支持向量机SVM(附Python实现代码)
1 前备知识
在这里简略讲一下使用方法,具体原理和推导公式不展开讲了。
1.1 拉格朗日乘子法
拉格朗日乘子法就是求函数 f ( x 1 , x 2 , . . . ) f(x1,x2,...) f(x1,x2,...)在约束条件 g ( x 1 , x 2 , . . . ) = 0 g(x1,x2,...)=0 g(x1,x2,...)=0下的极值的方法。其主要思想是将约束条件函数与原函数联立,从而求出使原函数取得极值的各个变量的解。
首先看下面的例题:
m i n f = 2 x 1 2 + 3 x 2 2 + x 3 2 s . t . 2 x 1 + x 2 − 1 = 0 2 x 2 + x 3 − 2 = 0 min ~f=2x_{1}^{2}+3x_{2}^{2}+x_{3}^{2} \\ s.t. ~~2x_{1}+x_{2}-1=0 \\ ~~~ ~~~ ~2x_{2}+x_{3}-2=0 min f=2x12+3x22+x32s.t. 2x1+x2−1=0 2x2+x3−2=0
第一步将每个约束条件都分配一个乘子 α i \alpha_{i} αi,在将目标函数和所有的约束函数相加,得到函数:
L = f + ∑ i = 1 m g i α i L=f+\sum_{i=1}^{m}g_{i} \alpha_{i} L=f+i=1∑mgiαi
其中每个约束条件 g i g_{i} gi的右边都是0,所以 ∑ i = 1 m g i = 0 \sum_{i=1}^{m}g_{i}=0 ∑i=1mgi=0.
L = ( 2 x 1 2 + 3 x 2 2 + x 3 2 ) + α 1 ( 2 x 1 + x 2 − 1 ) + α 2 ( 2 x 2 + x 3 − 2 ) L=(2x_{1}^{2}+3x_{2}^{2}+x_{3}^{2})+\alpha_{1}(2x_{1}+x_{2}-1)+\alpha_{2}(2x_{2}+x_{3}-2) L=(2x12+3x22+x32)+α1(2x1+x2−1)+α2(2x2+x3−2)
第二步对 x i x_{i} xi求偏导:
{ ∂ L ∂ x 1 = 4 x 1 + 2 α 1 ∂ L ∂ x 2 = 6 x 2 + α 1 + 2 α 2 ∂ L ∂ x 3 = 2 x 3 + α 2 \left\{\begin{matrix}\frac{\partial L}{\partial x_{1}}=4x_{1}+2\alpha_{1} \\\frac{\partial L}{\partial x_{2}}=6x_{2}+\alpha_{1}+2\alpha_{2}\\ \frac{\partial L}{\partial x_{3}}=2x_{3}+\alpha_{2}\end{matrix}\right. ⎩⎨⎧∂x1∂L=4x1+2α1∂x2∂L=6x2+α1+2α2∂x3∂L=2x3+α2
令偏导数等于0,用 α i \alpha_{i} αi表示 x x x:
{ x 1 = − α 1 2 x 2 = − α 1 + 2 α 2 6 x 3 = − α 2 2 \left\{\begin{matrix}x_{1}=-\frac{\alpha_{1}}{2} \\ x_{2}=-\frac{\alpha_{1}+2\alpha_{2}}{6} \\ x_{3}=-\frac{\alpha_{2}}{2}\end{matrix}\right. ⎩⎨⎧x1=−2α1x2=−6α1+2α2x3=−2α2
将所得 x x x代入约束条件 g g g中,求得 α \alpha α:
{ α 1 = − 2 / 5 α 2 = − 72 / 45 \left\{\begin{matrix}\alpha_{1}=-2/5 \\ \alpha_{2}=-72/45 \end{matrix}\right. {α1=−2/5α2=−72/45
得到 α \alpha α的值,代入上式得到 x x x的最优解。
1.2 KKT条件
我们可以发现,1.1讲的拉格朗日乘子法中,它的约束条件都是等式,那么对于约束条件是不等式的应该怎么办呢?
