Java批量解析微信dat文件,微信图片破解
Java批量解析微信dat文件,微信图片破解
- 前言
- 关于异或值怎么计算
- 代码
- 第二种方式,适合不懂怎么计算,想直接用的代码
前言
偶然看到有可以解密微信dat的文档,上网查了查,找到了一篇可以用的文章,不过转换过程代码是有问题的,在这里改了下发布上来。
附带依赖jdk8的微信图片破解小工具:链接:https://pan.baidu.com/s/1t_e5rMFKmIRDNQAfN5rtaQ
提取码:ymw6
关于异或值怎么计算
首先使用十六进制器打开微信dat文件,显示如下
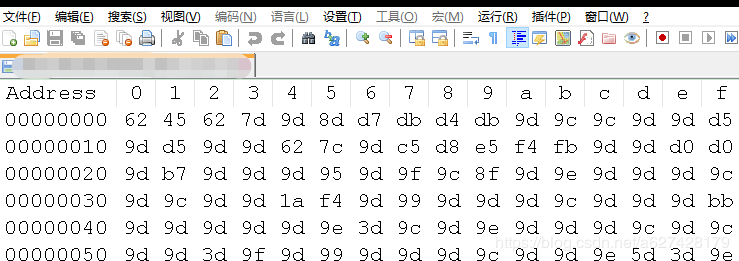
jpg图片文件头一般为FF D8 开头的,所以此处使用科学计算器,计算异或值
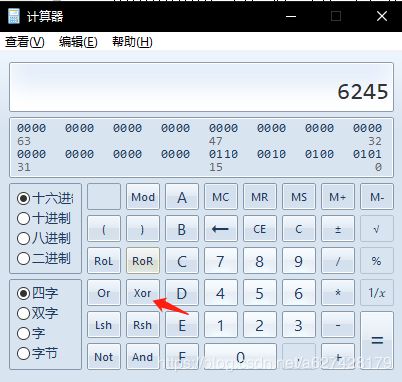
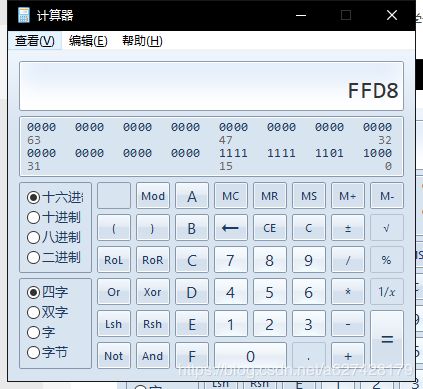
计算后的值

所以此处异或值就是0x9D
代码
以下是java代码,创建一个weChatImgRevert .java后复制进去就好啦。
此处的jdk版本需要1.8以上…,另外三个参数需要改成自己的哦~
package main.java.com.example.demo;
import java.io.*;
import java.util.Arrays;
import java.util.HashMap;
import java.util.Map;
import java.util.concurrent.atomic.AtomicReference;
public class weChatImgRevert {
public static void main(String[] args) {
String path = "C:\\Users\\Administrator\\Documents\\WeChat Files\\xxx\\FileStorage\\Image\\2019-07";
String targetPath = "D:\\weChat\\2019-07\\";
int xor = 0xCB;
convert(path, targetPath, xor);
}
/**
* @param path 图片地址
* @param targetPath 转换后目录
*/
private static void convert(String path, String targetPath, int xor) {
File[] file = new File(path).listFiles();
if (file == null) {
return;
}
int size = file.length;
System.out.println("总共" + size + "个文件");
AtomicReference<Integer> integer = new AtomicReference<>(0);
Arrays.stream(file).parallel().forEach(file1 -> {
try (InputStream reader = new FileInputStream(file1);
OutputStream writer =
new FileOutputStream(targetPath + file1.getName().split("\\.")[0] + ".jpg")) {
byte[] bytes = new byte[1024 * 10];
int b;
while ((b = reader.read(bytes)) != -1) {//这里的in.read(bytes);就是把输入流中的东西,写入到内存中(bytes)。
for (int i = 0; i < bytes.length; i++) {
bytes[i] = (byte) (int) (bytes[i] ^ xor);
if (i == (b - 1)) {
break;
}
}
writer.write(bytes, 0, b);
writer.flush();
}
integer.set(integer.get() + 1);
System.out.println(file1.getName() + "(大小:" + ((double) file1.length() / 1000) + "kb),进度:" + integer.get() +
"/" + size);
} catch (Exception e) {
e.printStackTrace();
}
});
System.out.println("解析完毕!");
}
/**
* 获取异或值,不一定准确,当解析不出来的时候,换一张图片的异或值来解析
*
* @param PhotoPath
* @return
*/
private static int getXor(String PhotoPath) {
File file = new File(PhotoPath);
try (InputStream reader = new FileInputStream(file)) {
int[] xors = new int[4];
xors[0] = reader.read() & 0xFF ^ 0xFF;
