Linux内存管理
本文主要是总结Linux在80x86(IA-32)微处理器下的内存管理。
内存地址空间的划分
8086微处理器是X86时代开始的标志。在8086之前,都是4位机和8位机的天下,程序访问内存需要给出内存的实际物理地址,程序的可控性弱,重定位难。8086微处理器在内存寻址方面引入了分段机制,目标寻址空间达到了1M。80286微处理器引入了保护模式,在保护模式下程序不能再随意访问任意的物理内存。实模式是80X86微处理器向前兼容的模式,在实模式下,80X86等同于16位的8086微处理器,只使用低20位地址线,只能寻址1M的物理地址空间。从80386开始,CPU引入虚拟8086模式,可以在保护模式下运行8086环境。80386微处理器的地址总线的位宽和内部数据总线的位宽都是32位,寻址空间可达4GB。
内存寻址
地址类型
-
物理地址(physical address)
处理器通过地址总线访问的内存称为物理内存。物理内存被组织成的一个8位的字节序列,每个字节分配个唯一的地址,这个地址叫做物理地址。 -
线性地址(linear address)
内存对程序来说是一个单一,连续的地址空间,这个空间叫线性地址空间。代码,数据,栈都在这个地址空间内。线性地址空间以字节编址,在线性地址空间中字节的地址叫做线性地址。 -
逻辑地址(logical address)
内存对于程序来说是一组独立的地址空间,这个独立地址空间叫段。代码,数据和栈分别在不同的段中。为了访问段中的字节,引入了逻辑地址。逻辑地址包含段选择符(segment selector)和偏移(offset)。段选择符标识被访问的段,偏移用于定位段地址空间中的字节。系统中定义的所有段都被映射到处理器的线性地址空间。为了内存寻址,处理器需要将逻辑地址转换成线性地址。这个转换对于应用程序来说是透明的。 -
虚拟地址(virtual address)
在Intel IA-32手册里并没有提到这个术语,但Linux内核中用到了这个概念,在Linux内核中虚拟地址和线性地址可以不做区分。
内存管理单元(MMU)
MMU(Memory Managment Unit)是负责CPU的内存访问请求的计算机硬件,MMU的作用有两个:地址翻译,内存保护。
-
地址翻译:
逻辑地址 --(段表)–> 线性地址 --(页表)–> 物理地址。 -
内存保护:
采用页式内存管理时可以提供页粒度级别的保护,允许对单元内存页设置读,写,执行权限。
Linux中,分段机制的使用很有限。实际上,分段和分页在功能上有冗余,分段和分页都可以隔离不同进程的物理地址空间。Linux的设计目标是对各种体系结构有广泛的可移植性,而RISC架构对分段的支持有限,Linux最终选择了使用分页内存管理。Linux内核将所有类型的段的段基址(segment base address)都设为0,段的长度设置为最大,这使得所有段都重合了,也就间接的关闭了段映射。
-
两级分页机制
两级分页机制将32位的线性地址分为三段,低12位表示页内偏移(Offset),中间10位为页表(Table),高10位为页目录(Directory)。 页框的大小为4K,页目录只有一个,有210个页目录项,每个页目录项对应一个二级页表,每个二级页表有210个页表项。 -
线性地址转换为物理地址步骤:
- CR3寄存器存放当前页目录表的物理基地址,线性地址的22~31位作为页目录表的偏移,根据"页目录物理基地址+偏移"找到对应的页目录项,从页目录项中找出页表的物理基地址。
- 线性的地址的12~21位作为页表的偏移,根据“页表物理基地址 + 偏移”找到对应的页表项,从页表项里找到物理页框的地址。
- 线性地址的0~11位作为物理页框的偏移地址,实际物理地址=物理页框地址+偏移地址。