对于一个新的极值问题:
m i n f = x 1 2 − 2 x 1 + x 2 2 + 5 s . t . x 1 + 10 x 2 > 10 10 x 1 − x 2 < 10 min ~f=x_{1}^{2}-2x_{1}+x_{2}^{2}+5 \\ s.t. ~~x_{1}+10x_{2}>10 \\ ~~~ ~~~ ~10x_{1}-x_{2}<10 min f=x12−2x1+x22+5s.t. x1+10x2>10 10x1−x2<10
为了统一,首先将约束条件都转化为小于号:
m i n f = x 1 2 − 2 x 1 + x 2 2 + 5 s . t . 10 − x 1 − 10 x 2 < 0 10 x 1 − x 2 − 10 < 0 min ~f=x_{1}^{2}-2x_{1}+x_{2}^{2}+5 \\ s.t. ~~10-x_{1}-10x_{2}<0 \\ ~~~ ~~~ ~~10x_{1}-x_{2}-10<0 min f=x12−2x1+x22+5s.t. 10−x1−10x2<0 10x1−x2−10<0
依旧是分配乘子并求和:
L = f + ∑ i = 1 m g i α i + ∑ i = 1 m h i β i L=f+\sum_{i=1}^{m}g_{i} \alpha_{i}+\sum_{i=1}^{m}h_{i} \beta_{i} L=f+i=1∑mgiαi+i=1∑mhiβi
其中 g i g_{i} gi是不等式约束条件, h i h_{i} hi是等式约束条件。(此例中没有等式)
L = ( x 1 2 − 2 x 1 + x 2 2 + 5 ) + α 1 ( 10 − x 1 − 10 x 2 ) + α 2 ( 10 x 1 − x 2 − 10 ) L=(x_{1}^{2}-2x_{1}+x_{2}^{2}+5)+\alpha_{1}(10-x_{1}-10x_{2})+\alpha_{2}(10x_{1}-x_{2}-10) L=(x12−2x1+x22+5)+α1(10−x1−10x2)+α2(10x1−x2−10)
KKT条件就是最优值,KKT条件为:
- L L L对每个 x x x求偏导等于 0 0 0;
- h ( x ) = 0 h(x)=0 h(x)=0;
- g i ( x ) < = 0 g_{i}(x)<=0 gi(x)<=0
- α i > = 0 \alpha_{i}>=0 αi>=0
- ∑ α i g i ( x ) = 0 \sum\alpha_{i}g_{i}(x)=0 ∑αigi(x)=0
可以发现,将3、4、5合并就是:
α i g i ( x ) = 0 \alpha_{i}g_{i}(x)=0 αigi(x)=0
对于上例题,接下来的操作就是:
一、 L L L对每个 x x x求偏导等于 0 0 0求出 x x x的表达式。
二、将 x x x的表达式代入 α i g i ( x ) = 0 \alpha_{i}g_{i}(x)=0 αigi(x)=0,求出 α \alpha α。
三、将 α \alpha α代回,求出 x x x。
2 SVM
2.1 简介
支持向量机(support vector machines, SVM)是一种二分类问题模型。
它的目标是找到一个尽可能正确分类,且“确信度”尽可能高的超平面。
其中“确信度”指的是:正确分类的样本点,距离超平面越远,该样本点的确信度就越高。(我对这个样本点分类正确的信任程度)
换而言之,就是该超平面的鲁棒性要好,泛化能力要强。
对于线性可分支持向量机,分类超平面为:
w ∗ ⋅ x + b ∗ = 0 w^{*}·x+b^{*}=0 w∗⋅x+b∗=0
相应的分类决策函数
f ( x ) = s i g n ( w ∗ ⋅ x + b ∗ ) f(x)=sign(w^{*}·x+b^{*}) f(x)=sign(w∗⋅x+b∗)
称为线性可分支持向量机。
2.2 函数间隔与几何间隔
函数间隔和几何间隔是用来描述计算“确信度”的。
2.1.1 函数间隔
在超平面 w ⋅ x + b = 0 w·x+b=0 w⋅x+b=0确定的情况下, ∣ w ⋅ x i + b ∣ |w·x_{i}+b| ∣w⋅xi+b∣的值可以作为衡量样本点 x i x_{i} xi确信度的一个指标, ∣ w ⋅ x i + b ∣ |w·x_{i}+b| ∣w⋅xi+b∣就是该样本点的函数间隔。
定义(函数间隔):对于给定的训练数据集 T T T和超平面 ( w , b ) (w,b) (w,b),定义超平面 ( w , b ) (w,b) (w,b)关于样本点 ( x i , y i ) (x_{i}, y_{i}) (xi,yi)的函数间隔为:
γ i ^ = ∣ w ⋅ x i + b ∣ \hat{\gamma _{i}}=|w·x_{i}+b| γi^=∣w⋅xi+b∣
超平面 ( w , b ) (w,b) (w,b)关于样本点 ( x i , y i ) (x_{i}, y_{i}) (xi,yi)的函数间隔为所有样本点函数间隔的最小值:
γ ^ = m i n γ i ^ , i = 1 , 2 , . . . , N \hat{\gamma }=min~\hat{\gamma _{i}},~~i=1,2,...,N γ^=min γi^, i=1,2,...,N
函数间隔虽然可以表示预测的确信度,但是当 w w w和 b b b成比例增加时,超平面没有改变,但函数间隔却成倍增加。
例如超平面 λ w ∗ ⋅ x + λ b ∗ = 0 \lambda w^{*}·x+\lambda b^{*}=0 λw∗⋅x+λb∗=0与 w ∗ ⋅ x + b ∗ = 0 w^{*}·x+b^{*}=0 w∗⋅x+b∗=0等价,但是 γ i ^ = λ ∣ w ⋅ x i + b ∣ \hat{\gamma _{i}}=\lambda|w·x_{i}+b| γi^=λ∣w⋅xi+b∣。
为了解决这个问题,引入了几何间隔。
2.2.2 几何间隔
在二维坐标系中,点是样本,线是分离超平面,那么点到线的距离就是几何间隔。
点到线的距离公式:
d = ∣ A x 0 + B y 0 + C ∣ A 2 + B 2 d=\frac{|Ax_{0}+By_{0}+C|}{\sqrt{A_{2}+B_{2}}} d=A2+B2∣Ax0+By0+C∣
扩展到多维坐标系:
d = ∣ w ⋅ x + b ∣ ∣ ∣ w ∣ ∣ 2 d=\frac{|w·x+b|}{||w||_{2}} d=∣∣w∣∣2∣w⋅x+b∣
其中 ∣ ∣ w ∣ ∣ 2 = ∑ i = 1 m w ||w||_{2}=\sqrt{\sum_{i=1}^{m}w} ∣∣w∣∣2=∑i=1mw为L2范数。
我们记 γ i = ∣ w ⋅ x i + b ∣ ∣ ∣ w ∣ ∣ 2 \gamma _{i}=\frac{|w·x_{i}+b|}{||w||_{2}} γi=∣∣w∣∣2∣w⋅xi+b∣
同样:
γ = m i n γ i , i = 1 , 2 , . . . , N \gamma=min~\gamma _{i},~~i=1,2,...,N γ=min γi, i=1,2,...,N
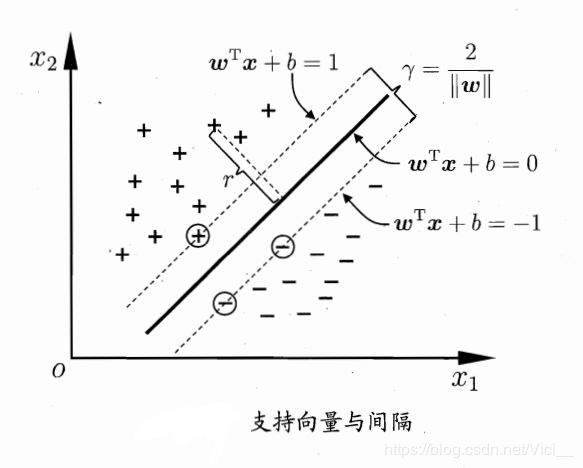
2.2.3 间隔最大化
回想一下,我们SVM的目标是什么来着?
