Hadoop之MapReduce---Shuffle的详细工作流程
文章主要内容
- shuffle的简介----前半部分(3.2.1)+后半部分(3.2.2)
- Partition分区----原理概述(3.2.3)+实际案例(3.2.4)
- WritableComparable 排序----原理+案例(3.2.6)
- Combiner 合并(3.2.7 )
- GroupingComparator 分组(辅助排序)(3.2.8)
- 总结----shuffle的工作流程+环形缓冲区(3.2.9)
承接文章:Hadoop之MapReduce
本文所有案例的代码:案例代码
3.2 Shuffle的详细工作流程
在经过了上述过程之后,可以了解一下详细的Shuffle的工作流程。
3.2.1 Shuffle的前半部分
- 客户端提交给yarn,然后yarn给一个id,客户端把信息提交后,yarn再继续任务
- 要开几个MapTask是由Yarn决定的(切片数量)。
- 一个RecordReader只处理一个切片,一个MapTask也只对应一个切片。
- MapTask处理完的KV值交给Mapper
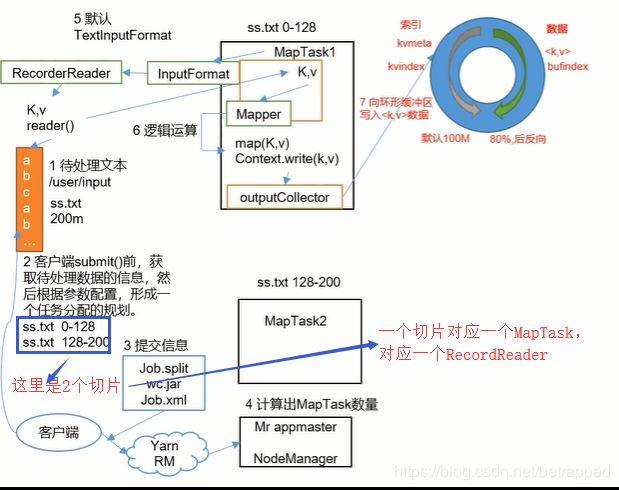
- 逻辑处理完后交给框架,进入到一个环形缓冲区
- 从Mapper出来的数据按Key值做了全排序,把相同的Key放在一起,通过这种方式完成分组。
全排序的方式是:把数据分为几部分,先局部排序(采用快排),再对排序好的这些区域做整体的归并排序。
具体实现:在缓冲区对数据进行快排,当缓冲区内存满了之后,就写到一个文件中,第二次满了就再写一个文件。然后对这些文件进行归并排序。
直到10这一步,MapTask就结束了。
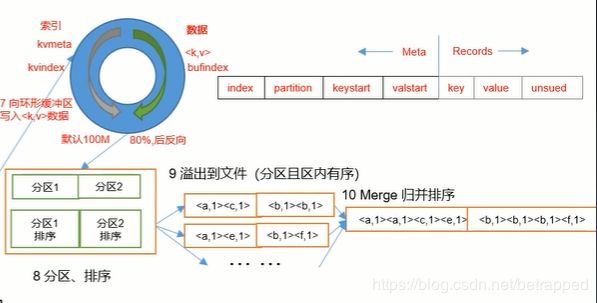
3.2.2 Shuffle的后半部分
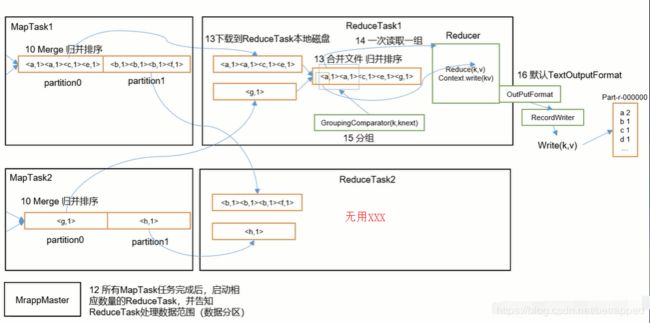
MapReduce传进来的数据放到一个ReduceTask中再次进行归并排序。得到一个全部数据的全排序文件。
3.2.3 Partition分区 - 数据的分区号就是它将在哪个ReducerTask上执行。
- 分区号是在进入环形缓冲区之前获得的。
- numReducerTask可以在Driver中通过job.setNumReducerTask(num);来设置
- 分区号的获取:

首先得到Key的hashcode,对numReducerTasks取模(得到的分区号就是0~numReducerTasks-1)
&一个Max_VALUE是防止hashcode出现负值
3.2.4 Partition分区案例实践
例3:分区实践
3.2.4.1 需求
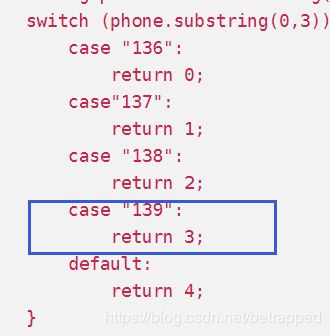
将统计结果按照手机归属地不同省份输出到不同的文件中
期望输出:
手机号136、137、138、139开头分别放到一个独立的4个文件中,其他开头的放到一个文件中。
3.2.4.2 实现
这部分基于2.3的例1实现,把计算完流量的用户,按上述需求分为5个文件。
一个新的Partition–MyPartitioner:
public class MyPartitioner extends Partitioner {
public int getPartition(Text text, FlowBean flowBean, int numPartitions) {
String phone = text.toString();
switch (phone.substring(0,3)){
case "136":
return 0;
case"137":
return 1;
case "138":
return 2;
case "139":
return 3;
default:
return 4;
}
}
}
一个新的Driver-- MyPartitionDriver
public class MyPartitionDriver {
public static void main(String[] args) throws InterruptedException, IOException, ClassNotFoundException {
Job job = Job.getInstance(new Configuration());
job.setJarByClass(MyPartitionDriver.class);
job.setMapperClass(FlowMapper.class);
job.setReducerClass(FlowReducer.class);
//只新增了这两部分,设定一下Tasks的数量,和设定新写的Partition
job.setNumReduceTasks(5);
job.setPartitionerClass(MyPartitioner.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(FlowBean.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
FileInputFormat.setInputPaths(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
boolean b = job.waitForCompletion(true);
System.exit(b?0:1);
}
}
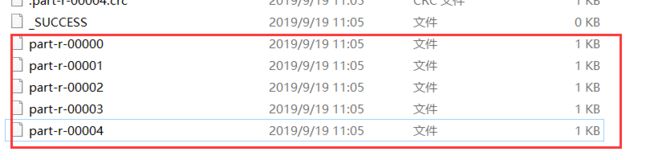
3.2.4.3 结果
五个文件分别对应五个分区
3.2.5 shuffle机制
再回头看一下shuffle的机制
- 分区=告诉数据要被哪个ReduceTasks处理
- 一个ReduceTasks对应一个输出文件,也就是一个分区对应一个输出文件。
一些问题:
- 现 在上述的例子中,删去下图框出的部分:
依旧会生成5个文件,因为设置了ReduceTasks=5,所以一定会有五个文件,只是有一个文件为空。 - 如果现在是在图中的基础上再增加一个case,分区数大于设置的ReduceTasks的数量,就会报错。
- 当真实的分区数量=设置的分区数量的时候,分区号要按顺序填写,不然依旧会报错。例如,现设置ReduceTasks=4,依旧把上图中蓝色框的部分删去,文件的分区号变为(0,1,2,4),会报错,因为4对应的是第五个分区,而这里没有第五个分区。
综上所述:分区号要从零开始逐一累加,一是防止报错,二是节约资源。
3.2.6 WritableComparable 排序
上述介绍中可以看出,排序是MapReduce框架中最重要的操作之一。
MapTask和ReduceTask均会对数据按照Key进行排序。该操作是Hadoop框架强制性的,任何应用程序中的数据均会被排序,不管逻辑上是否需要。
默认排序是按照字典顺序排序,实现排序的方法是快速排序。
例4:WritableComparable 排序案例
- 需求:根据2.3的例1产生的结果再次对总流量进行排序。
- 思路:在FlowBean中自定义一个排序方法,然后把FlowBean变成Key值在Mapper中写入框架,框架会自动完成排序。
- 实现
对FlowBean要进行两个地方的修改:
-
修改接口