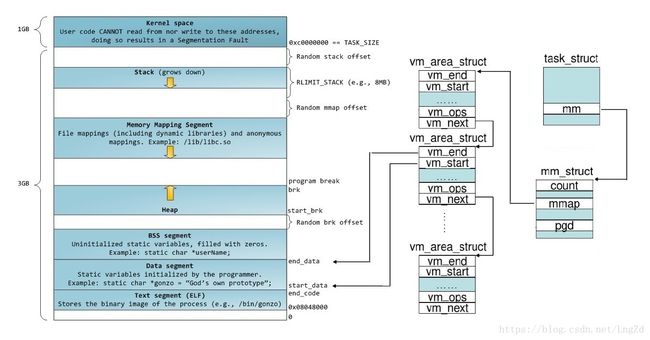
虚拟地址空间的划分
4G的虚拟地址空间被划分为用户空间和内核空间。0 ~ 3G为用户空间,3 ~ 4G为内核空间。内核地址空间由所有进程共享,只有运行在内核态的进程才能访问,用户进程可以通过系统调用切换到内核态。每个进程的用户空间是独立的,互不相干的。通常用户空间包含以下几个段。
- text段:存放程序执行代码,在内存中权限为只读。
- data段:存放已初始化的全局变量和静态变量。
- bss段:存放未初始化的全局变量和静态变量,特点是程序执行之前bss段会自动清零。
- 堆(heap): 用于存放进程运行中动态分配的内存。大小不固定,可动态扩张或缩小。
- 栈(stack): 存放函数参数和局部变量,栈的特点是先进先出(FIFO)。
linux内核中,虚拟内存的基本管理单元为struct vm_area_struct, 该虚拟地址空间范围可以用[vm_start, vm_end )表示。
低端内存(low memory)与高端内存(high memory)
Linux为了使内核访问内存简单化,把内核的线性地址空间直接一一映射到物理地址空间,即线性地址连续,被映射的物理地址也连续。
物理地址 = 线性地址 – 0xC0000000
内核的线性地址空间只有1G,如果内核的全部线性空间直接一一映射到物理地址,内核态的进程能使用到的物理内存最多只有1G。物理内存可能会大于1G,为了使内核态的进程访问到更多的物理内存,Linux将1G的内核线性地址空间分为两个部分,第一部分为1G的前896M,剩下的128M线性空间用来动态映射剩下的所有物理内存。高端内存的思想是,借用一段线性地址和物理内存进行映射,用完归还。因此高端内存和低端内存的概念主要用来区分内核线性空间是否可以被直接映射到内核的物理内存。
物理地址空间的划分
物理地址空间被划分为三个区域:
-
ZONE_DMA
ZONE_DMA的地址范围:0 ~ 16MB,和线性地址3G ~ 3G+16M一一映射。DMA用于内存与高速外设进行大量数据传输,DMA控制器取代CPU获得总线控制权。一些DMA控制器并不能访问到所有的内存,例如x86 ISA总线上的DMA控制器访问不了16M以上的内存。ZONE_DMA产生的本质原因是,不一定所有的DMA都能访问到所有内存,是硬件的设计限制。ZONE_DMA的内存不是专门用于DMA的,而是有缺陷的DMA要申请内存时,才从这个区域申请。 -
ZONE_NORMAL
地址范围:16MB ~ 896MB,和线性地址3G+16M ~ 3G+896M一一映射。该区域存放的是内核会频繁用到的数据,包含内核镜像文件。 -
ZONE_HIGH
地址范围: 896MB ~ 4G。高端内存和ZONE_HIGH是动态映射关系。
内存分配
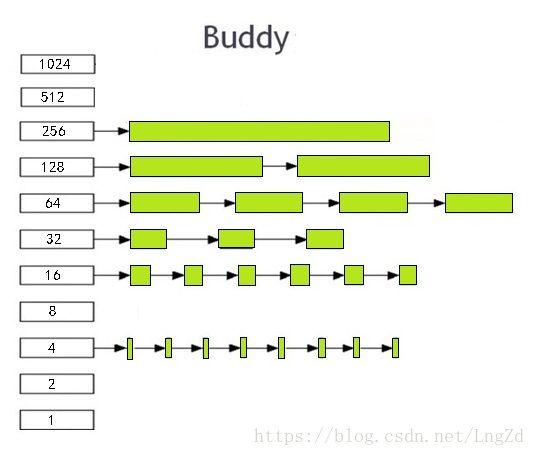
buddy算法
buddy系统以2的n次方为单位管理所有的空闲物理内存,相同大小的连续页框被放到同一个链表中。共有11个链表,每个链表的大小分别为1,2,4,8,16,32,64,128,256,512,1024。Linux底层的物理内存申请和释放以2n为单位。分配内存的时候,小块不够拆大块,释放的时候,伙伴小块合并大块。Buddy算法的精髓在于任何正整数都可以用2的n次方的和表示。
伙伴关系的两个块需要满足:
- 两个块大小一致
- 物理地址必须连续
- 两个块必须是从同一个大块分离出来的。
例如,假设ZONE_NORMAL中有16页内存(24),此时程序申请一页内存,buddy算法把剩下的页拆分为8+4+2+1,放到不同的链表中。如果再申请2页,则直接给2页,剩下的页面为8+4+1。程序释放1页,释放的1页和伙伴系统中的1页形成伙伴关系,合并这两页。于是剩下的块为8+4+2.
