Java 八大基本数据类型
1. Java的简单类型及其封装器类
Java基本类型共有八种,基本类型可以分为三类,字符类型char,布尔类型boolean以及数值类型byte、short、int、long、float、double。数值类型又可以分为整数类型byte、short、int、long和浮点数类型float、double。JAVA中的数值类型不存在无符号的,它们的取值范围是固定的,不会随着机器硬件环境或者操作系统的改变而改变。实际上,JAVA中还存在另外一种基本类型void,它也有对应的包装类 java.lang.Void,不过我们无法直接对它们进行操作。8 中类型表示范围如下:
byte:8位,最大存储数据量是255,存放的数据范围是-128~127之间。
short:16位,最大数据存储量是65536,数据范围是-32768~32767之间。
int:32位,最大数据存储容量是2的32次方减1,数据范围是负的2的31次方到正的2的31次方减1。
long:64位,最大数据存储容量是2的64次方减1,数据范围为负的2的63次方到正的2的63次方减1。
float:32位,数据范围在3.4e-45~1.4e38,直接赋值时必须在数字后加上f或F。
double:64位,数据范围在4.9e-324~1.8e308,赋值时可以加d或D也可以不加。
boolean:只有true和false两个取值。
char:16位,存储Unicode码,用单引号赋值。
Java决定了每种简单类型的大小。这些大小并不随着机器结构的变化而变化。这种大小的不可更改正是Java程序具有很强移植能力的原因之一。下表列出了Java中定义的简单类型、占用二进制位数及对应的封装器类。
简单类型 |
boolean |
byte |
char |
short |
Int |
long |
float |
double |
void |
二进制位数 |
1 |
8 |
16 |
16 |
32 |
64 |
32 |
64 |
-- |
封装器类 |
Boolean |
Byte |
Character |
Short |
Integer |
Long |
Float |
Double |
Void |
对于数值类型的基本类型的取值范围,我们无需强制去记忆,因为它们的值都已经以常量的形式定义在对应的包装类中了。如:
基本类型byte 二进制位数:Byte.SIZE最小值:Byte.MIN_VALUE最大值:Byte.MAX_VALUE
基本类型short二进制位数:Short.SIZE最小值:Short.MIN_VALUE最大值:Short.MAX_VALUE
基本类型char二进制位数:Character.SIZE最小值:Character.MIN_VALUE最大值:Character.MAX_VALUE
基本类型double 二进制位数:Double.SIZE最小值:Double.MIN_VALUE最大值:Double.MAX_VALUE
注意:float、double两种类型的最小值与Float.MIN_VALUE、 Double.MIN_VALUE的值并不相同,实际上Float.MIN_VALUE和Double.MIN_VALUE分别指的是 float和double类型所能表示的最小正数。也就是说存在这样一种情况,0到±Float.MIN_VALUE之间的值float类型无法表示,0 到±Double.MIN_VALUE之间的值double类型无法表示。这并没有什么好奇怪的,因为这些范围内的数值超出了它们的精度范围。
Float和Double的最小值和最大值都是以科学记数法的形式输出的,结尾的"E+数字"表示E之前的数字要乘以10的多少倍。比如3.14E3就是3.14×1000=3140,3.14E-3就是3.14/1000=0.00314。
Java基本类型存储在栈中,因此它们的存取速度要快于存储在堆中的对应包装类的实例对象。从Java5.0(1.5)开始,JAVA虚拟机(JavaVirtual Machine)可以完成基本类型和它们对应包装类之间的自动转换。因此我们在赋值、参数传递以及数学运算的时候像使用基本类型一样使用它们的包装类,但这并不意味着你可以通过基本类型调用它们的包装类才具有的方法。另外,所有基本类型(包括void)的包装类都使用了final修饰,因此我们无法继承它们扩展新的类,也无法重写它们的任何方法。
基本类型的优势:数据存储相对简单,运算效率比较高
包装类的优势:有的容易,比如集合的元素必须是对象类型,满足了java一切皆是对象的思想
2.Java中的常量
十六进制整型常量:以十六进制表示时,需以0x或0X开头,如0xff,0X9A。
八进制整型常量:八进制必须以0开头,如0123,034。
长整型:长整型必须以L作结尾,如9L,342L。
浮点数常量:由于小数常量的默认类型是double型,所以float类型的后面一定要加f(F)。同样带小数的变量默认为double类型。
如:float f;
f=1.3f;//必须声明f。
字符常量:字符型常量需用两个单引号括起来(注意字符串常量是用两个双引号括起来)。Java中的字符占两个字节。一些常用的转义字符:
①\r表示接受键盘输入,相当于按下了回车键;
②\n表示换行;
③\t表示制表符,相当于Table键;
④\b表示退格键,相当于Back Space键;
⑤\'表示单引号;
⑥\''表示双引号;
⑦\\表示一个斜杠\。
3. 数据类型之间的转换
1).简单类型数据间的转换,有两种方式:自动转换和强制转换,通常发生在表达式中或方法的参数传递时。
自动转换
具体地讲,当一个较"小"数据与一个较"大"的数据一起运算时,系统将自动将"小"数据转换成"大"数据,再进行运算。而在方法调用时,实际参数较"小",而被调用的方法的形式参数数据又较"大"时(若有匹配的,当然会直接调用匹配的方法),系统也将自动将"小"数据转换成"大"数据,再进行方法的调用,自然,对于多个同名的重载方法,会转换成最"接近"的"大"数据并进行调用。这些类型由"小"到"大"分别为 (byte,short,char)--int--long--float—double。这里我们所说的"大"与"小",并不是指占用字节的多少,而是指表示值的范围的大小。
①下面的语句可以在Java中直接通过:
byte b;int i=b; long l=b; float f=b; double d=b;
②如果低级类型为char型,向高级类型(整型)转换时,会转换为对应ASCII码值,例如
char c='c'; int i=c;
System.out.println("output:"+i);输出:output:99;
③对于byte,short,char三种类型而言,他们是平级的,因此不能相互自动转换,可以使用下述的强制类型转换。
short i=99 ; char c=(char)i; System.out.println("output:"+c);输出:output:c;
强制转换
将"大"数据转换为"小"数据时,你可以使用强制类型转换。即你必须采用下面这种语句格式: int n=(int)3.14159/2;可以想象,这种转换肯定可能会导致溢出或精度的下降。
2)表达式的数据类型自动提升, 关于类型的自动提升,注意下面的规则。
①所有的byte,short,char型的值将被提升为int型;
②如果有一个操作数是long型,计算结果是long型;
③如果有一个操作数是float型,计算结果是float型;
④如果有一个操作数是double型,计算结果是double型;
例, byte b; b=3; b=(byte)(b*3);//必须声明byte。
3)包装类过渡类型转换
一般情况下,我们首先声明一个变量,然后生成一个对应的包装类,就可以利用包装类的各种方法进行类型转换了。例如:
①当希望把float型转换为double型时:
float f1=100.00f;
Float F1=new Float(f1);
double d1=F1.doubleValue();//F1.doubleValue()为Float类的返回double值型的方法
②当希望把double型转换为int型时:
double d1=100.00;
Double D1=new Double(d1);
int i1=D1.intValue();
简单类型的变量转换为相应的包装类,可以利用包装类的构造函数。即:Boolean(boolean value)、Character(char value)、Integer(int value)、Long(long value)、Float(float value)、Double(double value)
而在各个包装类中,总有形为××Value()的方法,来得到其对应的简单类型数据。利用这种方法,也可以实现不同数值型变量间的转换,例如,对于一个双精度实型类,intValue()可以得到其对应的整型变量,而doubleValue()可以得到其对应的双精度实型变量。
4)字符串与其它类型间的转换
其它类型向字符串的转换
①调用类的串转换方法:X.toString();
②自动转换:X+"";
③使用String的方法:String.volueOf(X);
字符串作为值,向其它类型的转换
①先转换成相应的封装器实例,再调用对应的方法转换成其它类型
例如,字符中"32.1"转换double型的值的格式为:new Float("32.1").doubleValue()。也可以用:Double.valueOf("32.1").doubleValue()
②静态parseXXX方法
String s = "1";
byte b = Byte.parseByte( s );
short t = Short.parseShort( s );
int i = Integer.parseInt( s );
long l = Long.parseLong( s );
Float f = Float.parseFloat( s );
Double d = Double.parseDouble( s );
③Character的getNumericValue(char ch)方法
5)Date类与其它数据类型的相互转换
整型和Date类之间并不存在直接的对应关系,只是你可以使用int型为分别表示年、月、日、时、分、秒,这样就在两者之间建立了一个对应关系,在作这种转换时,你可以使用Date类构造函数的三种形式:
①Date(int year, int month, int date):以int型表示年、月、日
②Date(int year, int month, int date, int hrs, int min):以int型表示年、月、日、时、分
③Date(int year, int month, int date, int hrs, int min, int sec):以int型表示年、月、日、时、分、秒
在长整型和Date类之间有一个很有趣的对应关系,就是将一个时间表示为距离格林尼治标准时间1970年1月1日0时0分0秒的毫秒数。对于这种对应关系,Date类也有其相应的构造函数:Date(long date)。
获取Date类中的年、月、日、时、分、秒以及星期你可以使用Date类的getYear()、getMonth()、getDate()、getHours()、getMinutes()、getSeconds()、getDay()方法,你也可以将其理解为将Date类转换成int。
而Date类的getTime()方法可以得到我们前面所说的一个时间对应的长整型数,与包装类一样,Date类也有一个toString()方法可以将其转换为String类。
有时我们希望得到Date的特定格式,例如20020324,我们可以使用以下方法,首先在文件开始引入,
import java.text.SimpleDateFormat;
import java.util.*;
java.util.Date date = new java.util.Date();
//如果希望得到YYYYMMDD的格式
SimpleDateFormat sy1=new SimpleDateFormat("yyyyMMDD");
String dateFormat=sy1.format(date);
//如果希望分开得到年,月,日
SimpleDateFormat sy=new SimpleDateFormat("yyyy");
SimpleDateFormat sm=new SimpleDateFormat("MM");