是寻找一个“确信度”尽可能高的超平面,也就是一个几何间隔尽可能大的超平面。
那么我们可以得到一个约束最优化问题:
使几何间隔最大化的 w w w和 b b b,并且满足约束条件所有样本的几何间隔大于 γ \gamma γ.
max w , b γ s . t . y i ( w ⋅ x i + b ) ∣ ∣ w ∣ ∣ 2 ≥ γ , i = 1 , . . , N \max_{w,b}~~~~~~~~~~~~~\gamma~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ \\ ~\\ s.t.~~~~~~~~\frac{y_{i}(w·x_{i}+b)}{||w||_{2}}\geq \gamma, ~~~i=1,..,N w,bmax γ s.t. ∣∣w∣∣2yi(w⋅xi+b)≥γ, i=1,..,N
又因为函数间隔和几何间隔的关系:
γ = γ ^ ∣ ∣ w ∣ ∣ 2 \gamma = \frac{\hat{\gamma }}{||w||_{2}} γ=∣∣w∣∣2γ^
上述问题可以化为:
max w , b γ ^ ∣ ∣ w ∣ ∣ 2 s . t . y i ( w ⋅ x i + b ) ≥ γ ^ , i = 1 , . . , N \max_{w,b}~~~~~~~~~~~~~\frac{\hat{\gamma }}{||w||_{2}}~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ \\ ~\\ s.t.~~~~~~~~y_{i}(w·x_{i}+b)\geq \hat{\gamma}, ~~~i=1,..,N w,bmax ∣∣w∣∣2γ^ s.t. yi(w⋅xi+b)≥γ^, i=1,..,N
函数间隔 γ ^ \hat{\gamma} γ^的取值并不影响最优化问题的解,则可以令 γ ^ = 1 \hat{\gamma}=1 γ^=1。
这个其实也好理解,我们看上式, w w w和 b b b就是两个参数,令 γ ^ = 1 \hat{\gamma}=1 γ^=1,就相当于将 w ′ = w γ ^ w^{'}=\frac{w}{\hat{\gamma}} w′=γ^w和 b ′ = b γ ^ b^{'}=\frac{b}{\hat{\gamma}} b′=γ^b,对于该约束最优化问题的解没有任何影响。就好比解方程时等式两边同时除以一个数。
另外,最大化 1 ∣ ∣ w ∣ ∣ 2 \frac{1}{||w||_{2}} ∣∣w∣∣21和最小化 1 2 ∣ ∣ w ∣ ∣ 2 \frac{1}{2}{||w||^{2}} 21∣∣w∣∣2是等价的。
所以上面的问题就变成了:
min w , b 1 2 ∣ ∣ w ∣ ∣ 2 s . t . y i ( w ⋅ x i + b ) − 1 ≥ 0 , i = 1 , . . , N \min_{w,b}~~~~~~~~~~~~~~\frac{1}{2}{||w||^{2}}~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ \\ ~\\ s.t.~~~~~~~~y_{i}(w·x_{i}+b)-1\geq 0, ~~~i=1,..,N w,bmin 21∣∣w∣∣2 s.t. yi(w⋅xi+b)−1≥0, i=1,..,N
这就是SVM的基本型(对于线性可分问题),后面主要就是这个约束问题的求解。
2.3 对偶问题
我们可以发现上面的约束最优化问题本身就是一个凸二次规划问题,所以我们可以使用更高效的方法去求解,也就是使用拉格朗日乘子法得到其“对偶问题”。
首先稍微做一下调整:
min w , b 1 2 ∣ ∣ w ∣ ∣ 2 s . t . 1 − y i ( w ⋅ x i + b ) ≤ 0 , i = 1 , . . , N \min_{w,b}~~~~~~~~~~~~~~\frac{1}{2}{||w||^{2}}~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ \\ ~\\ s.t.~~~~~~~~1-y_{i}(w·x_{i}+b)\leq 0, ~~~i=1,..,N w,bmin 21∣∣w∣∣2 s.t. 1−yi(w⋅xi+b)≤0, i=1,..,N
定义拉格朗日乘子 α i \alpha_{i} αi,根据
L = f + ∑ i = 1 m g i α i + ∑ i = 1 m h i β i L=f+\sum_{i=1}^{m}g_{i} \alpha_{i}+\sum_{i=1}^{m}h_{i} \beta_{i} L=f+i=1∑mgiαi+i=1∑mhiβi
得到:
L = 1 2 ∣ ∣ w ∣ ∣ 2 + ∑ i = 1 m α i [ 1 − y i ( w ⋅ x i + b ) ] L=\frac{1}{2}{||w||^{2}}+\sum_{i=1}^{m}\alpha_{i}[1-y_{i}(w·x_{i}+b)] L=21∣∣w∣∣2+i=1∑mαi[1−yi(w⋅xi+b)]
令 L L L对 w w w和 b b b求偏导等于零,得:
{ w = ∑ i = 1 m α i y i x i 0 = ∑ i = 1 m α i y i \left\{\begin{matrix}w=\sum_{i=1}^{m}\alpha_{i}y_{i}x_{i} \\ \\ 0=\sum_{i=1}^{m}\alpha_{i}y_{i}~~~~ \end{matrix}\right. ⎩⎨⎧w=∑i=1mαiyixi0=∑i=1mαiyi
