【实验2】编译器级别的代码优化对比实验(C#)
目录
前言
关于实验对比方向
关于编译优化
1、实验目的
2、实验平台、工具
3、实验设计
4、实验步骤
5、实验结果讨论
前言
在折腾完win10下载Win-TC用不了、先痛苦后享受地做完C#版后,发现实验要求里是有Win-TC附件链接的。不过试了实验室win7系统虽然可以运行,但是生成的asm文件我怎么都没找到,就算了,尽管方向2还想用Win-TC做呢。
本实验实现了方向1、3。另外,由于整个篇幅太长,实验3只给出了设计,完整的可以查完文档。文末给出了C#反汇编的il文件的参考链接。
完整文档及源码可以点击下载:this。
关于实验对比方向
- 方向1-相同编译器下不同优化参数(相同源代码,采用不同的优化参数)的性能对比
- 方向2-不同编译器下相同源代码(例如采用C语言用WinTC和gcc对比;或者C#下采用不同的.NET Framework版本2.0和4.0(版本差最好拉大一点))的性能对比
- 方向3-相同编译器下相同编译参数,不同的源代码写法(源代码结果一样,但实现不同,例如递归和通常的实现等)的对比
关于编译优化
代码编译优化,文末有参考的博文链接,其实老师上课讲的ppt也很清晰。
Debug与Release二者的详细区分:
- Debug:Debug通常称为调试版本,通过一系列编译选项的配合,编译的结果通常包含调试信息,而且不做任何优化,以为开发人员提供强大的应用程序调试能力。
- Release:Release通常称为发布版本,是为用户使用的,一般客户不允许在发布版本上进行调试。所以不保存调试信息,同时,它往往进行了各种优化,以期达到代码最小和速度最优。为用户的使用提供便利。
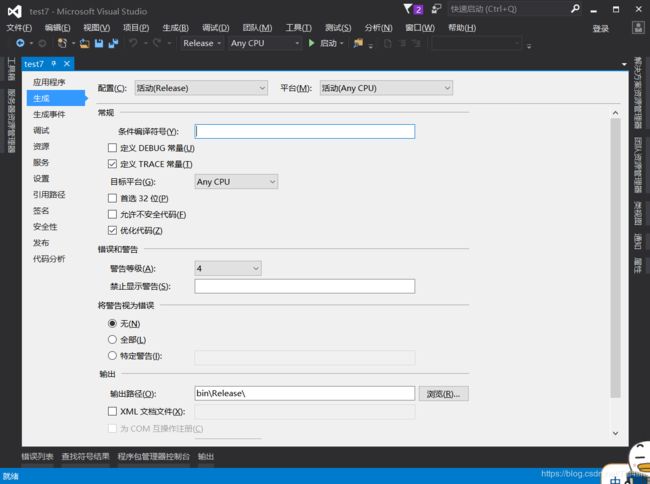
VS中可以选择优化参数,如下:
- 汇编原理:编译器对变量的存取速度,寄存器快于内存,最慢是硬盘。
相对复杂的工作流程产生了更多的时延,累计起来就比寄存器慢很多,为了提高执行效率,编译器会对有必要优化的变量做访问方式上的处理,这就是编译器对变量的优化。
多数情况下,变量是存放在内存而非寄存器中的,这样对变量的存取效率很低。对于频繁使用的变量,编译器自动地把变量mov到寄存器里,使用的时候直接访问寄存器里的值,以加快存取速度,这就是寄存器对变量的优化。
1、实验目的
在编程语言中,对比不同编程风格的代码写法,或者通过使用不同的编译器和编译优化参数,通过编译器生成汇编代码,静态分析所生成汇编代码的运行效率。
2、实验平台、工具
在Windows平台下,采用visual studio 2015开发工具编写C#程序,并通过VS中引入Microsoft自带的外部工具ildasm反汇编生成il文件。然后使用UltraCompare工具来比较汇编文件的异同(win-TC在win10 64位下无法正常运行)。
3、实验设计
方向1. 相同编译器下不同优化参数的性能对比(相同源代码,采用不同的优化参数)
在VS2015中,编写代码test1如下,使用Debug和Release编译并用ildasm生成对应的汇编代码,再对比分析。
///
/// 相同编译器下不同优化参数的性能对比
///
///
/// -> Debug和Release编译
/// -> 对比il文件
public static void test1()
{
/// 0.空指令删除--> 很明显,代码中没有了nop字段,程序更加紧凑了。
/// 1.冗余优化-->未使用的变量
Console.WriteLine("->exp1: not use x=27");
int x = 27;
const string strHello = "HELLOWORLD";
// Console.WriteLine(strHello);
Console.WriteLine("End->exp1");
/// .locals init (int32 x)优化后不见了(局部变量,类型为int32)
/// ldc.i4.3(将3推送到堆栈上)和stloc.0(将值从堆栈弹出到局部变量 0)也消失了。
/// 没有使用的变量,在设置为优化的时候,就直接消失了,就像从来没有写过一样
/// 2.优化-->try-catch空句
Console.WriteLine("->exp2: try-catch set null");
try
{
}
catch { }
try { } catch { }
finally {
Console.WriteLine("End->exp2");
}
/// 空的try catch直接消失了,但是空的try catch finally代码是不会消失的,但是也不会直接调用finally内的代码(即还是会生成try代码段)。
/// 3.优化-->跳转简化
goto LABEL1;
LABEL2: Console.WriteLine("->exp3: simplify goto");
Console.WriteLine("End->exp3");
goto LABELNext;
LABEL1: goto LABEL2;
/// 一些多层的标签跳转会得到简化
/// 4.临时变量消除:for中iexp4: for");
int n = 27;
int[] array = new int[n];
for (int k = 0; k < n; k++)
{ /// 数组初始化
array[k] = k;
}
/// 折半查找 元素Num
int Num = 4;
int low = 0;
int high = n - 1;
int mid = 0;
bool found = false;
while ((low <= high) && !found )
{
mid = (low + high) / 2;
if (Num > array[mid])
low = mid + 1;
else if (Num == array[mid])
found = true;
else high = mid - 1;
}
if (found)
Console.WriteLine("数组包含所找元素");
else
Console.WriteLine("not Found");
}
方向3. 相同编译器下相同编译参数,不同的源代码写法的对比
在VS2015中,编写代码test3 add和test3 sub,对循环条件中循环变量的自增和自减问题进行讨论,以下为两段代码:
static void Main(string[] args)
{
//test1();
///// test3 add
//int itotal = 1000;
//int a = 0;
//for (int i = 0; i < itotal; i++)
//{
// a++;
//}
//Console.WriteLine("a=" + a);
/// test3 sub
int itotal = 1000;
int a = 0;
for (int i = itotal; i >= 0; i--)
{
a++;
}
Console.WriteLine("a=" + a);
Console.Read();
}使用相同的优化参数Release编译并用ildasm生成对应的汇编代码,对比以上代码的运行效率,分析在完成相同的功能,for循环使用++和–哪个效率更高,应用到编程中,我们如何提高for循环效率。
4、实验步骤
方向1. 相同编译器下不同优化参数的性能对比
a) 在VS2015中,编写代码test1如下:

b) 设置调试配置为Debug,编译程序 ,打开ildasm工具将exe转储成test1Debug.il文件:


c) 设置调试配置为Release,编译程序 ,打开ildasm工具将exe转储成test1Release.il文件:

d) 对两个文件用UC对比,讨论结果:

5、实验结果讨论
方向1. 相同编译器下不同优化参数的性能对比(相同源代码,采用不同的优化参数):左边是无任何优化的Debug的汇编代码,右边是Release优化级别的代码及汇编,下面分析6点。
另外发现,有时候编译器优化后会导致一些本来运行正常的代码出问题,可参阅书本《CLR via C#》了解。
1.1 从Main中test1()函数的调用就可以看出很明显的优化——代码中没有了nop字段,程序更加紧凑了。
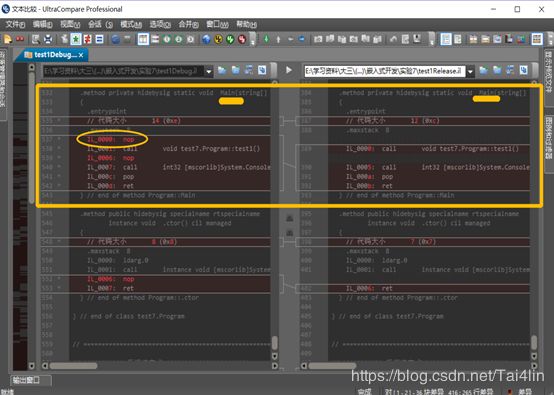
1.2 对未使用的变量的冗余优化。
如下图,右边优化后, .locals init (int32 x)优化后不见了(局部变量,类型为int32), 变量x在程序中是声明但未使用的。
对没有使用的变量,release优化的时候,就直接消失了,就像从来没有写过一样。