SimpleDateFormat sd=new SimpleDateFormat("dd");
String syear=sy.format(date);
String smon=sm.format(date);
String sday=sd.format(date);
总结:只有boolean不参与数据类型的转换
(1).自动类型的转换:a.常数在表数范围内是能够自动类型转换的
b.数据范围小的能够自动数据类型大的转换(注意特例)
int到float,long到float,long到double 是不会自动转换的,不然将会丢失精度
c.引用类型能够自动转换为父类的
d.基本类型和它们包装类型是能够互相转换的
(2).强制类型转换:用圆括号括起来目标类型,置于变量前
4.Java引用类型
Java有 5种引用类型(对象类型):类 接口 数组 枚举 标注
引用类型:底层结构和基本类型差别较大
JVM的内存空间:(1). Heap 堆空间:分配对象 new Student()
(2). Stack 栈空间:临时变量 Student stu
(3).Code 代码区 :类的定义,静态资源 Student.class
eg:Student stu = new Student(); //new 在内存的堆空间创建对象
stu.study(); //把对象的地址赋给stu引用变量
上例实现步骤:a.JVM加载Student.class 到Code区
b.new Student()在堆空间分配空间并创建一个Student实例;
c.将此实例的地址赋值给引用stu, 栈空间;
----------------------------------------- 个人总结 -----------------------------------------
上面是转载别人的文章,下面做个总结:
1、如果小数类型,并且小数比较小,比如四位小数,建议使用 BigDecimal 如果 是 double 类型会有失精度,有的时候会用科学记数法表示;
比如 0.0001 会变成 1.0E-4,试问谁能看懂,如果偏要用 double 还要对类型进行转换。
2、int double 都是有包装类型的,建议使用包装类型,包装类型能区分 null 和 0,就像在spring-mvc接收时使用 int 类型接收值,如果这个属性不传值,ajax 请求会报 400 错误,而且不能区分这个值是否是空;
3、for 循环中如果要对字符串进行拼接,建议使用 StringBuffer ,如果没有线程安全问题,直接使用 StringBuilder,原因StringBuffer的所有操作是保证线程安全的,可以理解成使用了 synchronized 关键字,对性能是有影响的。
4、最后对所有包装类型进行操作(比如 toString())要进行空指针判断,我们并不能保证这个值是有的。
//
Java 变量之变量数据类型
Java数据类型图: 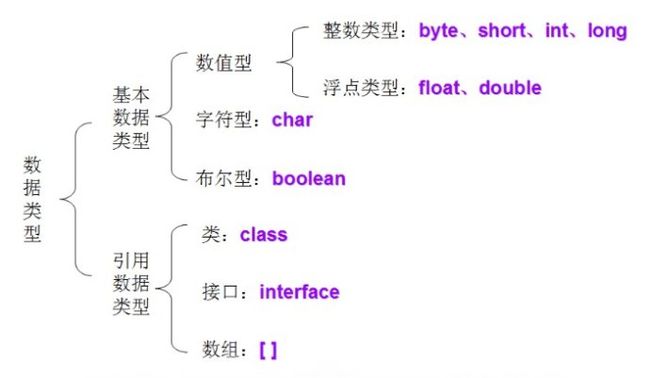
1.基本数据类型
基本数据类型,也称内置类型,是可以在栈直接分配内存的,Java保留基本数据类型最大的原因也在此:性能。关于这一点可以参考:Java为什么需要保留基本数据类型。
另外,要注意,Java是基于JVM的,所以,其所占字节固定,与机器平台无关,所有地方统一占用内存大小(除了boolean,以及byte/short/boolean数组的时候每个单元所占的内存是由各个JVM自己实现的)。
总共有四类八种基本数据类型(注1):
1).整型:全部是有符号类型。
1.byte:1字节(8bit),高位为符号位,其余7位为数据位,范围:-2的7次方~2的7次方-1(1111,1111~0111,1111),即-128~127(下面的计算方式相同);
注意:byte类型虽然在语义(逻辑)上是占用1字节,但实际上,JVM中是将其当做int看
的,也就是事实上是占用了32位,4字节的,所以其运算效率和int没区别,short也一样。
之所以要有byte/short类型,一是因为某些地方要明确使用这些范围类型,二是,
在byte[]数组中,JVM存储的则是真的1字节,short[]2字节。(但也有的JVM其byte[]
数组也是4字节1位)- 1
- 2
- 3
- 4
- 5
2.short:2字节(16bit),高位为符号位,其余15位为数据位,范围:-2的15次方~2的15次方-1,即-32768~32767;
3.int:4字节(32bit),范围-2的31次方~2的31次方-1;Java默认的整型类型,即:
long l = 0xfffffffffff;//0x表示这个数是16进制数,0表示8进制。
//编译器报错,因为右边默认是int,但其超出了范围(没超出int范围的话
//编译器会隐式将int转为long),故报错(同样的错误也会出现在float)。- 1
- 2
- 3
同样的还有:
short s = 123;//(这个123也是int类型,这里,= 操作编译器能隐式转换)
s = s + 123;//编译器报错,那是因为s+1是int类型(编译器先将s转化为int,再+1),
//这里,+ 操作编译器不能隐式转换(会提示失真,即精度可能会受损),正确的做法:
s = (short)(s + 123)//注意,不是(short)s + 123。- 1
- 2
- 3
- 4
类型转化详见:Java 数据类型转化。
4.long:8字节(64bit),范围:-2的63次方~2的63次方-1;声明大的long方法:
long l = 0xfffffffffffL;//即在后面加上L或l。
//(强制转化:long l = (long)0xfffffffffff也没用)- 1
- 2
2).浮点型
5.float:4字节(32bit),单精度,数据范围:(-2^128)~(-2^(-23-126))-(0)-(2^-149)~2^128。浮点数,通俗来说就是小数,但是,这是有精度要求的,即在这区间float可不是能表达任意小数的,而是在一定精度下,比如float有效位7~8位(包括整数位和小数位,有效小数位是6~7位,这里为什么是7~8(6~7),参考:Java中float/double取值范围与精度),即0.123456789后面的9JVM是不认识的(8能认识,整数位为0则不算是有效位,例如12.1234567后面的7也不认识,只有6位有效小数位(注意,看的是有效位,不是有效小数位,float有7~8位有效位)),即:
if(0.123456781f == 0.123456789f){//注意后面加f/F,否则就是double
System.out.println("true");
}else{
System.out.println("false");
}
//打印结果:true
//事实上,浮点数值的比较是不能直接用==判断的,这里原因就要追究到浮点数的内存结构
//浮点数比较可以用一个差值,但这种情况只是近似的比较
//如果想要精确,可以使用BigDecimal
System.out.println(Float.MIN_VALUE);//1.4E-45 = 2^-149
//这里的“最小值”意味float能表示的最小小数,实际上float最小值等于最大值取负
System.out.println(Float.MAX_VALUE);//3.4028235E38 = 2^128- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
6.double:8字节(64bit),双精度,范围:-2^1024~(-2^(-1022-52))-0-(2^-1074)~2^1024,Java默认的浮点类型,即若后面不加f/F,默认是double类型,即:
float f = 1.23;//编译报错,因为
float f = 1.23f;//或float f = 1.23F;
//默认是double,1.23(double)转成float,做隐式转换,但是double转成float是
//取值范围大的转成取值范围小的会损失精度,因此不能转换(详见Java数据类型转换)
//那为什么,int可以转换成byte、short,int范围更大不是?
//前面已经说过了,byte、short实际在JVM上就是int,因此编译器是不会认为会损失精度的
//但是int是不能转换成boolean,虽然boolean也是4字节(一般JVM),但在JVM认为这
//两者完全是两个东西,当然不能转换(强制也不行,你不能把猫强制转换成鸟,完全两个物种),而byte、short都是整型,同int是一个类型- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
3).字符型
7.char:2字节(16bit),表示一个字符(可以是汉字),字符编码采用Unicode(说的更准确点,字符集(charset)采用UCS-2,编码(encoding)采用UTF-16),实际上就是一个16位的无符号整型,但是,要注意的是,因为随着发展,char所能代表的字符个数(UCS-2字符集)被限定死了,所以并不推荐使用。(更多内容,以及关于Unicode、UTF8/16参考:Unicode、UTF8以及Java char。)
char c = 3+5;//正确,char是无符号整型,但不能这样
int a1 = 3;int a2 = 5;char c0 = a1+a2;//这里需要强制转换才行
char c1 = -3;//编译错误,char不能表示负数,即使
char c2 = (char)-3;//编译正确,但无意义(乱码)
char c3 = '3';//正确,输出字符3
char c4 = "3";//编译错误,双引号,表示的是字符串
char c5 = '65';//编译错误,这里65是两个字符- 1
- 2
- 3
- 4
- 5
- 6
- 7
4).布尔型
8.boolean:逻辑上:1bit,但是实际上,boolean并没有具体规定,完全是看各个JVM实现,不过《Java虚拟机规范》给出了4个字节(同byte解释)和boolean数组一个字节的定义。
注1:
(1).这种分法是一种比较流行的分法,事实上应该为两种:数值类型与布尔型。数值类型分为整型和浮点型。整型包括:byte、short、int、long、char;浮点型:float、double;布尔型boolean。之所以将char认为是整型是因为char在JVM就是以无符号整型存在的。
(2).事实上Java中除去这8种以及对象类型,还有一种比较特殊的类型存在,那就是Void。java.lang.Void,是一个占位符类,不可实例化,保存着Java关键字void的Class对象。为什么说它特殊呢?明明是一个类,难道不是对象类型?那是因为void.class.isPrimitive()(这个方法是用来判断一个Class对象是否是基本类型的)返回的是true,所以Void也算是基本类型的一个了(错了),只不过它比较特殊,不能算是一种数据,只是一种象征。
20160921 改:上面弄错了,把Void和void两个混为一体了,事实上,可以简单的把这两者的关系看成类似包装类和基本类型的关系,像Integer和int的关系,java.lang.Void是一个不可实例化的占位符类来保存一个引用代表了Java关键字void的Class对象:
public static final Class TYPE = Class.getPrimitiveClass("void"); - 1
而Integer也有类似的语句:
public static final Class<Integer> TYPE = (Class<Integer>) Class.getPrimitiveClass("int");- 1
区别只是,Void仅仅是为void服务,即所谓的占位符类,不做他用。所以Void类只是一个普通类,而void则可以认作为如同int一样的基本类型。
2.引用数据类型
也称对象变量类型,复合数据类型,包含类、接口、数组(除了基本类型外,就是引用类型)。引用类型与基本类型最大的区别在于:
int a = 5;//这里的a是对象(严格来说不算是对象,只是个符号标识),5是数值
Integer a = 5;//这里的a是一个引用,5才是一个对象,更形象常见的是:
Object o = new Object();//o是引用(栈中),new Object()是对象(堆中)