- 用buddyinfo查看物理理内存分配情况
root@localhost:~# cat /proc/buddyinfo
Node 0, zone DMA 0 0 0 1 2 1 1 0 1 1 3
Node 0, zone DMA32 3661 12630 3101 103 19 13 10 5 3 0 0
Node 0, zone Normal 7328 2802 12 10 7 7 2 1 1 0 0
内存碎片化
Buddy算法对内存的拆拆合合会导致内存的碎片化,空闲页面趋于散落在不连续的空间,很难有足够长的连续物理内存页面分配。一些DMA控制器没有MMMU,需要连续的物理内存。例如,Camera进程需要通过DMA将拍摄的图片从camera搬移到内存,DMA申请16M内存。但此时没有足够大的连续内存,即使物理内存总共有100M空闲,DMA也无法申请到内存。解决办法有:reserved内存,CMA(连续内存分配器)
-
reserved内存
如Linux可以在开机的时候将16M连续物理内存预留给Camera。 -
CMA(连续内存分配器)
CMA一般用在嵌入式设备中,原理是,预留一段内存给驱动使用,当驱动不适用的时候,CMA区域可以分配给用户进程使用,当驱动需要使用时,将进程占用的内存通过回收或迁移的方式将之前占用的预留内存腾出来。
页面的类型:
- 不可移动页面unmoveable:在内存中位置必须固定,无法移动到其他地方
- 可回收页面reclaimable:不能直接移动,但是可以回收
- 可移动页面movable:页面可以随意的移动
slab算法
Buddy系统分配物理内存最小单位是页,现实的需求却是更小粒度的分配,如分配几十或几百字节。slab分配系统是为了小内存分配而生,slab分配内存以byte为单位。slab对buddy系统分配的大内存进一步细分成小内存。slab基于对象进行管理,对象即内核的数据结构,如task_struct, file_struct。当要申请一个对象,slab分配从slab列表中分配一个对象,当要释放时,将其重新放回slab列表中,而不是返回给buddy系统。
查看slab缓存
- 用slabinfo查看slab分配器的情况
root@localhost:~# cat /proc/slabinfo | head
slabinfo - version: 2.1
# name : tunables : slabdata
btrfs_delayed_data_ref 0 0 112 36 1 : tunables 0 0 0 : slabdata 0 0 0
btrfs_delayed_ref_head 0 0 208 19 1 : tunables 0 0 0 : slabdata 0 0 0
btrfs_delayed_node 0 0 304 13 1 : tunables 0 0 0 : slabdata 0 0 0
btrfs_ordered_extent 0 0 416 19 2 : tunables 0 0 0 : slabdata 0 0 0
bio-1 12 12 320 12 1 : tunables 0 0 0 : slabdata 1 1 0
btrfs_extent_buffer 0 0 280 14 1 : tunables 0 0 0 : slabdata 0 0 0
btrfs_extent_state 0 0 80 51 1 : tunables 0 0 0 : slabdata 0 0 0
btrfs_transaction 0 0 432 18 2 : tunables 0 0 0 : slabdata 0 0 0
- slabtop
NAME
slabtop - display kernel slab cache information in real time
SYNOPSIS
slabtop [options]
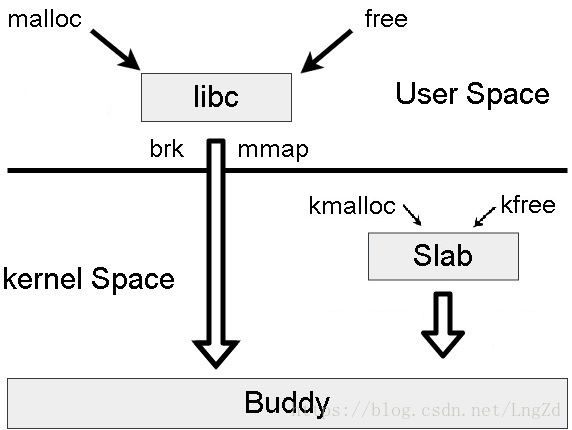
动态内存分配
-
brk
brk调整program break的位置, 通常将堆当前的内存边界称为program break,
program break最初在未初始化的数据段的后面。通过调整program break的位置,brk可以调整堆的大小。内核在进程首次访问新分配的虚拟地址时自动分配物理内存页。 -
mmap
mmap在堆和栈之间找出一块空闲的虚拟内存。从内存分配调度角度来看,mmap能够用于实现共享内存根本的原因是,不同进程的虚拟地址可以映射到同一个物理地址。 -
