高斯分布
高斯分布
- 高斯分布概念
- 协方差矩阵的传播(covariance propagation)
- 多元高斯概率密度函数的拆分与组合
- 高斯分布边缘化(Marginalization)
- 高斯分布的独立性与不相关性
高斯分布概念
高斯分布(正态分布)是一个常见的连续概率分布。正态分布的数学期望值或期望值 μ {\displaystyle \mu } μ 等于位置参数,决定了分布的位置;其方差 σ 2 \sigma ^{2} σ2的开平方或标准差 σ \sigma σ 等于尺度参数,决定了分布的幅度。正态分布的概率密度函数曲线呈钟形,因此人们又经常称之为钟形曲线(类似于寺庙里的大钟,因此得名)。我们通常所说的标准正态分布是位置参数 μ = 0 \mu = 0 μ=0,方差 σ 2 = 1 \sigma^{2}=1 σ2=1的正态分布。(源自wiki百科)

若随机变量 X X X服从一个位置参数为 μ \mu μ、方差为 σ 2 \sigma^2 σ2的正态分布,可以记为 X X X~ N ( μ , σ 2 ) N(\mu,\sigma^2) N(μ,σ2),则其概率密度函数为 f ( x ) = 1 σ 2 π e x p ( − ( x − μ ) 2 2 σ 2 ) f(x) = \frac{1} {{\sigma\sqrt{2\pi}}}exp(-\frac{(x-\mu)^2}{2\sigma^2}) f(x)=σ2π1exp(−2σ2(x−μ)2)
从上面可以看到,一维高斯分布可以用变量均值和方差进行描述,那么二维高斯分布的呢?一维正态分布只有一个变量,则二维高斯分布则包含有两个变量,二维高斯分布的均值 μ \mu μ由两个变量的均值描述,其方差由变量的协方差矩阵进行描述,协方差矩阵 Σ \Sigma Σ 表示的是两个变量之间的关系。
μ = ( μ a μ b ) Σ = ( σ x 2 ρ σ x σ y ρ σ x σ y σ y 2 ) \mu = {\mu_a \choose \mu_b } \quad \Sigma = \begin{pmatrix} \sigma^2_x & \rho\sigma_x\sigma_y \\ \rho\sigma_x\sigma_y & \sigma^2_y \end{pmatrix} μ=(μbμa)Σ=(σx2ρσxσyρσxσyσy2)
其中, ρ σ x σ y \rho\sigma_x\sigma_y ρσxσy和 ρ σ y σ x \rho\sigma_y\sigma_x ρσyσx分别为两个变量的协方差值。协方差的计算公式如下:
C o v ( X , Y ) = E [ ( X − E ( X ) ( Y − E ( Y ) ] = E [ X Y ] − E [ X ] E [ Y ] \begin{aligned} Cov(X,Y) &= E[(X-E(X)(Y-E(Y)] \\ &= E[XY] - E[X]E[Y] \end{aligned} Cov(X,Y)=E[(X−E(X)(Y−E(Y)]=E[XY]−E[X]E[Y]
协方差为正,则说明这两个变量呈正相关,为零则不相关,为负则为负相关。
对于一个二维高斯随机变量 x x x~ N ( μ , Σ ) N(\mu,\Sigma) N(μ,Σ),其概率密度可以表示为:
P ( x ) = 1 ∣ 2 π Σ ∣ e x p ( − 1 2 ( x − μ ) T Σ − 1 ( x − μ ) ) P(x) = \frac{1}{|2\pi\Sigma|}exp(-\frac{1}{2}(x-\mu)^T\Sigma^{-1}(x-\mu)) P(x)=∣2πΣ∣1exp(−21(x−μ)TΣ−1(x−μ))
其图形可表示为:

协方差矩阵的传播(covariance propagation)
- 一个高斯随机变量的线性变换仍是高斯随机变量。
假设一个高斯随机变量 x x x~ N ( μ , Σ ) N(\mu,\Sigma) N(μ,Σ),如果有 x ′ = A x + b x^{\prime} = Ax + b x′=Ax+b,则 x ′ x^{\prime} x′~ N ( μ ′ , Σ ′ ) N(\mu^{\prime},\Sigma^{\prime}) N(μ′,Σ′)。其中, μ ′ \mu^{\prime} μ′和 Σ ′ \Sigma^{\prime} Σ′为:
μ ′ = E [ x ′ ] = E [ A x + b ] = A E [ x ] + b = A μ + b \mu^\prime = E[x^{\prime}] = E[Ax+b] = AE[x] + b = A\mu + b μ′=E[x′]=E[Ax+b]=AE[x]+b=Aμ+b
