GraphQL实现前后端分离(一):GraphQL 入门看这篇就够了
前言:
最近打算写一个关于GraphQL 的系列,总结一下在开发中对GraphQL服务的使用,同时也希望能对初次使用GraphQL以及正在使用GraphQL的童鞋提供一丢丢帮助。这个系列目前大致书写方向如下:
GraphQL入门
SpringBoot对GraphQL Java的集成开发环境的构建
GraphQL 在前端框架vue.js中的应用
GraphQL在实际开发中遇到的一些用法扩展(比如Scalar)、问题处理、需求处理、源码解析等
-----------------------------------------------------入门开始------------------------------------------------------------
1、GraphQL是什么?
GraphQL 是一个用于 API 的查询语言,是一个使用基于类型系统来执行查询的服务端运行时(类型系统由你的数据定义)。GraphQL 并没有和任何特定数据库或者存储引擎绑定,而是依靠你现有的代码和数据支撑,GraphQL 可以运行在任何后端框架或者编程语言之上。
上面这句释义来至GraphQL官网,不清楚类型系统(type system)的话,读起来可能会有点涩。。往后看就懂了。
2、为什么要是用GraphQL
GraphQL可以理解为是一个基于新的API标准,或者说基于对RESTful的封装的一种API查询语言。再过去的很多年里,RESTful被当做了API设计的一种标准(这里说RESTfu是一种设计标准其实不准确,说它是一种软件架构风格、设计风格更好,它只是提供了一组设计原则和约束条件。暂且这么说了。),但是在客户需求快速变化的今天,RESTful API显得有些死板僵化。而GraphQL的推出就是为了针对性的解决客户端数据访问的灵活性和高效。
怎么理解RESTful API 在适应当今复杂需求的时显露出来的僵化问题?或者说相比较而言Graphql API 的优势是什么呢?
在开发中RESTful API接口返回的数据格式、数据类型都是后端预先定义好的,如果返回的数据格式并不是调用者(前端)理想型,前端一般会通过以下两种方式来解决:
<1> 和后端沟通,改接口(更改数据源)
<2> 前端自己做适配工作(处理数据源)
一般如果是小型项目,或者说对应的是单前端需求,改后端接口比较好商量,对这个项目的有效运行影响不大。但是如果是大项目,譬如,我先在所在项目,一个后端API对应的是三接口,什么意思呢,就是一个后端API需要同时满足web、Android Q、IOS前端的不同的数据需求,这种情况下为了某一方需求要求改后端API,明显会顾此失彼,不现实。所以一般这种情况就需要前端自己做适配来满足自己的需求。
正是为了适应当今愈加复杂的需求环境,Facebook推出了Graphql API,一个可以帮助前后端解耦的API查询语言,让接口的返回值从静态变为动态,即调用者(前端)来声明接口返回什么数据。
举个例子:
假设在一个共享汽车管理系统中,客户端进来的首页,需要同时显示的部分信息有:当前用户的用户名,当前用户的近一周的订单信息,当前用户的账户余额信息。如下需求:

针对上面需求,RESTful API和GraphQL的处理方式是不同的。
RESTful API 分三次请求完成:
通过user.id 获取用户账号(zhxx)信息数据
通过user.id获取用户钱包(qbxx)信息数据
通过user.id获取用户订单(ddxx)信息数据
GraphQL web客户端做一次下面请求就可:

而且如果此时我的Android前端还需要上面zhxx数据中的age字段,那么Android前端只需在请求数据时,加上age字段即可:
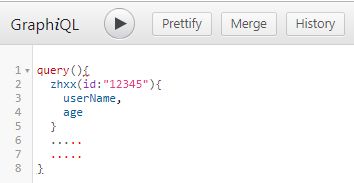
这就是Graphql官网所说的: ask exactly what you want!
