对抗样本(论文解读十三):机器学习模型可解释性方法、应用与安全研究综述
机器学习模型可解释性方法、应用与安全研究综述
纪守领1 李进锋1 杜天宇1 李 博2
1(浙江大学计算机科学与技术学院网络空间安全研究中心 杭州 310027)
2(伊利诺伊大学香槟分校计算机科学学院 美国伊利诸伊州厄巴纳香槟 61822)
这是一篇中文核心期刊文章,收稿于2019-06-11,发表于计算机研究与发展。
这一篇文章总结的主要是模型的可解释性相关知识,但是同样涉及到了对抗样本相关的研究,所以对于对抗样本的相关攻防,同样具有比较大的参考价值。
文章介绍:在本文中,我们首先详细地阐述可解释性的定义和所解决的问题.然后,我们对现有的可解释性方法进行系统的总结和归类,并讨论相关方法的局限性.接着,我们简单地介绍模型可解释性相关技术的实际应用场景,同时详细地分析可解释性中的安全问题.最后,我们讨论模型可解释性相关研究所面临的挑战以及未来可行的研究方向.
文章主体分为六个部分:
- 机器学习可解释性问题
- 事前(ante-hoc)可解释性
- 事后(post-hoc)可解释性
- 可解释性应用
- 可解释性与安全性分析(对抗样本)
- 当前挑战与未来方向
其中,我们主要关注于第5部分,其他部分将做一个简单的总结和梳理。
1.机器学习可解释性问题
可解释性被定义为向人类解释或以呈现可理解的术语的能力.从本质上讲,可解释性是人类与决策模型之间的接口。在自上而下的机器学习任务中,模型通常建立在一组统计规则和假设之上,模型可解释性是验证假设是否稳健,以及所定义的规则是否完全适合任务的重要手段.自下而上的机器学习通常对应于手动和繁重任务的自动化,即给定一批训练数据,通过最小化学习误差,让模型自动地学习输入数据与输出类别之间的映射关系.可解释性旨在帮助人们理解机器学习模型是如何学习的,它从数据中学到了什么,针对每一个输入它为什么会做出如此决策以及它所做的决策是否可靠。
机器学习模型可解释性总体上可分为2类:事前(ante-hoc)可解释性和事后(post-hoc)可解释性.其中,ante-hoc可解释性指通过训练结构简单、可解释性好的模型或将可解释性结合到具体的模型结构中的自解释模型使模型本身具备可解释能力.post-hoc可解释性指通过开发可解释性技术解释已训练好的机器学习模型,又可分为全局可解释性(global interpretability) 和局部可解释性(local)。
2.事前(ante-hoc)可解释性
1)自解释模型:朴素贝叶斯模型,线性模型,决策树;
2)广义加性模型,通过线性函数组合每一单特征模型得到最终的决策形式,梯度提升树加性模型,图形化解释框架;
3)注意力机制,翻译,情感分析,看图说话,推进系统。
3.事后(post-hoc)可解释性
1)全局可解释性:规则提取,模型蒸馏(模型压缩,利用结构紧凑的学生模型来模拟结构复杂的教师模型,从而完成从教师模型到学生模型的知识迁移过程,实现对复杂教师模型的知识“蒸馏”,软目标),激活最大化,
2)局部可解释性,敏感性分析(用于分析待解释样本的每一维特征对模型最终分类结果的影响,局部梯度信息,限制支持域集(显著性掩码)),局部近似(模型拟合),反向传播(Grad,反卷积,显著性图,SmoothGrad),特征反演(充分利用模型的中间层信息),类激活映射(CAM,Grad-CAM,Guided Grad-CAM),其他方法(抽象解释和准确一致解释等)
4.可解释性应用
4.1模型验证:传统方法通过验证集来验证模型的好坏,我们可以利用模型的可解释性及相关解释方法对模型可靠性进行更细粒度的评估和验证。基于可解释性的模型验证方法一般思路如下:首先构造一个可信验证集,消除验证集中可能存在的数据偏差,保证验证数据的可靠性;然后,基于可信验证集,利用相关解释方法提供对模型整体决策行为(全局解释)或模型决策结果(局部解释)的解释;最后,基于解释方法给出的解释结果并结合人类认知,对模型决策行为和决策结果的可靠性进行验证,以检查模型是否在以符合人类认知的形式正常工作.
4.2模型诊断(调试优化):模型可解释性相关技术作为一种细粒度分析和解释模型的有效手段,可用于分析和调试模型的错误决策行为,以“诊断”模型中存在的缺陷,并为修复模型中的缺陷提供有力的支撑.针对已发现的模型“漏洞”,我们可以基于模型诊断方法给出的推理结果,采取相应的措施对模型进行“治疗”,如提高训练数据的质量、选择可靠特征以及调整模型超参等。
4.3辅组分析:基于可解释性的辅助分析技术在医疗数据分析、分子模拟以及基因分析等多个领域取得了巨大的成功,有效地解决了人工分析耗时费力的难题.
