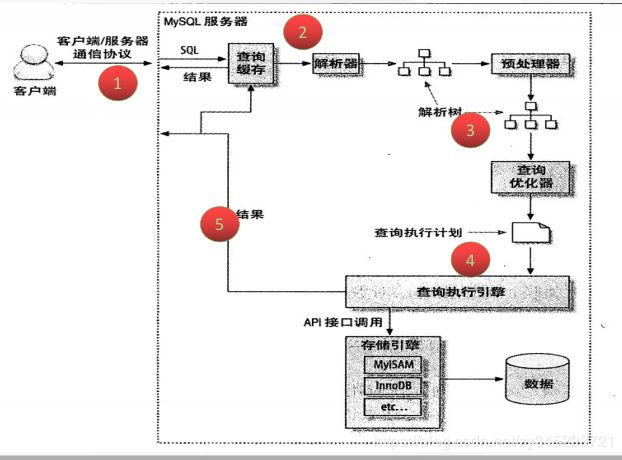
1)mysql客户端/服务器端通信
2)查询缓存
3)查询优化处理
4)查询执行引擎
5)返回客户端
mysql客户端/服务器端通信:
mysql客户端与服务器端的通信方式是“半双工”
全双工:双向通信,发送同时也可以接收数据
半双工:双向通信,同时只能接收或者发送,无法同时操作
单工:只能单一方向传送
特点和限制:客户端一旦开始发送消息,另一端要接收完整才能进行响应
客户端一旦开始接收数据没法停下来发送指令
客户端和服务端通信状态
对于一个mysql连接,或者一个线程,时刻都有一个状态来标识这个连接正在做什么,查看命令:show full processlist/show processlist
1) sleep:线程正在等待客户端发送数据
2) query:连接线程正在执行查询
3)Locked:线程正在等待表锁的释放
4)sorting result:线程正在对结果进行排序
5)Sending data:请求端返回数据
可以通过kill {id}的方式进行杀掉连接
查询缓存
工作原理:
缓存select操作的结果集合sql语句
新的select语句,先去查询缓存,判断是否存在可用的记录集;
判断标准:与缓存的sql语句,是否完全一样,区分大小写(可以认为存储了一个key-value结构,key为sql,value为查询结果集)
query_cache_type
值:0-不启用查询缓存,默认值
值:1-启用查询缓存,只要符合查询缓存的要求
值:2-启用查询缓存
query_cache_zie:允许设置query_cache_size的值最小为40k,默认1m
query_Cache_Limit:限制查询缓存区最大缓存的查询记录集,默认设置为1M
show status like 'Qcache%'命令可查看缓存情况
查询缓存--不会存在的情况:
当查询语句中有一些不确定的数据时,则不会被缓存。如包含函数now()
当查询的结果大于query_cache_limit设置的时,结果不会被缓存
对于InnoDB来说,一个语句事务修改了某个人,事务还没提交,这个表相关的查询无法被缓存
查询的表是系统表
查询语句不涉及到表
为什么mysql默认关闭了缓存开启?
1.在查询之前必须先检查是否命中缓存,浪费计算资源
2.如果这个查询可以被缓存,那么执行完成后,mysql发现查询缓存中没有这个查询,最后结果将进入缓存,带来额外系统开销;
3.针对表进行写入或更新数据时,将对应表的所有缓存设置失效
4.如果缓存很大或者碎片很多时,这个操作可以带来很大的系统消耗
查询缓存适用于业务场景:
以读为主的业务,数据生成之后就不常改变的业务,比如门户类,新闻类,报表类,论坛类
查询优化处理,查询优化处理的三个阶段:
1))解析sql:通过lex词法分析,yacc词法分析将sql语句解析成解析树
2))预处理阶段:根据msyql的语法的规则进一步检查解析树的合法性,如:检查表和列是否存在
3)) 查询优化器阶段:优化器的作用是找到最优的执行计划
查询优化器如何找到最优的执行计划?
使用等价变化规则,如5=5 and a>5改变成a>5,基于联合索引,调整条件位置
优化count,min,max函数
min函数只找最左边
myisam引擎count(*)
覆盖索引扫描,子查询优化,提前终止查询(用limit关键字或者使用不存在的条件)
in的优化:先进行排序,再采用二分查找的方式
mysql的查询优化器是基于成本计算的原则,他会尝试各种执行计划,数据抽样的方式进行验证。
select查询的序列号,标识执行的顺序:
1))id相同,执行顺序由上到下
2))id不同,如果是子查询,id的序号会递增,id值越大优先级越高,越先被执行
3))id相同又不同即两种情况同时存在,id如果相同,可以认为是一组,由上往下顺序执行;所有组中,id值越大,优先级越高,越先执行。
执行计划--select_type
查询的类型,主要用于区分普通查询,联合查询,子查询等;
simple:简单的select查询,查询中不包含子查询或union
primary:查询中包含子部分,最外层查询被标记为primary
subquery/materialized:subquery表示在select或where列表中包含子查询
union:或第二个select出现union之后,被标记为union
union result: 从union表获取结果的select
执行计划-table
直接查询或者显示表名
执行计划-type
执行额外信息-Extra
查询执行引擎
调用插件式的存储引擎的原子API的功能进行执行计划的执行
返回客户端
需要做缓存的,执行缓存操作,增量的返回结果
开始生成第一条结果时,mysql就开始往请求方逐步返回数据
好处:mysql服务器无须保存过多的数据,浪费内存,用户体验好,马上能拿到数据
如何定位sql慢?
业务驱动
测试驱动
慢查询日志
慢查询日志的配置:
show variables like 'slow_query_log'
set global slow_query_log=on
set global slow_query_log_file='/var/lib/mysql/zhangyu-slow.log'
set global log_queries_not_using_indexes=on
set global long_query_time=0.1
慢日志查询分析:

Time:日志记录的时间
User@Host:执行的用户及主机
Query_time:查询耗时时间 Lock_time:锁表时间 Rows_sent:发送给请求方的记录条数
Rows_examined:语句执行的记录数量
set timestamp:语句执行的时间点
Select .... 执行的具体语句
慢查询日志分析工具:
mysqldumpslow -t 10 -s at/var/lib/mysql/zhangyu-slow.log
其他工具:mysqlsla,pt-query-digest