虽然把 b b b给消去了,但是并没有影响,后续过程中原式的 b b b也会消去。
将 w = ∑ i = 1 m α i y i x i w=\sum_{i=1}^{m}\alpha_{i}y_{i}x_{i} w=∑i=1mαiyixi代入 L L L中,即可用 α i \alpha_{i} αi将 w w w和 b b b替换掉,得到对偶问题:
max α ∑ i = 1 m α i − 1 2 ∑ i = 1 m ∑ j = 1 m α i α j y i y j x i T x j s . t . ∑ i = 1 m α i y i = 0 , α i ≥ 0 , i = 1 , . . . , m \max_{\alpha}~\sum_{i=1}^{m}\alpha_{i}-\frac{1}{2}\sum_{i=1}^{m}\sum_{j=1}^{m}\alpha_{i}\alpha_{j}y_{i}y_{j}\boldsymbol{x}_{i}^T\boldsymbol{x}_{j} \\ s.t.~~~\sum_{i=1}^{m}\alpha_{i}y_{i}=0~,~~~~~~~~~~~~~~~~~~~~~~~\\ \alpha_{i} \geq 0,~~~~~~i=1,...,m αmax i=1∑mαi−21i=1∑mj=1∑mαiαjyiyjxiTxjs.t. i=1∑mαiyi=0 , αi≥0, i=1,...,m
另外,需要注意,这里的约束问题需要用到KKT条件:
- L L L对 w w w和 b b b求偏导等于 0 0 0;
- y i ( w ⋅ x i + b ) − 1 ≥ 0 y_{i}(w·x_{i}+b)-1\geq0 yi(w⋅xi+b)−1≥0
- α i > = 0 \alpha_{i}>=0 αi>=0
- α i [ y i ( w ⋅ x i + b ) − 1 ] = 0 \alpha_{i}[y_{i}(w·x_{i}+b)-1]=0 αi[yi(w⋅xi+b)−1]=0
- h ( x ) = 0 h(x)=0 h(x)=0; (这里没有等式约束,可以忽略)
整理一下,可简化为两种情况:
- 当 α i = 0 \alpha_{i}=0 αi=0时, y i ( w ⋅ x i + b ) − 1 ≥ 0 y_{i}(w·x_{i}+b)-1\geq0 yi(w⋅xi+b)−1≥0
- 当 0 < α i < ξ i 0<\alpha_{i}<\xi_{i} 0<αi<ξi时, y i ( w ⋅ x i + b ) − 1 = 0 y_{i}(w·x_{i}+b)-1=0 yi(w⋅xi+b)−1=0
( ξ i \xi_{i} ξi为松弛变量,下面会讲。)
到这里,只要解出 α i \alpha_{i} αi,就可以得到 w w w和 b b b,从而得到分离超平面。
那么如何去求解 α i \alpha_{i} αi呢?一种比较高效的方法就是SMO算法。
在此之前需要先讲一下松弛变量和核函数。
2.4 松弛变量和核函数
2.4.1 线性SVM与松弛变量
在此之前所讲的都是数据集时线性可分的,但是还有的数据集是线性不可分的,这两种情况合起来就是线性SVM。
如下图,线性不可分的数据集:
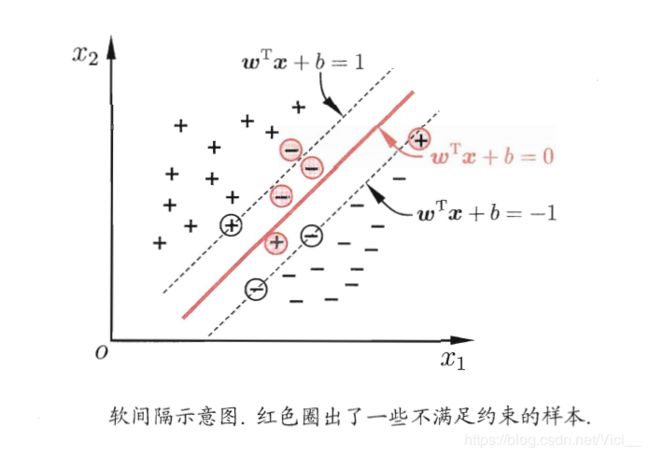
线性不可分意味着某些样本点 ( x i , y i ) (x_{i}, y_{i}) (xi,yi)不能满足函数间隔大于等于1的约束条件。为了解决这个问题,给每一个样本点 ( x i , y i ) (x_{i}, y_{i}) (xi,yi)引进一个松弛变量 ξ i ≥ 0 \xi_{i} \geq 0 ξi≥0,使函数间隔加上松弛变量大于等于1。这样,约束条件变为:
y i ( w ⋅ x i + b ) − 1 + ξ i ≥ 0 y_{i}(w·x_{i}+b)-1+\xi_{i} \geq 0 yi(w⋅xi+b)−1+ξi≥0
同时,对每个松弛变量 ξ i \xi_{i} ξi,需要支付一个代价 ξ i \xi_{i} ξi,则目标函数就由原来的 1 2 ∣ ∣ w ∣ ∣ 2 \frac{1}{2}||w||_{2} 21∣∣w∣∣2变为:
1 2 ∣ ∣ w ∣ ∣ 2 + C ∑ i = 1 N ξ i \frac{1}{2}||w||_{2}+C\sum_{i=1}^{N}\xi_{i} 21∣∣w∣∣2+Ci=1∑Nξi
其中 C > 0 C>0 C>0称为惩罚参数,用来控制松弛变量的代价高低。
所以对于线性不可分的SVM的基本模型就是:
min w , b , ξ 1 2 ∣ ∣ w ∣ ∣ 2 + C ∑ i = 1 N ξ i s . t . y i ( w ⋅ x i + b ) ξ i ≥ 1 , ξ i ≥ 0 , i = 1 , . . , N \min_{w,b,\xi}~~~~~~~~~~~~~~\frac{1}{2}{||w||^{2}}+C\sum_{i=1}^{N}\xi_{i}~~~~~~~~~~~~~~~~~ \\ ~\\ s.t.~~~~~~~~y_{i}(w·x_{i}+b)\xi_{i} \geq 1, \\ ~~~~~~~~~~~~\xi_{i}\geq 0,~~i=1,..,N w,b,ξmin 21∣∣w∣∣2+Ci=1∑Nξi s.t. yi(w⋅xi+b)ξi≥1, ξi≥0, i=1,..,N
2.4.2 非线性SVM与核函数
2.4.2.1 核技巧和核函数
