RHCS集群套件—HA高可用集群部署(ricci+luci+fence)双机热备
一、基本概念
HA(High Available)高可用集群是减少服务中断时间为目的的服务器集群技术,也是保证业务连续性的有效解决方案。集群,一般有两个或者两个以上的计算机组成,这些组成集群的计算机被称为节点。
其中由两个节点组成的集群被称为双机热备,即使用两台服务器互相备份,当其中一台服务器出现问题时,另一台服务器马上接管服务,来保护用户的业务程序对外不间断提供的服务,当然集群系统更可以支持两个以上的节点,提供比双机热备更多、更高级的功能,把因软件/硬件/人为造成的故障对业务的影响降低到最小程度。
在集群中为了防止服务器出现 “脑裂” 的现象,集群中一般会添加Fence设备,有的是使用服务器本身的的硬件接口称为内部Fence,有的则是外部电源设备称为外部Fence,当一台服务出现问题响应超时的时候,Fence设备会对服务器直接发出硬件管理指令,将服务器重启或关机,并向其他节点发出信号接管服务。
在红帽系统中我们通过luci和ricci来配置管理集群,其中luci安装在一台独立的计算机上或者节点上,luci只是用来通过web访问来快速的配置管理集群的,它的存在与否并不影响集群。ricci是安装在每个节点上,它是luci与集群给节点通信的桥梁。
在HA集群坏境中,每个节点之间互相发送探测包进行判断节点的存活性。一般会有专门的线路进行探测,这条线路称为“心跳线”。假设node1的心跳线出问题,则node2和node3会认为node1出问题,然后就会把资源调度在node2或者node3上运行,但node1会认为自己没问题不让node2或者node3抢占资源,此时就出现了脑裂(split brain)。
此时如果在整个环境里有一种设备直接把node1断电,则可以避免脑裂的发生,这种设备叫做fence或者stonith(Shoot The Other Node In The Head爆头哥)。
二、HA高可用集群配置
主机环境: 6.5版本redhat
实验准备:
1.server1、server4时间同步
![]()
![]()
2.添加每个节点的解析


实验环境:
集群管理主机:(也可另开启一台主机server2,安装luci即可)
server1:172.25.51.1
集群节点:
server1:172.25.51.1
server4:172.25.51.4
实验步骤:
1、server1、server4设置集群节点,安装ricci并设置密码
server1:
[root@server1 ~]# yum install ricci -y
[root@server1 ~]# passwd ricci ##设置密码
[root@server1 ~]# /etc/init.d/ricci start
[root@server1 ~]# chkconfig ricci on ##设置开机自启
server4:
[root@server4 ~]# yum install ricci -y
[root@server4 ~]# passwd ricci ##设置密码
[root@server4 ~]# /etc/init.d/ricci start
[root@server4 ~]# chkconfig ricci on ##设置开机自启
示图:设置密码

2、server1设置集群管理主机,安装luci
[root@server1 ~]# yum install luci -y
[root@server1 ~]# /etc/init.d/luci start
3、物理机:
<1>主机名解析
[root@foundation51 ~]# vim /etc/hosts ##添加集群管理主机名解析
![]()
4、配置集群:
<1>web访问luci配置集群,https://server1:8084
示图:获取证书
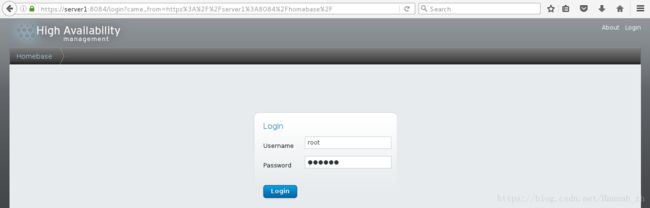
<2>登陆,账户密码为管理主机的root及其密码
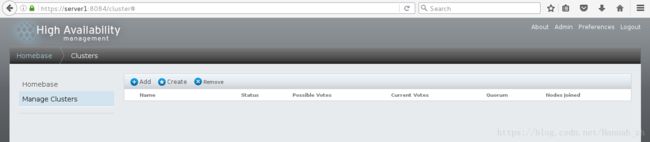
<3>创建集群并添加两个节点

