java实现网格法、KDTree空间检索
Spatial Query
一、介绍
二、问题描述
2.1具体任务
2.2程序输入
2.3 程序输出
三、问题解答
3.1 数据预处理
3.2 Grid-based Spatial Indexing
3.2.1 搜索的特点
3.2.2 范围查询
3.2.3 最邻近查询
3.2.4 基于网格查询的优缺点
3.3 KD-Tree Spatial Indexing
3.3.1 搜索的特点
3.2.2 范围查询
3.2.3最邻近查询
四、代码实现
4.1 程序总流程
4.2 具体代码实现
五、程序运行结果
5.1 网格法空间搜索:
5.1.1最邻近算法
5.1.2范围查找算法
5.1.3圆范围查找
5.2 KD-Tree空间搜索
5.2.1最邻近算法查找
5.2.2范围查找
5.2.3半径查找
5.3 索引文件建立时间对比
Spatial Query
一、介绍
空间索引(spatial index)是指依据空间对象的位置和形状,按一定顺序排列的一种数据结构,其中包含空间对象的概要信息如对象的标识、最小外接矩形(minimum bounding rectangle,MBR)及指向空间对象实体的指针。空间索引使空间操作能够快速访问操作对象,从而提高效率。目前普遍认为,空间索引技术的采纳与否以及空间索引的性能优劣直接影响地理信息系统(GIS)的整体性能。
空间索引技术可大致分为:基于树结构,基于网格划分,混合型。这里主要分析基于网格以及KD树的空间索引。
1.网格索引法:
格网型空间索引的基本思想是将研究区域用横竖线条划分大小相等或不等的格网,记录每一个格网所包含的空间实体。当用户进行空间查询时,首先计算出用户查询对象所在格网,然后再在该网格中快速查询所选空间实体,这样一来就大大地加速了空间索引的查询速度。
把一幅图的矩形地理范围均等地划分为 m行n列,即规则地划分二维数据空间,得到m×n个小矩形网格区域。每个网格区域为一个索引项,并分配一个 动态存储区,全部或部分落入该网格的空间对象的标识以及外接矩形存入该网格。
网格索引是一种多对多的索引,会导致冗余,网格划分得越细,搜索的精度就越高,当然冗余也越大,耗费的磁盘空间和搜索时间也越长。网格法由于必须预先定义好网格大小,因此它不是一种动态的数据结构。适合点数据。网格索引搜索算法的时间复杂度为o(N2)。
- KD-Tree法:
SIFT算法中做特征点匹配的时候就会利用到k-d树。而特征点匹配实际上就是一个通过距离函数在高维矢量之间进行相似性检索的问题。针对如何快速而准确地找到查询点的近邻,现在提出了很多高维空间索引结构和近似查询的算法,k-d树就是其中一种。
索引结构中相似性查询有两种基本的方式:一种是范围查询(range searches),另一种是K近邻查询(K-neighbor searches)。范围查询就是给定查询点和查询距离的阈值,从数据集中找出所有与查询点距离小于阈值的数据;K近邻查询是给定查询点及正整数K,从数据集中找到距离查询点最近的K个数据,当K=1时,就是最近邻查询(nearest neighbor searches)。
特征匹配算子大致可以分为两类。一类是线性扫描法,即将数据集中的点与查询点逐一进行距离比较,也就是穷举,缺点很明显,就是没有利用数据集本身蕴含的任何结构信息,搜索效率较低,第二类是建立数据索引,然后再进行快速匹配。因为实际数据一般都会呈现出簇状的聚类形态,通过设计有效的索引结构可以大大加快检索的速度。索引树属于第二类,其基本思想就是对搜索空间进行层次划分。根据划分的空间是否有混叠可以分为Clipping和Overlapping两种。前者划分空间没有重叠,其代表就是k-d树;后者划分空间相互有交叠,其代表为R树。
二、问题描述
2.1具体任务
本次作业任务是空间检索,给定一个GPS数据记录文件,每条记录包含经度、纬度等多个属性,其中常用的就是经度、维度、地点的ID以及地点的类别属性,要求采用合适的算法,实现三种检索方法,分别是最邻近算法(KNN),区域查询以及半径查询。最邻近算法是给定一个坐标ID,查找距离该坐标最近的某个地点。区域查询是通过给定的矩形范围四个角的经纬度,查询该区域中某类别的坐标地点。半径查询是给定一个中心位置,以该位置为圆心,进行圆形区域范围检索某类别的坐标地点。
2.2程序输入
本程序分为最近距离搜索、区域搜索和半径搜索。最近距离搜索的输入为:查询地点的坐标ID,最近的查询类别编号。区域搜素的输入为:左上角经度,左上角纬度,右上角经度,右上角纬度,查找类别。半径搜索的输入为:查找地点坐标ID,查询半径以及查询地点的类别编号。
2.3 程序输出
本程序输出的是经度坐标、维度坐标、名字和最近距离。
三、问题解答
3.1 数据预处理
本次程序输入为GPS数据记录文件,每行记录又分为若干个属性,根据题意,我们只需关注经度、纬度坐标、地点ID以及坐标类别属性即可,原始数据文件部分记录如图3.1所示:

图3.1 原始数据文件部分记录示意图
刚开始选择的方案是与数据文件建立连接,从中抽取出需要的属性对应的数据,形成新的数据文件或者是在存储在内存数组中,存储在内存中缺点是占用内存,形成新的数据文件是用行号作为索引,可能会多次多文件进行读取,增大运行时间。后来经过研究发现,可以有两种方式,在不占用太大内存的情况下,将数据输入数据文件,并在内存中建立数据的索引。分别时将对象序列化存入数据文件,将对象的索引以集合的方式在内存中建立索引,另一种是将数据存储JSONObject,然后装入JSONArray,写入JSON文件,就可以以下标方式建立索引。通过运行时间比较发现,对象序列化方式建立文件和读取的速度快。
3.2 Grid-based Spatial Indexing
3.2.1 搜索的特点
(1)将空间划分为不相交和均匀的网格
(2)在每个网格和网格点之间建立反向索引


3.2.2 范围查询
(1)查找与范围查询相关的网格。
(2)从网格中获取点并确定范围内的点。

3.2.3 最邻近查询
(1)计算的是欧式距离。
(2)道路网络的距离是完全不同的。
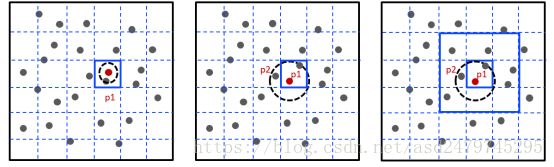
最近的点在网格内部 最近的点在网格外部 快速近似
3.2.4 基于网格查询的优缺点
优点:(1)易于实现和理解。
(2)能非常有效的处理范围和最近的查询。
缺点:(1)索引大小可能很大。
(2)难以处理不平衡的数据。

3.3 KD-Tree Spatial Indexing
3.3.1 搜索的特点
图中的行编号表示对应节点出现的树的级别。
Kd-Tree,即K-dimensional tree,是一棵二叉树,树中存储的是一些K维数据。在一个K维数据集合上构建一棵Kd-Tree代表了对该K维数据集合构成的K维空间的一个划分,即树中的每个结点就对应了一个K维的超矩形区域(Hyperrectangle)。

3.2.2 范围查询
(1) 判断结点在不在范围之内,如果包含于范围之内就进入子树查询。
(2)通过建立的树节点比较可以节省查询时间,提高查询效率。
由于kd-tree每一层都是对平面的划分,我们考虑其孙子辈节点.查询只会对那些与其相交的节点递归查询,因此只需要判断相交区域数目就行了。

3.2.3最邻近查询
从根节点开始递归的查找,根据p在节点的左边还是右边,决定递归方向
若到达叶节点,则将其作为当前最优节点
回溯:
(1) 若当前节点比当前最优点更优,则将其作为当前最优节点
(2) 判断左子树是否存在最优点,若有则递归下去
当根节点搜索完毕,则查找结束。
具体实现的时候需要说明的是,可以用一个优先队列存储最优的k个节点,这样每次比对回溯节点是否比当前最优点更优的时候,就只需用当前最优点中里p最远的节点来比对,而这个工作对于优先队列来说是O(1)的。

四、代码实现
4.1 程序总流程
网格法空间搜索:
(1)获取原始点坐标并将其写入到文件中,主要包括读文件和写文件两种操作。
(2)将所选区域等分为格状,读取目标物经纬度,查找网格内部与它最近的点的位置。
(3)若搜寻无果,则扩大搜索范围,采用递归调用的方法逐渐搜寻与他最近的点。
KD-Tree空间搜索:
1.最邻近算法
k_close(p,o,k,)//查询点p,树当前节点o,近邻数目k
从根节点开始递归的查找,根据p在节点的左边还是右边,决定递归方向
若到达叶节点,则将其作为当前最优节点
回溯:
(1) 若当前节点比当前最优点更优,则将其作为当前最优节点
(2) 判断左子树是否存在最优点,若有则递归下去
当根节点搜索完毕,则查找结束。
2.范围查找
if v 是叶子
报告并return
if lc(左子树) 包含于 搜索区域
报告lc
else 左子树与搜索区域相交
递归搜索左子树
if rc(右子树) 包含于 搜索区域
else 右子树与搜索区域相交
递归搜索右子树
报告rc
4.2 具体代码实现
https://download.csdn.net/download/asd2479745295/10675084
五、程序运行结果
5.1 网格法空间搜索:
5.1.1最邻近算法

5.1.2范围查找算法

5.1.3圆范围查找

5.2 KD-Tree空间搜索
5.2.1最邻近算法查找

5.2.2范围查找

5.2.3半径查找

5.3 索引文件建立时间对比
抽取的数据放入txt需要频繁读取,所以考虑了两种建立索引的方式,一种是将数据放入对象,然后序列化写入文件,另一种是将数据存入JSON对象,然后写入JSON文件。