简单说就是,对于非线性问题,可以将样本通过一个 φ ( x ) \varphi(x) φ(x)从原始空间映射到一个更高维的特征空间,使得样本在这个特征空间内线性可分。
如下图,对于异或问题,就是一个非线性问题,原始问题是在一个二维空间中,当我们将样本特征空间做一个映射,提升到三维空间中,就能容易找到一个分离超平面。
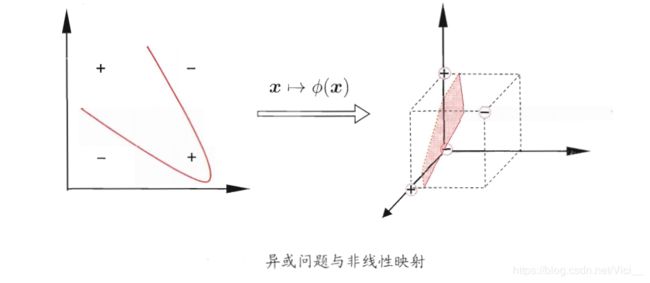
非线性SVM的基本模型为:
min w , b , ξ 1 2 ∣ ∣ w ∣ ∣ 2 s . t . y i ( w ⋅ φ ( x i ) + b ) ≥ 1 , i = 1 , . . , N \min_{w,b,\xi}~~~~~~~~~~~~~~\frac{1}{2}{||w||^{2}}~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ \\ ~\\ s.t.~~~~~~~~y_{i}(w· \varphi (x_{i})+b)\geq 1,~~i=1,..,N w,b,ξmin 21∣∣w∣∣2 s.t. yi(w⋅φ(xi)+b)≥1, i=1,..,N
其对偶问题为:
max α ∑ i = 1 m α i − 1 2 ∑ i = 1 m ∑ j = 1 m α i α j y i y j φ ( x i ) T φ ( x j ) s . t . ∑ i = 1 m α i y i = 0 , α i ≥ 0 , i = 1 , . . . , m \max_{\alpha}~\sum_{i=1}^{m}\alpha_{i}-\frac{1}{2}\sum_{i=1}^{m}\sum_{j=1}^{m}\alpha_{i}\alpha_{j}y_{i}y_{j}\varphi (\boldsymbol{x}_{i})^T \varphi (\boldsymbol{x}_{j}) \\ s.t.~~~\sum_{i=1}^{m}\alpha_{i}y_{i}=0~,~~~~~~~~~~~~~~~~~~~~~~~\\ \alpha_{i} \geq 0,~~~~~~i=1,...,m αmax i=1∑mαi−21i=1∑mj=1∑mαiαjyiyjφ(xi)Tφ(xj)s.t. i=1∑mαiyi=0 , αi≥0, i=1,...,m
特征空间的维数可能非常高。如果支持向量机的求解只用到内积运算,而在低维输入空间又存在某个函数 K ( x i , x j ) K(x_{i}, x_{j}) K(xi,xj) ,它恰好等于在高维空间中这个内积,即 K ( x i , x j ) = < φ ( x i ) ⋅ φ ( x j ) > = φ ( x i ) T φ ( x j ) K( x_{i}, x_{j}) =<φ( x_{i}) ⋅φ( x_{j}) > =\varphi (\boldsymbol{x}_{i})^T \varphi (\boldsymbol{x}_{j}) K(xi,xj)=<φ(xi)⋅φ(xj)>=φ(xi)Tφ(xj)那么支持向量机就不用计算复杂的非线性变换,而由这个函数 K ( x i , x j ) K(x_{i}, x_{j}) K(xi,xj) 直接得到非线性变换的内积,使大大简化了计算。这样的函数 K ( x i , x j ) K(x_{i}, x_{j}) K(xi,xj) 称为核函数。
则该对偶问题可以改写为:
max α ∑ i = 1 m α i − 1 2 ∑ i = 1 m ∑ j = 1 m α i α j y i y j K ( x i , x j ) s . t . ∑ i = 1 m α i y i = 0 , α i ≥ 0 , i = 1 , . . . , m \max_{\alpha}~\sum_{i=1}^{m}\alpha_{i}-\frac{1}{2}\sum_{i=1}^{m}\sum_{j=1}^{m}\alpha_{i}\alpha_{j}y_{i}y_{j}K( x_{i}, x_{j}) \\ s.t.~~~\sum_{i=1}^{m}\alpha_{i}y_{i}=0~,~~~~~~~~~~~~~~~~~~~~~~~\\ \alpha_{i} \geq 0,~~~~~~i=1,...,m αmax i=1∑mαi−21i=1∑mj=1∑mαiαjyiyjK(xi,xj)s.t. i=1∑mαiyi=0 , αi≥0, i=1,...,m
2.4.2.2 常用的核函数

3 SMO算法
序列最小最优化(sequential minimal optimization,SMO)算法,可以高效地实现支持向量机问题。SMO算法在这里用来更新优化 α i \alpha_{i} αi的值。
算法的基本思想就是,每次挑选出两个变量(假设为 α 1 \alpha_{1} α1和 α 2 \alpha_{2} α2),固定其它的变量( α i \alpha_{i} αi),每次只更新 α 1 \alpha_{1} α1和 α 2 \alpha_{2} α2,循环迭代多次,尽可能接近最优解。
SMO算法其实就做了两件事:
- 变量的挑选方法:挑选出 α 1 \alpha_{1} α1和 α 2 \alpha_{2} α2。
- 两个变量二次规划的求解方法:更新 α 1 \alpha_{1} α1和 α 2 \alpha_{2} α2。
3.1 两个变量二次规划的求解方法
假设选择的两个变量为 α 1 \alpha_{1} α1和 α 2 \alpha_{2} α2,其它变量 α i , ( i = 3 , . . . , N ) \alpha_{i},(i=3,...,N) αi,(i=3,...,N)是固定的,则SMO的最优化问题的子问题可以写成:
min α 1 , α 2 W ( α 1 , α 2 ) = 1 2 K 11 α 1 2 + 1 2 K 22 α 2 2 + y 1 y 2 K 12 α 1 α 2 − ( α 1 + α 2 ) + y 1 α 1 ∑ i = 3 N y i α i K i 1 + y 2 α 2 ∑ i = 3 N y i α i K i 2 s . t . α 1 y 1 + α 2 y 2 = − ∑ i = 3 N y i α i = δ 0 ≤ α i ≤ C , i = 1 , 2 \min_{\alpha_{1},\alpha_{2}}~~~~W(\alpha_{1},\alpha_{2})=\frac{1}{2}K_{11}\alpha_{1}^{2}+\frac{1}{2}K_{22}\alpha_{2}^{2}+y_{1}y_{2}K_{12}\alpha_{1}\alpha_{2}\\-(\alpha_{1}+\alpha_{2})+y_{1}\alpha_{1}\sum_{i=3}^{N}y_{i}\alpha_{i}K_{i1}+y_{2}\alpha_{2}\sum_{i=3}^{N}y_{i}\alpha_{i}K_{i2} \\s.t. ~~~~~\alpha_{1}y_{1}+\alpha_{2}y_{2}=-\sum_{i=3}^{N}y_{i}\alpha_{i}=\delta \\ 0 \leq \alpha_{i} \leq C,~i=1,2 α1,α2min W(α1,α2)=21K11α12+21K22α22+y1y2K12α1α2−(α1+α2)+y1α1i=3∑NyiαiKi1+y2α2i=3∑NyiαiKi2s.t. α1y1+α2y2=−i=3∑Nyiαi=δ0≤αi≤C, i=1,2
其中 δ \delta δ是常数,目标函数中省略了不含 α 1 , α 2 \alpha_{1},\alpha_{2} α1,α2的常数项。
接下来,我们从约束条件入手:
α 1 y 1 + α 2 y 2 = δ 0 ≤ α i ≤ C , i = 1 , 2 \alpha_{1}y_{1}+\alpha_{2}y_{2}=\delta \\0 \leq \alpha_{i} \leq C,~i=1,2 α1y1+α2y2=δ0≤αi≤C, i=1,2
我们假设考虑为变量 α 2 \alpha_{2} α2的最优化问题。
假设问题的初始可行解为 α 1 o l d \alpha_{1}^{old} α1old和 α 2 o l d \alpha_{2}^{old} α2old,更新后的解为 α 1 n e w \alpha_{1}^{new} α1new和 α 2 n e w \alpha_{2}^{new} α2new,并记未经剪辑时 α 2 \alpha_{2} α2的最优解为 α 2 n e w _ u n c \alpha_{2}^{new\_unc} α2new_unc。(未经剪辑就是不一定满足 0 ≤ α 2 n e w _ u n c ≤ C 0 \leq \alpha_{2}^{new\_unc} \leq C 0≤α2new_unc≤C)
我们先求 α 2 n e w _ u n c \alpha_{2}^{new\_unc} α2new_unc,再对其约束得到 α 2 n e w \alpha_{2}^{new} α2new。
我们假设最优值 α 2 n e w \alpha_{2}^{new} α2new必须满足:
L ≤ α 2 n e w ≤ H L\leq \alpha_{2}^{new}\leq H L≤α2new≤H
如上图所示,分两种情况讨论,L、H的值就是线段 l j l_{j} lj和边界相交的点,可以求出:
- y 1 = y 2 y_{1}=y_{2} y1=y2:
L = m a x ( 0 , α 2 o l d + α 1 o l d − C ) , H = m i n ( C , α 2 o l d + α 1 o l d ) L=max(0,\alpha_{2}^{old}+\alpha_{1}^{old}-C),H=min(C,\alpha_{2}^{old}+\alpha_{1}^{old}) L=max(0,α2old+α1old−C),H=min(C,α2old+α1old) - y 1 ≠ y 2 y_{1}\neq y_{2} y1=y2
L = m a x ( 0 , α 2 o l d − α 1 o l d ) , H = m i n ( C , C + α 2 o l d − α 1 o l d ) L=max(0,\alpha_{2}^{old}-\alpha_{1}^{old}),H=min(C,C+\alpha_{2}^{old}-\alpha_{1}^{old}) L=max(0,α2old−α1old),H=min(C,C+α2old−α1old)
得到 L , H L,H L,H后,我们先放一放,先去求 α 2 n e w _ u n c \alpha_{2}^{new\_unc} α2new_unc的值:
记
g ( x ) = ∑ i = 1 N α i y i K ( x i , x ) + b E i = g ( x i ) − y i g(x)=\sum_{i=1}^{N}\alpha_{i}y_{i}K(x_{i},x)+b \\ ~\\E_{i}=g(x_{i})-y_{i} g(x)=i=1∑NαiyiK(xi,x)+b Ei=g(xi)−yi