示图:创建集群后,出现以下wait状态
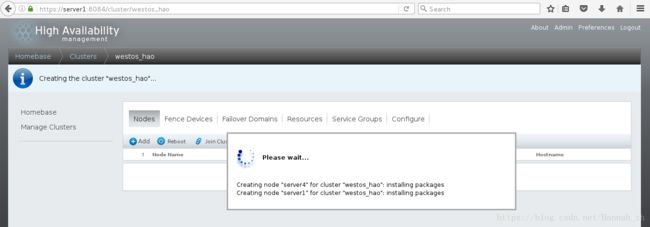
此时,重启server1的ricci、luci和server4的ricci

![]()
则集群创建成功
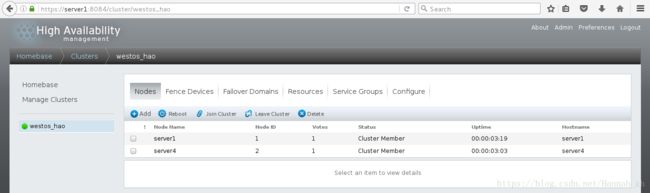
示图:集群管理主机上查看集群状态(在节点server1上查看,状态中的Local就在server1上显示)

<4>server1、server4添加fence
1>查找安装包并下载
[root@foundation51 ~]#yum install fence-virtd.x86_64 -y
[root@foundation51 ~]#yum install fence-virtd-libvirt.x86_64 -y
[root@foundation51 ~]#yum install fence-virtd-multicast.x86_64
2>执行命令并按要求配置(一路回车)
[root@foundation51 ~]# fence_virtd -c
示图:配置结果

3>采集随即信息到生成的key文件里
[root@foundation51 cluster]# dd if=/dev/urandom of=/etc/cluster/fence_xvm.key bs=128 count=1
![]()
4>启动fence_virtd服务
[root@foundation51 ~]# systemctl restart fence_virtd.service
![]()
5>将物理机产生的key文件传给server1、server4
[root@foundation51 ~]# scp /etc/cluster/fence_xvm.key [email protected]:/etc/cluster/
[root@foundation51 ~]# scp /etc/cluster/fence_xvm.key [email protected]:/etc/cluster/
![]()
![]()
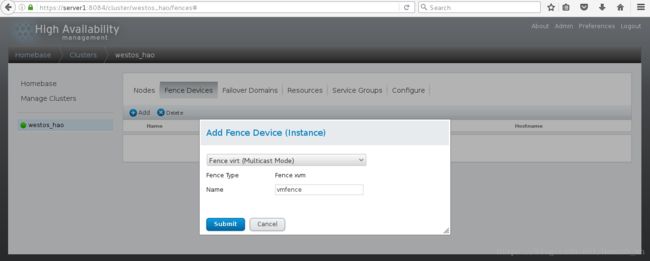
6>通过luci给集群添加fence,选择Fence virt(MulticastMode )
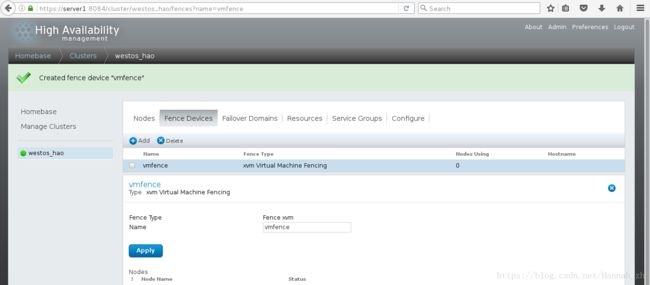
7>然后点击Nodes里的节点server1为集群添加fence
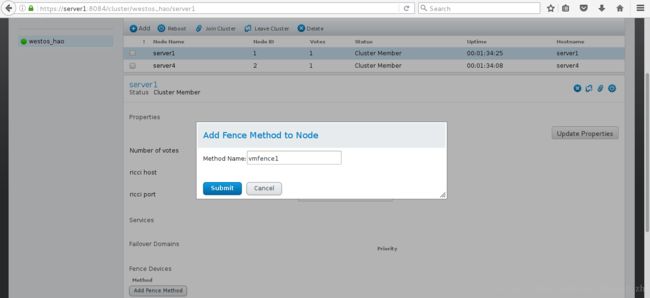
8>选择vmfence(xvm Virtual Machine Fencing)其中Domain填写虚拟机的名字或UUID
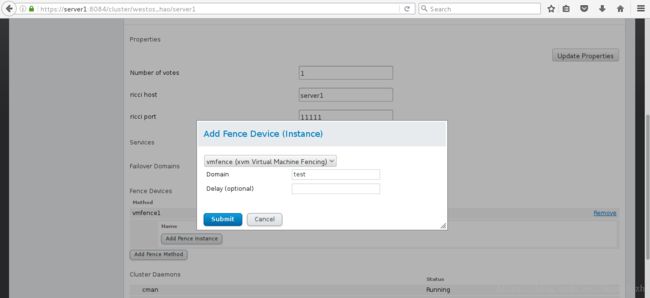
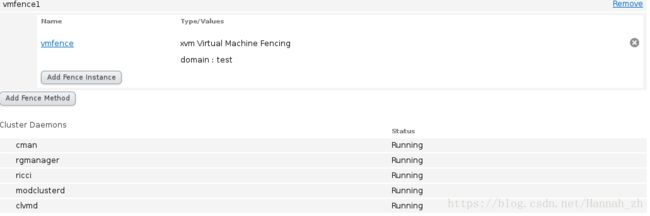
9>server4同上

