Huffman 编解码算法实现与压缩效率分析
一、实验原理
1 熵,又称为“信息熵” (Entropy)
1.1 在信息论中,熵是信息的度量单位。信息论的创始人 Shannon 在其著作《通信的 数学理论》中提出了建立在 概率统计模型上的信息度量。他把信息定义为“用来 消除不确定性的东西”。
1.2 一般用符号 H 表示,单位是比特。对于任意一个随机变量 X,它的熵定义如下:

1.3 变量的不确定性越大,熵也就越大。换句话说,了解它所需要的信息量也就越大。
2 Huffman 编码
2.1 Huffman Coding (霍夫曼编码)是一种无失真编码的编码方式,Huffman 编码是可 变字长编码(VLC)的一种。
2.2 Huffman 编码基于信源的概率统计模型,它的基本思路是,出现概率大的信源符 号编长码,出现概率小的信源 符号编短码,从而使平均码长最小。
2.3 在程序实现中常使用一种叫做树的数据结构实现 Huffman 编码,由它编出的码是 即时码。
3 Huffman 编码的方法
3.1 统计符号的发生概率;
3.2 把频率按从小到大的顺序排列
3.3 每一次选出最小的两个值,作为二叉树的两个叶子节点,将和作为它们的根节点, 这两个叶子节点不再参与比 较,新的根节点参与比较;
3.4 重复 3,直到最后得到和为 1 的根节点;
3.5 将形成的二叉树的左节点标 0,右节点标 1,把从最上面的根节点到最下面的叶 子节点途中遇到的 0,1 序列串 起来,就得到了各个符号的编码。
4.静态链接库的使用
本实验包含两个project,第一个project为huff_code,是实现Huffman编码,会生成一个.lib文件。第二个project为Huff_run。在此,需要配置库目录属性和附加依赖属性。



二、Huffman编解码流程
编码流程:

解码流程:

1.节点数据类型定义
typedef struct huffman_node_tag
{
unsigned char is Leaf; /* 是否为叶结点*/
unsigned long count; /* 信源中出现频数 */
struct huffman_node_tag *parent; /* 父节点指针 */
union
{
struct
{
struct huffman_node_tag *zero, *one; /*如果不是树叶,则此项为该结点左右孩子的指针*/
};
unsigned char symbol; /*如果是树叶,为某个信源符号 */
};
} huffman_node; 2.码字节点 数据类型定义
typedef struct huffman_code_tag
{
/* 码字的长度(单位:位) */
unsigned long numbits;
/* 码字,
码字的第 1 位存于 bits[0]的第 1 位,
码字的第 2 位存于 bits[0]的第 2 位,
码字的第 8 位存于 bits[0]的第 8 位,
码字的第 9 位存于 bits[1]的第 1 位 */
unsigned char *bits;
} huffman_code; 三、Huffman代码分析
1.主函数
int
main(int argc, char** argv)
{
char memory = 0;
char compress = 1;
int opt;
const char *file_in = NULL, *file_out = NULL;
//step1:add by yzhang for huffman statistics
const char *file_out_table = NULL;
//end by yzhang
FILE *in = stdin;
FILE *out = stdout;
//step1:add by yzhang for huffman statistics
FILE * outTable = NULL;
//end by yzhang
/* Get the command line arguments. */
while((opt = getopt(argc, argv, "i:o:cdhvmt:")) != -1) //演示如何跳出循环,及查找括号对
{
switch(opt)
{
case 'i'://输入文件
file_in = optarg;
break;
case 'o'://输出文件
file_out = optarg;
break;
case 'c'://编码
compress = 1;
break;
case 'd'://解码
compress = 0;
break;
case 'h'://参数用法输出到屏幕
usage(stdout);
return 0;
case 'v'://版本信息输出到屏幕
version(stdout);
return 0;
case 'm'://对内存数据进行编码
memory = 1;
break;
// by yzhang for huffman statistics
case 't'://编码结果输出
file_out_table = optarg;
break;
//end by yzhang
default:
usage(stderr);
return 1;
}
}
/* If an input file is given then open it. */
if(file_in)
{
in = fopen(file_in, "rb");
if(!in)
{
fprintf(stderr,
"Can't open input file '%s': %s\n",
file_in, strerror(errno));
return 1;
}
}
/* If an output file is given then create it. */
if(file_out)
{
out = fopen(file_out, "wb");
if(!out)
{
fprintf(stderr,
"Can't open output file '%s': %s\n",
file_out, strerror(errno));
return 1;
}
}
//by yzhang for huffman statistics
if(file_out_table)
{
outTable = fopen(file_out_table, "w");
if(!outTable)
{
fprintf(stderr,
"Can't open output file '%s': %s\n",
file_out_table, strerror(errno));
return 1;
}
}
//end by yzhang
if(memory)//memeory=1编码,memory!=1解码
{
return compress ?
