Apache Hudi architecture and implementation research
There are 2 parts of the article,as follows:
1.Hudi scenario and concepts
2.Performance bottlenecks
1.Hudi scenario and concepts
There is a lot of concepts , some is similar as HBase.Some is new concepts.But What is the relationship with scenario and concepts?

This is a mind map about Hudi.Mind map is better than text.if we can connecting scenarios and concepts.we will run the engine better.There is 3 parts of it .I will introduce these parts in turn
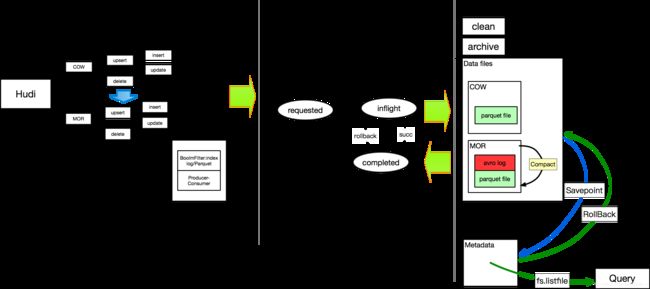
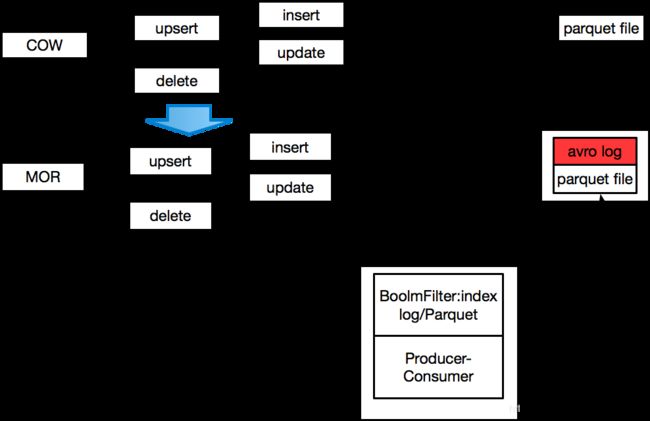
This is the Common scenarios in hudi;Is copy on write and merge on read mode .Mor is a extention of copy on write
Mainly differents is MOR mode has avro log;
In fact,Many MOR classes are extend from COW
For example:
HoodieMergeOnReadTable
MergeOnReadLazyInsertIterable
Both the cow or mor operation will trigger Timeline change.
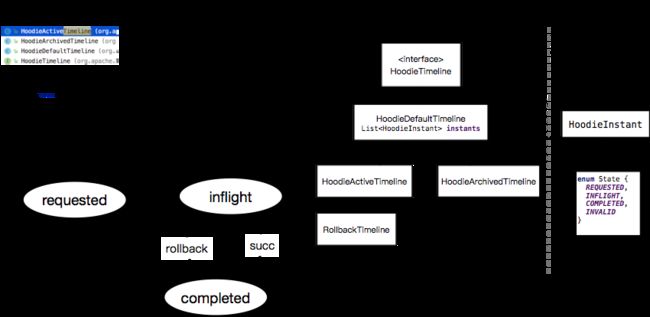
Timeline is the core of Hudi.Basically all operation are related to Timeline.
Their are 3 classes represent active,archive,and rollback timeline
A timeline contains a instant list . a instant object contains a state.
I draw a stats Diagram about the stats transition. stats transite in diff type in HoodieTimeline class.
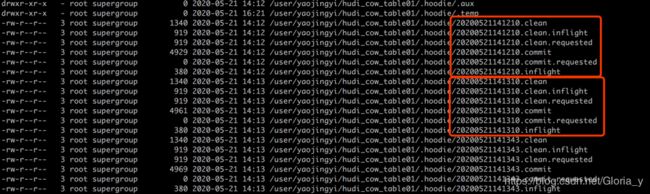
Timeline classes control instant to different status.But Finally it will write many metadata files to HDFS.
So we can see next page, about what is the hudi’s file management .
File management policy is important in hudi.If we run a spark job to write data into hudi table.Infact you only needs set the basePath and set the key configuration instead of a DDL SQl.
Because hudi store the metadata in HDFS directory.and if we need read metadata it will trigger the HDFS operation too.
There is Instant metadata file,Log file,Parquet file and Partitions metadata file.
We will continue to talk about file management in the finally part.

This is the whole relationship diagram of hudi,and I add the class name in the corresponding node.
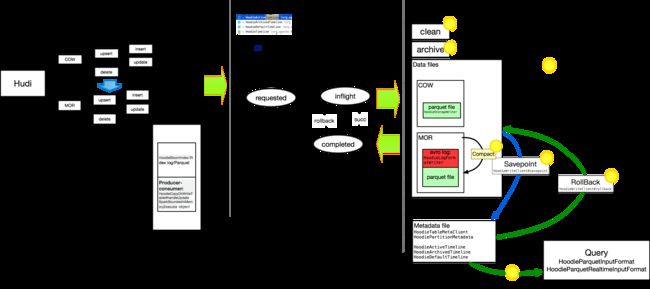
Those repationship and implaments closely related to engine performace.
2.Performance bottlenecks
When we know the relationship between scenarios ,concepts and implementation
we can locate the performance bottleneck of the engine.
first performance bottleneck :

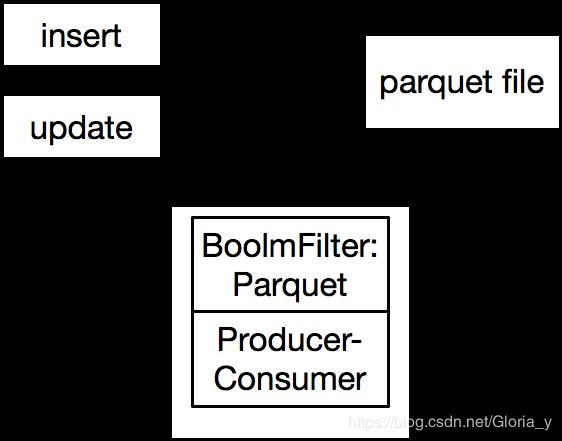
In hudi’s community .they are talking about how to reduce the operation on HDFS.
Multiple metadata files => get metadata from index file and single metadata file.Reduce HDFS namenode pressure and improve performance of reading hudi metadata
The second performance bottlenecks is Write amplifications and Read Perspiration
Engineers never stop optimizing it in storage engine.
It means if you write some data into storage,More data will read and write on disk.
In COW mode,'update' operation will trigger 'Write amplifications and Read Perspiration'
In MOR mode,'update' and 'compaction' will trigger 'Write amplifications and Read Perspiration'.
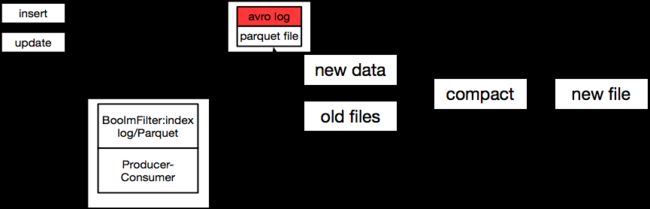
we need to find the appropriate compact parameter.we have to know When to trigger compact and how does to select files
The above is the research of performance analysis.
I think there is more challenge and opportunity in Hudi