g ( x ) g(x) g(x)为预测值, E i E_{i} Ei为预测值与真实值之差。
则:
α 2 n e w _ u n c = α 2 o l d + y 2 E 1 − E 2 η \alpha_{2}^{new\_unc}=\alpha_{2}^{old}+y_{2}\frac{E1-E2}{\eta} α2new_unc=α2old+y2ηE1−E2
其中,
η = K 11 + K 22 − 2 K 12 = ∣ ∣ ϕ ( x 1 ) − ϕ ( x 2 ) ∣ ∣ 2 \eta = K_{11}+K_{22}-2K_{12}=||\phi(x_{1})-\phi(x_{2})||^{2} η=K11+K22−2K12=∣∣ϕ(x1)−ϕ(x2)∣∣2
再求 α 2 n e w \alpha_{2}^{new} α2new:
α 2 n e w = { H , α 2 n e w _ u n c > H α 2 n e w _ u n c , L ≤ α 2 n e w _ u n c ≤ H L , α 2 n e w _ u n c < L \alpha_{2}^{new}=\left\{\begin{matrix} H~~~~~~~,\alpha_{2}^{new\_unc}>H\\\alpha_{2}^{new\_unc}~~~~,L\leq \alpha_{2}^{new\_unc} \leq H \\ L~~~~~~, \alpha_{2}^{new\_unc}
根据
α 1 y 1 + α 2 y 2 = δ \alpha_{1}y_{1}+\alpha_{2}y_{2}=\delta α1y1+α2y2=δ
得到:
α 1 n e w = α 1 o l d + y 1 y 2 ( α 2 o l d − α 2 n e w ) \alpha_{1}^{new}=\alpha_{1}^{old}+y_{1}y_{2}(\alpha_{2}^{old}-\alpha_{2}^{new}) α1new=α1old+y1y2(α2old−α2new)
于是得到新的 α 1 \alpha_{1} α1和 α 2 \alpha_{2} α2。
3.2 变量的挑选方法
SMO算法要挑选的两个变量,一个( α 1 \alpha_{1} α1)是违反KKT条件的,另一个( α 2 \alpha_{2} α2)的选择标准是希望能使 α 2 \alpha_{2} α2有足够大的变化。
3.2.1 第一个变量的选择
SMO称选择第一个变量的过程称为外层循环。外层循环在训练样本中选取违反KKT条件的样本点,并将其对应的 α i \alpha_{i} αi作为第一个变量。
KKT条件:
- 当 α i = 0 \alpha_{i}=0 αi=0时, y i ( w ⋅ x i + b ) − 1 ≥ 0 y_{i}(w·x_{i}+b)-1\geq0 yi(w⋅xi+b)−1≥0
- 当 0 < α i < ξ i 0<\alpha_{i}<\xi_{i} 0<αi<ξi时, y i ( w ⋅ x i + b ) − 1 = 0 y_{i}(w·x_{i}+b)-1=0 yi(w⋅xi+b)−1=0
一般把松弛变量统一为一个量,记为 C C C。则:
当 0 < α i < C 0<\alpha_{i}0<αi<C 时, y i ( w ⋅ x i + b ) − 1 = 0 y_{i}(w·x_{i}+b)-1=0 yi(w⋅xi+b)−1=0
在检验选取过程中,外层循环首先遍历符合 0 < α i < C 0<\alpha_{i}
3.2.2 第二个变量的选择
SMO称选择第二个变量的过程称为内层循环。我们的选择标准是希望能使 α 2 \alpha_{2} α2有足够大的变化。
根据公式:
α 2 n e w _ u n c = α 2 o l d + y i ( E 1 − E 2 ) η \alpha_{2}^{new\_unc}=\alpha_{2}^{old}+\frac{y_{i}(E_{1}-E_{2})}{\eta} α2new_unc=α2old+ηyi(E1−E2)
可知 α 2 n e w \alpha_{2}^{new} α2new是依赖于 ∣ E 1 − E 2 ∣ |E_{1}-E_{2}| ∣E1−E2∣的,所以:
- 当 E 1 ≥ 0 E_{1}\geq0 E1≥0时,选择所有样本点中最小的 E i E_{i} Ei作为 E 2 E_{2} E2;
- 当 E 1 < 0 E_{1}<0 E1<0时,选择所有样本点中最大的 E i E_{i} Ei作为 E 2 E_{2} E2;
同时将挑选出的 E i E_{i} Ei相对应的 α i \alpha_{i} αi作为第二个变量( α 2 \alpha_{2} α2)
3.2.3 计算并更新阈值 b b b和差值 E i E_{i} Ei

4 Python代码实现SVM
import numpy as np
class SVM:
def init_args(self, max_iter, features, labels):
self.max_iter = max_iter
self.m, self.n = features.shape
self.X = features
self.Y = labels
self.b = 0.0
self.alpha = np.ones(self.m)
self.E = [self.calc_E(i) for i in range(self.m)]
self.C = 1.0