接口要换成WritableComparable,其实这个接口就是Writable+Comparable,但是框架引用的是WritableComparable,所以分开来写是不行的,要写成一个接口。 -
重写排序方法
sum写成sun了,sunFlow就是总流量的意思。

SortMapper:
主要进行的就是赋值,并且把FlowBean当成Key值输出出去,这样框架就会自动对FlowBean进行排序。
public class SortMapper extends Mapper {
private FlowBean flow=new FlowBean();
private Text phone=new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] field = value.toString().split("\t");
phone.set(field[0]);
flow.setUpFlow(Long.parseLong(field[1]));
flow.setDownFlow(Long.parseLong(field[2]));
flow.setSunFlow(Long.parseLong(field[3]));
context.write(flow,phone);
}
}
SortReducer:
就是把KV值转换一下,手机号变为Key,FLowBean变成Value。
public class SortReducer extends Reducer {
@Override
protected void reduce(FlowBean key, Iterable values, Context context) throws IOException, InterruptedException {
for (Text value : values) {
context.write(value,key);
}
}
}
SortDriver
跟之前的一致,注意一下调转Mapper的KV值的类型即可。

3.2.7 Combiner 合并
- Combiner是MapReduce程序中Mapper和Reducer之外的一种组件
- Combiner组件的父类就是Reducer
- Combiner和Reducer的区别在于运行时的位置:Combiner是在每一个MapTask所在的节点运行;Reducer是接收所有Mapper的输出结果。
- Combiner的意义就是对每一个MapTask的输出进行局部汇总,以减小网络传输量
- Combiner能够应用的前提是不能影响最终的业务逻辑(默认情况下是不开的)
- Combiner的输出KV应该跟Reducer的输入KV类型要对应起来,所以Combiner的输入输出类型要一致,因为它本质是Reducer,所以它的输入类型是Mapper的输出类型,输出依旧还要是Mapper的输出类型。
- Combiner起效的位置:

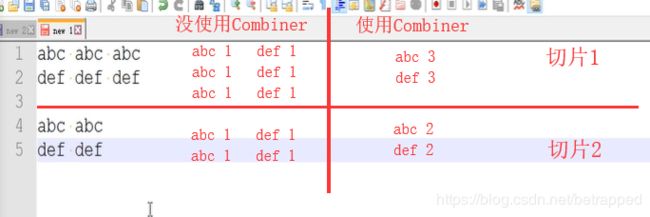
如果启动了Combiner,在Shuffle需要进行三次排序中,在前两次排序的之后,都会起效。因为每次归并排序前后都有可能出现重复的Key值。第三次排序直接就到Reducer处理了,就不需要Combiner了。
以wordCount为例:
在WcDriver中增加一句:
job.setCombinerClass(WcReducer.class); #因为在这里Combiner的作用和WcReducer一致
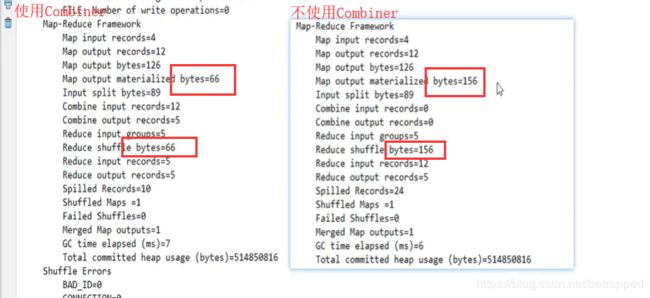
使用与未使用Combiner的差别:
3.2.8 GroupingComparator 分组(辅助排序)
对Reduce阶段的数据根据某一个或者几个字段进行分组
默认的分组规则是:两个KV对的Key相等就是一组的,不等就不是一组的。
例5:GroupingComparator分组案例实操
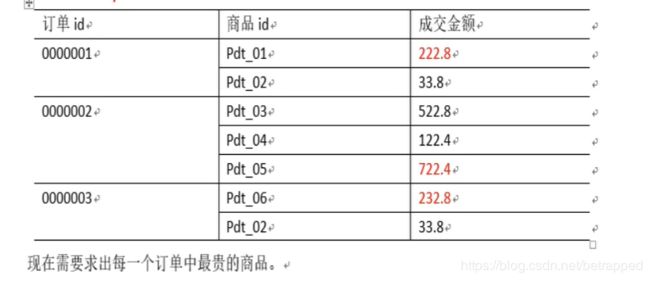
- 需求:有如下订单数据,求出每个订单中最贵的商品:
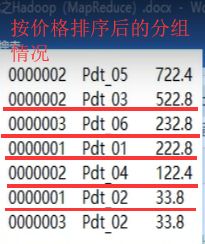
- 思路:因为MapReduce执行的顺序是先排序再分组,那么如果用默认的分组,按照价格排序后,分组的时候就无法把每个组都订单都分在一起(如下图左,只有三组订单但是分成了6组)。所以应该先按订单排序,再在组中按价格的倒序排序(如下图右),就需要重写分组规则,因为排序在分组之前进行,所以排序一定要体现分组的过程。