memory_encode_file(in, out) : memory_decode_file(in, out);
}
if(compress) //change by yzhang
huffman_encode_file(in, out,outTable);//step1:changed by yzhang from huffman_encode_file(in, out) to huffman_encode_file(in, out,outTable)
else
huffman_decode_file(in, out);
if(in)
fclose(in);
if(out)
fclose(out);
if(outTable)
fclose(outTable);
return 0;
}(1)第一次扫描,统计信源字符发生频率(8 比特,共 256 个信源符号)。
<1>创建一个 256 个元素的指针数组,用以保存 256 个信源符号的频率。其下 标对应相应字符的 ASCII 码。
<2>数组中的非空元素为当前待编码文件中实际出现的信源符号。
<3>程序代码如下:
typedef huffman_node* SymbolFrequencies[MAX_SYMBOLS];
SymbolFrequencies sf;
static unsigned int get_symbol_frequencies(SymbolFrequencies *pSF, FILE *in)
{
int c;
/* 总信源符号数初始化为 0 */
unsigned int total_count = 0;
/* 将所有信源符号地址初始化为 NULL(0) */
init_frequencies(pSF);
/* 第一遍扫描文件 */
while ((c = fgetc(in)) != EOF)
{
unsigned char uc = c;
/* 如果是一个新符号,则产生该字符的一个新叶节点 */
if (!(*pSF)[uc])
(*pSF)[uc] = new_leaf_node(uc);
/* 当前字符出现的频数+1 */
++(*pSF)[uc]->count;
/* 总信源符号数 +1 */
++total_count;
}
return total_count;
}<1>按频率从小到大顺序排序并建立 Huffman 树
static SymbolEncoder* calculate_huffman_codes(SymbolFrequencies * pSF)
{
unsigned int i = 0;
unsigned int n = 0;
huffman_node *m1 = NULL, *m2 = NULL;
SymbolEncoder *pSE = NULL;
/* 按信源符号出现频率大小排序.小概率符号在前(pSF 数组中) * 下标较小 */
qsort((*pSF), MAX_SYMBOLS, sizeof((*pSF)[0]), SFComp);
/* 得到当前待编码文件中所出现的信源符号的种类总数 */
for (n = 0; n < MAX_SYMBOLS && (*pSF)[n]; ++n);
/* * 建立 huffman 树。需要合并 n-1 次,所以循环 n-1 次。 */
for (i = 0; i < n - 1; ++i)
{
/* 将 m1、m2 置为当前频数最小的两个信源符号 */
m1 = (*pSF)[0]; m2 = (*pSF)[1];
/* 将 m1、m2 合并为一个 huffman 结点加入到数组中,
左右孩子分别置为 m1、m2 的地址,频数为 m1、m2 的频数
* 之和。 */
(*pSF)[0] = m1->parent = m2->parent =
new_nonleaf_node(m1->count + m2->count, m1, m2);
(*pSF)[1] = NULL;
/* 在 m1、m2 合并后重新排序 */
qsort((*pSF), n, sizeof((*pSF)[0]), SFComp);
}
/* 由建立的 huffman 树对计算每个符号的码字. */
pSE = (SymbolEncoder*)malloc(sizeof(SymbolEncoder));
memset(pSE, 0, sizeof(SymbolEncoder));
build_symbol_encoder((*pSF)[0], pSE);
return pSE;
}
typedef huffman_code* SymbolEncoder[MAX_SYMBOLS];
/* 256 个 huffman_code 的指针,位置上对应于 ASCII 的顺序,用于保存码表 */
void build_symbol_encoder(huffman_node *subtree, SymbolEncoder *pSF)
{
if (subtree == NULL) /* 是否已到了 root, 是则说明编码结束,return */
return;
if (subtree->isLeaf) /* 是叶结点则产生码字 */
(*pSF)[subtree->symbol] = new_code(subtree);
else
{
build_symbol_encoder(subtree->zero, pSF);
/* 递归, 中序遍历 */
build_symbol_encoder(subtree->one, pSF);
}
}