Σ ′ = c o v [ x ′ ] = E [ ( x ′ − E [ x ′ ] ) ( x ′ − E [ x ′ ] ) ] = A E [ ( x − μ ) ( x − μ ) T ] A T = A Σ A T \begin{aligned} \Sigma^\prime &= cov[x^{\prime}] = E[(x^\prime - E[x^\prime])(x^\prime-E[x^\prime])] \\ &= AE[(x-\mu)(x-\mu)^T]A^T \\ &= A{\Sigma}A^T \end{aligned} Σ′=cov[x′]=E[(x′−E[x′])(x′−E[x′])]=AE[(x−μ)(x−μ)T]AT=AΣAT
- 多个独立的高斯随机变量的线性组合仍是高斯随机变量。
假设 x 1 ∼ N ( μ 1 , Σ 1 ) x_1 \sim N(\mu_1,\Sigma_1) x1∼N(μ1,Σ1); x 2 ∼ N ( μ 2 , Σ 2 ) x_2 \sim N(\mu_2,\Sigma_2) x2∼N(μ2,Σ2)
且 x ′ = A x 1 + B x 2 x^\prime = Ax1 + Bx2 x′=Ax1+Bx2,有:
μ ′ = E [ x ′ ] = A μ 1 + B μ 2 Σ ′ = c o v [ x ′ ] = A Σ 1 A T + B Σ 2 B T \begin{aligned}\mu^\prime &= E[x^\prime]= A\mu_1 + B\mu_2 \\ \Sigma^\prime &= cov[x^\prime] = A\Sigma_1A^T + B\Sigma_2B^T\end{aligned} μ′Σ′=E[x′]=Aμ1+Bμ2=cov[x′]=AΣ1AT+BΣ2BT
多元高斯概率密度函数的拆分与组合
-
多元高斯联合分布可拆分为一个先验分布与条件分布的乘积。(拆分公式)
有 P ( x ) = P ( x 1 ∣ x 2 ) P ( x 2 ) P(x)=P(x_1|x_2)P(x_2) P(x)=P(x1∣x2)P(x2),假设该分布为: x = [ ( x 1 x 2 ) ] x = [{x_1 \choose x_2}] x=[(x2x1)]~ N ( [ ( μ 1 μ 2 ) ] , [ Σ 11 Σ 12 Σ 21 Σ 22 ] ) N([{\mu_1 \choose \mu_2}],\begin{bmatrix} \Sigma_{11} & \Sigma_{12} \\ \Sigma_{21} & \Sigma_{22} \end{bmatrix}) N([(μ2μ1)],[Σ11Σ21Σ12Σ22]),那么条件概率密度函数与先验(边缘)概率密度函数分别为:
P ( x 1 ∣ x 2 ) ∼ N ( μ 1 + Σ 12 Σ 22 − 1 ( x 2 − μ 2 ) , Σ 11 − Σ 12 Σ 22 − 1 Σ 21 ) P ( x 2 ) ∼ N ( μ 2 , Σ 22 ) P(x_1|x_2) \sim N(\mu_1+\Sigma_{12}\Sigma_{22}^{-1}(x_2-\mu_2),\Sigma_{11}-\Sigma_{12}\Sigma_{22}^{-1}\Sigma_{21}) \\ P(x_2) \sim N(\mu_2,\Sigma_{22}) P(x1∣x2)∼N(μ1+Σ12Σ22−1(x2−μ2),Σ11−Σ12Σ22−1Σ21)P(x2)∼N(μ2,Σ22)
我们把上式称之为多元高斯联合分布的拆分公式,这个公式是如何来的呢,可以先使用舒尔补求逆,然后化简得到,有时间的话我会出一篇讲边缘化的博客,里面会证明这个式子。总之,我们可以把上式称之为拆分公式。 -
反之,一个多元高斯联合分布也可以由先验概率和条件概率组合而成。(组合公式)
如果有 P ( x 2 ) ∼ N ( μ 2 , Σ 22 ) P(x_2) \sim N(\mu_2,\Sigma_{22}) P(x2)∼N(μ2,Σ22), P ( x 1 ∣ x 2 ) ∼ N ( H x 2 , R ) P(x_1|x_2) \sim N(Hx_2,R) P(x1∣x2)∼N(Hx2,R),将两者组成有:
x = [ ( x 1 x 2 ) ] ∼ N ( [ ( H μ 2 μ 2 ) ] , [ H Σ 22 H T H Σ 22 Σ 22 H T Σ 22 ] ) x=[{x_1\choose x_2}] \sim N([{H\mu_2 \choose \mu_2}],\begin{bmatrix} H\Sigma_{22}H^T & H\Sigma_{22} \\ \Sigma_{22}H^T & \Sigma_{22}\end{bmatrix}) x=[(x2x1)]∼N([(μ2Hμ2)],[HΣ22HTΣ22HTHΣ22Σ22])
同上,证明可以先不管,但如果你想证也是简单的,我们把上式称之为组合公式。
高斯分布边缘化(Marginalization)