malloc/free
malloc是libc的库函数,malloc/free用于在堆上分配/释放内存。一般情况,free不会降低program break的位置,而是会将释放的内存添加到空闲内存列表中,供后续的malloc循环使用。这样做的原因在于:堆中间地址的内存需要等堆高地址的内存释放后才能释放,被释放的内存块可能会在堆的中间,因此不会降低program break。还有就是最大程度减少了brk系统调用的次数。默认情况下,小于128K的内存,malloc使用brk向内核申请。大于128K的内存,malloc用mmap向内核申请。 -
kmalloc
kmalloc保证分配的物理内存是连续的,从低端内存分配,一般用来分配小块内存。 -
vmalloc
vmalloc只保证分配的虚拟地址空间是连续的, vmalloc分配的一般是高端内存,只有当内存不够的时候才分配低端内存,不能直接用于DMA内存分配,分配的一般为大块内存。 -
ioremap
用于物理地址向虚拟地址的映射,适用于物理地址已经知道的情况,如设备驱动。寄存器通过ioremap向malloc映射区映射。ioremap从vmalloc映射区找一个空闲的虚拟地址空间,然后去修改页表,把这个虚拟地址往这个寄存器的物理地址映射。
用vmallocinfo查看寄存器映射情况
root@localhost:~# cat /proc/vmallocinfo | grep ioremap
0xffffc90000000000-0xffffc90000002000 8192 acpi_os_map_iomem+0x16d/0x1a0 phys=bffe0000 ioremap
0xffffc90000002000-0xffffc90000004000 8192 pci_enable_msix+0x2b0/0x3f0 phys=febd2000 ioremap
0xffffc90000004000-0xffffc90000007000 12288 acpi_os_map_iomem+0x16d/0x1a0 phys=bffe0000 ioremap
0xffffc9000063a000-0xffffc9000063c000 8192 acpi_os_map_iomem+0x16d/0x1a0 phys=fed00000 ioremap
0xffffc90000720000-0xffffc90000723000 12288 zs_cpu_notifier+0x4b/0x90 ioremap
内存的延迟分配
Linux内核定义了“零页面”,页面全为0的一个物理页,且物理地址固定。进程申请内存,获得线性地址,线性地址和零页面的物理地址在页表项中是临时映射关系,在页表中访问权限为只读。当进程往该地址写入数据,发生page fault,内核检查VMA的权限,发现进对该区域进行有写入权限,分配新的物理页面,重新和线性地址进行映射,并且发生写时拷贝,把零页内容拷贝到新分配的物理页面。
OOM机制
Linux会在运行的时候,对每一个进程做一个OOM(Out Of Memory)打分,当物理内存耗尽的时候,分数最高的进程被kill掉。
-
OOM打分取决于:
- 驻留内存、pagetable和swap的使用
- 是否为root用户进程,root用户减去30
- oom_score_adj的值,oom_score会加上oom_score_adj这个值
-
查看进程OOM分数
root@localhost:~# pgrep raven
14633
root@localhost:~# cat /proc/14633/oom_score
66
内存的消耗与泄漏
进程的VMA
VMA(Virtual Memory Area)虚拟地址空间, 内核中用vm_area_struct这个数据结构来描述虚拟地址空间。
查看VMA的分布情况
- pmap
NAME
pmap - report memory map of a process
SYNOPSIS
pmap [options] pid [...]
- maps
/proc/[pid]/maps
A file containing the currently mapped memory regions and their access permissions. See mmap(2) for some further
information about memory mappings.