huffman_code* new_code(const huffman_node* leaf)
{
/* Build the huffman code by walking up to
* the root node and then reversing the bits,
* since the Huffman code is calculated by
* walking down the tree. */
unsigned long numbits = 0; /* 码长 */
unsigned char* bits = NULL; /* 码字首地址 */
huffman_code *p;
while (leaf && leaf->parent) /* leaf !=0: 当前字符存在,应该编码 */
/* leaf->parent !=0: 当前字符的编码仍未完成,即未完成 由叶至根的该字符的编码过程 */
{
huffman_node *parent = leaf->parent;
unsigned char cur_bit = (unsigned char)(numbits % 8); /* 所编位在当前 byte 中的位置 */
unsigned long cur_byte = numbits / 8; /* 当前是第几个 byte */
/* If we need another byte to hold the code,
then allocate it. */
/* realloc 这里很关键,它与 malloc 不同,它在保持原有的数据不变的情
况下重新分配新的空间,原有数据存在新空间中的前面部分
(这里空间的地址可 能有变化) */
if (cur_bit == 0)
{
size_t newSize = cur_byte + 1;
bits = (unsigned char*)realloc(bits, newSize);
bits[newSize - 1] = 0; /* 初始化新分配的 8bit 为 0 */
}
/* If a one must be added then or it in. If a zero
* must be added then do nothing, since the byte
* was initialized to zero. */
if (leaf == parent->one)
bits[cur_byte] |= 1 << cur_bit; /* 左移 1 至当前 byte 的当前位(待编位) */
++numbits;
leaf = parent;
}
if (bits)
reverse_bits(bits, numbits); /* 整个码字逆序 */
p = (huffman_code*)malloc(sizeof(huffman_code));
p->numbits = numbits;
p->bits = bits; /* 整数个字节。与 numbits 配合才可得到真正码字 */
return p;
}
for (i = 0; i < MAX_SYMBOLS; ++i)
{
huffman_code *p = (*se)[i];
if (p)
{
unsigned int numbytes;
/* Write the 1 byte symbol. */
fputc((unsigned char)i, out);
/* Write the 1 byte code bit length. */
fputc(p->numbits, out);
/* Write the code bytes. */
numbytes = numbytes_from_numbits(p->numbits);
if (fwrite(p->bits, 1, numbytes, out) != numbytes)
return 1;
}
}
int do_file_encode(FILE* in, FILE* out, SymbolEncoder *se)
{
unsigned char curbyte = 0;
unsigned char curbit = 0;
int c;
while ((c = fgetc(in)) != EOF) /* 遍历文件的每一个字符(/字节) */
{
unsigned char uc = (unsigned char)c;
huffman_code *code = (*se)[uc]; /* 查表 */
unsigned long i;
for (i = 0; i < code->numbits; ++i) /* 将码字写入文件 */
{
/* Add the current bit to curbyte. */
curbyte |= get_bit(code->bits, i) << curbit;
/* If this byte is filled up then write it
* out and reset the curbit and curbyte. */
if (++curbit == 8) {
fputc(curbyte, out);
curbyte = 0;
curbit = 0;
}
}
}
/* * If there is data in curbyte that has not been
* output yet, which means that the last encoded
* character did not fall on a byte boundary,
* then output it.