通过上面描述,可以发现GraphQL API有如下优点:客户端可以自定义查询语句,数据获取灵活多变,服务端按需返回数据,减少网络的开销,提高了性能。而这些都是Restful API的弊端。
3、鸟瞰GraphQL的整个查询服务代码架构
GraphQL 其实就是想要什么,就传入需求,然后按需返回字段,具体字段处理是服务器所提供,,而 graphql 并不会关心服务器怎么处理。下面我先带大家看看一个GraphQL查询服务的整体流程是怎么走的,懂得GraphQL处理业务的流程,基本就知道怎么开始摸索开发了:
3.1 先看看GraphQL服务的大致工作流程图:

3.2 来个具体案例实现上图业务处理流程:查询客户端登录的用户信息(只说大致流程,下篇详解开发细节。)
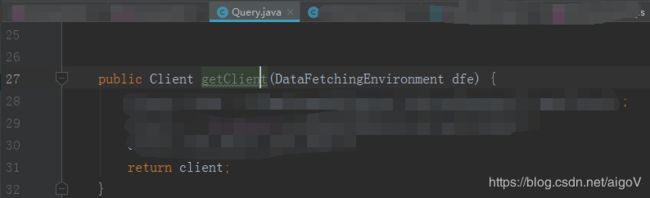
(1) java服务端定义业务方法,查出所需数据,类似这样(这其实就是后面要讲的 Resolver(解析器)):
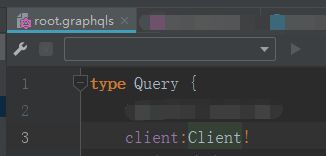
(2)在.graphqls文件中定义所需数据的字段、字段类型,类似这样(这里就开始涉及Granphql类型系统的知识了):
(2.1) 定义graphql查询方法
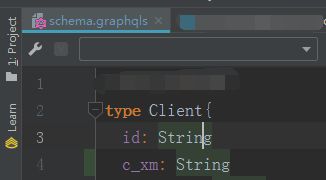
(2.2)定义Client对象的类型属性
(3) 前台按照约定,编写查询语句,发送请求取数据,如下:

在上面这个查询请求中,我们可以将查询语句拆分为几个部分:
<1> 我们从query这个查询的根对象开始定义查询,query是一个特殊的对象,这个对象名不是你自定义的,但是这个对象的属性,也就是之后出现所有子查询请求,都是由你来定义的。通俗的来说,query是所有子查询的入口,所有的查询请求都将从这里进入。
<2> 这里前端告知需要查询client的数据,client是一个我自定义的查询对象,它表示的是客户的登录信息,在此刻它也变成了query查询对象里的一个属性了。现在我将开始查询client对象里面一些属性数据。
<3> 现在前端告诉我,他只需要client里面的id,c_xm属性数据,其它的诸如性别,住址都不要。于是,整个graphql查询语句就写成了上面这样。
4、一些关于Graphql 的重要概念解释:
4.1 Granphql Schema
每一个 GraphQL 服务都会定义一套类型,用以描述你可能从那个服务查询到的数据。每当查询到来,服务器就会根据 schema 验证并执行查询。那么这里的说的schema什么?这关乎我们理解Granphql 类型系统,所以在说Granphql 类型系统之前,我们的先弄懂GraphQL Schema。
与XML Schema 的概念类似,Schema由服务端来定义,用于定义API接口,并依靠Schema来生成文档以及对客户端请求进行校验。Schema只是一个概念,它是由各种数据类型及其字段组成,而每个类型的每个字段都有相应的函数来返回数据。如下面这个,就是一个Schema:
type Query {
#用户对象
client:Client!