xors[1] = reader.read() & 0xFF ^ 0xD8;
reader.skip(file.length() - 1);
xors[2] = reader.read() & 0xFF ^ 0xFF;
xors[3] = reader.read() & 0xFF ^ 0xD9;
Map<Integer, Integer> map = new HashMap<>();
for (int xor : xors) {
if (map.containsKey(xor)) {
map.put(xor, map.get(xor) + 1);
} else {
map.put(xor, 1);
}
}
return map.values().stream().max(Integer::compareTo).get();
} catch (Exception e) {
e.printStackTrace();
}
return 0;
}
}
执行main方法后就可以在目标文件夹中去看转换后的图片了
以下是转换后的效果图片: 
第二种方式,适合不懂怎么计算,想直接用的代码
以下是java代码,创建一个WxChatImgRevert.java后复制进去就好啦。
此处的jdk版本需要1.8以上…,另外两个参数需要改成自己的哦~
此处的原理是判断图片文件的十六进制特征码。
package main.java.com.example.demo;
import java.io.*;
import java.util.Arrays;
import java.util.HashMap;
import java.util.Map;
import java.util.concurrent.atomic.AtomicInteger;
import java.util.concurrent.atomic.AtomicReference;
public class WxChatImgRevert2 {
public static void main(String[] args) {
String path = "C:\\Users\\Administrator\\Documents\\WeChat Files\\xxx\\FileStorage";
String targetPath = "D:\\weChat\\temp";
convert(path, targetPath);
}
/**
* @param path 图片目录地址
* @param targetPath 转换后目录
*/
private static void convert(String path, String targetPath) {
File[] file = new File(path).listFiles();
if (file == null) {
return;
}
int size = file.length;
System.out.println("总共" + size + "个文件");
AtomicReference<Integer> integer = new AtomicReference<>(0);
AtomicInteger x = new AtomicInteger();
for (File file1 : file) {
if (file1.isFile()) {
Object[] xori = getXor(file1);
if (xori != null && xori[1] != null){
x.set((int)xori[1]);
}
break;
}
}
Arrays.stream(file).parallel().forEach(file1 -> {
if (file1.isDirectory()) {
String[] newTargetPath = file1.getPath().split("/|\\\\");
File targetFile = new File(targetPath+File.separator+newTargetPath[newTargetPath.length - 1]);
if (!targetFile.exists()) {
targetFile.mkdirs();
}
convert(file1.getPath(),targetPath+File.separator+newTargetPath[newTargetPath.length - 1]);
return;
}
Object[] xor = getXor(file1);
if (x.get() == 0 && xor[1] != null && (int) xor[1] != 0) {
x.set((int) xor[1]);
}
xor[1] = xor[1] == null ? x.get() : xor[1];
try (InputStream reader = new FileInputStream(file1);
OutputStream writer =
new FileOutputStream(targetPath + File.separator + file1.getName().split("\\.")[0] + (xor[0] != null ?