- 实现

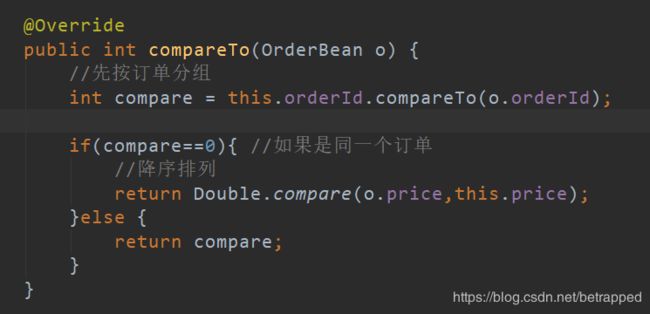
1.OrderBean

OrderBean与例4的FlowBean在构造上并无不同,只是ComparaTo函数的重写需要体现多次排序的思路,即先按订单分组,再在同组订单中降序排列:
2.OrderMapper
完成取值拆分的工作,因为不需要进行什么累加的操作,所以V值赋值成:NullWritable

3.OrderComparator
此处要申明一下对象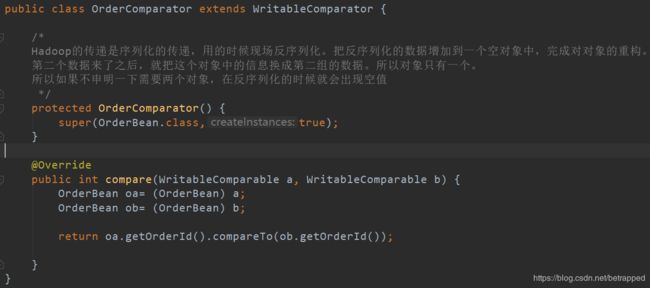
4.OrderReducer
取出即是最大值

5.OrderDriver
增加这句即可:

3.2.9 总结
总的来说,MapReduce的流程大致可以解释为:
输入->Mapper->分区&排序->Reducer->输出
一个分片一个MapTask,一个分区一个ReduceTask
实现代码的时候,只要按照这个顺序,写好输入输出和需求即可。
输入输出的关系:
- Mapper输入KV=InputFormat的KV值
- 分区的输入KV=Mapper的输出KV;排序是根据Mapper输出的Key值排序的
- Reducer的输入=Mapper的输出
- Reducer的输出=文件最终的输出
逻辑需求:
- Mapper主要用来切割文件,把它们转换成想要的KV值输出出去。特别的数据类型要另外实现。
- 分区是把数据按类型分为几类文件,一个分区输出就几个文件。自定义的排序方法写在自定义的数据类型里即可,框架会自动实现。
- Reducer完成对KV值的逻辑处理,例如:累加,相乘、调转KV值等。
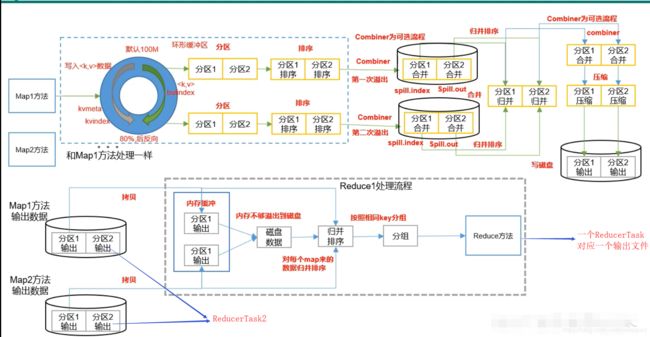
Shuffle的流程总结:
简单来说:
Map方法出来的数据
具体细节:
- Map方法出来的
- 在发生溢写的时候才进行物理分区,先根据P-分区号排序,P一致的情况下再根据K排序,也就是下图这个过程(完成了该溢写文件中的分区,并且分区内有序):
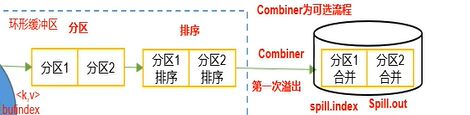
- 之后再对每个溢写文件进行归并排序完成合并,合并的最终文件就是MapTask的输出文件,文件特点:分区并且分区内有序。
- 接下来启动ReduceTask,假设有N个MapTask,每个MapTask分三个区。那么会启动三个ReduceTask,每个ReduceTask处理N个分区(同一个)。
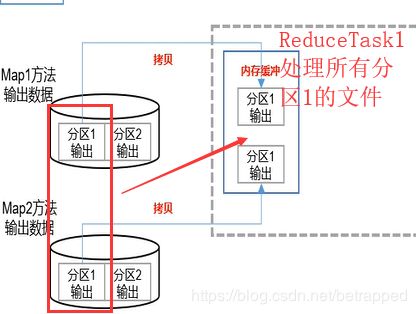
- ReduceTask把文件放在内存缓存中,满了之后再考虑写入磁盘。继而继续对每个Map来的文件进行归并排序和分组,把数据输入到Reduce方法中去。
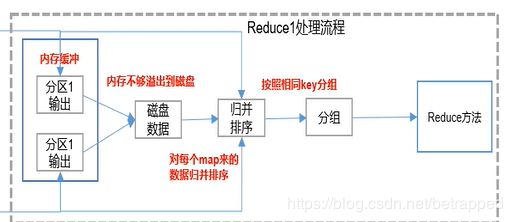
环形缓冲区:
环形缓冲区的好处就是
- 可以从一个起始点开始,一边写入KV值,一边写入索引。这样查找的时候就可以查找小内存区域的索引来快速定位,而不必去一个个遍历查找KV值。
- 在80%满的时候就停止了,就开始发生溢写。在溢写的过程中数据进来了,再继续上面1的过程,即从百分之20%的部分,再找一点开始写入KV值和索引。环形缓冲区就是通过这样,保证数据的读写一直在进行。当然这些参数都是可调的。
- 溢写数据的排序也在环形缓冲区中进行,排序的过程中,不交换KV值只交换索引,可减小IO。排序之后,从写入点开始往索引的方向开始溢写,根据索引现在的顺序,一个个的把KV值写入到溢写文件中

问题: - 分区和分组
默认情况下是:在一个分区中,KEY值相同的被分为一组。但是分组规则是可以自定义的,也就是说,在同一分区中,数据按定义的规则分组。
此外,有几个分区就产生几个输出文件,就像例3中对手机号按地区分区,最后生成了5个文件。而分组是在分区之中的,分组的作用是:数据按照组别成批放到reduce()方法中进行处理。
总而言之,分组是对每个分区的数据进行的,分区是在MapTask中进行的,而分组是在ReduceTask中进行的。