# 核函数,这里选用线性核
def kernel(self, x1, x2):
sum = 0
for i in range(self.n):
sum += x1[i]*x2[i]
return sum
# 计算预测值
def calc_g(self, i):
g = self.b
for j in range(self.m):
g += self.alpha[j]*self.Y[j]*self.kernel(self.X[i], self.X[j])
return g
# 计算预测值与真实值的差值
def calc_E(self, i):
return self.calc_g(i) - self.Y[i]
# 判断是否满足KKT条件
def judge_KKT(self, i):
if self.alpha[i]==0 and self.Y[i]*self.calc_g(i)>=1:
return True
elif 0<self.alpha[i]<self.C and self.Y[i]*self.calc_g(i)==1:
return True
return False
def get_alpha(self):
# 外层循环,找第一个变量,遍历样本点,找到第一个不满足KKT条件的
for i in range(self.m):
if self.judge_KKT(i) == False:
# 内层循环,找第二个变量
E1 = self.E[i]
if E1 >= 0:
j = min(range(self.m), key=lambda index : self.E[index])
else:
j = max(range(self.m), key=lambda index : self.E[index])
return i, j
def train(self, max_iter, features, labels):
# 迭代训练
self.init_args(max_iter, features, labels)
for i in range(self.max_iter):
# 选择 alpha1和alpha1
i1, i2 = self.get_alpha()
# 边界
if self.Y[i1] == self.Y[i2]:
L = max(0, self.alpha[i2]+self.alpha[i1]-self.C)
H = min(self.C, self.alpha[i2]+self.alpha[i1])
else:
L = max(0, self.alpha[i2]-self.alpha[i1])
H = min(self.C, self.alpha[i2]+self.alpha[i1]+self.C)
eta = self.kernel(self.X[i1], self.X[i1]) + self.kernel(self.X[i2], self.X[i2]) - 2*self.kernel(self.X[i1], self.X[i2])
alpha2_new_unc = self.alpha[i2] + self.Y[i2] * (self.E[i1] - self.E[i2]) / eta
if alpha2_new_unc > H:
alpha2_new = H
elif L <= alpha2_new_unc <= H:
alpha2_new = alpha2_new_unc
elif alpha2_new_unc < L:
alpha2_new = L
alpha1_new = self.alpha[i1] + self.Y[i1] * self.Y[i2] * (self.alpha[i2] - alpha2_new)
b1_new = -self.E[i1] - self.Y[i1] * self.kernel(self.X[i1], self.X[i1]) * (alpha1_new-self.alpha[i1]) - self.Y[i2] * self.kernel(self.X[i2], self.X[i1]) * (alpha2_new-self.alpha[i2])+ self.b
b2_new = -self.E[i2] - self.Y[i1] * self.kernel(self.X[i1], self.X[i2]) * (alpha1_new-self.alpha[i1]) - self.Y[i2] * self.kernel(self.X[i2], self.X[i2]) * (alpha2_new-self.alpha[i2])+ self.b
if 0 < alpha1_new < self.C:
b_new = b1_new
elif 0 < alpha2_new < self.C:
b_new = b2_new
else:
b_new = (b1_new + b2_new) / 2
# 更新参数
self.alpha[i1] = alpha1_new
self.alpha[i2] = alpha2_new
self.b = b_new
self.E[i1] = self.calc_E(i1)
self.E[i2] = self.calc_E(i2)
print("Train: {0} iterations have been done.".format(self.max_iter))
from sklearn.svm import SVC
svc = SVC()
svc.fit(X, Y)
svc.score(Xt, Yt)
参考:
- 《统计学习方法》李航
- 《机器学习》周志华
- SVM参考博客