4.4知识发现:通过将可解释性相关技术与基于机器学习的自动决策系统相结合,可有效地挖掘出自动决策系统从数据中学到的新知识,以提供对所研究科学问题的深入理解,从而弥补人类认知与领域知识的局限性.医疗保健,数据挖掘等。
5.可解释性与安全性分析
模型可解释性相关技术同样可以被攻击者利用以探测机器学习模型中的“漏洞”。此外,由于解释方法与待解释模型之间可能存在不一致性,因而可解释系统或可解释方法本身就存在一定的安全风险.
5.1安全隐患消除:
人工智能安全领域相关研究表明即使决策“可靠”的机器学习模型也同样容易受到对抗样本攻击,只需要在输入样本中添加精心构造的、人眼不可察觉的扰动就可以轻松地让模型决策出错.而现存防御方法大多数是针对某一个特定的对抗样本攻击设计的静态的经验性防御,因而防御能力极其有限.然而,不管是哪种攻击方法,其本质思想都是通过向输入中添加扰动以转移模型的决策注意力,最终使模型决策出错.由于这种攻击使得模型决策依据发生变化,因而解释方法针对对抗样本的解释结果必然与其针对对应的正常样本的解释结果不同.因此,我们可以通过对比并利用这种解释结果的反差来检测对抗样本,而这种方法并不特定于某一种对抗攻击,因而可以弥补传统经验性防御的不足.
除上述防御方法外,很多学者从不同的角度提出了一些新的基于可解释性技术的对抗防御方法.
其中,Tao等人认为对抗攻击与模型的可解释性密切相关,即对于正常样本的决策结果,可以基于人类可感知的特征或属性来进行推理,而对于对抗样本的决策结果我们则通常无法解释.基于这一认知,作者提出一种针对人脸识别模型的对抗样本检测方法,该方法首先利用敏感性分析解释方法识别与人类可感知属性相对应的神经元,称之为**“属性见证”神经元**;然后,通过加强见证神经元同时削弱其他神经元将原始模型转换为属性导向模型,对于正常样本,属性导向模型的预测结果与原始模型一致,对于对抗样本二者预测结果则不一致;最后,利用2个模型预测结果的不一致性来检测对抗样本,实现对对抗攻击的防御.
Liu等人则基于对分类模型的解释,提出了一种新的对抗样本检测框架.给定一个恶意样本检测器,该框架首先选择一个以确定为恶意样本的样本子集作为子样本,然后构建一个局部解释器解释种子样本被分类器视为恶意样本的原因,并通过朝着解释器确定的规避方向来扰动每一个种子样本的方式产生对抗样本.最后,通过利用原始数据和生成的对抗样本对检测器进行对抗训练,以提高检测器对对抗样本的鲁棒性,从而降低模型的外在安全风险.
5.2安全威胁
尽管可解释性技术是为保证模型可靠性和安全性而设计的,但其同样可以被恶意用户滥用而给实际部署应用的机器学习系统带来安全威胁.比如说,攻击者可以利用解释方法探测能触发模型崩溃的模型漏洞,在对抗攻击中,攻击者还可以利用可解释方法探测模型的决策弱点或决策逻辑,从而为设计更强大的攻击提供详细的信息.
在本文中,我们将以对抗攻击为例,阐述可解释性技术可能带来的安全风险.
在白盒对抗攻击中,攻击者可以获取目标模型的结构、参数信息,因而可以利用反向传播解释方法的思想来探测模型的弱点.其中,Goodfellow等人提出了快速梯度符号攻击方法(FGSM),通过计算模型输出相对于输入样本的梯度信息来探测模型的敏感性,并通过朝着敏感方向添加一个固定规模的噪音来生成对抗样本.Papernot等人基于Grad解释方法提出了雅可比显著图攻击(JSMA),该攻击方法首先利用 Grad解释方法生成显著图,然后基于选择图来选择最重要的特征进行攻击.利用 Grad方法提供的特征重要性信息,JMSA 攻击只需要扰动少量的特征就能达到很高的攻击成功率,因而攻击的隐蔽性更强.
对于黑盒对抗攻击,由于无法获取模型的结构信息,只能操纵模型的输入和输出,因而攻击者可以利用模型无关解释方法的思想来设计攻击方法.其中,Papernot等人提出了一种针对黑盒机器学习模型的替代模型攻击方法.该方法首先利用模型蒸馏解释方法的思想训练一个替代模型来拟合目标黑盒模型的决策结果,以完成从黑盒模型到替代模型的知识迁移过程;然后,利用已有的攻击方法针对替代模型生成对抗样本;最后,利用生成的对抗样本对黑盒模型进行迁移攻击.
Li等人提出了一种基于敏感性分析解释方法的文本对抗攻击方法(TextBugger),用于攻击真实场景中的情感分析模型和垃圾文本检测器.该方法首先通过观察去掉某个词前后模型决策结果的变化来定位文本中的重要单词,然后通过利用符合人类感知的噪音逐个扰动重要的单词直到达到攻击目标.该研究表明,利用 TextBugger攻击方法可以轻松的攻破Google Cloud,Microsoft Azure,Amazon AWS,IBM Watson,Facebook fastText等平台提供的商业自然语言处理机器学习服务,并且攻击成功率高、隐蔽性强.