定义:联合概率中,把最终结果中不需要的那些事件合并成其事件的全概率而消失(对离散随机变量用求和得全概率,对连续随机变量用积分得全概率),这称为边缘化(marginalization)。
假设有一个离散的联合分布律如下图表示:
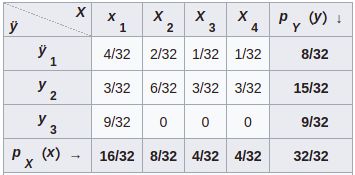
x的边缘概率可表示为: p X ( x i ) = ∑ j p ( x i , y j ) p_X(x_i)=\sum\limits_{j} p(x_i,y_j) pX(xi)=j∑p(xi,yj);y的边缘概率可以表示为: p Y ( y j ) = ∑ i p ( x i , y j ) p_Y(y_j)=\sum\limits_{i} p(x_i,y_j) pY(yj)=i∑p(xi,yj)。
可以看到要求某一变量的边缘概率,要对另一变量进行求和。
那么在连续概率分布(如高斯分布中)呢?可以假设有两个变量 x 1 , x 2 x_1,x_2 x1,x2,我们要求 x 1 x1 x1的边缘分布,实际上就是把 x 2 x_2 x2边缘化。
∫ x 2 P ( x 1 , x 2 ) d x 2 = ∫ x 2 P ( x 2 ∣ x 1 ) P ( x 1 ) d x 2 = ∫ x 2 P ( x 2 ∣ x 1 ) d x 2 P ( x 1 ) = P ( x 1 ) ∼ N ( μ 1 , Σ 11 ) \begin{aligned} \int_{x_2}P(x_1,x_2)dx_2 &=\int_{x_2}P(x_2|x_1)P(x_1)dx_2 \\ &=\int_{x_2}P(x_2|x_1)dx_2P(x_1)\\ &= P(x_1) \sim N(\mu_1,\Sigma_{11})\end{aligned} ∫x2P(x1,x2)dx2=∫x2P(x2∣x1)P(x1)dx2=∫x2P(x2∣x1)dx2P(x1)=P(x1)∼N(μ1,Σ11)
可以看到,对于高斯分布的边缘化,我们只需要在协方差矩阵将无关的变量(对应变量的行和列)去除掉即可。
N ( μ 1 , Σ 11 ) = N ( [ ( μ 1 μ 2 ) ] , [ Σ 11 Σ 12 Σ 21 Σ 22 ] ) N(\mu_1,\Sigma_{11}) = N([{\mu_1 \choose \sout{\mu_2}}], \begin{bmatrix} \Sigma_{11} & \sout{\Sigma_{12}} \\ \sout{\Sigma_{21}} & \sout{\Sigma_{22}}\end{bmatrix}) N(μ1,Σ11)=N([(μ2μ1)],[Σ11Σ21Σ12Σ22])
高斯分布的独立性与不相关性
由上述高斯分布的拆分公式中,有 P ( x ) = P ( x 1 ∣ x 2 ) P ( x 2 ) P(x)=P(x_1|x_2)P(x_2) P(x)=P(x1∣x2)P(x2)。
右式分别满足以下分布:
P ( x 1 ∣ x 2 ) ∼ N ( μ 1 + Σ 12 Σ 22 − 1 ( x 2 − μ 2 ) , Σ 11 − Σ 12 Σ 22 − 1 Σ 21 ) P ( x 2 ) ∼ N ( μ 2 , Σ 22 ) P(x_1|x_2) \sim N(\mu_1+\Sigma_{12}\Sigma_{22}^{-1}(x_2-\mu_2),\Sigma_{11}-\Sigma_{12}\Sigma_{22}^{-1}\Sigma_{21}) \\ P(x_2) \sim N(\mu_2,\Sigma_{22}) P(x1∣x2)∼N(μ1+Σ12Σ22−1(x2−μ2),Σ11−Σ12Σ22−1Σ21)P(x2)∼N(μ2,Σ22)
假设 x 1 x_1 x1和 x 2 x_2 x2不相关,那么有: Σ 12 = 0 \Sigma_{12} = 0 Σ12=0 ,两者协方差为0。
Σ 12 = E [ ( x 1 − μ 1 ) ( x 2 − μ 2 ) ] = E [ x 1 x 2 T ] − E [ x 1 ] E [ x 2 ] T = 0 \Sigma_{12}=E[(x_1-\mu_1)(x_2-\mu_2)]=E[x_1x_2^T] - E[x_1]E[x_2]^T=0 Σ12=E[(x1−μ1)(x2−μ2)]=E[x1x2T]−E[x1]E[x2]T=0
根据独立的概念, E ( x 1 x 2 ) = E ( x 1 ) E ( x 2 ) E(x_1x_2)=E(x_1)E(x_2) E(x1x2)=E(x1)E(x2),该式和上式显然一样。
说明了,高斯分布的变量的不相关即为变量独立。
好了,关于高斯分布就告一段落。
如果我的文章对你有帮助,欢迎关注,点赞,评论。
参考:
https://games-cn.org/games-webinar-20180426-43/