*/ if (curbit > 0) fputc(curbyte, out);
return 0;
}
(1)读取码表并重建据此 Huffman 树
huffman_node* read_code_table(FILE* in, unsigned int *pDataBytes)
{
huffman_node *root = new_nonleaf_node(0, NULL, NULL);
unsigned int count;
if (fread(&count, sizeof(count), 1, in) != 1) // 得到码表中的符号数
{
free_huffman_tree(root);
return NULL;
}
/* Read the number of data bytes this encoding represents. */
if (fread(pDataBytes, sizeof(*pDataBytes), 1, in) != 1)
{
free_huffman_tree(root); return NULL;
}
/* Read the entries. */
while (count-- > 0)
/* 检查是否仍有叶节点未建立,每循环一次建立起一条由根
节点至叶结点(符号)的路径 */
{
int c;
unsigned int curbit;
unsigned char symbol;
unsigned char numbits;
unsigned char numbytes;
unsigned char *bytes;
huffman_node *p = root;
if ((c = fgetc(in)) == EOF)
{
free_huffman_tree(root);
return NULL;
}
symbol = (unsigned char)c; // 符号
if ((c = fgetc(in)) == EOF)
{
free_huffman_tree(root);
return NULL;
}
numbits = (unsigned char)c; // 码长
numbytes = (unsigned char)numbytes_from_numbits(numbits);
bytes = (unsigned char*)malloc(numbytes);
// 为读取码字分配空间
if (fread(bytes, 1, numbytes, in) != numbytes) // 读取码字
{
free(bytes);
free_huffman_tree(root);
return NULL;
}
/* * Add the entry to the Huffman tree. The value
* of the current bit is used switch between
* zero and one child nodes in the tree. New nodes
* are added as needed in the tree. */
for (curbit = 0; curbit < numbits; ++curbit)
// 读取当前码字的每一位,并依 据读取的结果逐步建立起由根节点至该符号叶结点的路径
{
if (get_bit(bytes, curbit)) // 当前读取位是否为’1’
{ // 当前读取位为’1’
if (p->one == NULL)
{
p->one = curbit == (unsigned char)(numbits - 1)
/* 是否是当 前码字的最后一位,是,则新建叶结点;不是,则新建非叶结点。 */
? new_leaf_node(symbol)
: new_nonleaf_node(0, NULL, NULL);
p->one->parent = p; // ‘1’的一枝的父节点指向当前节点
}
p = p->one; // 沿’1’方向下移一级
}
else
{ // 当前读取位为’0’
if (p->zero == NULL)
{
p->zero = curbit == (unsigned char)(numbits - 1)
? new_leaf_node(symbol)
: new_nonleaf_node(0, NULL, NULL);
p->zero->parent = p;
}
p = p->zero;