1.3 优化try-catch空句。如下图:
右边优化后,第一个空的try catch直接消失了;但是空的try catch finally代码是不会消失的,且不会直接调用finally内的代码(即还是会生成try代码段),故第二个空的try catch finally在右边保留了,同时优化了nop空操作。
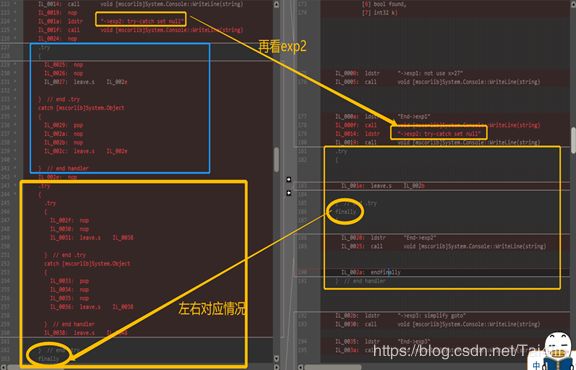

1.4 跳转简化:一些多层的标签跳转会得到简化
源代码:

比较如下图,右边直接简化成源程序最后的效果。

1.5 临时变量消除:优化后不会声明临时的bool变量(如for中i
源程序中有比较的变量如下图:
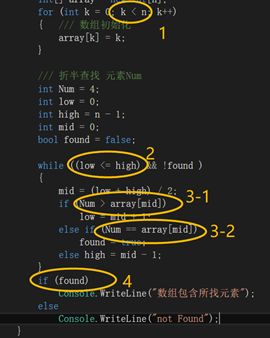
其中第3的两处均为对Num和array[mid]两个值的比较,故用同一个bool值即可,则总共4个bool值,编译优化后临时变量均消除了,如下图声明时优化后无需bool值:

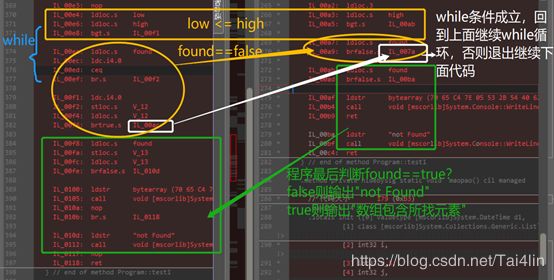
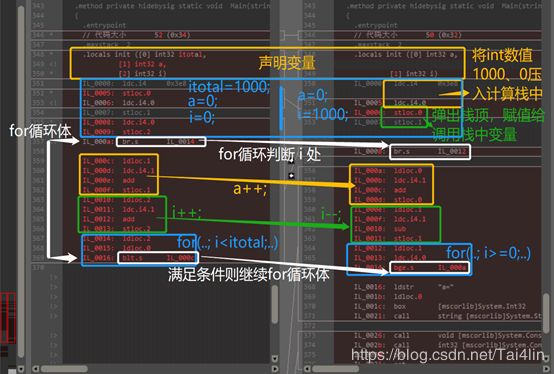
例如数组初始化的for循环中,右边release优化后,在比较k 折半查找 元素Num对应的初始化说明如下: 1.6 计算堆栈优化,请看下图第一个方框(low <= high)的对比: 左边对low变量的调用为:Ldloc.S 将特定索引处的局部变量加载到计算堆栈上 右边对low变量的调用(方框中high的上一句)为:Ldloc.3 将索引 3 处的局部变量加载到计算堆栈上 (回去1.5中的图可知,调用栈中第3个变量为low)则优化后直接加载了调用栈中第3个变量即low,而左边未优化时,需获取变量low的特定索引,再回去调用栈中加载该变量 While循环体内容如下: 方向3. 相同编译器下相同编译参数,不同的源代码写法的对比 3.1 for循环使用++和––哪个效率更高 分析发现,在完成相同的功能,for循环使用第2种––的方法效率更高。原因如下: 参考: i - -操作本身会影响CPSR(当前程序状态寄存器),CPSR常见的标志有N(结果为负), Z(结果为0),C(有进位),O(有溢出)。i > 0,可以直接通过Z标志判断出来。 i++操作也会影响CPSR(当前程序状态寄存器),但只影响O(有溢出)标志,这对于i < n的判断没有任何帮助。所以还需要一条额外的比较指令,也就是说每个循环要多执行一条指令。 如下图中第2个蓝色方框中,左边指令 ldloc.2 调用itotal与i作比较,而右边直接将int32数值0加载进计算堆栈中与i做比较。 参考博客: 方向1: 《C#编译器优化那点事》——被推荐好书:《C# via CLR》——《CLR via C# 读书笔记 2-1 编译器优化导致的问题》 《C#程序性能优化》 《C#的性能优化》 《C#中那些[举手之劳]的性能优化》 《VS中Dubug和Release的详细区别》 方向2: 方向3: 《for循环用效率分析(++和--时效率的差异分析)》 《编译器在代码优化方面的局限性》 《VS反编译C++代码》 《.NET IL .maxstack指令如何工作》