//第二行代码中,5被自动包装成Integer对象- 1
- 2
- 3
- 4
这里的引用有点像C/C ++中的指针,但是同指针不同的是,你不能通过改变它的值从而去改变它所指向的值。即
ClassA p = new ClassA();//C++中,这个时候是可以这样操作的:
p = p + 1;//向前移动一个单元,Java则不能
//这种操作,其实是对内存直接的操作,很显然,Java是不允许程序员做这种操作的- 1
- 2
- 3
其实质就是,Java的引用不支持对内存直接操作,而指针则可以,所以,Java用起来更安全,但不够灵活,而指针,自由度大,但同时,要更加小心因为指针操作不当而引起的各种内存问题。在Java中,任何对象都需要通过引用才能访问到,没有引用指向的对象被视为垃圾对象,将会被回收。
引用,其实质同指针一样(可以理解为受限制的指针),存放的是一个地址,至于是实例对象的地址,还是一个指向句柄池的地址(这里可以参考:(3) Java内存结构),完全是看各个JVM的实现了。
Java中的枚举类型,都是Enum类的子类,算是类中的一种,也是引用类型。
引用类型又称为对象变量类型,是相对于基本数据类型来说的(基本数据类型不是对象),而又被称为复合数据类型,可以这样理解,引用类型的数据最终都是由基本数据类型构成的。而像接口,接口是不能实例化的,最终的实现还是由类实现的;数组在JVM中的实现也是通过类实现的,每个类型的一维数组,二维数组……都是一个类,只是这是一个特殊的类,它的对象头有别于一般对象的对象头(最主要的就是,数组对象头有对象长度)。
Java语言是静态类型的(statical typed),也就是说所有变量和表达式的类型再编译时就已经完全确定。由于是statical typed,导致Java语言也是强类型(Strong typed)的。强类型意味着每个变量都具有一种类型,每个表达式具有一种类型,并且每种类型都是严格定义的,类型限制了变量可以hold哪些值,表达式最终产生什么值。同时限制了这些值可以进行的操作类型以及操作的具体方式。所有的赋值操作,无论是显式的还是在方法调用中通过参数传递,都要进行类型兼容性检查。
1. 数据类型:
在java源代码中,每个变量都必须声明一种类型(type)。有两种类型:primitive type和reference type。引用类型引用对象(reference to object),而基本类型直接包含值(directly contain value)。因此,Java数据类型(type)可以分为两大类:基本类型(primitive types)和引用类型(reference types)。primitive types 包括boolean类型以及数值类型(numeric types)。numeric types又分为整型(integer types)和浮点型(floating-point type)。整型有5种:byte short int long char(char本质上是一种特殊的int)。浮点类型有float和double。关系整理一下如下图:
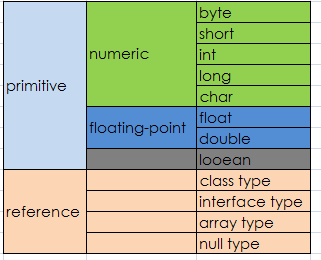
对象是动态创建的类实例或者动态创建的数组。The value of reference types are references to objects,而引用一般是指内存地址。所有的对象(包括数组)支持Object类中定义的方法。String literals are presented by String object.
java有两种类型(type),与之相对应的是两种数据的值(two kinds of data values that can be stored in variable, pass as arguments and returned by methods),这两只data values是:primitive values,reference values。也许这么理解起来更方便(虽然不严谨),Java变量有两种:primitive variable和reference variable,在变量中,它们分别存储primitive value和reference value。
null是一种特殊的type,但是你不能声明一个变量为null类型,null type的唯一取值就是null。null可以负值给任意的引用类型或者转化成任意的引用类型。在实践中,一般把null当做字面值(literal),这个字面值可是是任意的引用类型。
2. 基本类型:
Java为基本类型提供语言级别的支持,即已经在Java中预定义,用相应的保留关键字表示。基本类型是单个值,而不是复杂的对象,基本类型不是面向对象的,主要出去效率方面的考虑,但是同时也提供基本类型的对象版本,即基本类型的包装器(wrapper)。可以直接使用这些基本类型,也可以使用基本类型构造数组或者其他自定义类型。基本类型具有明确的取值范围和数学行为。
2.1 整型
整型有byte short int long char,分别用8、16、32、64、16bits表示。有些地方可能不会把char列入整型范畴,但本质上char类型是int的一个子集。整型的宽度不应该被看成整数所占用的内存空间大小,而应当理解成定义为整型的变量或者表达式的行为。JVM可以自由使用它们希望的、任何大小的内存空间,只要类型的行为符合规范。byte short int long都是有符号的,用2的补码(two‘s-complement)表示。而char用16位表示,它是无符号的,表示的是UTF-16编码集。
2.1.1 byte
byte由1个字节8位表示,是最小的整数类型。主要用于节省内存空间关键。当操作来自网络、文件或者其他IO的数据流时,byte类型特别有用。取值范围为:[-128, 127]. byte的默认值为(byte)0,如果我们试图将取值范围外的值赋给byte类型变量,则会出现编译错误,例如 byte b = 128;这个语句是无法通过编译的。一个有趣的问题,如果我们有个方法: public void test(byte b)。试图这么调用这个方法是错误的: test(0); 编译器会报错,类型不兼容!!!我们记得byte b =0;这是完全没有问题的,为什么在这里就出错啦?