10>测试集群节点是否成功添加fence
[root@server1 ~]# fence_node server4
示图:在server1中执行命令,可以看到server4主机关闭又自动重启
![]()
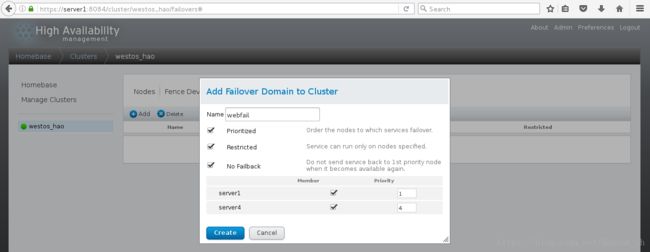
<5>添加故障转移域
Prioritized设置优先级,数字越小,优先级越高
Restricted设置只在勾选节点中运行
No Failback设置当优先级高的节点恢复时不会接管正在运行的服务
<6>在Resource中添加资源,此处添加虚拟ip和httpd的脚本(集群要安装httpd)
1>添加虚拟ip

2>添加httpd脚本
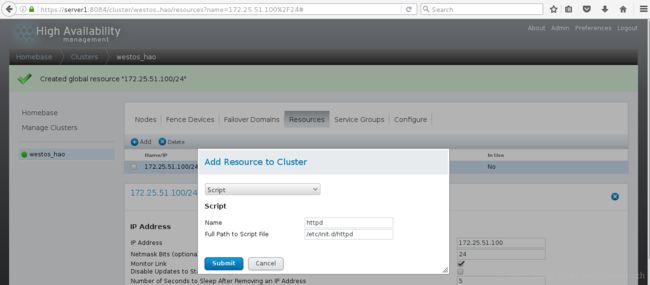
<7>设置service group
Automatically Start This Service设置自动开启服务
Run Exclusive 设置当运行此服务时不再运行其他服务

点击 Add Resource,增加Resource中上一步配置的虚拟IP和httpd脚本
测试:
优先级:server1>server4
<1>web服务开启节点server1上
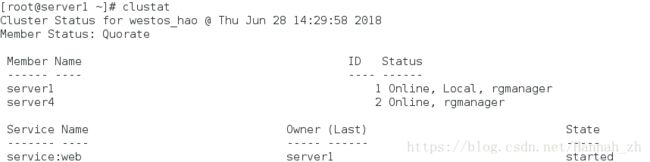

示图:虚拟ip停留在server1
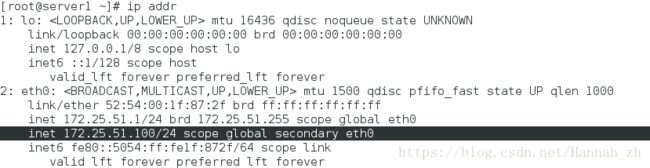
<2>server内核崩溃,server1主机将在fence的作用下重启,刷新页面可看到:
[root@server1 ~]# echo c > /proc/sysrq-trigger
示图1:
![]()
示图2:此时web服务运行在server4上
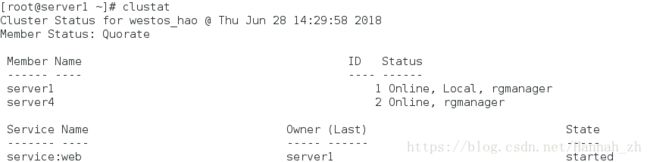
示图3:虚拟ip停留在server4

注意:当server4的web服务disabled后,killall -9 httpd,server1不会主动接管服务。但是,当web服务恢复后,由于server1优先级高,server1主动开启web服务。
示图:此栏可设定web节点状态
![]()