}
}
free(bytes);
}
return root; // 返回 Huffman 树的根结点
}(2)读取 Huffman 码字,并解码输出
Int huffman_decode_file(FILE *in, FILE *out)
{
huffman_node *root, *p;
int c;
unsigned int data_count;
/* Read the Huffman code table. */
root = read_code_table(in, &data_count);
if (!root)
return 1; // Huffman 树建立失败
/* Decode the file. */
p = root;
while (data_count > 0 && (c = fgetc(in)) != EOF) // data_count >0 :逻辑上仍有 数据;(c = fgetc(in)) != EOF):文件中仍有数据。
{
unsigned char byte = (unsigned char)c;
// 1byte 的码字
unsigned char mask = 1; // mask 用于逐位读出码字
while(data_count > 0 && mask) // loop9: mask = 0x00000000,跳出循环
{
p = byte & mask ? p->one : p->zero; // 沿 Huffman 树前进
mask <<= 1; // loop1: byte & 0x00000001
// loop2: byte & 0x00000010
// ……
// loop8: byte & 0x10000000
if (p->isLeaf) // 至叶结点(解码完毕)
{
fputc(p->symbol, out);
p = root;
--data_count; }
}
}
free_huffman_tree(root); // 所有 Huffman 码字均已解码输出,文件解码完毕
return 0;
}四、实验结果分析
1.,输出编码结果文件(以列表方式显示字符、字符发生的概率、字符对应编码码字长度、字符对应编码码字)。
以doc文件为例:
2.选择十种不同格式类型的文件,使用Huffman编码器进行压缩得到输出的压缩比特流文件:

3.以表格形式表示的实验结果:
| 文件类型 | doc | psd | jpg | MP4 | yuv | xls | ppt | exe | zip | |
| 平均码长 | 7.67 | 7.12 | 7.98 | 8.00 | 8.00 | 2.38 | 4.19 | 7.66 | 5.79 | 8.00 |
| 信源熵(bit/symbol) | 7.64 | 7.08 | 7.96 | 7.98 | 7.98 | 2.29 | 4.17 | 7.62 | 5.74 | 7.99 |
| 原文件大小(kB) | 3083 | 11454 | 355 | 1065 | 2637 | 732 | 49 | 1618 | 374 | 3499 |
| 压缩后文件大小(kB) | 2956 | 10195 | 355 | 1065 | 2637 | 219 | 27 | 1551 | 272 | 3499 |
| 压缩比 | 1.04 | 1.12 | 1.00 | 1.00 | 1.00 | 3.34 | 1.81 | 1.04 | 1.38 | 1.00 |
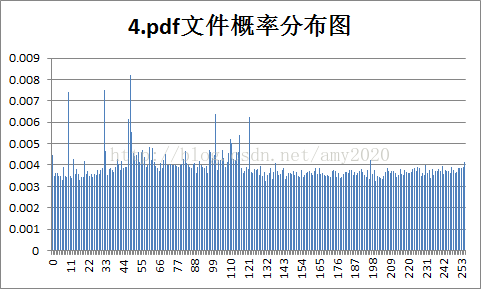
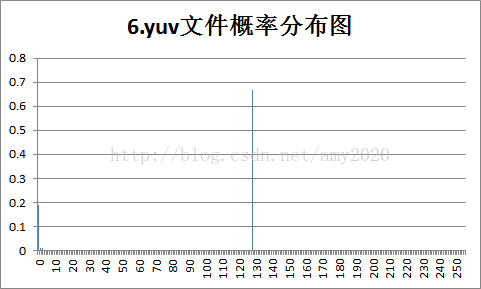
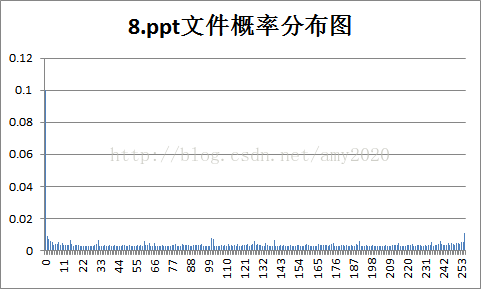
4.各样本文件的概率分布图:
 |
 |
 |
 |
 |
 |
 |
 |
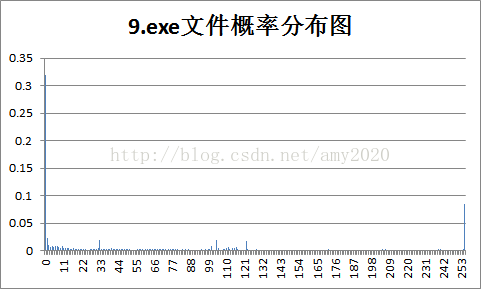 |
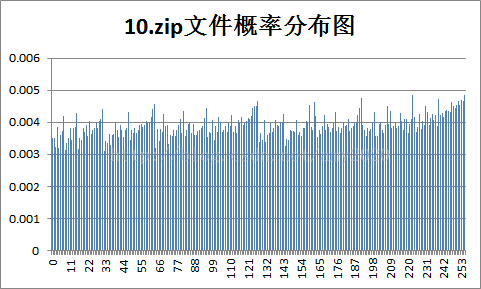 |
5.实验结果的分析。根据3和4的结果,对各种不同类型文件的统计特性和压缩效率进行分析:
a.Huffman的信源熵是平均码长的最下限,共有256种符号,最大信源熵为8bit/symbol;
b.由图分析可知,概率分布越均匀,压缩比越小,反之,概率分布越不均匀,压缩比越大;