这里涉及到一个叫字面值(literal)的问题,字面值就是表面上的值,例如整型字面值在源代码中就是诸如 5 , 0, -200这样的。如果整型子面子后面加上L或者l,则这个字面值就是long类型,比如:1000L代表一个long类型的值。如果不加L或者l,则为int类型。基本类型当中的byte short int long都可以通过不加L的整型字面值(我们就称作int字面值吧)来创建,例如 byte b = 100; short s = 5;对于long类型,如果大小超出int所能表示的范围(32 bits),则必须使用L结尾来表示。整型字面值可以有不同的表示方式:16进制【0X or 0x】、10进制【nothing】、八进制【0】2进制【0B or 0b】等,二进制字面值是JDK 7以后才有的功能。在赋值操作中,int字面值可以赋给byte short int long,Java语言会自动处理好这个过程。如果方法调用时不一样,调用test(0)的时候,它能匹配的方法是test(int),当然不能匹配test(byte)方法,至于为什么Java没有像支持赋值操作那样支持方法调用,不得而知。注意区别包装器与原始类型的自动转换(anto-boxing,auto-unboxing)。byte d = 'A';也是合法的,字符字面值可以自动转换成16位的整数。
更多关于字面值的介绍,参考oracle文档(http://docs.oracle.com/javase/tutorial/java/nutsandbolts/datatypes.html)。
对byte类型进行数学运算时,会自动提升为int类型,如果表达式中有double或者float等类型,也是自动提升。所以下面的代码是错误的:
- byte s2 = 'a';
- byte sum = s1 + s2;//should cast by (byte)
2.1.2 short
用16为表示,取值范围为:[- 2^15, 2^15 - 1]。short可能是最不常用的类型了。可以通过整型字面值或者字符字面值赋值,前提是不超出范围(16 bit)。short类型参与运算的时候,一样被提升为int或者更高的类型。(顺序为 byte short int long float double).
2.1.3 int
32 bits, [- 2^31, 2^31 - 1].有符号的二进制补码表示的整数。常用语控制循环,注意byte 和 short在运算中会被提升为int类型或更高。Java 8以后,可以使用int类型表示无符号32位整数[ 0, 2^31 - 1]。
2.1.4 long
64 bits, [- 2^63, 2^63 - 1,默认值为0L].当需要计算非常大的数时,如果int不足以容纳大小,可以使用long类型。如果long也不够,可以使用BigInteger类。
2.1.5 char
16 bits, [0, 65535], [0, 2^16 -1],从'\u0000'到'\uffff'。无符号,默认值为'\u0000'。Java使用Unicode字符集表示字符,Unicode是完全国际化的字符集,可以表示全部人类语言中的字符。Unicode需要16位宽,所以Java中的char类型也使用16 bit表示。 赋值可能是这样的:
char ch1 = 88;
char ch2 = 'A';
ASCII字符集占用了Unicode的前127个值。之所以把char归入整型,是因为Java为char提供算术运算支持,例如可以ch2++;之后ch2就变成Y。当char进行加减乘除运算的时候,也被转换成int类型,必须显式转化回来。
2.2 浮点类型
包含单精度的float和双精度的double,分别用32、64bits表示,遵循IEEE 754规范。
2.2.1 float
使用32 bit表示,对应单精度浮点数,运行速度相比double更快,占内存更小,但是当数值非常大或者非常小的时候会变得不精确。精度要求不高的时候可以使用float类型,声明赋值示例:
- f1 = 10L;
- f1 = 10.0f;
- //f1 = 10.0;默认为double
2.2.2 double
64为表示,将浮点子面子赋给某个变量时,如果不显示在字面值后面加f或者F,则默认为double类型。java.lang.Math中的函数都采用double类型。
如果double和float都无法达到想要的精度,可以使用BigDecimal类。
2.3 boolean类型
boolean类型只有两个值true和false,默认为false。boolean与是否为0没有任何关系,但是可以根据想要的逻辑进行转换。许多地方都需要用到boolean类型。
3. 字面值
在Java源代码中,字面值用于表示固定的值(fixed value)。数值型的字面值是最常见的,字符串字面值可以算是一种,当然也可以把特殊的null当做字面值。字面值大体上可以分为整型字面值、浮点字面值、字符和字符串字面值、特殊字面值。
3.1. 整型字面值
从形式上看是整数的字面值归类为整型字面值。例如: 10, 100000L, 'B'、0XFF这些都可以称为字面值。整型字面值可以用十进制、16、8、2进制来表示。十进制很简单,2、8、16进制的表示分别在最前面加上0B(0b)、0、0X(0x)即可,当然基数不能超出进制的范围,比如09是不合法的,八进制的基数只能到7。一般情况下,字面值创建的是int类型,但是int字面值可以赋值给byte short char long int,只要字面值在目标范围以内,Java会自动完成转换,如果试图将超出范围的字面值赋给某一类型(比如把128赋给byte类型),编译通不过。而如果想创建一个int类型无法表示的long类型,则需要在字面值最后面加上L或者l。通常建议使用容易区分的L。所以整型字面值包括int字面值和long字面值两种。
3.2. 浮点字面值