}
# 用户对象
type Client{
id: String
login_id: String
rid: String
c_xm: String
}
上面定义了两个类型,Client和Query:Client有几个字段分别是id、Login_id、rid、c_xm;Query是个特殊的类型,是查询入口,所有要查询的都放着里面。Client类型中的字段都有自动生成的函数来返回数据,类似于这种:
function Client_id(client) {
return client.getId();
}4.2 Granphql 类型系统(Type System)
GraphQL作为一种应用层的查询语言,它有自己的数据类型,用来描述数据(换句话说:用它自己的数据类型来定义你想要查询的对象及对象的属性,类似Java定义属性或对象的数据类型:String name、JSONObject data。Graphql定义查询对象和对象属性如上3.2的(2)部分提到的)。比如标量类型、集合类型、Object类型、枚举等,甚至有接口类型,这些构成了Graphql的Type System。
GraphQL 服务可以用任何语言来编写运行,因为它并不依赖于任何编程语言的句法来与 GraphQL schema 沟通,它定义了自己的语言:GraphQL schema language —— 它和 GraphQL 的查询语言很相似,能够和 GraphQL schema 之间可以正常沟通。
4.2.1 对象类型和字段(Object Types and Fields)
一个 GraphQL schema 中的最基本的组件是对象类型,它表示你可以从服务器上获取到什么类型的对象,以及这个对象的所有属性字段(如果你需要它所有字段的话)。使用 GraphQL schema language,可以如下表示:
#国家对象
type Country{
#国家名称
name: String
#省份
province: String
}Country是一个 GraphQL 对象类型,同Java对象一样,它也会拥有一些字段。schema 中的大多数类型都会是对象类型。name和province是Country对象类型上的字段。当你查询Country对象时,就会获得有且仅有name和province字段。String是内置的标量类型,标量类型下面详述。- # 号是GraphQL schema中用来注释代码的
4.2.1 标量类型(Scalar Types)
从上面说到的对象类型可以知道,一个对象类型同java对象一样,有自己的对象名和属性字段,它的属性字段也需要Graphql的类型系统给出具体类型来注释,以便同服务器的传递过来的不同类型的数据不起冲突。所以Graphql的类型系统便定义了标量类型,它是解析到单个标量对象的类型,无法在查询中对它进行次级选择,标量类型是不能包含子字段(通俗来讲,你在上面秒速文件中,按住ctrl键,鼠标点击String,点不进去了,但是你点击第一个Dwxx却可以点进去,并定位到下面的type Dwxx)。
目前 GraphQL 自带的标量类型有如下几个(注意首字母):
Int:有符号 32 位整数。Float:有符号双精度浮点值。String:UTF‐8 字符序列。Boolean:true或者false。ID:常用于获取数据的唯一标志,或缓存的键值,它也会被序列化为String,但可读性差
除此之外,我们也可以自定以标量类型来满足我们的实际开发需求,比如,我可以定义一个名为 yyyymmdd 的yyyymmdd格式的日期标量类型,具体实现后面讲。
4.2.2 集合 (List)
在GraphQL规范中可以使用一个类型修饰符方括号:[] 来标记一个类型为 List,这有点像java中定义数组。它表示这个字段会返回这个类型的数组(集合)。
例如下面这个例子,一个Country有很多个province,province就表示为一个集合或者说数组:
#国家对象
type Country{
#国家名称
name: String
#省份
province: [String]
}4.2.3 空(null)、非空 (Non-Null)
在GraphQL 规范中,通过在类型名后面添加一个叹号: ! 来将其标注为非空。这样后台服务器就必须要对这个字段返回一个非空的值。如果后台服务器返回了一个null给这个字段,GraphQL 就发生错误,同时客户端也会受到这个错误信息。
例:
#国家对象
type Country{
#国家名称
name: String!
#省份
province: [String!]
#市
city:[String]!
#乡镇
town:[String!]!
}String!后面加的这个英文叹号表示name这个字段是非空的,当你查询这个字段时Graphql必须要给你返回一个非null的值。[String!]表示province的返回值是一个非空字符串的数组(集合)。即数组本身可以为空,但是其不能有任何空值成员,详细参照下面:
province: null // 有效
province: [] // 有效
province: ['a', 'b'] // 有效
province: ['a', null, 'b'] // 错误[String]!表示city的返回值是一个不可为空的字符串数组(集合)(注意同上面的语言表达有异)。即数组本身不能为空,但是其可以包含空值成员,详细参照下面:
city: null // 错误
city: [] // 有效
city: ['a', 'b'] // 有效
city: ['a', null, 'b'] // 有效[String!]!表示town的值是一个 非空字符串的非空数组(集合)。即返回的集合不能为空,集合中也不能存在空值。参考下面:
city: null // 错误
city: [] // 错误
city: ['a', 'b'] // 有效
city: ['a', null, 'b'] // 错误4.2.4 参数(Arguments)
实际开发中,我们可能需要前端提交查询请求的同时,传递参数给我们供我们后台服务器拿去执行查询。
举个例子,现有这样一个需求背景:前端需要查询单位信息数据,后台提供的查询接口,支持前台输入单位代码(dwdm),机构名(jgm)等参数来精确查询,其中单位代码是比输入项,机构名为选填。那么graphql的描述文件(或者说schema )可以这样写:
type query{
#查询单位信息
dwxx(
#单位代码,必填
dwdm:String!
