理解OAuth 2.0
本文参考:【1】http://www.ruanyifeng.com/blog/2014/05/oauth_2_0.html
【2】https://www.cnblogs.com/flashsun/p/7424071.html
【3】https://www.zifangsky.cn/1313.html
【4】https://www.zifangsky.cn/1309.html
写在最前:
本文将介绍,OAuth2.0,它的产生背景,概念,以及简单实现(待实现)
一、背景
首先说一下为什么需要auth2.0,可以这样理解,
A是行业中的小生,两手空空,
B是行业大佬,财大气粗,
C是一大批人(用户群)。
这个时候A需要借用B的用户群信息来构建自己的项目中的某项功能,但是出于资源的保护和各方面原因,B不相信A,不会让A接入自己的信任体系里面,A是无法直接获取B那边用户群的用户名和密码的,同时A又想借用B拥有的用户群信息来完善自己项目中的某些功能。
这个时候就需要auth2.0来做中介,通过一些业务流程来实现A在没有B的用户群的直接信息(账户和密码),可以间接的获取到B那边的用户群的其他信息(除了用户名和密码,如用户昵称等等),至于信息的开放程度,那得看B了。说白了就是如何使得A在没有B的用户群的密码和账号的情况下获取B的用户群的其他的信息,auth2.0就是解决这样的问题。
举个例子,有一个"云冲印"的网站,可以将用户储存在Google的照片,冲印出来。用户为了使用该服务,必须让"云冲印"读取自己储存在Google上的照片。

问题是只有得到用户的授权,Google才会同意"云冲印"读取这些照片。那么,"云冲印"怎样获得用户的授权呢?
传统方法是,用户将自己的Google用户名和密码,告诉"云冲印",后者就可以读取用户的照片了。这样的做法有以下几个严重的缺点。
(1)"云冲印"为了后续的服务,会保存用户的密码,这样很不安全。
(2)Google不得不部署密码登录,而我们知道,单纯的密码登录并不安全。
(3)"云冲印"拥有了获取用户储存在Google所有资料的权力,用户没法限制"云冲印"获得授权的范围和有效期。
(4)用户只有修改密码,才能收回赋予"云冲印"的权力。但是这样做,会使得其他所有获得用户授权的第三方应用程序全部失效。
(5)只要有一个第三方应用程序被破解,就会导致用户密码泄漏,以及所有被密码保护的数据泄漏。
OAuth就是为了解决上面这些问题而诞生的。
二、概念
OAuth是一个关于授权(authorization)的开放网络标准,在全世界得到广泛应用,目前的版本是2.0版。
简单来说,OAuth是一个协议,一种思路,一种思想,而不是一个工具——OAuth在"客户端"与"服务提供商"之间,设置了一个授权层(authorization layer)。"客户端"不能直接登录"服务提供商",只能登录授权层,以此将用户与客户端区分开来。"客户端"登录授权层所用的令牌(token),与用户的密码不同。用户可以在登录的时候,指定授权层令牌的权限范围和有效期。
"客户端"登录授权层以后,"服务提供商"根据令牌的权限范围和有效期,向"客户端"开放用户储存的资料。
客户端必须得到用户的授权(authorization grant),才能获得令牌(access token)。OAuth 2.0定义了四种授权方式。
- 授权码模式(authorization code)
- 简化模式(implicit)
- 密码模式(resource owner password credentials)
- 客户端模式(client credentials)
下面详述授权码模式。
三、授权码模式
授权码模式(authorization code)是功能最完整、流程最严密的授权模式。它的特点就是通过客户端的后台服务器,与"服务提供商"的认证服务器进行互动。
在详细讲解授权码之前,需要了解几个专用名词。它们对读懂后面的讲解,至关重要。
(1) Third-party application:第三方应用程序,本文中又称"客户端"(client),即上一节例子中的"云冲印"。
(2)HTTP service:HTTP服务提供商,本文中简称"服务提供商",即上一节例子中的Google。
(3)Resource Owner:资源所有者,本文中又称"用户"(user)。
(4)User Agent:用户代理,本文中就是指浏览器。
(5)Authorization server:认证服务器,即服务提供商专门用来处理认证的服务器。
(6)Resource server:资源服务器,即服务提供商存放用户生成的资源的服务器。它与认证服务器,可以是同一台服务器,也可以是不同的服务器。
知道了上面这些名词,就不难理解,OAuth的作用就是让"客户端"安全可控地获取"用户"的授权,与"服务商提供商"进行互动。