浮点字面值简单的理解可以理解为小数。分为float字面值和double字面值,如果在小数后面加上F或者f,则表示这是个float字面值,如11.8F。如果小数后面不加F(f),如10.4。或者小数后面加上D(d),则表示这是个double字面值。另外,浮点字面值支持科学技术法表示。下面是一些例子:
- double d2 = 11.4;
- double d3 = 1.23E3;
- double d4 = 10D;
- double d5 = 0.4D;
- float f1 = 10;
- float f2 = 11.1F;
- float f3 = 1.23e-4F;
- float f4 = 1.23E0F;
3.3 字符及字符串字面值
Java中字符字面值用单引号括起来,如‘@’‘1’。所有的UTF-16字符集都包含在字符字面值中。不能直接输入的字符,可以使用转义字符,如‘\n’为换行字符。也可以使用八进制或者十六进制表示字符,八进制使用反斜杠加3位数字表示,例如'\141'表示字母a。十六进制使用\u加上4为十六进制的数表示,如'\u0061'表示字符a。也就是说,通过使用转义字符,可以表示键盘上的有的或者没有的所有字符。常见的转义字符序列有:
\ddd(八进制) 、 \uxxxx(十六进制Unicode字符)、\'(单引号)、\"(双引号)、\\ (反斜杠)\r(回车符) \n(换行符) \f(换页符) \t(制表符) \b(回格符)
字符串字面值则使用双引号,字符串字面值中同样可以包含字符字面值中的转义字符序列。字符串必须位于同一行或者使用+运算符,因为java没有续行转义序列。
3.4 特殊字面值
null是一种特殊的类型(type),可以将它赋给任何引用类型变量,表示这个变量不引用任何东西。如果一个引用类型变量为null,表示这个变量不可用。
还有一种特殊的class literal,用type name加上.class表示,例如String.class。首先,String是类Class(java.lang.Class)的一个实例(对象),而"This is a string"是类String的一个对象。然后,class literal用于表示类Class的一个对象,比如String.class用于表示类Class的对象String。简单地说,类子面子(class literal)就是诸如String.class 、Integer.class这样的字面值,它所表示的就是累String、类Integer。如果输出Integer.class,你会得到class java.lang.Integer。List.class的输出为interface java.util.List。总之,class literal用于表示类型本身!
3.5 在数值型字面值中使用下划线。
JDK7开始,可以在数值型字面值(包括整型字面值和浮点字面值)插入一个或者多个下划线。但是下划线只能用于分隔数字,不能分隔字符与字符,也不能分隔字符与数字。例如 int x = 123_456_789.在编译的时候,下划线会自动去掉。可以连续使用下划线,比如float f = 1.22___33__44.二进制或者十六进制的字面值也可以使用下划线,记住一点,下划线只能用于数字与数字之间,初次以外都是非法的。例如1._23是非法的,_123、11000_L都是非法的。
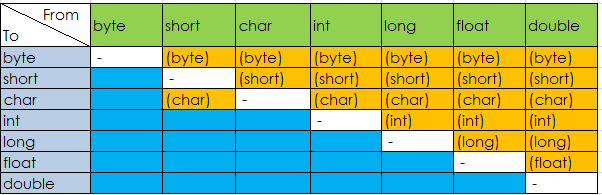
4. 基本类型之间的转换
我们看到,将一种类型的值赋给另一种类型是很常见的。在Java中,boolean类型与所有其他7种类型都不能进行转换,这一点很明确。对于其他7中数值类型,它们之间都可以进行转换,但是可能会存在精度损失或者其他一些变化。转换分为自动转换和强制转换。对于自动转换(隐式),无需任何操作,而强制类型转换需要显式转换,即使用转换操作符(type)。首先将7种类型按下面顺序排列一下:
byte <(short=char)< int < long < float < double
如果从小转换到大,可以自动完成,而从大到小,必须强制转换。short和char两种相同类型也必须强制转换。
4.1 自动转换
自动转换时发生扩宽(widening conversion)。因为较大的类型(如int)要保存较小的类型(如byte),内存总是足够的,不需要强制转换。如果将字面值保存到byte、short、char、long的时候,也会自动进行类型转换。注意区别,此时从int(没有带L的整型字面值为int)到byte/short/char也是自动完成的,虽然它们都比int小。在自动类型转化中,除了以下几种情况可能会导致精度损失以外,其他的转换都不能出现精度损失。
》int--> float
》long--> float
》long--> double
》float -->double without strictfp
除了可能的精度损失外,自动转换不会出现任何运行时(run-time)异常。
4.2 强制类型转换
如果要把大的转成小的,或者在short与char之间进行转换,就必须强制转换,也被称作缩小转换(narrowing conversion),因为必须显式地使数值更小以适应目标类型。强制转换采用转换操作符()。严格地说,将byte转为char不属于narrowing conversion),因为从byte到char的过程其实是byte-->int-->char,所以widening和narrowing都有。强制转换除了可能的精度损失外,还可能使模(overall magnitude)发生变化。强制转换格式如下:
(target-type) value
- byte b;
- b = (byte)a;//1
如果整数的值超出了byte所能表示的范围,结果将对byte类型的范围取余数。例如a=256超出了byte的[-128,127]的范围,所以将257除以byte的范围(256)取余数得到b=1;需要注意的是,当a=200时,此时除了256取余数应该为-56,而不是200.