#单位名称
dwmc:String
):Dwxx
}
type Dwxx{
id:Int
..
这里是要返回的单位信息对象类型的一些属性字段
}4.3 Resolver
如果你仅在Schema中的Query{ }查询接口中声明了若干子query函数和定义它的返回值类型,那么此刻你只完成了一半的工作,因为你还需要提供相关Query所返回数据的后台逻辑。所以为了能够使GraphQL正常工作,你还需要再了解一个核心概念——Resolver(解析函数)。
GraphQL中官方文档中对于每个子Query和与之对应的Resolver有明确的定义规范,以确保GraphQL能把Schema中每个子query同它们的Resolver一一对应起来,最终实现后端逻辑处理数据后丢给Graphql,Graphql再返回数据给前端。
Granphql官方文档中,Resolver命名规范如下(注意红色部分就是方法名命名格式,任选其一就可):
is
get
getField
就上面规范举个例子,比如关于
type Query {
#用户对象
client:Client!
}这Query中的子query client, 它的Resolver的名字可以为client、isClient、getClient、getFieldClient,一般我会直接选第一种方式。
5、鸟瞰 Granphql 的内部运行机制
我这里写了一个Schema文件来定义返回值type,type Query{ }部分代码就不写了,实际上type Query{ }这个查询入口可以单独写个Schema文件,和type car这种类型定义的Schema文件区分开来,这样代码可读性更强(在type Query{ }的Schema文件中按住Ctrl键,鼠标单击 car ,是可以跳到type car { }里面的,和java一样,可以实现代码追踪)。好了,先看下面type定义:
#汽车
type car{
#车辆编号
id: ID
#备注
txt: String
#生产商
product: company
}
#汽车生产商
type company{
#生产商编码
id: ID
#生产商名字
name: String
}此时前端开始请求数据:
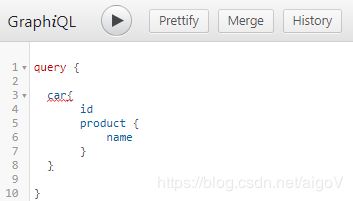
现在我们来看看这段请求,GraphQL API是如何解析这段查询语句的:
- 首先进行第一层解析,当前GraphQL
Query的Root Query类型是query(Root Query类型一种有三个,还有mutation 更改,subscription 订阅 这两个类型入口,暂不描述。),同时需要它的子query名字是 car - 之后会尝试使用car的
Resolver获取解析数据,第一层解析完毕 -
之后对第一层解析的返回值,进行第二层解析,当前
car还包含2个属性需要查询,分别是id、product- id在type car中为标量类型,解析结束
- product在type product类型中为对象类型company,于是Granphql尝试使用
company的Resolver获取数据,当前field解析完毕 - 之后对第二层解析的返回值,进行第三层解析,当前product还包含一个属性
name,由于它是标量类型,解析结束。返回数据至前端
通过上面解析,我们知道了GraphQL大体的解析流程就是遇到一个Query之后,尝试使用它的Resolver取值,之后再其Resolver对返回值进行解析,这个过程是递归的,直到所解析Field的类型是Scalar Type(标量类型)为止。解析的整个过程我们可以把它想象成一个很长的Resolver Chain(解析链)。
这里对GraphQL的解析过程的解释只是比较粗略的概括,其内部运行机制远比这个复杂,但是对于程序员来说,正常情况下,了解这些就足够你比较清晰的开始开发项目了。
现在你再把5这部分回过头去同3把部分结合起来看一下,就会发现真正的豁然开朗了。
---------------看完这篇入门,再看我下一篇就更清晰了:
用真实项目手把手教你使用SpringBoot集成GraphQL服务,并进行流程开发。
---------------有时间再补充一下 mutation 更改,subscription 订阅 这两个Query Root 中的类型入口---------