"." + xor[0] : ""))) {
byte[] bytes = new byte[1024 * 10];
int b;
while ((b = reader.read(bytes)) != -1) {//这里的in.read(bytes);就是把输入流中的东西,写入到内存中(bytes)。
for (int i = 0; i < bytes.length; i++) {
bytes[i] = (byte) (int) (bytes[i] ^ (int) xor[1]);
if (i == (b - 1)) {
break;
}
}
writer.write(bytes, 0, b);
writer.flush();
}
integer.set(integer.get() + 1);
System.out.println(file1.getName() + "(大小:" + ((double) file1.length() / 1000) + "kb,异或值:" + xor[1] + ")," +
"进度:" + integer.get() +
"/" + size);
} catch (Exception e) {
e.printStackTrace();
}
});
System.out.println("解析完毕!");
}
/**
* 判断图片异或值
*
* @param file
* @return
*/
private static Object[] getXor(File file) {
Object[] xor = null;
if (file != null) {
byte[] bytes = new byte[4];
try (InputStream reader = new FileInputStream(file)) {
reader.read(bytes, 0, bytes.length);
} catch (Exception e) {
e.printStackTrace();
}
xor = getXor(bytes);
}
return xor;
}
/**
* @param bytes
* @return
*/
private static Object[] getXor(byte[] bytes) {
Object[] xorType = new Object[2];
int[] xors = new int[3];
for (Map.Entry<String, String> type : FILE_TYPE_MAP.entrySet()) {
String[] hex = {
String.valueOf(type.getKey().charAt(0)) + type.getKey().charAt(1),
String.valueOf(type.getKey().charAt(2)) + type.getKey().charAt(3),
String.valueOf(type.getKey().charAt(4)) + type.getKey().charAt(5)
};
xors[0] = bytes[0] & 0xFF ^ Integer.parseInt(hex[0], 16);
xors[1] = bytes[1] & 0xFF ^ Integer.parseInt(hex[1], 16);
xors[2] = bytes[2] & 0xFF ^ Integer.parseInt(hex[2], 16);
if (xors[0] == xors[1] && xors[1] == xors[2]) {
xorType[0] = type.getValue();
xorType[1] = xors[0];
break;
}
}
return xorType;
}
private final static Map<String, String> FILE_TYPE_MAP = new HashMap<String, String>();
static {
getAllFileType();
}
private static void getAllFileType() {
FILE_TYPE_MAP.put("ffd8ffe000104a464946", "jpg"); //JPEG (jpg)
FILE_TYPE_MAP.put("89504e470d0a1a0a0000", "png"); //PNG (png)
FILE_TYPE_MAP.put("47494638396126026f01", "gif"); //GIF (gif)
FILE_TYPE_MAP.put("49492a00227105008037", "tif"); //TIFF (tif)
FILE_TYPE_MAP.put("424d228c010000000000", "bmp"); //16色位图(bmp)
FILE_TYPE_MAP.put("424d8240090000000000", "bmp"); //24位位图(bmp)
FILE_TYPE_MAP.put("424d8e1b030000000000", "bmp"); //256色位图(bmp)
FILE_TYPE_MAP.put("41433130313500000000", "dwg"); //CAD (dwg)
FILE_TYPE_MAP.put("3c21444f435459504520", "html"); //HTML (html)
FILE_TYPE_MAP.put("3c21646f637479706520", "htm"); //HTM (htm)
FILE_TYPE_MAP.put("48544d4c207b0d0a0942", "css"); //css
FILE_TYPE_MAP.put("696b2e71623d696b2e71", "js"); //js
FILE_TYPE_MAP.put("7b5c727466315c616e73", "rtf"); //Rich Text Format (rtf)
FILE_TYPE_MAP.put("38425053000100000000", "psd"); //Photoshop (psd)
FILE_TYPE_MAP.put("46726f6d3a203d3f6762", "eml"); //Email [Outlook Express 6] (eml)