解释:
(A)用户访问客户端,后者将前者导向认证服务器。
(B)用户选择是否给予客户端授权。
(C)假设用户给予授权,认证服务器将用户导向客户端事先指定的"重定向URI"(redirection URI),同时附上一个授权码。
(D)客户端收到授权码,附上早先的"重定向URI",向认证服务器申请令牌。这一步是在客户端的后台的服务器上完成的,对用户不可见。
(E)认证服务器核对了授权码和重定向URI,确认无误后,向客户端发送访问令牌(access token)和更新令牌(refresh token)。
很难理解对不对,下面还是用一个例子来解释:
举个例子,你想登录豆瓣去看看电影评论,但你丫的从来没注册过豆瓣账号,又不想新注册一个再使用豆瓣,怎么办呢?不用担心,豆瓣已经为你这种懒人做了准备,用你的qq号可以授权给豆瓣进行登录,请看。
第一步:在豆瓣官网点击用qq登录
第二步:跳转到qq登录页面输入用户名密码,然后点授权并登录

第三步:跳回到豆瓣页面,成功登录

这几秒钟之内发生的事情,在无知的用户视角看来,就是在豆瓣官网上输了个qq号和密码就登录成功了。在一些细心的用户视角看来,页面经历了从豆瓣到qq,再从qq到豆瓣的两次页面跳转。但作为一群专业的程序员,我们还应该从上帝视角来看这个过程。
简单来说,上述例子中的豆瓣就是客户端,QQ就是认证服务器,OAuth2.0就是客户端和认证服务器之间由于相互不信任而产生的一个授权协议。呵呵,要是相互信任那QQ直接把自己数据库给豆瓣好了,你直接在豆瓣输入qq账号密码查下数据库验证就登陆呗,还跳来跳去的多麻烦。
先上一张图,该图描绘了只几秒钟发生的所有事情用上帝视角来看的流程。
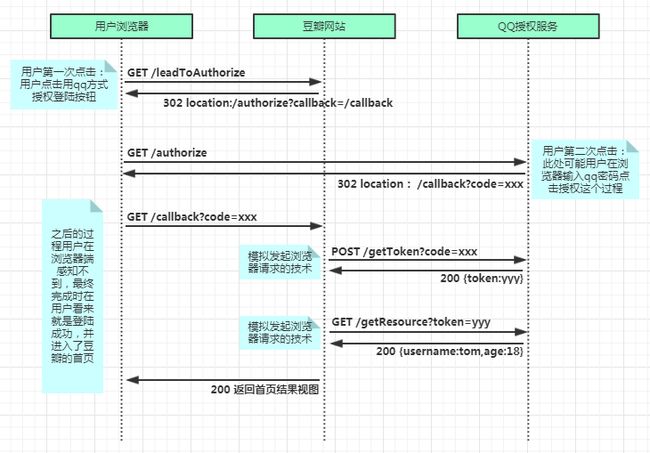
这张图就对应着本节刚开始非常抽象的那张图,现在看一下是不是好理解多了。下面就再详细的解释一下这其中的猫腻。
第一步:在豆瓣官网点击用qq登录
当你点击用qq登录的小图标时,实际上是向豆瓣的服务器发起了一个 http://www.douban.com/leadToAuthorize 的请求,豆瓣服务器会响应一个重定向地址,指向qq授权登录
浏览器接到重定向地址http://www.qq.com/authorize?callback=www.douban.com/callback,再次访问。并注意到这次访问带了一个参数是callback,以便qq那边授权成功再次让浏览器发起这个callback请求。不然qq怎么知道你让我授权后要返回那个页面啊,每天让我授权的像豆瓣这样的网站这么多。
至于访问这个地址之后,qq那边做出怎样的回应,就是第二步的事情了。总之第一步即对应了图中的这些部分。

第二步:跳转到qq登录页面输入用户名密码,然后点授权并登录
上一步中浏览器接到重定向地址并访问 http://www.qq.com/authorize?callback=www.douban.com/callback。
qq的服务器接受到了豆瓣访问的authorize,在次例中所给出的回应是跳转到qq的登录页面,用户输入账号密码点击授权并登录按钮后,一定还会访问qq服务器中校验用户名密码的方法,若校验成功,该方法会响应浏览器一个重定向地址,并附上一个code(授权码)。由于豆瓣只关心像qq发起authorize请求后会返回一个code,并不关心qq是如何校验用户的,并且这个过程每个授权服务器可能会做些个性化的处理,只要最终的结果是返回给浏览器一个重定向并附上code即可,所以这个过程在图中并没有详细展开。现把展开图画给大家。

第三步:跳回到豆瓣页面,成功登录
这一步背后的过程其实是最繁琐的,但对于用户来说是完全感知不到的。用户在QQ登录页面点击授权登陆后,就直接跳转到豆瓣首页了,但其实经历了很多隐藏的过程。
首先接上一步,QQ服务器在判断登录成功后,使页面重定向到之前豆瓣发来的callback并附上code授权码,即 callback=www.douban.com/callback 。
页面接到重定向,发起 http://www.douban.com/callback 请求。
豆瓣服务器收到请求后,做了两件再次与QQ沟通的事,即模拟浏览器发起了两次请求。一个是用拿到的code去换token,另一个就是用拿到的token换取用户信息。最后将用户信息储存起来,返回给浏览器其首页的视图。到此OAuth2.0授权结束。

此篇终。