将浮点类型赋给整数类型的时候,会发生截尾(truncation)。也就是把小数的部分去掉,只留下整数部分。此时如果整数超出目标类型范围,一样将对目标类型的范围取余数。
7中基本类型转换总结如下图:
4.3 赋值及表达式中的类型转换:
4.3.1 字面值赋值
在使用字面值对整数赋值的过程中,可以将int literal赋值给byte short char int,只要不超出范围。这个过程中的类型转换时自动完成的,但是如果你试图将long literal赋给byte,即使没有超出范围,也必须进行强制类型转换。例如 byte b = 10L;是错的,要进行强制转换。
4.3.2 表达式中的自动类型提升
除了赋值以外,表达式计算过程中也可能发生一些类型转换。在表达式中,类型提升规则如下:
》所有byte/short/char都被提升为int。
》如果有一个操作数为long,整个表达式提升为long。float和double情况也一样。
java中的数据类型分为两大类:基本数据类型和引用数据类型 基本数据类型,包括数值型,字符型和布尔型。 数值型:1)整型:byte 1个字节;short 2个字节;int 4个字节;long 8个字节。 2)浮点型:float 4个字节;double 8个字节;可以采用十进制和十六进制两种表示方式,其中十六进制表示方法只能采用科学计数法,例如:0x1.2p3,表示的是的是1乘以16加上2乘以16的-1次方的和乘以2的三次方;浮点型的默认类型为DOUBLE型,如果声明float型浮点数,要在数值后面加上f或F,例如:float f1 = 3.14F;否则会报精度错误。 字符型:char 采用unicod的16位编码方式进行编码。 布尔型:true,false; 引用数据类型:类、接口类型、数组类型、枚举类型、注解类型; 基本数据类型和引用数据类型的区别主要在存储方式上: 基本数据类型在被创建时,在栈上给其划分一块内存,将数值直接存储在栈上; 引用数据类型在被床架时,首先要在栈上给其引用(句柄)分配一块内存,而对象的具体信息都存储在堆内存上,然后由栈上面的引用指向堆中对象的地址。 例如:我有一个类MyDate,其中有属性day,mouth,year等,有构造方法(带参数); 现在为其创建一个对象MyDate d1 = new MyDate(8,8,2008); 在内存中的具体创建过程是: 1)首先在栈内存中位其d1分配一块空间; 2)然后在堆内存中为MyDate对象分配一块空间,并为其三个属性设初值0,0,0; 3)根据类MyDate中对属性的定义,为该对象的三个属性进行赋值操作; 4)调用构造方法,为三个属性赋值为8,8,2008;(注意这个时候d1与MyDate对象之间还没有建立联系) 5)将MyDate对象在堆内存中的地址,赋值给栈中的d1;通过句柄d1可以找到堆中对象的具体信息。 呵呵,引用数据类型的创建还真是挺复杂的一个过程。。。
他们分别是byte、short、int、long、float、double、char、boolean
整型
其中byte、short、int、long都是表示整数的,只不过他们的取值范围不一样
byte的取值范围为-128~127,占用1个字节(-2的7次方到2的7次方-1)
short的取值范围为-32768~32767,占用2个字节(-2的15次方到2的15次方-1)
int的取值范围为(-2147483648~2147483647),占用4个字节(-2的31次方到2的31次方-1)
long的取值范围为(-9223372036854774808~9223372036854774807),占用8个字节(-2的63次方到2的63次方-1)
可以看到byte和short的取值范围比较小,而long的取值范围太大,占用的空间多,基本上int可以满足我们的日常的计算了,而且int也是使用的最多的整型类型了。
在通常情况下,如果JAVA中出现了一个整数数字比如35,那么这个数字就是int型的,如果我们希望它是byte型的,可以在数据后加上大写的B:35B,表示它是byte型的,同样的35S表示short型,35L表示long型的,表示int我们可以什么都不用加,但是如果要表示long型的,就一定要在数据后面加“L”。
为什么是2的7次方,因为是2的八次方,但前面的1是负号了。后面的2的63次方,
浮点型
float和double是表示浮点型的数据类型,他们之间的区别在于他们的精确度不同
float 3.402823e+38 ~ 1.401298e-45(e+38表示是乘以10的38次方,同样,e-45表示乘以10的负45次方)占用4个字节
double 1.797693e+308~ 4.9000000e-324 占用8个字节
double型比float型存储范围更大,精度更高,所以通常的浮点型的数据在不声明的情况下都是double型的,如果要表示一个数据是float型的,可以在数据后面加上“F”。
浮点型的数据是不能完全精确的,所以有的时候在计算的时候可能会在小数点最后几位出现浮动,这是正常的。
boolean型(布尔型)
这个类型只有两个值,true和false(真和非真)
boolean t = true;
boolean f = false;
char型(文本型)
用于存放字符的数据类型,占用2个字节,采用unicode编码,它的前128字节编码与ASCII兼容
字符的存储范围在\u0000~\uFFFF,在定义字符型的数据时候要注意加' ',比如 '1'表示字符'1'而不是数值1,
char c = ' 1 ';
我们试着输出c看看,System.out.println(c);结果就是1,而如果我们这样输出呢System.out.println(c+0);
结果却变成了49。
如果我们这样定义c看看
char c = ' \u0031 ';输出的结果仍然是1,这是因为字符'1'对应着unicode编码就是\u0031
char c1 = 'h',c2 = 'e',c3='l',c4='l',c5 = 'o';
System.out.print(c1);System.out.print(c2);System.out.print(c3);System.out.print(c4);Sytem.out.print(c5);
String
在前面我们看到过这样的定义:
String s = "hello";
System.out.println(s);跟上面的5条语句组合起来的效果是一样的,那么String是个什么呢?String是字符串,它不是基本数据类型,它是一个类。