FILE_TYPE_MAP.put("d0cf11e0a1b11ae10000", "doc"); //MS Excel 注意:word、msi 和 excel的文件头一样
FILE_TYPE_MAP.put("d0cf11e0a1b11ae10000", "vsd"); //Visio 绘图
FILE_TYPE_MAP.put("5374616E64617264204A", "mdb"); //MS Access (mdb)
FILE_TYPE_MAP.put("252150532D41646F6265", "ps");
FILE_TYPE_MAP.put("255044462d312e360d25", "pdf"); //Adobe Acrobat (pdf)
FILE_TYPE_MAP.put("2e524d46000000120001", "rmvb"); //rmvb/rm相同
FILE_TYPE_MAP.put("464c5601050000000900", "flv"); //flv与f4v相同
FILE_TYPE_MAP.put("00000020667479706973", "mp4");
FILE_TYPE_MAP.put("49443303000000000f76", "mp3");
FILE_TYPE_MAP.put("000001ba210001000180", "mpg"); //
FILE_TYPE_MAP.put("3026b2758e66cf11a6d9", "wmv"); //wmv与asf相同
FILE_TYPE_MAP.put("524946464694c9015741", "wav"); //Wave (wav)
FILE_TYPE_MAP.put("52494646d07d60074156", "avi");
FILE_TYPE_MAP.put("4d546864000000060001", "mid"); //MIDI (mid)
FILE_TYPE_MAP.put("504b0304140000000800", "zip");
FILE_TYPE_MAP.put("526172211a0700cf9073", "rar");
FILE_TYPE_MAP.put("235468697320636f6e66", "ini");
FILE_TYPE_MAP.put("504b03040a0000000000", "jar");
FILE_TYPE_MAP.put("4d5a9000030000000400", "exe");//可执行文件
FILE_TYPE_MAP.put("3c25402070616765206c", "jsp");//jsp文件
FILE_TYPE_MAP.put("4d616e69666573742d56", "mf");//MF文件
FILE_TYPE_MAP.put("3c3f786d6c2076657273", "xml");//xml文件
FILE_TYPE_MAP.put("efbbbf2f2a0d0a53514c", "sql");//xml文件
FILE_TYPE_MAP.put("7061636b616765207765", "java");//java文件
FILE_TYPE_MAP.put("406563686f206f66660d", "bat");//bat文件
FILE_TYPE_MAP.put("1f8b0800000000000000", "gz");//gz文件
FILE_TYPE_MAP.put("6c6f67346a2e726f6f74", "properties");//bat文件
FILE_TYPE_MAP.put("cafebabe0000002e0041", "class");//bat文件
FILE_TYPE_MAP.put("49545346030000006000", "chm");//bat文件
FILE_TYPE_MAP.put("04000000010000001300", "mxp");//bat文件
FILE_TYPE_MAP.put("504b0304140006000800", "docx");//docx文件
FILE_TYPE_MAP.put("d0cf11e0a1b11ae10000", "wps");//WPS文字wps、表格et、演示dps都是一样的
FILE_TYPE_MAP.put("6431303a637265617465", "torrent");
FILE_TYPE_MAP.put("494d4b48010100000200", "264");
FILE_TYPE_MAP.put("6D6F6F76", "mov"); //Quicktime (mov)
FILE_TYPE_MAP.put("FF575043", "wpd"); //WordPerfect (wpd)
FILE_TYPE_MAP.put("CFAD12FEC5FD746F", "dbx"); //Outlook Express (dbx)
FILE_TYPE_MAP.put("2142444E", "pst"); //Outlook (pst)
FILE_TYPE_MAP.put("AC9EBD8F", "qdf"); //Quicken (qdf)
FILE_TYPE_MAP.put("E3828596", "pwl"); //Windows Password (pwl)
FILE_TYPE_MAP.put("2E7261FD", "ram"); //Real Audio (ram)
}
}
简要介绍下小工具:
打开小工具后的页面是这样子的,如果没有安装jdk8的话,可以在这里下载安装,不然是运行不了的
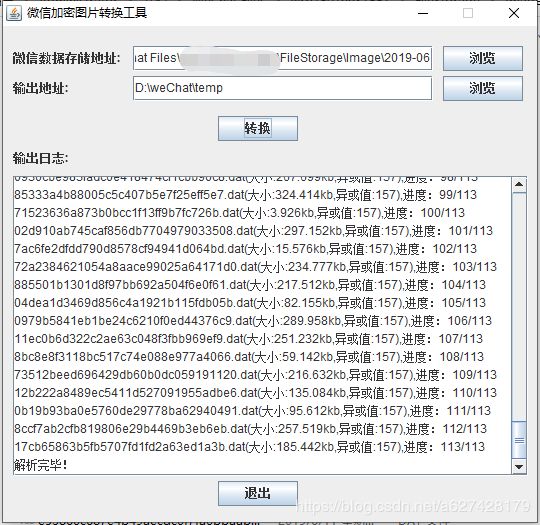
微信的数据存储地址一般是:C:\Users\Administrator\Documents\WeChat Files\xxx
可以整个扔进去,但是要注意,输出地址一定不能和存储地址相同,最好不要在同一个文件夹里面!!!
本质上,第一个是读取操作,第二个是写入操作,读取并不会破坏原文件,但是写入如果是同一个文件夹,并且存在同名文件,会被覆盖掉。转换后就是在你指定的输出目录里面
ps:小工具是花了一晚上随手写的,楼主估计都找不到源码在哪里了,所以将就着用吧。
参考文档
[1]: https://blog.csdn.net/weixin_42440768/article/details/88870077
[2]: https://www.jianshu.com/p/782730f7f016