5.3自身安全性问题
由于采用了近似处理或是基于优化手段,大多数解释方法只能提供近似的解释,因而解释结果与模型的真实行为之间存在一定的不一致性.而最新研究表明,攻击者可以利用解释方法与待解释模型之间的这种不一致性设计针对可解释系统的新型对抗样本攻击,因而严重的威胁着可解释系统的自身安全.根据攻击目的不同,现存针对可解释系统的新型对抗样本攻击可以分为2类:1)在不改变模型的决策结果的前提下,使解释方法解释出错;2)使模型决策出错而不改变解释方法的解释结果.其中,Ghorbani等人首次将对抗攻击的概念引入到了神经网络的可解释性中并且提出了模型解释脆弱性的概念.具体地,他们将针对解释方法的对抗攻击定义为优化问题:
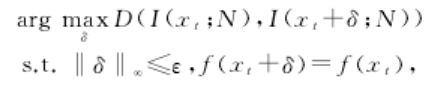
其中,I(xt;N) 为解释系统对神经网络 N 针对样本xt决策结果f(xt)的解释,δ 为样本中所需添加的扰动,D(·)用于度量扰动前后解释结果的变化.通过优化上述目标函数,可以在不改变模型决策结果的前提下,生成能让解释方法产生截然不同的解释结果的对抗样本.针对Grad,Integrated以及DeepLIFT等反向传播解释方法的对抗攻击实验证明,上述解释方法均容易受到对抗样本攻击,因而只能提供脆弱的模型解释.
与Ghorbani等人研究相反,Zhang等人提出了 Acid攻击,旨在生成能让模型分类出错而不改变解释方法解释结果的对抗样本.通过对 表示导 向 的 (如 激 活 最 大 化、特 征 反 演等)、模型导向的(如基于掩码模型的显著性 检测等)以及扰动导向的(如敏感性分析等)三大类解释方法进行Acid攻击和经验性评估,作者发现生成欺骗分类器及其解释方法的对抗样本实际上并不比生成仅能欺骗分类器的对抗样本更困难.因此,这几类解释方法同样是脆弱的,在对抗的环境下,其提供的解释结果未必可靠.此外,这种攻击还会使基于对比攻击前后解释结果的防御方法失效,导致对抗攻击更难防御.
上述研究表明:现存解释方法大多数是脆弱的,因此只能提供有限的安全保证.但由于可解释性技术潜在应用广泛,因而其自身安全问题不容忽视.因此,仅有解释是不够的,为保证机器学习及可解释性技术在实际部署应用中的安全,解释方法本身必须是安全的,而设计更精确的解释方法以消除解释方法与决策系统之间的不一致性则是提高解释方法鲁棒性进而消除其外在安全隐患的重要途径.
6.当前挑战与未来方向
6.1解释方法设计
现有关于ante-hoc可解释性的研究多局限于诸如线性回归、决策树等算法透明、结构简单的模型,对于复杂的 DNN 模型则只能依赖于注意力机制提供一个粗粒度的解释.一种直观的方法是将机器学习与因果模型相结合,让机器学习系统具备从观察数据中发现事物间的因果结构和定量推断的能力.同时,我们还可以将机器学习与常识推理和类比计算等技术相结合,形成可解释的、能自动推理的学习系统.
对于post-hoc可解释性而言,大多数的研究都在尝试采用近似的方法来模拟模型的决策行为,以从全局的角度解释模型的整体决策逻辑或者从局部的角度解释模型的单个决策结果.未来一个有前景的潜在研究方向是设计数学上与待解释模型等价的解释方法或解释模型.
6.2解释方法评估
可解释性研究领域缺乏一个用于评估解释方法的科学评估体系,只能定性评估,无法对解释方法的性能进行量化,也无法对同类型的研究工作进行精确地比较.并且,由于人类认知的局限性,人们只能理解解释结果中揭示的显性知识,而通常无法理解其隐性知识,因而无法保证基于认知的评估方法的可靠性.
对于ante-hoc可解释性而言,未来我们可以从应用场景、算法功能、人类认知这3个角度来设计评估指标.这些指标虽各有利弊但相互补充,可以实现多层次、细粒度的可解释性评估,以弥补单一评估指标的不足.
对于post-hoc可解释性而言,未来我们需要从解释结果的保真度、一致性以及不同解释方法的差异性等角度设计评价指标,对解释方法进行综合评估.
个人总结:
之前针对对抗样本的防御这一块,也想过从模型可解释性出发,是否可以找到更加底层或者鲁棒的防御方法。这篇文章关于可解释性以及对抗样本的关系,可以说是综述的比较全面了。模型可解释性本身也是基于DNNs的,而对抗样本就是针对于DNNs,所以针对于可解释性,其不仅可以应用于对抗样本的防御,而同样也面临着自身安全性的问题。而这又回到了最初的矛与盾的问题。当然,从可解释性入手,可能是不仅仅基于模型的结果及现象,能够更深入到DNNs的中间层或底层,可能又会有更多的发现及收获。