部分代码
public class UtilZ
{
/**
* 读取指定文件指定行号的内容
* @param sourceFile 文件
* @param lineNumber 行号
* @return 字符串内容
*/
public String readAppointedLineNumber(File sourceFile, int lineNumber)
throws IOException {
FileReader in = new FileReader(sourceFile);
LineNumberReader reader = new LineNumberReader(in);
String s = "";
int lines = 0;
while (s != null) {
lines++;
s = reader.readLine();
if((lines - lineNumber) == 0) {
// System.out.println(s);
return s;
}
}
reader.close();
in.close();
return s;
}
/**
* 字符串模糊匹配
* @param adressName 匹配的字符串 比如ATM
* @param text 查询的内容 比如中国银行ATM机
* @return 字符串内容
*/
private static boolean match(String adressName,String text){
Pattern pattern = Pattern.compile("("+adressName+")");
Matcher matcher = pattern.matcher(text);
if(matcher.find()){
// System.out.println("匹配到了:"+matcher.group(1));
return true;
}
// System.out.println("没有匹配到");
return false;
}
/**
* 根据两点经纬度获得两点距离
* @param lat 经度
* @param lon 纬度
* @return 两点距离
*/
public static double Geodist(double lat1, double lon1, double lat2, double lon2)
{
double radLat1 = Rad(lat1);
double radLat2 = Rad(lat2);
double delta_lon = Rad(lon2 - lon1);
double top_1 = Math.cos(radLat2) * Math.sin(delta_lon);
double top_2 = Math.cos(radLat1) * Math.sin(radLat2) - Math.sin(radLat1) * Math.cos(radLat2) * Math.cos(delta_lon);
double top = Math.sqrt(top_1 * top_1 + top_2 * top_2);
double bottom = Math.sin(radLat1) * Math.sin(radLat2) + Math.cos(radLat1) * Math.cos(radLat2) * Math.cos(delta_lon);
double delta_sigma = Math.atan2(top, bottom);
double distance = delta_sigma * 6378137.0;
return distance;
}
public static double Rad(double d)
{
return d * Math.PI / 180.0;
}
/**
* 根据某点经纬度和半径,获取圆周内最大最小经纬度
* @param lat 经度
* @param lon 纬度
* @param 半径
* @return 数组minLat, minLng, maxLat, maxLng
*/
public static double[] GetAround(double lat, double lon, int raidus)
{
Double latitude = lat;
Double longitude = lon;
Double degree = (24901 * 1609) / 360.0;
double raidusMile = raidus;
Double dpmLat = 1 / degree;
Double radiusLat = dpmLat * raidusMile;
Double minLat = latitude - radiusLat;
Double maxLat = latitude + radiusLat;
Double mpdLng = degree * Math.cos(latitude * (3.14159265 / 180));
Double dpmLng = 1 / mpdLng;
Double radiusLng = dpmLng * raidusMile;
Double maxLng = longitude - radiusLng;
Double minLng = longitude + radiusLng;
return new double[] { minLat, minLng, maxLat, maxLng };
}
/**
* 求一个一维数组的方差
* @param data 数据
*
* @return 方差
*/
public static double variance(ArrayList data,int dimention){
double vsum = 0;
double sum = 0;
for(double[] d:data){
sum+=d[dimention];
vsum+=d[dimention]*d[dimention];
}
int n = data.size();
return vsum/n-Math.pow(sum/n, 2);
}
/**
* 递归实现快速排序算法
* @param data 数据
* @param low 低位置
* @param high 高位置
* @return 方差
*/
public static void QuickSort(double[] data,int low,int high)
{
// TODO 自动生成的方法存根
if(low= temp)
{
high--;
}
data[low] = data[high];//比中轴小的记录移到低位置
while(low < high && data[low] <= temp)
{
low++;
}
data[high] = data[low] ; //比中轴大的记录移到高位置
}
data[low] = temp ; //将中轴元素放入中轴
return low;
}
/**
* 求矩形外一点到矩形最小的距离
* @param input 输入的点的数据
* @param max 横纵坐标的最大值
* @param min 横纵坐标的最小值
* @return 最小距离
*/
public static double minP_RDistance(double []input,double []max,double min[])
{
double point_x=input[0];
double point_y=input[1];
double max_x=max[0];
double max_y=max[1];
double min_x=min[0];
double min_y=min[1];
double mindistance=0;
//如果在矩形的左右两边
if(point_y>min_y&&point_ymax_x)
{
mindistance=Geodist(point_x,point_y, max_x, point_y);
}
else if(point_xmin_x&&point_xmax_y)
{
mindistance=Geodist(point_x,point_y, point_x, max_y);
}
else if(point_ymax_y)
{
mindistance=Geodist(point_x,point_y,min_x,max_y);
}//左下
else if(point_xmax_x&&point_y>max_y)
{
mindistance=Geodist(point_x,point_y,max_x,max_y);
}//右下
else if(point_x>max_x&&point_y