- smaps
/proc/[pid]/smaps (since Linux 2.6.14)
This file shows memory consumption for each of the process's mappings. (The pmap(1) command displays similar
information, in a form that may be easier for parsing.) For each mapping there is a series of lines such as the
following:
page fault的几种可能性
-
访问非法的内存区
程序访问VMA以外的非法区域。 -
内存分配延迟
malloc新申请10M内存,但新申请到的10M内存全部映射到一个物理地址相同的零页。第一写的时候,发生page fault。 -
没有权限
如VMA的权限为R+X,但对次VMA进行了写操作。 -
执行代码段时发生缺页
从硬盘读取代码段,发生IO操作,为major主缺页。
| major主缺页 | minor次缺页 |
|---|---|
| 发生缺页必须读硬盘,有IO行为,处理时间长。 | 发生缺页直接申请内存,如malloc申请内存,第一次写发生page fault. |
VSS, RSS, PSS和USS
- VSS:使用的虚拟内存
- RSS:实际使用物理内存
- PSS:比例占用物理内存(有多个进程同时使用按照比例计算)
- USS:独占物理内存(本进程独有的不和其他进程共享的内存)
一般情况,VSS>=RSS>=PSS>=USS。进程申请到一块虚拟内存,物理内存会存在延迟分配的情况,即物理内存在首次写入的时候才会分配。所以VSS>=RSS。进程会之间会共享内存,如mmap。一个物理内存地址会被映射到多个进程的虚拟地址,PSS用于描述物理页面被共享的情况。USS是指进程独占的物理内存,可用于评估进程是否存在内存泄漏。
用smen评估内存使用情况
root@localhost:~# smem
PID User Command Swap USS PSS RSS
737 root /sbin/agetty --noclear tty1 0 148 157 396
740 root /sbin/agetty --keep-baud 11 0 152 161 396
638 daemon /usr/sbin/atd -f 0 216 226 484
673 root /usr/sbin/irqbalance --pid= 0 276 309 708
625 root /usr/sbin/cron -f 0 316 339 764
535 root /sbin/dhclient -1 -v -pf /r 0 852 859 1032
内存泄漏检测
内存泄漏:进程运行时间越久,占用的内存越高,申请和释放的内存不成对。内存泄漏的观测采用多点采样法,内存泄漏只看USS即可。
- 内存检测工具
| valgrind | addresssanitizer |
|---|---|
| 程序运行在虚拟机中,速度慢,不用重新编译 | 速度比valgrind块,但需要重新编译,编译的时候添加-fsanitize=address 参数 |
内存与IO的交换
page cache 与 buffer cache
buffer cache主要面向块设备,操作的基本单位为块。page cache是面向文件和内存的,操作的基本单位为页。早期的内核中buffer cache和page cache并存,表现为同一份文件数据既出现在buffer cache中,又出现在page cache中。Linux 2.6内核对这两个cache进行了合并,统一使用页缓存做缓存。
read, write, mmap
读取文件的时候,内核采取预读取的方式,在page cache缓存文件的部分内容。read拷贝内核空间的page cache到用户空间的buffer。write拷贝用户空间的buffer到内核空间的page cache。read和write相当于进行了两次拷贝,一次是从文件到page cache,另一次是从page cache到用户空间的buffer。而mmap直接将文件的page cache映射到进程用户空间的虚拟地址,所以mmap只需要一次拷贝,就是从文件拷贝到page cache。所以mmap的读写比read/write快。
内存交换
File-backed page和Anonymous page
- File-backed page
进程的虚拟地址空间映射到文件,如代码段,动态库。 - Anonymous page
进程的虚拟地址空间没有映射到任何的文件,如stack, heap。
file-backed page可以swap到磁盘。内存紧张情况下,代码段,mmap的字体文件等可以被替换出去而不驻留内存。anonymous page看可以交换到swapfile文件或swap文件。
回收的水位
Linux中有三个回收水位:min, low, high。每个zone单独设置水位。
- Background后台回收
由后台进程kswapd回收,由low水位触发,直到回到high水位。后台慢慢回收,进程在申请内存进行写操作时,仍然可以申请到内存。 - Direct reclaim
直接回收,由min水位触发,直到回到low水位。进程要申请内存进行写操作时,直接被堵住,直到回收到了足够的内存。
用zoneinfo查看内存的水位
root@localhost:~# cat /proc/zoneinfo
Node 0, zone DMA
pages free 3976
min 67
low 83
high 100
scanned 0
spanned 4095
present 3998
managed 3976
用min_free_kbytes设置水位
查看min_free_kbytes的值:
cat /proc/sys/vm/min_free_kbytes
- min水位计算: watermark[min]=min_free_kbytes * zone大小 /总内存大小
- low水位计算:watermark[low]=5/4 * watermark[min]
- high水位计算:watermark[high]=6/4 * watermark[min]
swappiness
swappiness反映是否积极地使用swap空间。查看swappiness大小:
cat /proc/sys/vm/swappiness
- swappiness值为0时,仅在内存不足(free and file-backed pages < high water mark in a zone)的时候使用swap。
- swappiness值较小时,倾向回收有文件背景的页面。
- swappiness值比较大时,倾向于回收匿名页。
参考
- Linux任督二脉之内存管理
- Linux操作系统原理与应用 陈莉君
- 奔跑吧Linux内核 张天飞
- 英特尔® 64 位和 IA-32 架构开发人员手册